
Le preguntamos y usted respondió: ¿Debería Google agregar compatibilidad con noindex a robots.txt? Resultados de la Encuesta
Publicado: 2021-10-05En septiembre, puse una encuesta aquí en Search Engine Land para ver si a los lectores les gustaría tener una instrucción en robots.txt para marcar las páginas para que no estén indexadas. Hoy presentaré los resultados junto con una revisión de cuáles son los problemas clave (y por qué Google no agregará soporte para esto).
- ¿Por qué sería esto de interés?
- ¿Cuáles son las desventajas de esta idea?
- Resultados generales de la encuesta de robots.txt
¿Por qué sería esto de interés?
En el entorno actual, robots.txt se utiliza exclusivamente para guiar el comportamiento del rastreo web. Además, el enfoque actual para marcar una página como "NoIndex" es colocar una etiqueta en la página misma. Desafortunadamente, si lo bloquea en robots.txt, Google nunca verá la etiqueta y aún podría indexar la página aunque usted no quiera que eso suceda.
En sitios grandes, esto presenta algunos desafíos cuando tiene diferentes clases de páginas que le gustaría bloquear para que no se rastreen Y mantenerlas fuera del índice de Google. Una forma en que esto puede suceder es en implementaciones complejas de navegación por facetas donde tiene páginas que crea que tienen un valor significativo para los usuarios pero terminan presentando demasiadas páginas a Google. Por ejemplo, miré el sitio web de un minorista de calzado y descubrí que tienen más de 70 000 páginas diferentes relacionadas con "Calzado Nike para hombre". Esto incluye una amplia variedad de tamaños, anchos, colores y más.
En algunas pruebas en las que he participado con sitios con navegación facetada compleja como el ejemplo que compartí anteriormente, hemos encontrado que esta gran cantidad de páginas es un problema importante. Para una de esas pruebas, trabajamos con un cliente para implementar la mayor parte de su navegación por facetas en AJAX, por lo que la presencia de la mayoría de sus páginas de navegación por facetas era invisible para Google, pero los usuarios podían acceder fácilmente a ellas. El número de páginas de este sitio pasó de 200 millones de páginas a 200 000 páginas: una reducción de mil a una. Durante el año siguiente, el tráfico del sitio se triplicó, un resultado sorprendentemente bueno. Sin embargo, el tráfico DISMINUYÓ inicialmente, y tomó alrededor de 4 meses volver a los niveles anteriores y luego subió desde allí.
En otro escenario, vi un sitio implementar una nueva plataforma de comercio electrónico y su número de páginas se disparó de alrededor de 5000 páginas a más de 1 millón. Su tráfico se desplomó y nos trajeron para ayudarlos a recuperarse. ¿La solución? Para que el recuento de páginas indexables vuelva a estar donde estaba antes. Desafortunadamente, dado que esto se hizo con herramientas como NoIndex y etiquetas Canonical, la velocidad de recuperación se vio afectada en gran medida por el tiempo que le tomó a Google volver a visitar una cantidad significativa de páginas en el sitio.
En ambos casos, los resultados de las empresas involucradas se vieron impulsados por el presupuesto de rastreo de Google y el tiempo que se tardó en realizar un rastreo suficiente para comprender completamente la nueva estructura del sitio. Tener una instrucción en Robots.txt aceleraría rápidamente este tipo de procesos.
¿Cuáles son las desventajas de esta idea?
Tuve la oportunidad de discutir esto con Patrick Stox, asesor de productos y embajador de la marca de Ahrefs, y su respuesta rápida fue: “Simplemente no creo que suceda al menos dentro de robots.txt, tal vez dentro de otro sistema como GSC. Google fue claro en que quiere robots.txt solo para control de rastreo. El mayor inconveniente probablemente serán todas las personas que accidentalmente eliminen todo su sitio del índice”.
Y, por supuesto, este problema de que todo el sitio (o partes clave de un sitio) se eliminen del índice es el gran problema. En todo el ámbito de la web, no tenemos que preguntarnos si esto sucederá o no, sucederá. Lamentablemente, es probable que suceda con algunos sitios importantes y, lamentablemente, probablemente suceda con mucha frecuencia.
En mi experiencia a lo largo de 20 años de SEO, descubrí que existe un malentendido sobre cómo usar varias etiquetas de SEO. Por ejemplo, cuando existía la autoría de Google y teníamos etiquetas rel=author, realicé un estudio sobre qué tan bien las implementaban los sitios y descubrí que el 72 % de los sitios habían usado las etiquetas incorrectamente. ¡Eso incluyó algunos sitios muy conocidos en nuestra industria!
En mi conversación con Stox, señaló además: “Pensando en más inconvenientes, tienen que descubrir cómo tratarlo cuando un archivo robots.txt no está disponible temporalmente. ¿De repente comienzan a indexar páginas que antes estaban marcadas como no indexadas?
También contacté a Google para hacer comentarios, y me señalaron la publicación de su blog cuando eliminaron el soporte para noindex en robots.txt en 2014. Esto es lo que decía la publicación sobre el asunto:

“Mientras abrimos nuestra biblioteca de analizador, analizamos el uso de las reglas de robots.txt. En particular, nos enfocamos en las reglas que no son compatibles con el borrador de Internet, como crawl-delay, nofollow y noindex. Dado que estas reglas nunca fueron documentadas por Google, naturalmente, su uso en relación con Googlebot es muy bajo. Profundizando más, vimos que su uso se contradecía con otras reglas en todos menos en el 0,001 % de todos los archivos robots.txt en Internet. Estos errores dañan la presencia de los sitios web en los resultados de búsqueda de Google de maneras que no creemos que los webmasters pretendieran. “
* La negrita de la última oración fue hecha por mí para enfatizar.
Creo que este es el factor determinante aquí. Google actúa para proteger la calidad de su índice y lo que puede parecer una buena idea puede tener muchas consecuencias no deseadas. Personalmente, me encantaría tener la capacidad de marcar páginas tanto para NoCrawl como para NoIndex de una manera clara y fácil, pero la verdad es que no creo que vaya a suceder.
Resultados generales de la encuesta de robots.txt
En primer lugar, me gustaría reconocer una falla en la encuesta en la pregunta 2, una pregunta obligatoria, asumió que respondió a la pregunta 1 con un "sí". Afortunadamente, la mayoría de las personas que respondieron "no" en la pregunta 1 hicieron clic en "Otro" para la pregunta 2 y luego ingresaron una razón por la que no querían esta capacidad. Una de esas respuestas notó esta falla y dijo: “Su encuesta es engañosa”. Mis disculpas por la falla allí.
Los resultados generales fueron los siguientes:
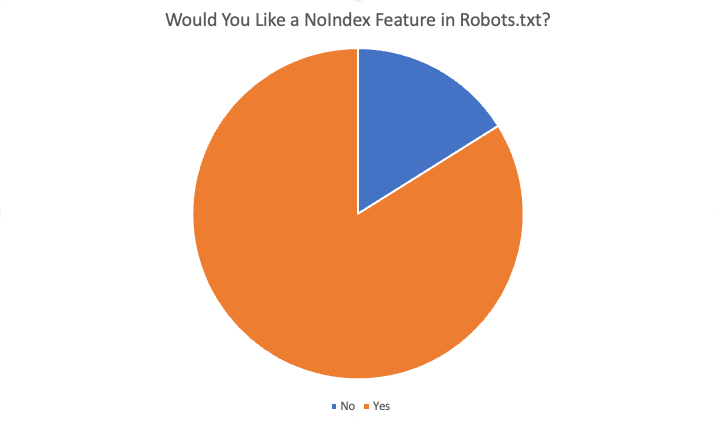
En total, el 84% de los 87 encuestados dijeron "sí", les gustaría esta función. Algunas de las razones ofrecidas para querer esta característica fueron:
- No hay situaciones en las que quiera bloquear el rastreo pero tener páginas indexadas.
- Noindexar una gran cantidad de páginas lleva mucho tiempo porque Google tiene que rastrear la página para ver el noindex. Cuando teníamos la directiva noindex, podíamos lograr resultados más rápidos para los clientes con problemas de sobreindexación.
- Tenemos un problema de cruft muy grande... contenido muy antiguo... cientos de directorios y subdirectorios antiguos y parece que lleva meses, si no años, desindexarlos una vez que los eliminamos y ergo 404. Parece que podríamos simplemente agregar la regla NoIndex en el archivo robots.txt y creer que Google se adherirá a esta instrucción mucho más rápido que tener que rastrear todas las URL antiguas a lo largo del tiempo... y repetidamente... para encontrar repeticiones de 404 para finalmente eliminarlas... así que , limpiar nuestro(s) dominio(s) es una forma de ayudar.
- Ahorre esfuerzo de desarrollo y se puede ajustar fácilmente si algo se rompe debido a los cambios.
- No se puede usar siempre un "noindex" y hay demasiadas páginas indexadas que no deberían indexarse. El bloqueo estándar para spider también debería "no indexar" las páginas al menos. Si quiero que un motor de búsqueda no rastree una URL/carpeta, ¿por qué querría que indexaran estas páginas "vacías"?
- Agregar nuevas instrucciones a un archivo .txt es mucho más rápido que obtener recursos de desarrollo
- Sí, es difícil cambiar la meta en cabeza para el CRM empresarial, por lo que la característica individual de noindex en robots.txt resolvería ese problema.
- Bloqueo de indexación de sitios más rápido y menos problemático :)
Otras razones para decir no incluyen:
- La etiqueta Noindex es lo suficientemente buena
- No son necesarias nuevas directivas en el archivo robots.txt
- No lo necesito y no lo veo funcionando
- no te molestes
- No cambies
Resumen
Ahí tienes. La mayoría de las personas que respondieron a esta encuesta están a favor de agregar esta función. Sin embargo, tenga en cuenta que los lectores de SEL consisten en una audiencia altamente informada, con mucha más comprensión y experiencia que el webmaster promedio. Además, incluso entre las respuestas afirmativas recibidas en la encuesta, hubo algunas respuestas a la pregunta 4 ("¿esta característica le beneficiaría como SEO? De ser así, cómo") que indicaban un malentendido sobre la forma en que funciona el sistema actual.
Sin embargo, en última instancia, aunque personalmente me encantaría tener esta función, es muy poco probable que suceda.
Las opiniones expresadas en este artículo pertenecen al autor invitado y no necesariamente a Search Engine Land. Los autores del personal se enumeran aquí.