
เราถามคุณตอบ: Google ควรเพิ่มการรองรับ noindex ให้กับ robots.txt หรือไม่ ผลการสำรวจความคิดเห็น
เผยแพร่แล้ว: 2021-10-05ในเดือนกันยายน ฉันได้จัดทำโพลที่นี่ใน Search Engine Land เพื่อดูว่าผู้อ่านต้องการคำแนะนำใน robots.txt ให้ทำเครื่องหมายหน้าว่าไม่มีการจัดทำดัชนีหรือไม่ วันนี้ฉันจะนำเสนอผลลัพธ์พร้อมกับการทบทวนว่าประเด็นสำคัญคืออะไร (และเหตุใด Google จะไม่เพิ่มการสนับสนุนสำหรับสิ่งนี้)
- ทำไมสิ่งนี้ถึงน่าสนใจ?
- อะไรคือข้อเสียของความคิดนี้?
- ผลการสำรวจความคิดเห็นของ robots.txt โดยรวม
ทำไมสิ่งนี้ถึงน่าสนใจ?
ในสภาพแวดล้อมปัจจุบัน ใช้ robots.txt เพื่อเป็นแนวทางในการรวบรวมข้อมูลเว็บเท่านั้น นอกจากนี้ วิธีการปัจจุบันในการทำเครื่องหมายหน้า “NoIndex” คือการวางแท็กบนหน้านั้นเอง ขออภัย หากคุณบล็อกใน robots.txt Google จะไม่เห็นแท็กดังกล่าว และยังสามารถจัดทำดัชนีหน้าเว็บได้ แม้ว่าคุณจะไม่ต้องการให้สิ่งนั้นเกิดขึ้น
ในไซต์ขนาดใหญ่ การทำเช่นนี้ทำให้เกิดความท้าทายเมื่อคุณมีหน้าเว็บประเภทต่างๆ ที่คุณต้องการบล็อกจากการรวบรวมข้อมูลและป้องกันไม่ให้ดัชนีของ Google วิธีหนึ่งที่สิ่งนี้สามารถเกิดขึ้นได้คือในการใช้งานการนำทางแบบเหลี่ยมเพชรพลอยที่ซับซ้อน ซึ่งคุณมีหน้าเว็บที่คุณสร้างขึ้นซึ่งมีคุณค่ามากสำหรับผู้ใช้ แต่ลงเอยด้วยการนำเสนอหน้าเว็บไปยัง Google มากเกินไป ตัวอย่างเช่น ฉันดูเว็บไซต์ร้านขายรองเท้าแห่งหนึ่งและพบว่ามีหน้าเว็บที่เกี่ยวข้องกับ "รองเท้า Nike สำหรับผู้ชาย" กว่า 70,000 หน้า ซึ่งรวมถึงขนาด ความกว้าง สี และอื่นๆ ที่หลากหลาย
ในการทดสอบบางอย่างที่ฉันได้เข้าร่วมกับไซต์ที่มีการนำทางแบบเหลี่ยมเพชรพลอยที่ซับซ้อน เช่นตัวอย่างที่ฉันแชร์ข้างต้น เราพบว่าหน้าเว็บจำนวนมากนี้เป็นปัญหาที่สำคัญ สำหรับการทดสอบดังกล่าว เราทำงานร่วมกับลูกค้าเพื่อใช้งานการนำทางแบบเหลี่ยมเพชรพลอยส่วนใหญ่ใน AJAX เพื่อให้ Google มองไม่เห็นการมีอยู่ของหน้าการนำทางแบบเหลี่ยมเพชรพลอยส่วนใหญ่ แต่ผู้ใช้ยังคงเข้าถึงได้ง่าย จำนวนหน้าสำหรับไซต์นี้เปลี่ยนจาก 200 ล้านหน้าเป็น 200,000 หน้า - ลดลงหนึ่งพันหน้า ในปีหน้า การเข้าชมไซต์เพิ่มขึ้นสามเท่า ซึ่งเป็นผลลัพธ์ที่ดีอย่างน่าอัศจรรย์ อย่างไรก็ตาม การจราจรลดลงในตอนแรก และใช้เวลาประมาณ 4 เดือนกว่าจะกลับสู่ระดับก่อนหน้า จากนั้นจึงไต่ขึ้นจากที่นั่น
ในอีกสถานการณ์หนึ่ง ฉันเห็นว่าไซต์ใช้แพลตฟอร์มอีคอมเมิร์ซใหม่และจำนวนหน้าเพิ่มขึ้นจากประมาณ 5,000 หน้าเป็นมากกว่า 1 ล้านหน้า การจราจรของพวกเขาลดลงและเราถูกนำตัวเข้าไปช่วยพวกเขาฟื้นตัว การแก้ไข? เพื่อนำหน้าที่สามารถจัดทำดัชนีได้นับถอยหลังอีกครั้งไปยังตำแหน่งที่เคยเป็นมาก่อน น่าเสียดาย เนื่องจากใช้เครื่องมืออย่างเช่น แท็ก NoIndex และ Canonical ความเร็วในการกู้คืนจึงได้รับผลกระทบอย่างมากจากเวลาที่ Google ใช้เพื่อเข้าชมหน้าเว็บจำนวนมากบนไซต์อีกครั้ง
ในทั้งสองกรณี ผลลัพธ์สำหรับบริษัทที่เกี่ยวข้องนั้นขับเคลื่อนโดยงบประมาณการรวบรวมข้อมูลของ Google และเวลาที่ใช้ในการรวบรวมข้อมูลที่เพียงพอเพื่อทำความเข้าใจโครงสร้างใหม่ของเว็บไซต์ การมีคำสั่งใน Robots.txt จะทำให้กระบวนการประเภทนี้เร็วขึ้น
อะไรคือข้อเสียของความคิดนี้?
ฉันมีโอกาสหารือเรื่องนี้กับ Patrick Stox ที่ปรึกษาผลิตภัณฑ์และแบรนด์แอมบาสเดอร์ของ Ahrefs และข้อคิดเห็นอย่างรวดเร็วของเขาคือ: "ฉันไม่คิดว่าจะเกิดขึ้นภายใน robots.txt อย่างน้อย บางทีอาจอยู่ในระบบอื่นเช่น GSC Google ชัดเจนว่าต้องการใช้ robots.txt สำหรับการควบคุมการรวบรวมข้อมูลเท่านั้น ข้อเสียที่ใหญ่ที่สุดน่าจะเป็นคนที่เผลอเอาเว็บไซต์ทั้งหมดออกจากดัชนี”
และแน่นอน ปัญหาของทั้งไซต์ (หรือส่วนสำคัญของไซต์) ที่ถูกนำออกจากดัชนีนี้เป็นปัญหาใหญ่ ทั่วทั้งขอบเขตของเว็บ เราไม่ต้องตั้งคำถามว่าสิ่งนี้จะเกิดขึ้นหรือไม่ — มันจะเกิดขึ้น น่าเศร้าที่มันมีแนวโน้มที่จะเกิดขึ้นกับบางเว็บไซต์ที่สำคัญและน่าเสียดายที่มันอาจเกิดขึ้นมากมาย
จากประสบการณ์ของฉันตลอด 20 ปีในการทำ SEO ฉันพบว่าความเข้าใจผิดเกี่ยวกับวิธีใช้แท็ก SEO ต่างๆ นั้นเกิดขึ้นอย่างมากมาย ตัวอย่างเช่น ย้อนกลับไปในวันที่ Google Authorship มีความสำคัญและเรามีแท็ก rel=author ฉันได้ศึกษาว่าไซต์ใช้งานได้ดีเพียงใด และพบว่า 72% ของไซต์ใช้แท็กอย่างไม่ถูกต้อง ซึ่งรวมถึงไซต์ที่มีชื่อเสียงในอุตสาหกรรมของเราด้วย!
ในการสนทนาของฉันกับ Stox เขาตั้งข้อสังเกตเพิ่มเติมว่า: "เมื่อคิดถึงข้อเสียที่มากขึ้น พวกเขาต้องหาวิธีจัดการกับมันเมื่อไฟล์ robots.txt ไม่พร้อมใช้งานชั่วคราว พวกเขาเริ่มสร้างดัชนีหน้าเว็บที่ถูกทำเครื่องหมายว่าไม่มีดัชนีมาก่อนหรือไม่”
ฉันยังติดต่อ Google เพื่อขอความคิดเห็น และถูกชี้ไปที่บล็อกโพสต์ของพวกเขาเมื่อพวกเขาเลิกสนับสนุน noindex ใน robots.txt ในปี 2014 นี่คือสิ่งที่โพสต์กล่าวถึงเรื่องนี้:
“ในขณะที่โอเพ่นซอร์สไลบรารี parser ของเรา เราได้วิเคราะห์การใช้กฎของ robots.txt โดยเฉพาะอย่างยิ่ง เราเน้นที่กฎที่อินเทอร์เน็ตไม่รองรับ เช่น ความล่าช้าในการรวบรวมข้อมูล nofollow และ noindex เนื่องจากกฎเหล่านี้ไม่เคยมีการบันทึกโดย Google การใช้งานที่เกี่ยวข้องกับ Googlebot จึงต่ำมาก เมื่อพิจารณาเพิ่มเติม เราพบว่าการใช้งานของพวกเขาขัดแย้งกับกฎอื่นๆ ทั้งหมดยกเว้น 0.001% ของไฟล์ robots.txt ทั้งหมดบนอินเทอร์เน็ต ข้อผิดพลาดเหล่านี้ส่งผลเสียต่อการปรากฏตัวของเว็บไซต์ในผลการค้นหาของ Google ในแบบที่เราไม่คิดว่าผู้ดูแลเว็บตั้งใจไว้ “
* ตัวหนาของประโยคสุดท้ายโดยฉันทำเพื่อเน้น

ฉันคิดว่านี่เป็นปัจจัยขับเคลื่อนที่นี่ Google ดำเนินการเพื่อปกป้องคุณภาพของดัชนีและสิ่งที่ดูเหมือนเป็นความคิดที่ดีอาจมีผลที่ไม่คาดคิดมากมาย โดยส่วนตัวแล้ว ฉันชอบที่จะมีความสามารถในการทำเครื่องหมายหน้าสำหรับทั้ง NoCrawl และ NoIndex ด้วยวิธีที่ชัดเจนและง่ายดาย แต่ความจริงของเรื่องนี้ก็คือ ฉันไม่คิดว่ามันจะเกิดขึ้น
ผลการสำรวจความคิดเห็นของ robots.txt โดยรวม
อันดับแรก ฉันต้องการรับทราบข้อบกพร่องในแบบสำรวจในคำถามข้อ 2 ซึ่งเป็นคำถามบังคับ โดยถือว่าคุณตอบคำถามที่ 1 ด้วยคำว่า "ใช่" โชคดีที่คนส่วนใหญ่ที่ตอบว่า “ไม่” ในคำถามที่ 1 คลิกที่ “อื่นๆ” สำหรับคำถามที่ 2 แล้วป้อนเหตุผลว่าทำไมพวกเขาถึงไม่ต้องการความสามารถนี้ หนึ่งในคำตอบเหล่านั้นสังเกตเห็นข้อบกพร่องนี้และกล่าวว่า "แบบสำรวจความคิดเห็นของคุณทำให้เข้าใจผิด" ฉันขอโทษสำหรับข้อบกพร่องที่นั่น
ผลลัพธ์โดยรวมมีดังนี้:
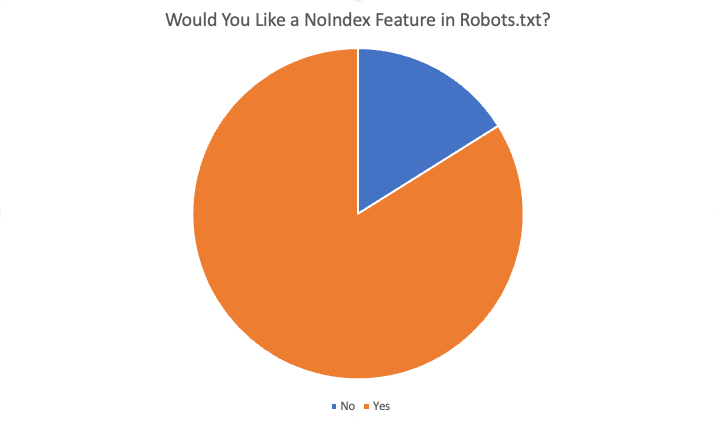
โดยรวมแล้ว 84% ของผู้ตอบแบบสอบถาม 87 คนตอบว่า "ใช่" พวกเขาต้องการคุณลักษณะนี้ เหตุผลบางประการที่เสนอให้ต้องการคุณลักษณะนี้คือ:
- ไม่มีสถานการณ์ใดที่ฉันต้องการบล็อกการรวบรวมข้อมูลแต่มีการจัดทำดัชนีหน้าเว็บ
- การไม่สร้างดัชนีของหน้าจำนวนมากใช้เวลานานเนื่องจาก Google ต้องรวบรวมข้อมูลหน้าเพื่อดู noindex เมื่อเรามีคำสั่ง noindex เราก็สามารถบรรลุผลลัพธ์ที่รวดเร็วยิ่งขึ้นสำหรับลูกค้าที่มีปัญหาการทำดัชนีเกิน
- เรามีปัญหาขยะแขยงมาก...เนื้อหาเก่ามาก...ไดเรกทอรีเก่าและไดเรกทอรีย่อยหลายร้อยรายการ และดูเหมือนต้องใช้เวลาหลายเดือนหากไม่ใช่หลายปีกว่าจะเลิกสร้างดัชนีเหล่านี้เมื่อเราลบและใช้งาน 404 รายการเหล่านั้น ดูเหมือนว่าเราสามารถเพิ่มกฎ NoIndex ในไฟล์ robots.txt และเชื่อว่า Google จะปฏิบัติตามคำแนะนำนี้เร็วกว่าการรวบรวมข้อมูล URL เก่าทั้งหมดเมื่อเวลาผ่านไป …และซ้ำแล้วซ้ำเล่า…เพื่อค้นหาการทำซ้ำ 404 เพื่อลบออกในที่สุด…ดังนั้น การล้างโดเมนของเราเป็นวิธีหนึ่งที่จะช่วยได้
- ประหยัดความพยายามในการพัฒนาและปรับเปลี่ยนได้ง่ายหากมีสิ่งผิดปกติเนื่องจากการเปลี่ยนแปลง
- ไม่สามารถใช้ “noindex” ได้เสมอ และมีการจัดทำดัชนีหน้าเว็บที่ไม่ควรจัดทำดัชนีมากเกินไป การบล็อกมาตรฐานสำหรับแมงมุมควร "ไม่สร้างดัชนี" หน้าอย่างน้อย หากฉันต้องการให้เครื่องมือค้นหาไม่รวบรวมข้อมูล URL/โฟลเดอร์ เหตุใดฉันจึงต้องการให้เครื่องมือค้นหาจัดทำดัชนีหน้า "ว่าง" เหล่านี้
- การเพิ่มคำแนะนำใหม่ให้กับไฟล์ .txt นั้นเร็วกว่าการรับทรัพยากรของ Dev
- ใช่ เป็นการยากที่จะเปลี่ยน meta ในหัวสำหรับ CRM ขององค์กร ดังนั้นคุณลักษณะ noindex แต่ละรายการใน robots.txt จะแก้ปัญหานั้นได้
- การบล็อกการจัดทำดัชนีเว็บไซต์ที่เร็วกว่าและมีปัญหาน้อยกว่า :)
เหตุผลอื่นๆ ที่บอกว่าไม่รวม:
- แท็ก Noindex ดีพอ
- ไม่จำเป็นต้องใช้คำสั่งใหม่ในไฟล์ robots.txt
- ฉันไม่ต้องการมันและไม่เห็นมันทำงาน
- อย่ากวน
- ห้ามเปลี่ยน
สรุป
ที่นั่นคุณมีมัน คนส่วนใหญ่ที่ตอบแบบสำรวจนี้ชอบที่จะเพิ่มคุณลักษณะนี้ อย่างไรก็ตาม โปรดทราบว่าผู้อ่านสำหรับ SEL ประกอบด้วยผู้ชมที่มีความรู้สูง โดยมีความเข้าใจและความเชี่ยวชาญมากกว่าผู้ดูแลเว็บทั่วไป นอกจากนี้ แม้จะตอบใช่ในแบบสำรวจความคิดเห็น ก็ยังมีคำตอบสำหรับคำถามที่ 4 (“คุณลักษณะนี้จะเป็นประโยชน์กับคุณในฐานะ SEO หรือไม่ ถ้าเป็นเช่นนั้น อย่างไร”) ที่บ่งชี้ถึงความเข้าใจผิดเกี่ยวกับวิธีการทำงานของระบบปัจจุบัน
แม้ว่าในท้ายที่สุดแล้ว แม้ว่าโดยส่วนตัวแล้วฉันชอบที่จะมีคุณลักษณะนี้ แต่ก็ไม่น่าจะเกิดขึ้นได้มากนัก
ความคิดเห็นที่แสดงในบทความนี้เป็นความคิดเห็นของผู้เขียนรับเชิญและไม่จำเป็นต้องเป็น Search Engine Land ผู้เขียนพนักงานอยู่ที่นี่