
Kami bertanya, Anda menjawab: Haruskah Google menambahkan dukungan noindex ke robots.txt? Hasil polling
Diterbitkan: 2021-10-05Pada bulan September, saya membuat polling di sini di Search Engine Land untuk melihat apakah pembaca ingin memiliki instruksi di robots.txt untuk menandai halaman tanpa Indeksasi. Hari ini saya akan menyajikan hasilnya bersama dengan ulasan tentang apa masalah utamanya (dan mengapa Google tidak menambahkan dukungan untuk ini).
- Mengapa ini menarik?
- Apa kelemahan dari ide ini?
- Hasil polling robots.txt secara keseluruhan
Mengapa ini menarik?
Di lingkungan saat ini, robots.txt digunakan secara eksklusif untuk memandu perilaku perayapan web. Selanjutnya, pendekatan saat ini untuk menandai halaman “NoIndex” adalah dengan menempatkan tag pada halaman itu sendiri. Sayangnya, jika Anda memblokirnya di robots.txt, Google tidak akan pernah melihat tag tersebut dan masih berpotensi mengindeks halaman meskipun Anda tidak ingin hal itu terjadi.
Di situs besar, ini menghadirkan beberapa tantangan ketika Anda memiliki kelas halaman yang berbeda yang ingin Anda blokir dari perayapan DAN jauhkan dari indeks Google. Salah satu cara hal ini dapat terjadi adalah dalam implementasi navigasi segi kompleks di mana Anda memiliki halaman yang Anda buat yang memiliki nilai signifikan bagi pengguna tetapi pada akhirnya menyajikan terlalu banyak halaman ke Google. Misalnya, saya melihat satu situs web pengecer sepatu dan menemukan bahwa mereka memiliki lebih dari 70.000 halaman berbeda yang terkait dengan “Sepatu Nike Pria”. Ini mencakup berbagai macam ukuran, lebar, warna, dan banyak lagi.
Dalam beberapa pengujian yang saya ikuti dengan situs dengan navigasi segi kompleks seperti contoh yang saya bagikan di atas, kami menemukan jumlah halaman yang besar ini menjadi masalah yang signifikan. Untuk salah satu pengujian tersebut, kami bekerja dengan klien untuk mengimplementasikan sebagian besar navigasi faceted mereka di AJAX sehingga keberadaan sebagian besar halaman nav faceted mereka tidak terlihat oleh Google tetapi masih mudah diakses oleh pengguna. Jumlah halaman untuk situs ini berubah dari 200 juta halaman menjadi 200 ribu halaman – pengurangan seribu menjadi satu. Selama tahun berikutnya, lalu lintas ke situs meningkat tiga kali lipat – hasil yang luar biasa bagus. Namun, lalu lintas pada awalnya TURUN, dan butuh sekitar 4 bulan untuk kembali ke level sebelumnya dan kemudian naik dari sana.
Dalam skenario lain, saya melihat sebuah situs menerapkan platform e-niaga baru dan jumlah halaman mereka melonjak dari sekitar 5.000 halaman menjadi lebih dari 1 juta. Lalu lintas mereka anjlok dan kami dibawa untuk membantu mereka pulih. Perbaikannya? Untuk mengembalikan jumlah halaman yang dapat diindeks ke posisi semula. Sayangnya, karena ini dilakukan dengan alat seperti NoIndex dan tag Canonical, kecepatan pemulihan sebagian besar dipengaruhi oleh waktu yang dibutuhkan Google untuk mengunjungi kembali sejumlah besar halaman di situs.
Dalam kedua kasus, hasil untuk perusahaan yang terlibat didorong oleh anggaran perayapan Google dan waktu yang dibutuhkan untuk melewati perayapan yang cukup untuk memahami sepenuhnya struktur baru situs. Memiliki instruksi di Robots.txt akan mempercepat jenis proses ini dengan cepat.
Apa kelemahan dari ide ini?
Saya memiliki kesempatan untuk mendiskusikan hal ini dengan Patrick Stox, Penasihat Produk & duta merek untuk Ahrefs, dan tanggapan singkatnya adalah: “Saya hanya tidak berpikir itu akan terjadi dalam robots.txt setidaknya, mungkin dalam sistem lain seperti GSC. Google jelas bahwa mereka menginginkan robots.txt hanya untuk kontrol perayapan. Kelemahan terbesar mungkin adalah semua orang yang secara tidak sengaja mengeluarkan seluruh situs mereka dari indeks.”
Dan tentu saja, masalah seluruh situs (atau bagian penting dari situs) yang dikeluarkan dari indeks adalah masalah besar dengannya. Di seluruh lingkup web, kita tidak perlu mempertanyakan apakah ini akan terjadi atau tidak — itu AKAN. Sayangnya, itu mungkin terjadi dengan beberapa situs penting, dan sayangnya, itu mungkin akan sering terjadi.
Dalam pengalaman saya selama 20 tahun SEO, saya telah menemukan bahwa kesalahpahaman tentang cara menggunakan berbagai tag SEO merajalela. Misalnya, pada hari ketika Google Authorship adalah sesuatu dan kami memiliki tag rel=author, saya melakukan studi tentang seberapa baik situs menerapkannya dan menemukan bahwa 72% situs telah menggunakan tag secara tidak benar. Itu termasuk beberapa situs yang sangat terkenal di industri kami!
Dalam diskusi saya dengan Stox, dia lebih lanjut mencatat: “Memikirkan lebih banyak kerugian, mereka harus mencari cara untuk menanganinya ketika file robots.txt tidak tersedia untuk sementara. Apakah mereka tiba-tiba mulai mengindeks halaman yang sebelumnya ditandai dengan noindex?”
Saya juga menghubungi Google untuk memberikan komentar, dan saya diarahkan ke posting blog mereka ketika mereka menghentikan dukungan untuk noindex di robots.txt pada tahun 2014. Inilah yang dikatakan posting tentang masalah tersebut:

“Saat membuka perpustakaan parser kami, kami menganalisis penggunaan aturan robots.txt. Secara khusus, kami berfokus pada aturan yang tidak didukung oleh konsep internet, seperti crawl-delay, nofollow, dan noindex. Karena aturan ini tidak pernah didokumentasikan oleh Google, tentu saja, penggunaannya dalam kaitannya dengan Googlebot sangat rendah. Menggali lebih jauh, kami melihat penggunaannya bertentangan dengan aturan lain di semua kecuali 0,001% dari semua file robots.txt di internet. Kesalahan ini merusak kehadiran situs web di hasil penelusuran Google dengan cara yang menurut kami tidak dimaksudkan oleh webmaster. “
* Pencetakan tebal dari kalimat terakhir oleh saya dilakukan untuk penekanan.
Saya pikir ini adalah faktor pendorong di sini. Google bertindak untuk melindungi kualitas indeksnya dan apa yang tampak seperti ide bagus dapat memiliki banyak konsekuensi yang tidak diinginkan. Secara pribadi, saya ingin memiliki kemampuan untuk menandai halaman untuk NoCrawl dan NoIndex dengan cara yang jelas dan mudah, tetapi kenyataannya adalah saya tidak berpikir itu akan terjadi.
Hasil polling robots.txt secara keseluruhan
Pertama, saya ingin mengakui kekurangan dalam survei di pertanyaan 2 itu, pertanyaan wajib, dengan asumsi Anda menjawab pertanyaan 1 dengan "ya". Untungnya, kebanyakan orang yang menjawab “tidak” pada pertanyaan 1 mengklik “Lainnya” untuk pertanyaan 2 dan kemudian memasukkan alasan mengapa mereka tidak menginginkan kemampuan ini. Salah satu tanggapan itu mencatat kekurangan ini dan berkata, “Jajak pendapat Anda menyesatkan.” Saya minta maaf untuk kekurangan di sana.
Hasil keseluruhan adalah sebagai berikut:
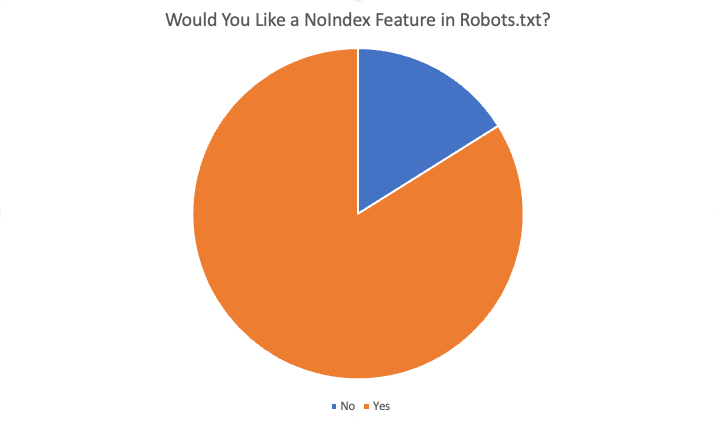
Sebanyak 84% dari 87 responden mengatakan “ya”, mereka menyukai fitur ini. Beberapa alasan yang ditawarkan untuk menginginkan fitur ini adalah:
- Tidak ada situasi di mana saya ingin memblokir perayapan tetapi halaman diindeks.
- Noindexing halaman dalam jumlah besar membutuhkan banyak waktu karena Google harus meng-crawl halaman untuk melihat noindex. Ketika kami memiliki arahan noindex, kami dapat mencapai hasil yang lebih cepat untuk klien dengan masalah indeksasi berlebih.
- Kami memiliki masalah cruft yang sangat besar…konten yang sangat lama…ratusan direktori dan subdirektori lama dan tampaknya membutuhkan waktu berbulan-bulan jika tidak bertahun-tahun untuk menghapus indeks ini setelah kami menghapusnya dan membuat 404 mereka. Sepertinya kita bisa menambahkan aturan NoIndex di file robots.txt dan percaya bahwa Google akan mematuhi instruksi ini lebih cepat daripada harus merayapi semua URL lama dari waktu ke waktu …dan berulang kali…untuk menemukan pengulangan 404 untuk akhirnya menghapusnya…jadi , membersihkan domain kami adalah salah satu cara yang akan membantu.
- Hemat upaya pengembangan dan mudah disesuaikan jika ada yang rusak karena perubahan
- Tidak dapat selalu menggunakan "noindex" dan terlalu banyak halaman yang diindeks yang seharusnya tidak diindeks. Pemblokiran standar untuk spider juga harus "mengindeks" halaman setidaknya. Jika saya ingin mesin pencari tidak merayapi URL/folder, mengapa saya ingin mereka mengindeks halaman "kosong" ini?
- Menambahkan instruksi baru ke file .txt jauh lebih cepat daripada mendapatkan sumber daya Dev
- Ya, sulit untuk mengubah meta di kepala untuk CRM perusahaan sehingga fitur noindex individual di robots.txt akan menyelesaikan masalah itu.
- Pemblokiran pengindeksan situs yang lebih cepat dan tidak terlalu bermasalah :)
Alasan lain untuk mengatakan tidak termasuk:
- Tag Noindex cukup bagus
- Arahan baru dalam file robots.txt tidak diperlukan
- Saya tidak membutuhkannya dan tidak melihatnya bekerja
- Jangan repot-repot
- Jangan berubah
Ringkasan
Di sana Anda memilikinya. Kebanyakan orang yang menanggapi jajak pendapat ini mendukung penambahan fitur ini. Namun, ingatlah bahwa pembaca untuk SEL terdiri dari audiens yang sangat berpengetahuan – dengan pemahaman dan keahlian yang jauh lebih banyak daripada rata-rata webmaster. Selain itu, bahkan di antara jawaban ya yang diterima dalam jajak pendapat, ada beberapa tanggapan untuk pertanyaan 4 ("Apakah fitur ini bermanfaat bagi Anda sebagai SEO? Jika demikian, bagaimana") yang menunjukkan kesalahpahaman tentang cara kerja sistem saat ini.
Namun pada akhirnya, meskipun saya pribadi ingin memiliki fitur ini, itu sangat tidak mungkin terjadi.
Pendapat yang diungkapkan dalam artikel ini adalah dari penulis tamu dan belum tentu Search Engine Land. Penulis staf tercantum di sini.