
Am întrebat, ați răspuns: Google ar trebui să adauge suport pentru noindex la robots.txt? Rezultatele sondajului
Publicat: 2021-10-05În septembrie, am făcut un sondaj aici pe Search Engine Land pentru a vedea dacă cititorii ar dori să primească instrucțiuni în robots.txt pentru a marca paginile fără indexare. Astăzi voi prezenta rezultatele împreună cu o revizuire a problemelor cheie (și de ce Google nu va adăuga suport pentru acest lucru).
- De ce ar fi acest lucru de interes?
- Care sunt dezavantajele acestei idei?
- Rezultatele generale ale sondajului robots.txt
De ce ar fi acest lucru de interes?
În mediul actual, robots.txt este folosit exclusiv pentru a ghida comportamentul accesării cu crawlere pe web. În plus, abordarea actuală pentru marcarea unei pagini „NoIndex” este de a plasa o etichetă pe pagina însăși. Din păcate, dacă îl blocați în robots.txt, Google nu va vedea niciodată eticheta și ar putea totuși să indexeze pagina, chiar dacă nu doriți să se întâmple asta.
Pe site-urile mari, acest lucru prezintă unele provocări atunci când aveți diferite clase de pagini pe care doriți să le blocați și să nu accesați cu crawlere indexul Google. O modalitate prin care acest lucru se poate întâmpla este în implementările complexe de navigare cu fațete, în care aveți pagini pe care le creați care au o valoare semnificativă pentru utilizatori, dar ajung să prezinte mult prea multe pagini pentru Google. De exemplu, m-am uitat pe site-ul web al unui comerciant cu amănuntul de pantofi și am descoperit că are peste 70.000 de pagini diferite legate de „Pantofi Nike pentru bărbați”. Aceasta include o mare varietate de dimensiuni, lățimi, culori și multe altele.
În unele teste la care am participat cu site-uri cu navigare complexă cu fațete, cum ar fi exemplul pe care l-am împărtășit mai sus, am constatat că această cantitate mare de pagini este o problemă semnificativă. Pentru unul dintre aceste teste, am lucrat cu un client pentru a implementa cea mai mare parte a navigației lor fațetate în AJAX, astfel încât prezența celor mai multe dintre paginile lor de navigare cu fațete a fost invizibilă pentru Google, dar totuși ușor accesată de utilizatori. Numărul de pagini pentru acest site a trecut de la 200 de milioane de pagini la 200 de mii de pagini – o reducere de o mie la una. În anul următor, traficul către site sa triplat – un rezultat uimitor de bun. Cu toate acestea, traficul a scăzut inițial și a durat aproximativ 4 luni pentru a reveni la nivelurile anterioare și apoi a urcat de acolo.
Într-un alt scenariu, am văzut un site implementând o nouă platformă de comerț electronic, iar numărul lor de pagini a crescut de la aproximativ 5.000 de pagini la mai mult de 1 milion. Traficul lor a scăzut și am fost aduși să-i ajutăm să-și revină. Remedierea? Pentru a aduce numărul de pagini indexabile înapoi la locul în care era înainte. Din păcate, deoarece acest lucru a fost realizat cu instrumente precum NoIndex și etichetele Canonical, viteza de recuperare a fost în mare măsură afectată de timpul în care a fost nevoie de Google pentru a revizui un număr semnificativ de pagini de pe site.
În ambele cazuri, rezultatele pentru companiile implicate au fost determinate de bugetul de accesare cu crawlere al Google și de timpul necesar pentru a trece cu crawling suficient pentru a înțelege pe deplin noua structură a site-ului. A avea o instrucțiune în Robots.txt ar accelera rapid aceste tipuri de procese.
Care sunt dezavantajele acestei idei?
Am avut ocazia să discut despre asta cu Patrick Stox, consilier de produs și ambasador al mărcii pentru Ahrefs, iar ideea sa rapidă a fost: „Nu cred că se va întâmpla cel puțin în robots.txt, poate într-un alt sistem precum GSC. Google a fost clar că vrea robots.txt numai pentru controlul accesării cu crawlere. Cel mai mare dezavantaj va fi probabil toți oamenii care își scot accidental întregul site din index.”
Și, desigur, această problemă a întregului site (sau părți cheie ale unui site) care este scoasă din index este marea problemă a acestuia. Pe întregul domeniu al web-ului, nu trebuie să ne întrebăm dacă acest lucru se va întâmpla sau nu - se va întâmpla. Din păcate, este posibil să se întâmple cu unele site-uri importante și, din păcate, probabil se va întâmpla foarte mult.
În experiența mea de 20 de ani de SEO, am descoperit că o neînțelegere a modului de utilizare a diferitelor etichete SEO este răspândită. De exemplu, pe vremea când Google Authorship era un lucru și aveam etichete rel=author, am făcut un studiu despre cât de bine le implementau site-urile și am descoperit că 72% dintre site-uri au folosit etichetele incorect. Acestea au inclus câteva site-uri cu adevărat cunoscute în industria noastră!
În discuția mea cu Stox, el a mai spus: „Gândindu-se la mai multe dezavantaje, trebuie să-și dea seama cum să o trateze atunci când un fișier robots.txt nu este disponibil temporar. Încep brusc să indexeze paginile care au fost marcate înainte ca noindex?”
De asemenea, am contactat Google pentru comentarii și am fost indicat la postarea lor de pe blog când au renunțat la suportul pentru noindex în robots.txt în 2014. Iată ce spunea postarea despre această problemă:

„În timp ce ne-am deschis biblioteca de analize, am analizat utilizarea regulilor robots.txt. În special, ne-am concentrat asupra regulilor neacceptate de proiectul de internet, cum ar fi crawl-delay, nofollow și noindex. Deoarece aceste reguli nu au fost niciodată documentate de Google, desigur, utilizarea lor în raport cu Googlebot este foarte scăzută. Săpând mai departe, am văzut că utilizarea lor a fost contrazisă de alte reguli în toate fișierele robots.txt de pe internet, cu excepția 0,001%. Aceste greșeli afectează prezența site-urilor web în rezultatele căutării Google în moduri pe care nu credem că webmasterii au vrut. „
* Sublinierea ultimei propoziții a fost făcută de mine pentru a sublinia.
Cred că acesta este factorul motor aici. Google acționează pentru a proteja calitatea indexului său și ceea ce poate părea o idee bună poate avea multe consecințe nedorite. Personal, mi-ar plăcea să am capacitatea de a marca pagini atât pentru NoCrawl, cât și pentru NoIndex într-un mod clar și ușor, dar adevărul este că nu cred că se va întâmpla.
Rezultatele generale ale sondajului robots.txt
În primul rând, aș dori să recunosc un defect al sondajului la întrebarea 2, o întrebare obligatorie, presupunând că ați răspuns la întrebarea 1 cu un „da”. Din fericire, majoritatea oamenilor care au răspuns „nu” la întrebarea 1 au făcut clic pe „Altul” pentru întrebarea 2 și apoi au introdus un motiv pentru care nu și-au dorit această capacitate. Unul dintre aceste răspunsuri a notat acest defect și a spus: „Sondajul tău este înșelător”. Scuzele mele pentru defectul de acolo.
Rezultatele generale au fost următoarele:
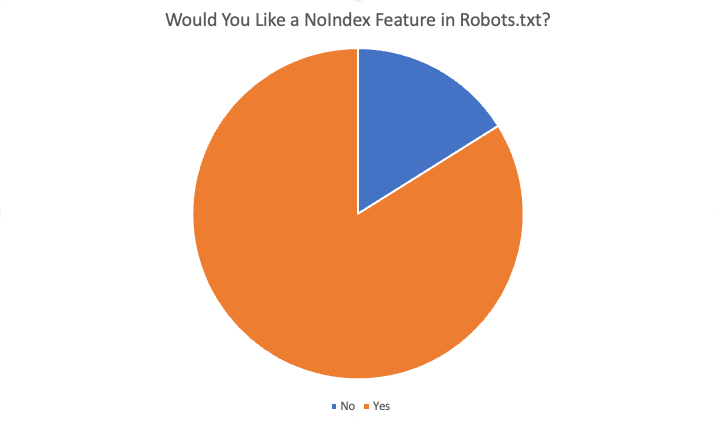
În total, 84% dintre cei 87 de respondenți au spus „da”, ar dori această funcție. Unele dintre motivele oferite pentru a dori această funcție au fost:
- Nu există situații în care vreau să blochez accesarea cu crawlere, dar să am pagini indexate.
- Noindexarea unui număr mare de pagini necesită mult timp, deoarece Google trebuie să acceseze cu crawlere pagina pentru a vedea noindexul. Când am avut directiva noindex, am putut obține rezultate mai rapide pentru clienții cu probleme de supraindexare.
- Avem o problemă foarte mare... conținut foarte vechi... sute de directoare și subdirectoare vechi și este nevoie aparent de luni, dacă nu de ani, pentru a le de-indexa, odată ce le ștergem și ergo 404. Se pare că am putea doar să adăugăm regula NoIndex în fișierul robots.txt și să credem că Google va respecta această instrucțiune mult mai repede decât a trebui să acceseze cu crawlere toate vechile URL-uri de-a lungul timpului... și în mod repetat... pentru a găsi repetarea 404 pentru a le șterge în cele din urmă... , curățarea domeniilor noastre este o modalitate de a ajuta.
- Economisiți efortul de dezvoltare și ușor de ajustat dacă ceva se rupe din cauza modificărilor
- Nu se poate folosi întotdeauna un „noindex” și prea multe pagini indexate care nu ar trebui să fie indexate. Blocarea standard pentru spider ar trebui, de asemenea, să „nu indexeze” paginile cel puțin. Dacă vreau ca un motor de căutare să nu acceseze cu crawlere o adresă URL/dosar, de ce aș vrea să indexeze aceste pagini „goale”?
- Adăugarea de instrucțiuni noi la un fișier .txt este mult mai rapidă decât obținerea resurselor Dev
- Da, este greu să schimbi meta în cap pentru CRM pentru întreprinderi, așa că funcția individuală noindex din robots.txt ar rezolva această problemă.
- Blocare mai rapidă și mai puțin problematică a indexării site-ului :)
Alte motive pentru a spune nu au inclus:
- Eticheta Noindex este suficient de bună
- Noile directive în fișierul robots.txt nu sunt necesare
- Nu am nevoie de el și nu văd că funcționează
- Nu te deranja
- Nu schimba
rezumat
Iată-l. Majoritatea persoanelor care au răspuns la acest sondaj sunt în favoarea adăugării acestei funcții. Cu toate acestea, rețineți că cititorii pentru SEL constă dintr-un public foarte bine informat - cu mult mai multă înțelegere și expertiză decât un webmaster obișnuit. În plus, chiar și printre răspunsurile da primite în sondaj, au existat câteva răspunsuri la întrebarea 4 („Te-ar beneficia această caracteristică ca SEO? Dacă da, cum”) care au indicat o înțelegere greșită a modului în care funcționează sistemul actual.
În cele din urmă, totuși, deși personal mi-ar plăcea să am această funcție, este foarte puțin probabil să se întâmple.
Opiniile exprimate în acest articol sunt cele ale autorului invitat și nu neapărat Search Engine Land. Autorii personalului sunt enumerați aici.