
Nous avons demandé, vous avez répondu : Google devrait-il ajouter la prise en charge de noindex à robots.txt ? Résultats du sondage
Publié: 2021-10-05En septembre, j'ai mis en place un sondage ici sur Search Engine Land pour voir si les lecteurs aimeraient avoir une instruction dans robots.txt pour marquer les pages pour aucune indexation. Aujourd'hui, je présenterai les résultats ainsi qu'un examen des principaux problèmes (et pourquoi Google n'ajoutera pas de support pour cela).
- Pourquoi cela aurait-il un intérêt ?
- Quels sont les inconvénients de cette idée ?
- Résultats globaux du sondage robots.txt
Pourquoi cela aurait-il un intérêt ?
Dans l'environnement actuel, robots.txt est utilisé exclusivement pour guider le comportement de l'exploration Web. De plus, l'approche actuelle pour marquer une page "NoIndex" consiste à placer une balise sur la page elle-même. Malheureusement, si vous le bloquez dans robots.txt, Google ne verra jamais la balise et pourrait toujours potentiellement indexer la page même si vous ne voulez pas que cela se produise.
Sur les grands sites, cela présente certains défis lorsque vous avez différentes catégories de pages que vous souhaitez à la fois bloquer l'exploration ET garder hors de l'index Google. Cela peut se produire notamment dans les implémentations de navigation à facettes complexes où vous avez des pages que vous créez qui ont une valeur significative pour les utilisateurs mais qui finissent par présenter beaucoup trop de pages à Google. Par exemple, j'ai consulté le site Web d'un détaillant de chaussures et j'ai découvert qu'il contenait plus de 70 000 pages différentes liées aux "chaussures Nike pour hommes". Cela comprend une grande variété de tailles, de largeurs, de couleurs et plus encore.
Dans certains tests auxquels j'ai participé avec des sites avec une navigation complexe à facettes comme l'exemple que j'ai partagé ci-dessus, nous avons trouvé que cette grande quantité de pages était un problème important. Pour l'un de ces tests, nous avons travaillé avec un client pour implémenter la plupart de sa navigation à facettes dans AJAX afin que la présence de la plupart de ses pages de navigation à facettes soit invisible pour Google mais toujours facilement accessible par les utilisateurs. Le nombre de pages de ce site est passé de 200 millions de pages à 200 000 pages, soit une réduction de mille à une. Au cours de l'année suivante, le trafic vers le site a triplé - un résultat étonnamment bon. Cependant, le trafic a initialement diminué et il a fallu environ 4 mois pour revenir aux niveaux antérieurs, puis il a grimpé à partir de là.
Dans un autre scénario, j'ai vu un site mettre en place une nouvelle plate-forme de commerce électronique et son nombre de pages est passé d'environ 5 000 pages à plus d'un million. Leur trafic a chuté et nous avons été appelés pour les aider à se rétablir. Le correctif ? Pour ramener le compte à rebours de la page indexable à l'endroit où il se trouvait auparavant. Malheureusement, comme cela a été fait avec des outils comme NoIndex et les balises canoniques, la vitesse de récupération a été largement affectée par le temps qu'il a fallu à Google pour revisiter un nombre important de pages sur le site.
Dans les deux cas, les résultats pour les entreprises impliquées ont été déterminés par le budget d'exploration de Google et le temps qu'il a fallu pour effectuer suffisamment d'exploration pour bien comprendre la nouvelle structure du site. Avoir une instruction dans Robots.txt accélérerait rapidement ces types de processus.
Quels sont les inconvénients de cette idée ?
J'ai eu l'occasion d'en discuter avec Patrick Stox, conseiller produit et ambassadeur de la marque pour Ahrefs, et sa réponse rapide a été : "Je ne pense tout simplement pas que cela se produira au moins dans robots.txt, peut-être dans un autre système comme GSC. Google a clairement indiqué qu'il ne voulait robots.txt que pour le contrôle de l'exploration. Le plus gros inconvénient sera probablement toutes les personnes qui retireront accidentellement l'intégralité de leur site de l'index.
Et bien sûr, cette question de l'intégralité du site (ou des parties clés d'un site) retirée de l'index est le gros problème avec cela. Dans toute la portée du Web, nous n'avons pas à nous demander si cela se produira ou non - cela se produira. Malheureusement, cela risque d'arriver avec certains sites importants, et malheureusement, cela arrivera probablement beaucoup.
Dans mon expérience de 20 ans de référencement, j'ai constaté qu'un malentendu sur la façon d'utiliser diverses balises de référencement est endémique. Par exemple, à l'époque où Google Authorship était une chose et que nous avions des balises rel=author, j'ai fait une étude sur la façon dont les sites les implémentaient et j'ai constaté que 72 % des sites avaient utilisé les balises de manière incorrecte. Cela comprenait des sites très connus dans notre industrie !
Dans ma discussion avec Stox, il a ajouté : « En pensant à d'autres inconvénients, ils doivent trouver comment le traiter lorsqu'un fichier robots.txt n'est pas disponible temporairement. Est-ce qu'ils commencent soudainement à indexer des pages qui étaient marquées sans index auparavant ? »
J'ai également contacté Google pour obtenir des commentaires, et j'ai été pointé vers leur article de blog lorsqu'ils ont abandonné la prise en charge de noindex dans robots.txt en 2014. Voici ce que l'article disait à ce sujet :

"Lors de l'open source de notre bibliothèque d'analyseurs, nous avons analysé l'utilisation des règles robots.txt. En particulier, nous nous sommes concentrés sur les règles non prises en charge par le brouillon Internet, telles que crawl-delay, nofollow et noindex. Étant donné que ces règles n'ont jamais été documentées par Google, leur utilisation par rapport à Googlebot est naturellement très faible. En creusant plus loin, nous avons vu que leur utilisation était contredite par d'autres règles dans tous les fichiers robots.txt sauf 0,001 % sur Internet. Ces erreurs nuisent à la présence des sites Web dans les résultats de recherche de Google d'une manière qui, selon nous, n'est pas prévue par les webmasters. "
* Le gras de la dernière phrase par moi a été fait pour l'emphase.
Je pense que c'est le facteur déterminant ici. Google agit pour protéger la qualité de son index et ce qui peut sembler être une bonne idée peut avoir de nombreuses conséquences imprévues. Personnellement, j'aimerais avoir la possibilité de marquer des pages pour NoCrawl et NoIndex de manière claire et simple, mais la vérité est que je ne pense pas que cela se produira.
Résultats globaux du sondage robots.txt
Tout d'abord, j'aimerais reconnaître une faille dans l'enquête dans cette question 2, une question obligatoire, supposant que vous avez répondu à la question 1 par « oui ». Heureusement, la plupart des personnes qui ont répondu « non » à la question 1 ont cliqué sur « Autre » pour la question 2, puis ont indiqué la raison pour laquelle elles ne souhaitaient pas cette fonctionnalité. L'une de ces réponses a noté cette faille et a déclaré: "Votre sondage est trompeur." Mes excuses pour la faille là-bas.
Les résultats globaux étaient les suivants :
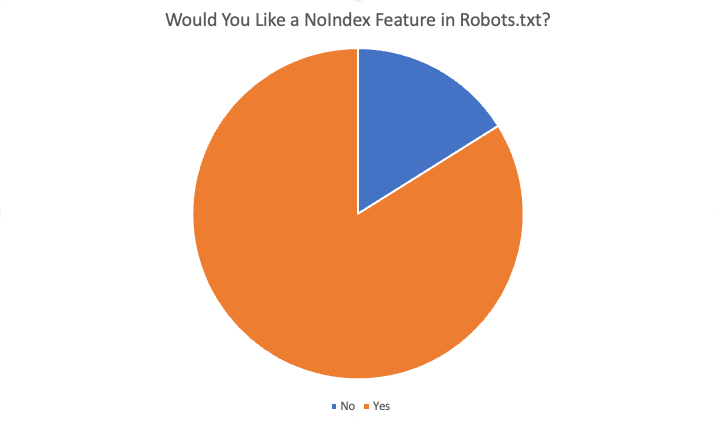
Au total, 84 % des 87 répondants ont répondu "oui", ils aimeraient cette fonctionnalité. Certaines des raisons invoquées pour vouloir cette fonctionnalité étaient :
- Il n'y a aucune situation où je veux bloquer l'exploration mais avoir des pages indexées.
- Noindexer un grand nombre de pages prend beaucoup de temps car Google doit crawler la page pour voir le noindex. Lorsque nous avions la directive noindex, nous pouvions obtenir des résultats plus rapides pour les clients ayant des problèmes de surindexation.
- Nous avons un problème très important… un contenu très ancien… des centaines d'anciens répertoires et sous-répertoires et il faut apparemment des mois, voire des années, pour les désindexer une fois que nous les avons supprimés et ergo 404. Il semble que nous pourrions simplement ajouter la règle NoIndex dans le fichier robots.txt et croire que Google respecterait cette instruction beaucoup plus rapidement que d'avoir à explorer toutes les anciennes URL au fil du temps… et à plusieurs reprises… pour trouver des répétitions 404 pour finalement les supprimer… alors , le nettoyage de nos domaines est une façon d'aider.
- Économisez l'effort de développement et facilement ajustable si quelque chose se casse à cause de changements
- Impossible d'utiliser toujours un "noindex" et trop de pages indexées qui ne devraient pas l'être. Le blocage standard pour spider devrait également "noindexer" les pages au moins. Si je veux qu'un moteur de recherche n'explore pas une URL/un dossier, pourquoi voudrais-je qu'il indexe ces pages "vides" ?
- Ajouter de nouvelles instructions à un fichier .txt est beaucoup plus rapide que d'obtenir des ressources de développement
- Oui, il est difficile de changer la méta dans la tête du CRM d'entreprise, donc la fonctionnalité noindex individuelle dans robots.txt résoudrait ce problème.
- Blocage d'indexation de site plus rapide et moins problématique :)
Autres raisons de dire non :
- La balise Noindex est assez bonne
- Les nouvelles directives dans le fichier robots.txt ne sont pas nécessaires
- Je n'en ai pas besoin et je ne le vois pas fonctionner
- Ne vous embêtez pas
- Ne changez pas
Sommaire
Voilà. La plupart des personnes qui ont répondu à ce sondage sont favorables à l'ajout de cette fonctionnalité. Cependant, gardez à l'esprit que le lectorat de SEL se compose d'un public très bien informé - avec beaucoup plus de compréhension et d'expertise que le webmaster moyen. De plus, même parmi les réponses positives reçues dans le sondage, il y avait des réponses à la question 4 (« cette fonctionnalité vous serait-elle bénéfique en tant que référenceur ? Si oui, comment ») qui indiquaient une mauvaise compréhension du fonctionnement du système actuel.
En fin de compte, même si j'aimerais personnellement avoir cette fonctionnalité, il est très peu probable qu'elle se produise.
Les opinions exprimées dans cet article sont celles de l'auteur invité et pas nécessairement Search Engine Land. Les auteurs du personnel sont répertoriés ici.