
Wir haben gefragt, Sie haben geantwortet: Sollte Google die robots.txt um noindex-Unterstützung erweitern? Umfrageergebnisse
Veröffentlicht: 2021-10-05Im September habe ich hier auf Search Engine Land eine Umfrage gestartet, um zu sehen, ob Leser eine Anweisung in der robots.txt-Datei haben möchten, Seiten für „Keine Indexierung“ zu markieren. Heute präsentiere ich die Ergebnisse zusammen mit einem Überblick über die wichtigsten Probleme (und warum Google dafür keine Unterstützung hinzufügen wird).
- Warum sollte das von Interesse sein?
- Was sind die Nachteile dieser Idee?
- Gesamtergebnisse der robots.txt-Umfrage
Warum sollte das von Interesse sein?
In der aktuellen Umgebung wird die robots.txt ausschließlich dazu verwendet, das Verhalten des Webcrawling zu steuern. Darüber hinaus besteht der aktuelle Ansatz zum Markieren einer Seite als „NoIndex“ darin, ein Tag auf der Seite selbst zu platzieren. Wenn Sie es in der robots.txt-Datei blockieren, sieht Google das Tag leider nie und könnte die Seite möglicherweise dennoch indexieren, obwohl Sie dies nicht möchten.
Auf großen Websites stellt dies einige Herausforderungen dar, wenn Sie verschiedene Klassen von Seiten haben, die Sie sowohl für das Crawlen blockieren als auch aus dem Google-Index heraushalten möchten. Eine Möglichkeit, wie dies passieren kann, sind komplexe facettierte Navigationsimplementierungen, bei denen Sie Seiten erstellen, die einen erheblichen Wert für die Benutzer haben, aber am Ende Google viel zu viele Seiten präsentieren. Zum Beispiel habe ich mir die Website eines Schuhhändlers angesehen und festgestellt, dass sie über 70.000 verschiedene Seiten zum Thema „Nike-Schuhe für Herren“ haben. Dazu gehören eine Vielzahl von Größen, Breiten, Farben und mehr.
In einigen Tests, an denen ich mit Websites mit komplexer Facettennavigation teilgenommen habe, wie dem Beispiel, das ich oben geteilt habe, haben wir festgestellt, dass diese große Anzahl von Seiten ein erhebliches Problem darstellt. Für einen dieser Tests haben wir mit einem Kunden zusammengearbeitet, um den größten Teil seiner facettierten Navigation in AJAX zu implementieren, sodass die Anwesenheit der meisten seiner facettierten Navigationsseiten für Google unsichtbar war, aber dennoch für Benutzer leicht zugänglich war. Die Seitenanzahl für diese Website stieg von 200 Millionen Seiten auf 200.000 Seiten – eine Reduzierung von tausend zu eins. Im Laufe des nächsten Jahres verdreifachte sich der Traffic auf der Website – ein erstaunlich gutes Ergebnis. Der Verkehr ging jedoch zunächst nach unten, und es dauerte etwa 4 Monate, bis er wieder auf das vorherige Niveau zurückkehrte, und dann stieg er von dort aus an.
In einem anderen Szenario sah ich, wie eine Website eine neue E-Commerce-Plattform implementierte und ihre Seitenzahl von etwa 5.000 Seiten auf über 1 Million stieg. Ihr Verkehr brach ein und wir wurden hinzugezogen, um ihnen bei der Genesung zu helfen. Die Reparatur? Um die Anzahl der indexierbaren Seiten wieder auf den vorherigen Stand zu bringen. Da dies mit Tools wie NoIndex und Canonical-Tags durchgeführt wurde, wurde die Geschwindigkeit der Wiederherstellung leider stark durch die Zeit beeinträchtigt, die Google benötigte, um eine beträchtliche Anzahl von Seiten auf der Website erneut zu besuchen.
In beiden Fällen wurden die Ergebnisse für die beteiligten Unternehmen vom Crawling-Budget von Google und der Zeit bestimmt, die benötigt wurde, um genügend Crawling durchzuführen, um die neue Struktur der Website vollständig zu verstehen. Eine Anweisung in Robots.txt würde diese Art von Prozessen schnell beschleunigen.
Was sind die Nachteile dieser Idee?
Ich hatte die Gelegenheit, dies mit Patrick Stox, Produktberater und Markenbotschafter für Ahrefs, zu besprechen, und seine kurze Meinung war: „Ich glaube einfach nicht, dass es zumindest innerhalb von robots.txt passieren wird, vielleicht in einem anderen System wie GSC. Google hat deutlich gemacht, dass sie robots.txt nur für die Crawl-Steuerung haben wollen. Der größte Nachteil werden wahrscheinlich all die Leute sein, die versehentlich ihre gesamte Website aus dem Index nehmen.“
Und natürlich ist dieses Problem, dass die gesamte Website (oder wichtige Teile einer Website) aus dem Index genommen werden, das große Problem damit. Im gesamten Bereich des Internets müssen wir uns nicht fragen, ob dies passieren wird oder nicht – es WIRD. Leider wird es wahrscheinlich bei einigen wichtigen Websites passieren, und leider wird es wahrscheinlich häufig passieren.
In meiner Erfahrung aus 20 Jahren SEO habe ich festgestellt, dass ein Missverständnis darüber, wie man verschiedene SEO-Tags verwendet, weit verbreitet ist. Als beispielsweise die Urheberschaft von Google noch eine Sache war und wir rel=author-Tags hatten, habe ich eine Studie darüber durchgeführt, wie gut Websites sie implementiert haben, und festgestellt, dass 72 % der Websites die Tags falsch verwendet haben. Dazu gehörten einige wirklich bekannte Seiten in unserer Branche!
In meiner Diskussion mit Stox bemerkte er weiter: „Wenn sie an weitere Nachteile denken, müssen sie herausfinden, wie sie damit umgehen, wenn eine robots.txt-Datei vorübergehend nicht verfügbar ist. Fangen sie plötzlich an, Seiten zu indizieren, die vorher mit noindex gekennzeichnet waren?“
Ich habe mich auch an Google gewandt, um einen Kommentar zu erhalten, und ich wurde auf ihren Blog-Beitrag verwiesen, als sie 2014 die Unterstützung für noindex in robots.txt eingestellt haben. Hier ist, was der Beitrag zu diesem Thema sagte:

„Beim Open-Sourcing unserer Parser-Bibliothek haben wir die Verwendung von robots.txt-Regeln analysiert. Insbesondere haben wir uns auf Regeln konzentriert, die vom Internet-Entwurf nicht unterstützt werden, wie z. B. Crawl-Delay, Nofollow und Noindex. Da diese Regeln von Google nie dokumentiert wurden, ist ihre Verwendung in Bezug auf Googlebot natürlich sehr gering. Als wir weiter gruben, sahen wir, dass ihre Verwendung durch andere Regeln in allen außer 0,001 % aller robots.txt-Dateien im Internet widerlegt wurde. Diese Fehler beeinträchtigen die Präsenz von Websites in den Google-Suchergebnissen auf eine Weise, die unserer Meinung nach nicht von Webmastern beabsichtigt war. „
* Der letzte Satz wurde von mir zur Hervorhebung fett gedruckt.
Ich denke, dass dies hier der treibende Faktor ist. Google handelt, um die Qualität seines Indexes zu schützen, und was wie eine gute Idee erscheinen mag, kann viele unbeabsichtigte Folgen haben. Ich persönlich hätte gerne die Möglichkeit, Seiten sowohl für NoCrawl als auch für NoIndex auf klare und einfache Weise zu markieren, aber die Wahrheit ist, dass ich nicht glaube, dass dies passieren wird.
Gesamtergebnisse der robots.txt-Umfrage
Zunächst möchte ich einen Fehler in der Umfrage in dieser Frage 2, einer Pflichtfrage, anerkennen, vorausgesetzt, Sie haben Frage 1 mit „Ja“ beantwortet. Glücklicherweise klickten die meisten Personen, die Frage 1 mit „Nein“ beantworteten, bei Frage 2 auf „Andere“ und gaben dann einen Grund ein, warum sie diese Funktion nicht wollten. Eine dieser Antworten bemerkte diesen Fehler und sagte: „Ihre Umfrage ist irreführend.“ Ich entschuldige mich für den Fehler dort.
Die Gesamtergebnisse waren wie folgt:
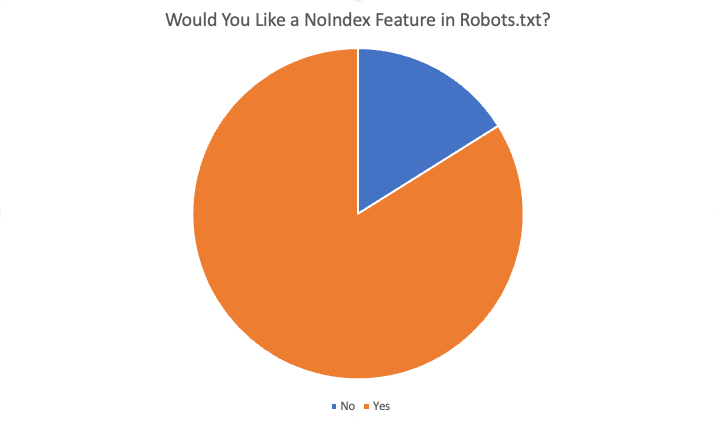
Insgesamt sagten 84 % der 87 Befragten „Ja“, dass sie diese Funktion gerne hätten. Einige der Gründe für den Wunsch nach dieser Funktion waren:
- Es gibt keine Situationen, in denen ich das Crawlen blockieren, aber Seiten indizieren möchte.
- Das Noindexing einer großen Anzahl von Seiten nimmt viel Zeit in Anspruch, da Google die Seite crawlen muss, um den Noindex zu sehen. Als wir die noindex-Direktive hatten, konnten wir schnellere Ergebnisse für Kunden mit Überindexierungsproblemen erzielen.
- Wir haben ein sehr großes Cruft-Problem … sehr alter Inhalt … Hunderte von alten Verzeichnissen und Unterverzeichnissen und es dauert scheinbar Monate, wenn nicht Jahre, diese zu de-indizieren, nachdem wir sie gelöscht und ergo 404 gemacht haben. Scheint, als könnten wir einfach die NoIndex-Regel in die robots.txt-Datei einfügen und glauben, dass Google sich viel schneller an diese Anweisung halten würde, als alle alten URLs im Laufe der Zeit durchsuchen zu müssen … und wiederholt … um sich wiederholende 404-Fehler zu finden, um sie schließlich zu löschen … also , unsere Domain(s) zu bereinigen, wäre eine Möglichkeit, wie es helfen würde.
- Entwicklungsaufwand sparen und leicht nachjustierbar, falls aufgrund von Änderungen mal etwas kaputt geht
- Es kann nicht immer ein „noindex“ verwendet werden und es werden zu viele Seiten indiziert, die nicht indiziert werden sollten. Die Standardblockierung für Spider sollte auch die Seiten zumindest „noindexen“. Wenn ich möchte, dass eine Suchmaschine eine URL/einen Ordner nicht crawlt, warum sollte ich dann wollen, dass sie diese „leeren“ Seiten indiziert?
- Das Hinzufügen neuer Anweisungen zu einer TXT-Datei ist viel schneller als das Abrufen von Dev-Ressourcen
- Ja, es ist schwierig, das Meta in Head für Unternehmens-CRM zu ändern, daher würde eine individuelle noindex-Funktion in robots.txt dieses Problem lösen.
- Schnelleres, weniger problematisches Blockieren der Site-Indizierung :)
Weitere Gründe für ein Nein waren:
- Noindex-Tag ist gut genug
- Neue Anweisungen in der robots.txt-Datei sind nicht erforderlich
- Ich brauche es nicht und sehe nicht, dass es funktioniert
- Mach dir keine Sorgen
- Ändere dich nicht
Zusammenfassung
Hier hast du es. Die meisten Personen, die auf diese Umfrage geantwortet haben, befürworten das Hinzufügen dieser Funktion. Denken Sie jedoch daran, dass die Leserschaft für SEL aus einem sehr sachkundigen Publikum besteht – mit weitaus mehr Verständnis und Fachwissen als der durchschnittliche Webmaster. Darüber hinaus gab es sogar unter den Ja-Antworten in der Umfrage einige Antworten auf Frage 4 („Würde diese Funktion Ihnen als SEO zugute kommen? Wenn ja, wie“), die auf ein Missverständnis der Funktionsweise des aktuellen Systems hindeuteten.
Obwohl ich diese Funktion persönlich gerne hätte, ist es höchst unwahrscheinlich, dass dies geschieht.
Die in diesem Artikel geäußerten Meinungen sind die des Gastautors und nicht unbedingt Search Engine Land. Mitarbeiter Autoren sind hier aufgelistet.