
我們問,你回答:谷歌是否應該向 robots.txt 添加 noindex 支持? 投票結果
已發表: 2021-10-059 月,我在 Search Engine Land 上進行了一項民意調查,看看讀者是否願意在 robots.txt 中有一條指令,以將頁面標記為無索引。 今天我將介紹結果以及對關鍵問題的回顧(以及為什麼 Google 不會為此添加支持)。
- 為什麼會引起興趣?
- 這個想法的缺點是什麼?
- 整體 robots.txt 民意調查結果
為什麼會引起興趣?
在當前環境下,robots.txt 專門用於指導網絡爬取行為。 此外,當前標記頁面“NoIndex”的方法是在頁面本身上放置一個標籤。 不幸的是,如果您在 robots.txt 中阻止它,Google 將永遠不會看到該標籤,並且即使您不希望這種情況發生,它仍然可能會將該頁面編入索引。
在大型網站上,如果您有不同類別的網頁,您既想阻止抓取又想將其排除在 Google 索引之外,這會帶來一些挑戰。 發生這種情況的一種方法是在復雜的分面導航實現中,您創建的頁面對用戶具有重要價值,但最終向 Google 展示了太多頁面。 例如,我查看了一家鞋類零售商網站,發現他們有超過 70,000 個與“男士耐克鞋”相關的不同頁面。 這包括各種尺寸、寬度、顏色等。
在我參與的一些具有復雜分面導航的網站的測試中,例如我上面分享的示例,我們發現如此大量的頁面是一個嚴重的問題。 對於其中一項測試,我們與客戶合作,在 AJAX 中實現了他們的大部分分面導航,因此谷歌看不到他們大部分分面導航頁面的存在,但用戶仍然可以輕鬆訪問。 該網站的頁數從 2 億頁增加到 20 萬頁——減少了一千比一。 在接下來的一年裡,該網站的訪問量增加了兩倍——這是一個非常好的結果。 然而,流量最初是下降的,大約需要 4 個月的時間才能恢復到之前的水平,然後從那裡開始攀升。
在另一個場景中,我看到一個網站實施了一個新的電子商務平台,其頁面數從大約 5,000 頁飆升至超過 100 萬頁。 他們的流量急劇下降,我們被請來幫助他們恢復。 修復? 使可索引的頁面計數再次下降到以前的位置。 不幸的是,由於這是使用 NoIndex 和 Canonical 標籤等工具完成的,因此恢復速度在很大程度上受到谷歌重新訪問網站上大量頁面的時間的影響。
在這兩種情況下,所涉及公司的結果都是由 Google 的抓取預算以及通過足夠的抓取以完全了解網站的新結構所花費的時間驅動的。 在 Robots.txt 中有一條指令會迅速加快這些類型的進程。
這個想法的缺點是什麼?
我有機會與 Ahrefs 的產品顧問兼品牌大使 Patrick Stox 討論了這個問題,他的快速反應是:“我只是認為至少在 robots.txt 中不會發生這種情況,可能會在像 GSC 這樣的另一個系統中發生。 谷歌很清楚他們只希望 robots.txt 用於抓取控制。 最大的缺點可能是所有不小心將整個網站從索引中刪除的人。”
當然,整個站點(或站點的關鍵部分)從索引中刪除的問題是它的大問題。 在整個網絡範圍內,我們不必質疑這是否會發生——它會發生。 可悲的是,它可能會發生在一些重要的站點上,不幸的是,它可能會發生很多。
在我 20 年的 SEO 經驗中,我發現對如何使用各種 SEO 標籤的誤解十分猖獗。 例如,在 Google Authorship 是一件事並且我們有 rel=author 標籤的那一天,我對網站實施它們的情況進行了研究,發現 72% 的網站錯誤地使用了標籤。 其中包括我們行業中一些非常知名的網站!
在我與 Stox 的討論中,他進一步指出:“考慮到更多的缺點,他們必須弄清楚當 robots.txt 文件暫時不可用時如何處理它。 他們是否突然開始索引以前標記為 noindex 的頁面?”
我也聯繫了谷歌徵求意見,當他們在 2014 年放棄對 robots.txt 中 noindex 的支持時,我被指向了他們的博客文章。這是這篇文章對此事的看法:
“在開源我們的解析器庫時,我們分析了 robots.txt 規則的使用。 特別是,我們專注於互聯網草案不支持的規則,例如 crawl-delay、nofollow 和 noindex。 由於 Google 從未記錄過這些規則,因此自然而然地,它們與 Googlebot 相關的使用率非常低。 進一步挖掘,我們發現它們的使用與互聯網上所有 robots.txt 文件的 0.001% 之外的所有其他規則相矛盾。 這些錯誤以我們認為網站管理員不希望出現的方式損害了網站在 Google 搜索結果中的存在。 “
*我最後一句加粗是為了強調。

我認為這是這裡的驅動因素。 谷歌採取行動保護其索引的質量,看似不錯的想法可能會產生許多意想不到的後果。 就個人而言,我希望能夠以一種清晰而簡單的方式為 NoCrawl 和 NoIndex 標記頁面,但事實是我認為這不會發生。
整體 robots.txt 民意調查結果
首先,我想承認問題 2 中的調查存在缺陷,這是一個必填問題,假設您以“是”回答問題 1。 值得慶幸的是,大多數在問題 1 中回答“否”的人都在問題 2 中單擊了“其他”,然後輸入了他們不想要此功能的原因。 其中一個回復指出了這個缺陷,並說:“你的民意調查具有誤導性。” 我為那裡的缺陷道歉。
總體結果如下:
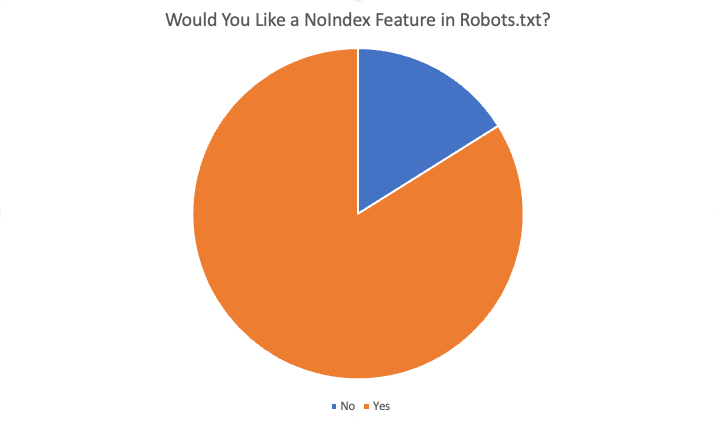
在 87 名受訪者中,總共有 84% 的人表示“是”,他們喜歡這個功能。 需要此功能的一些原因是:
- 在任何情況下,我都想阻止爬網但將頁面編入索引。
- Noindexing 大量頁面需要很長時間,因為 Google 必須抓取頁面才能看到 noindex。 當我們有 noindex 指令時,我們可以為存在過度索引問題的客戶獲得更快的結果。
- 我們有一個非常大的問題......非常舊的內容......數百個舊目錄和子目錄,一旦我們刪除它們並進行 404 處理,似乎需要數月甚至數年才能取消索引。 似乎我們可以在 robots.txt 文件中添加 NoIndex 規則,並相信 Google 會更快地遵守此指令,而不是隨著時間的推移不得不抓取所有舊 URL……並且反复……找到重複的 404 以最終刪除它們……所以,清理我們的域是一種有用的方法。
- 如果由於更改而出現問題,則可以節省開發工作並輕鬆調整
- 不能總是使用“noindex”和太多不應該被索引的頁面。 蜘蛛的標準阻止也應該至少“noindex”頁面。 如果我希望搜索引擎不抓取 URL/文件夾,我為什麼要他們索引這些“空”頁面?
- 向 .txt 文件添加新指令比獲取開發資源要快得多
- 是的,很難更改企業 CRM 中的元數據,因此 robots.txt 中的單個 noindex 功能可以解決這個問題。
- 更快,更少問題的站點索引阻止:)
拒絕的其他原因包括:
- Noindex 標籤就夠用了
- robots.txt 文件中的新指令不是必需的
- 我不需要它,也沒有看到它工作
- 不要打擾
- 不要換
概括
你有它。 對此民意調查做出回應的大多數人都讚成添加此功能。 但是,請記住,SEL 的讀者群由知識淵博的受眾組成——他們的理解力和專業知識遠遠超過普通網站管理員。 此外,即使在民意調查中收到的肯定答復中,也有一些對問題 4 的答复(“作為 SEO,此功能對您有幫助嗎?如果有,如何”)表明對當前系統的工作方式存在誤解。
最終,雖然我個人很想擁有這個功能,但它不太可能發生。
本文中表達的觀點是客座作者的觀點,不一定是 Search Engine Land。 工作人員作者在這裡列出。