
我们问,你回答:谷歌是否应该向 robots.txt 添加 noindex 支持? 投票结果
已发表: 2021-10-059 月,我在 Search Engine Land 上进行了一项民意调查,看看读者是否愿意在 robots.txt 中有一条指令,以将页面标记为无索引。 今天我将介绍结果以及对关键问题的回顾(以及为什么 Google 不会为此添加支持)。
- 为什么会引起兴趣?
- 这个想法的缺点是什么?
- 整体 robots.txt 民意调查结果
为什么会引起兴趣?
在当前环境下,robots.txt 专门用于指导网络爬取行为。 此外,当前标记页面“NoIndex”的方法是在页面本身上放置一个标签。 不幸的是,如果您在 robots.txt 中阻止它,Google 将永远不会看到该标签,并且即使您不希望这种情况发生,它仍然可能会将该页面编入索引。
在大型网站上,如果您有不同类别的网页,您既想阻止抓取又想将其排除在 Google 索引之外,这会带来一些挑战。 发生这种情况的一种方法是在复杂的分面导航实现中,您创建的页面对用户具有重要价值,但最终向 Google 展示了太多页面。 例如,我查看了一家鞋类零售商网站,发现他们有超过 70,000 个与“男士耐克鞋”相关的不同页面。 这包括各种尺寸、宽度、颜色等。
在我参与的一些具有复杂分面导航的网站的测试中,例如我上面分享的示例,我们发现如此大量的页面是一个严重的问题。 对于其中一项测试,我们与客户合作,在 AJAX 中实现了他们的大部分分面导航,因此谷歌看不到他们大部分分面导航页面的存在,但用户仍然可以轻松访问。 该网站的页数从 2 亿页增加到 20 万页——减少了一千比一。 在接下来的一年里,该网站的访问量增加了两倍——这是一个非常好的结果。 然而,流量最初是下降的,大约需要 4 个月的时间才能恢复到之前的水平,然后从那里开始攀升。
在另一个场景中,我看到一个网站实施了一个新的电子商务平台,其页面数从大约 5,000 页飙升至超过 100 万页。 他们的流量急剧下降,我们被请来帮助他们恢复。 修复? 使可索引的页面计数再次下降到以前的位置。 不幸的是,由于这是使用 NoIndex 和 Canonical 标签等工具完成的,因此恢复速度在很大程度上受到谷歌重新访问网站上大量页面的时间的影响。
在这两种情况下,所涉及公司的结果都是由 Google 的抓取预算以及通过足够的抓取以完全了解网站的新结构所花费的时间驱动的。 在 Robots.txt 中有一条指令会迅速加快这些类型的进程。
这个想法的缺点是什么?
我有机会与 Ahrefs 的产品顾问兼品牌大使 Patrick Stox 讨论了这个问题,他的快速反应是:“我只是认为至少在 robots.txt 中不会发生这种情况,可能会在像 GSC 这样的另一个系统中发生。 谷歌很清楚他们只希望 robots.txt 用于抓取控制。 最大的缺点可能是所有不小心将整个网站从索引中删除的人。”
当然,整个站点(或站点的关键部分)从索引中删除的问题是它的大问题。 在整个网络范围内,我们不必质疑这是否会发生——它会发生。 可悲的是,它可能会发生在一些重要的站点上,不幸的是,它可能会发生很多。
在我 20 年的 SEO 经验中,我发现对如何使用各种 SEO 标签的误解十分猖獗。 例如,在 Google Authorship 是一件事并且我们有 rel=author 标签的那一天,我对网站实施它们的情况进行了研究,发现 72% 的网站错误地使用了标签。 其中包括我们行业中一些非常知名的网站!
在我与 Stox 的讨论中,他进一步指出:“考虑到更多的缺点,他们必须弄清楚当 robots.txt 文件暂时不可用时如何处理它。 他们是否突然开始索引以前标记为 noindex 的页面?”
我也联系了谷歌征求意见,当他们在 2014 年放弃对 robots.txt 中 noindex 的支持时,我被指向了他们的博客文章。这是这篇文章对此事的看法:
“在开源我们的解析器库时,我们分析了 robots.txt 规则的使用。 特别是,我们专注于互联网草案不支持的规则,例如 crawl-delay、nofollow 和 noindex。 由于 Google 从未记录过这些规则,因此自然而然地,它们与 Googlebot 相关的使用率非常低。 进一步挖掘,我们发现它们的使用与互联网上所有 robots.txt 文件的 0.001% 之外的所有其他规则相矛盾。 这些错误以我们认为网站管理员不希望出现的方式损害了网站在 Google 搜索结果中的存在。 “
*我最后一句加粗是为了强调。

我认为这是这里的驱动因素。 谷歌采取行动保护其索引的质量,看似不错的想法可能会产生许多意想不到的后果。 就个人而言,我希望能够以一种清晰而简单的方式为 NoCrawl 和 NoIndex 标记页面,但事实是我认为这不会发生。
整体 robots.txt 民意调查结果
首先,我想承认问题 2 中的调查存在缺陷,这是一个必填问题,假设您以“是”回答问题 1。 值得庆幸的是,大多数在问题 1 中回答“否”的人都在问题 2 中单击了“其他”,然后输入了他们不想要此功能的原因。 其中一个回复指出了这个缺陷,并说:“你的民意调查具有误导性。” 我为那里的缺陷道歉。
总体结果如下:
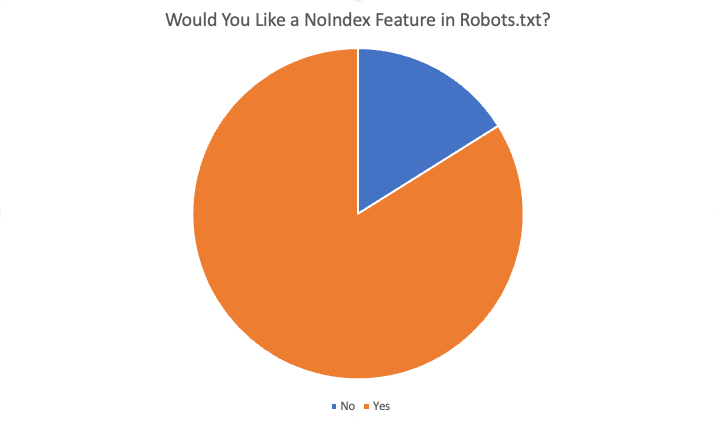
在 87 名受访者中,总共有 84% 的人表示“是”,他们喜欢这个功能。 需要此功能的一些原因是:
- 在任何情况下,我都想阻止爬网但将页面编入索引。
- Noindexing 大量页面需要很长时间,因为 Google 必须抓取页面才能看到 noindex。 当我们有 noindex 指令时,我们可以为存在过度索引问题的客户获得更快的结果。
- 我们有一个非常大的问题......非常旧的内容......数百个旧目录和子目录,一旦我们删除它们并进行 404 处理,似乎需要数月甚至数年才能取消索引。 似乎我们可以在 robots.txt 文件中添加 NoIndex 规则,并相信 Google 会更快地遵守此指令,而不是随着时间的推移不得不抓取所有旧 URL……并且反复……找到重复的 404 以最终删除它们……所以,清理我们的域是一种有用的方法。
- 如果由于更改而出现问题,则可以节省开发工作并轻松调整
- 不能总是使用“noindex”和太多不应该被索引的页面。 蜘蛛的标准阻止也应该至少“noindex”页面。 如果我希望搜索引擎不抓取 URL/文件夹,我为什么要他们索引这些“空”页面?
- 向 .txt 文件添加新指令比获取开发资源要快得多
- 是的,很难更改企业 CRM 中的元数据,因此 robots.txt 中的单个 noindex 功能可以解决这个问题。
- 更快,更少问题的站点索引阻止:)
拒绝的其他原因包括:
- Noindex 标签就够用了
- robots.txt 文件中的新指令不是必需的
- 我不需要它,也没有看到它工作
- 不要打扰
- 不要换
概括
你有它。 对此民意调查做出回应的大多数人都赞成添加此功能。 但是,请记住,SEL 的读者群由知识渊博的受众组成——他们的理解力和专业知识远远超过普通网站管理员。 此外,即使在民意调查中收到的肯定答复中,也有一些对问题 4 的答复(“作为 SEO,此功能对您有帮助吗?如果有,如何”)表明对当前系统的工作方式存在误解。
最终,虽然我个人很想拥有这个功能,但它不太可能发生。
本文中表达的观点是客座作者的观点,不一定是 Search Engine Land。 工作人员作者在这里列出。