
Nós perguntamos, você respondeu: o Google deve adicionar suporte noindex ao robots.txt? Resultados da enquete
Publicados: 2021-10-05Em setembro, eu coloquei uma enquete aqui no Search Engine Land para ver se os leitores gostariam de ter uma instrução em robots.txt para marcar páginas para não indexação. Hoje apresentarei os resultados juntamente com uma revisão de quais são os principais problemas (e por que o Google não adicionará suporte para isso).
- Por que isso seria interessante?
- Quais são as desvantagens dessa ideia?
- Resultados gerais da pesquisa do robots.txt
Por que isso seria interessante?
No ambiente atual, o robots.txt é usado exclusivamente para orientar o comportamento do rastreamento da web. Além disso, a abordagem atual para marcar uma página como “NoIndex” é colocar uma tag na própria página. Infelizmente, se você bloqueá-la em robots.txt, o Google nunca verá a tag e ainda poderá indexar a página, mesmo que você não queira que isso aconteça.
Em sites grandes, isso apresenta alguns desafios quando você tem diferentes classes de páginas que você gostaria de bloquear o rastreamento E manter fora do índice do Google. Uma maneira de isso acontecer é em implementações complexas de navegação facetada, nas quais você cria páginas que têm um valor significativo para os usuários, mas acabam apresentando muitas páginas ao Google. Por exemplo, dei uma olhada no site de um varejista de calçados e descobri que eles têm mais de 70.000 páginas diferentes relacionadas a “tênis masculinos da Nike”. Isso inclui uma ampla variedade de tamanhos, larguras, cores e muito mais.
Em alguns testes em que participei com sites com navegação facetada complexa, como o exemplo que compartilhei acima, descobrimos que essa grande quantidade de páginas é um problema significativo. Para um desses testes, trabalhamos com um cliente para implementar a maior parte de sua navegação facetada em AJAX, de modo que a presença da maioria de suas páginas de navegação facetada fosse invisível para o Google, mas ainda facilmente acessada pelos usuários. A contagem de páginas para este site passou de 200 milhões de páginas para 200 mil páginas – uma redução de mil para uma. No ano seguinte, o tráfego para o site triplicou – um resultado surpreendentemente bom. No entanto, o tráfego caiu inicialmente e levou cerca de 4 meses para voltar aos níveis anteriores e depois subiu a partir daí.
Em outro cenário, vi um site implementar uma nova plataforma de e-commerce e sua contagem de páginas subiu de cerca de 5.000 páginas para mais de 1M. O tráfego deles despencou e fomos trazidos para ajudá-los a se recuperar. O conserto? Para trazer a contagem de páginas indexáveis de volta para onde estava antes. Infelizmente, como isso foi feito com ferramentas como NoIndex e Canonical tags, a velocidade de recuperação foi amplamente afetada pelo tempo que o Google levou para revisitar um número significativo de páginas no site.
Em ambos os casos, os resultados para as empresas envolvidas foram impulsionados pelo orçamento de rastreamento do Google e pelo tempo necessário para realizar o rastreamento suficiente para entender completamente a nova estrutura do site. Ter uma instrução em Robots.txt aceleraria rapidamente esses tipos de processos.
Quais são as desvantagens dessa ideia?
Tive a oportunidade de discutir isso com Patrick Stox, consultor de produtos e embaixador da marca da Ahrefs, e sua opinião rápida foi: “Acho que não vai acontecer pelo menos no robots.txt, talvez em outro sistema como o GSC. O Google deixou claro que eles querem robots.txt apenas para controle de rastreamento. A maior desvantagem provavelmente serão todas as pessoas que acidentalmente tiram seu site inteiro do índice.”
E, claro, essa questão de todo o site (ou partes-chave de um site) ser retirado do índice é o grande problema com isso. Em todo o escopo da web, não temos que questionar se isso acontecerá ou não – IRÁ. Infelizmente, é provável que aconteça com alguns sites importantes e, infelizmente, provavelmente acontecerá muito.
Na minha experiência em 20 anos de SEO, descobri que um mal-entendido sobre como usar várias tags de SEO é desenfreado. Por exemplo, na época em que a autoria do Google existia e tínhamos tags rel=author, fiz um estudo sobre como os sites as implementaram e descobri que 72% dos sites usavam as tags incorretamente. Isso incluiu alguns sites muito conhecidos em nossa indústria!
Em minha discussão com Stox, ele observou ainda: “Pensando em mais desvantagens, eles precisam descobrir como tratá-lo quando um arquivo robots.txt não está disponível temporariamente. Eles de repente começam a indexar páginas que antes eram marcadas como sem indexação?”
Também entrei em contato com o Google para comentar e fui direcionado para a postagem do blog quando eles abandonaram o suporte para noindex no robots.txt em 2014. Aqui está o que a postagem dizia sobre o assunto:

“Ao abrir o código de nossa biblioteca de analisadores, analisamos o uso das regras do robots.txt. Em particular, focamos em regras não suportadas pelo rascunho da internet, como crawl-delay, nofollow e noindex. Como essas regras nunca foram documentadas pelo Google, naturalmente, seu uso em relação ao Googlebot é muito baixo. Indo mais longe, vimos que seu uso foi contrariado por outras regras em todos, exceto 0,001% de todos os arquivos robots.txt na Internet. Esses erros prejudicam a presença de sites nos resultados de pesquisa do Google de maneiras que não achamos que os webmasters pretendiam. “
* O negrito da última frase foi feito por mim para dar ênfase.
Acho que esse é o fator determinante aqui. O Google age para proteger a qualidade de seu índice e o que pode parecer uma boa ideia pode ter muitas consequências não intencionais. Pessoalmente, eu adoraria ter a capacidade de marcar páginas para NoCrawl e NoIndex de maneira clara e fácil, mas a verdade é que não acho que isso vá acontecer.
Resultados gerais da pesquisa do robots.txt
Primeiro, gostaria de reconhecer uma falha na pesquisa nessa pergunta 2, uma pergunta obrigatória, presumindo que você respondeu à pergunta 1 com um “sim”. Felizmente, a maioria das pessoas que respondeu “não” na pergunta 1 clicou em “Outro” na pergunta 2 e, em seguida, digitou o motivo pelo qual não queria esse recurso. Uma dessas respostas observou essa falha e disse: “Sua pesquisa é enganosa”. Minhas desculpas pela falha aí.
Os resultados gerais foram os seguintes:
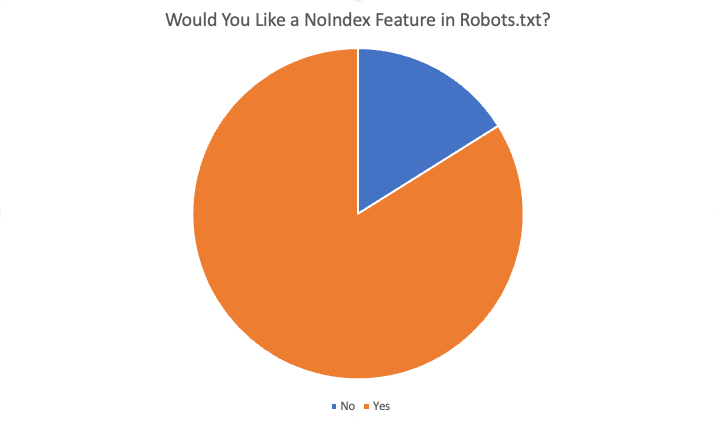
No total, 84% dos 87 entrevistados disseram “sim”, eles gostariam desse recurso. Algumas das razões oferecidas para querer esse recurso foram:
- Não há situações em que eu queira bloquear o rastreamento, mas ter páginas indexadas.
- A não indexação de um grande número de páginas leva muito tempo porque o Google precisa rastrear a página para ver o noindex. Quando tínhamos a diretiva noindex, conseguimos resultados mais rápidos para clientes com problemas de superindexação.
- Nós temos um grande problema de lixo… conteúdo muito antigo… centenas de diretórios e subdiretórios antigos e aparentemente leva meses, se não anos, para desindexá-los depois de excluí-los e ergo 404-los. Parece que poderíamos simplesmente adicionar a regra NoIndex no arquivo robots.txt e acreditar que o Google aderiria a essa instrução muito mais rápido do que ter que rastrear todos os URLs antigos ao longo do tempo... e repetidamente... encontrar 404 repetidos para finalmente excluí-los... então , limpar nosso(s) domínio(s) é uma maneira de ajudar.
- Economize esforço de desenvolvimento e seja facilmente ajustável se algo quebrar devido a alterações
- Não pode usar sempre um “noindex” e muitas páginas indexadas que não deveriam ser indexadas. O bloqueio padrão para spider também deve “noindex” as páginas pelo menos. Se eu quiser que um mecanismo de pesquisa não rastreie um URL/pasta, por que eu gostaria que eles indexassem essas páginas “vazias”?
- Adicionar novas instruções a um arquivo .txt é muito mais rápido do que obter recursos de desenvolvimento
- Sim, é difícil mudar a meta de cabeça para o CRM corporativo, então o recurso individual noindex no robots.txt resolveria esse problema.
- Bloqueio de indexação de sites mais rápido e menos problemático :)
Outras razões para dizer não incluem:
- A tag Noindex é boa o suficiente
- Novas diretivas no arquivo robots.txt não são necessárias
- Eu não preciso disso e não vejo isso funcionando
- Não se incomode
- Não mude
Resumo
Aí está. A maioria das pessoas que responderam a esta enquete é a favor de adicionar esse recurso. No entanto, tenha em mente que os leitores da SEL consistem em um público altamente conhecedor – com muito mais compreensão e experiência do que o webmaster médio. Além disso, mesmo entre as respostas sim recebidas na enquete, houve algumas respostas à pergunta 4 (“essa funcionalidade o beneficiaria como SEO? Se sim, como”) que indicavam um mal-entendido sobre o funcionamento do sistema atual.
Em última análise, embora eu pessoalmente adoraria ter esse recurso, é altamente improvável que isso aconteça.
As opiniões expressas neste artigo são do autor convidado e não necessariamente do Search Engine Land. Os autores da equipe estão listados aqui.