
Biz sorduk, siz cevapladınız: Google robots.txt'e noindex desteği eklemeli mi? Anket sonuçları
Yayınlanan: 2021-10-05Eylül ayında, okuyucuların robots.txt dosyasında Dizine Ekleme Yok için sayfaları işaretlemek için bir talimat almak isteyip istemediklerini görmek için Search Engine Land'e bir anket koydum. Bugün, sonuçların yanı sıra temel sorunların neler olduğunu (ve Google'ın neden buna destek eklemeyeceğini) gözden geçireceğim.
- Bu neden ilgi çeksin ki?
- Bu fikrin dezavantajları nelerdir?
- Genel robots.txt anket sonuçları
Bu neden ilgi çeksin ki?
Mevcut ortamda robots.txt, yalnızca web'de gezinme davranışını yönlendirmek için kullanılır. Ayrıca, bir sayfayı “NoIndex” olarak işaretlemeye yönelik mevcut yaklaşım, sayfanın kendisine bir etiket yerleştirmektir. Maalesef, robots.txt dosyasında engellerseniz, Google etiketi asla görmez ve bunun olmasını istemeseniz bile sayfayı potansiyel olarak dizine ekleyebilir.
Büyük sitelerde bu, hem taranmasını engellemek hem de Google dizininin dışında tutmak istediğiniz farklı sayfa sınıflarınız olduğunda bazı zorluklar sunar. Bunun olabilmesinin bir yolu, oluşturduğunuz, kullanıcılar için önemli bir değere sahip olan ancak sonunda Google'a çok fazla sayfa sunan sayfalara sahip olduğunuz karmaşık yönlü gezinme uygulamalarıdır. Örneğin, bir ayakkabı satıcısının web sitesine baktım ve "Erkek Nike ayakkabıları" ile ilgili 70.000'den fazla farklı sayfaya sahip olduklarını gördüm. Bu, çok çeşitli boyutlar, genişlikler, renkler ve daha fazlasını içerir.
Yukarıda paylaştığım örnekte olduğu gibi karmaşık yönlü navigasyona sahip sitelerle katıldığım bazı testlerde, bu büyük miktardaki sayfaların önemli bir sorun olduğunu gördük. Bu testlerden biri için, çok yönlü gezinmelerinin çoğunu AJAX'ta uygulamak için bir müşteriyle çalıştık, böylece çok yönlü gezinme sayfalarının çoğu Google tarafından görünmezdi, ancak yine de kullanıcılar tarafından kolayca erişilebilirdi. Bu sitenin sayfa sayısı 200 milyon sayfadan 200 bin sayfaya çıktı - binde bir azalma. Önümüzdeki yıl boyunca siteye gelen trafik üç katına çıktı - inanılmaz derecede iyi bir sonuç. Ancak trafik başlangıçta AZALDI ve önceki seviyelere geri dönmesi yaklaşık 4 ay sürdü ve ardından oradan tırmandı.
Başka bir senaryoda, bir sitenin yeni bir e-ticaret platformu uyguladığını ve sayfa sayısının yaklaşık 5.000 sayfadan 1 milyonun üzerine çıktığını gördüm. Trafikleri düştü ve iyileşmelerine yardımcı olmak için getirildik. Çözüm? İndekslenebilir sayfayı geri getirmek için, daha önce olduğu yere geri sayım yapın. Ne yazık ki, bu NoIndex ve Canonical etiketleri gibi araçlarla yapıldığından, kurtarma hızı, Google'ın sitedeki önemli sayıda sayfayı tekrar ziyaret etmesi için geçen süreden büyük ölçüde etkilendi.
Her iki durumda da, ilgili şirketler için sonuçlar, Google'ın tarama bütçesi ve sitenin yeni yapısını tam olarak anlamak için yeterli taramayı tamamlamak için geçen süre tarafından yönlendirildi. Robots.txt dosyasında bir talimata sahip olmak, bu tür süreçleri hızla hızlandıracaktır.
Bu fikrin dezavantajları nelerdir?
Ahrefs'in Ürün danışmanı ve marka elçisi Patrick Stox ile bu konuyu tartışma fırsatı buldum ve hızlı görüşü şu oldu: "En azından robots.txt içinde, belki de GSC gibi başka bir sistemde olacağını düşünmüyorum. Google, robots.txt dosyasını yalnızca tarama kontrolü için istedikleri konusunda netti. En büyük dezavantaj, muhtemelen tüm sitelerini yanlışlıkla dizinden çıkaran tüm insanlar olacaktır.
Ve elbette, tüm sitenin (veya bir sitenin önemli bölümlerinin) dizinden çıkarılması bu konudaki en büyük sorundur. Web'in tamamında bunun olup olmayacağını sorgulamamıza gerek yok - OLACAK. Ne yazık ki, bazı önemli sitelerde olması muhtemeldir ve ne yazık ki, muhtemelen çok fazla olacaktır.
20 yıllık SEO deneyimimde, çeşitli SEO etiketlerinin nasıl kullanılacağına dair bir yanlış anlaşılmanın yaygın olduğunu gördüm. Örneğin, Google Authorship'in bir şey olduğu ve rel=author etiketlerimizin olduğu günlerde, sitelerin bunları ne kadar iyi uyguladığını araştırdım ve sitelerin %72'sinin etiketleri yanlış kullandığını gördüm. Bu, sektörümüzde gerçekten iyi bilinen bazı siteleri içeriyordu!
Stox ile yaptığım tartışmada ayrıca şunları kaydetti: "Daha fazla olumsuzluk düşününce, bir robots.txt dosyası geçici olarak mevcut olmadığında bunu nasıl tedavi edeceklerini bulmaları gerekiyor. Daha önce noindex olarak işaretlenmiş sayfaları aniden dizine eklemeye mi başlıyorlar?”
Ayrıca yorum için Google'a ulaştım ve 2014'te robots.txt'de noindex desteğini bıraktıklarında blog gönderilerine işaret ettim. Gönderinin konuyla ilgili söylediği şey:

“Ayrıştırıcı kitaplığımızı açık kaynaklı hale getirirken robots.txt kurallarının kullanımını analiz ettik. Özellikle, tarama gecikmesi, nofollow ve noindex gibi internet taslağı tarafından desteklenmeyen kurallara odaklandık. Bu kurallar Google tarafından hiçbir zaman belgelenmediğinden, doğal olarak Googlebot ile ilgili kullanımları çok düşüktür. Daha da derine inerek, internetteki tüm robots.txt dosyalarının %0,001'i dışında tümünde kullanımlarının diğer kurallarla çeliştiğini gördük. Bu hatalar, web sitelerinin Google'ın arama sonuçlarındaki varlığına, web yöneticilerinin amaçladığını düşünmediğimiz şekillerde zarar verir. “
* Son cümle tarafımdan kalınlaştırılarak vurgu yapılmıştır.
Bence buradaki itici faktör bu. Google, dizininin kalitesini korumak için hareket eder ve iyi bir fikir gibi görünen birçok istenmeyen sonuca yol açabilir. Şahsen, hem NoCrawl hem de NoIndex için sayfaları açık ve kolay bir şekilde işaretleme yeteneğine sahip olmayı çok isterdim, ancak işin gerçeği, bunun olacağını düşünmüyorum.
Genel robots.txt anket sonuçları
İlk olarak, 2. sorudaki anketteki bir kusuru kabul etmek isterim, zorunlu bir soru, 1. soruyu “evet” ile yanıtladığınızı varsaydım. Neyse ki, 1. soruya "hayır" yanıtı veren çoğu kişi 2. soru için "Diğer"e tıkladı ve ardından bu yeteneği neden istemediklerinin nedenini girdi. Bu yanıtlardan biri bu kusura dikkat çekti ve “Anketiniz yanıltıcı” dedi. Oradaki kusur için özür dilerim.
Genel sonuçlar şu şekildeydi:
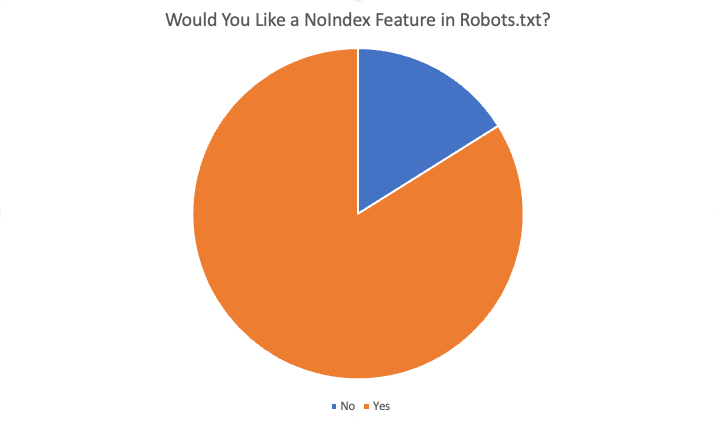
87 katılımcının toplamda %84'ü “evet” dedi ve bu özelliği beğeneceklerini söyledi. Bu özelliği istemek için sunulan nedenlerden bazıları şunlardı:
- Taramayı engellemek istediğim ancak sayfaların dizine eklenmesini istediğim durumlar yok.
- Google'ın noindex'i görmek için sayfayı taraması gerektiğinden, çok sayıda sayfayı noindexlemek çok zaman alır. Noindex yönergesine sahip olduğumuzda, aşırı endeksleme sorunları olan müşteriler için daha hızlı sonuçlar elde edebiliyorduk.
- Çok büyük bir kabahat sorunumuz var…çok eski içerik…yüzlerce eski dizin ve alt dizin ve onları sildikten ve 404'e geri döndüğümüzde, bunları indekslemek yıllar olmasa da aylar alıyor. Görünüşe göre robots.txt dosyasına NoIndex kuralını ekleyebilir ve Google'ın bu talimata, zaman içinde tüm eski URL'leri taramak zorunda kalmaktan çok daha hızlı bir şekilde uyacağına ve sonunda onları silmek için tekrar eden 404'leri bulmaktan çok daha hızlı uygulayacağına inanabiliriz. , alan(lar)ımızı temizlemek yardımcı olabilecek bir yoldur.
- Geliştirme çabalarından tasarruf edin ve değişiklikler nedeniyle bir şeyler bozulursa kolayca ayarlanabilir
- Her zaman bir "noindex" kullanamazsınız ve dizine eklenmemesi gereken çok fazla sayfa dizine eklenir. Örümcek için standart engelleme de en azından sayfaları "noindex" yapmalıdır. Bir arama motorunun bir URL'yi/klasörü taramamasını istiyorsam, neden bu "boş" sayfaları dizine eklemelerini isteyeyim?
- Bir .txt dosyasına yeni talimatlar eklemek, Geliştirme kaynaklarını almaktan çok daha hızlıdır
- Evet, kurumsal CRM için metayı değiştirmek zordur, bu nedenle robots.txt dosyasındaki bireysel noindex özelliği bu sorunu çözecektir.
- Daha hızlı, daha az sorunlu site indeksleme engelleme :)
Hayır demenin diğer nedenleri şunlardır:
- Noindex etiketi yeterince iyi
- robots.txt dosyasındaki yeni yönergeler gerekli değildir
- İhtiyacım yok ve çalıştığını görmüyorum
- zahmet etme
- Değiştirme
Özet
İşte aldın. Bu ankete yanıt veren çoğu kişi bu özelliğin eklenmesinden yana. Ancak, SEL okuyucusunun, ortalama bir web yöneticisinden çok daha fazla anlayışa ve uzmanlığa sahip, oldukça bilgili bir hedef kitleden oluştuğunu unutmayın. Ek olarak, ankette alınan evet yanıtları arasında bile 4. soruya (“bu özellik bir SEO olarak size fayda sağlar mı? Olursa, nasıl”) mevcut sistemin çalışma şeklinin yanlış anlaşıldığını gösteren bazı yanıtlar vardı.
Nihayetinde, şahsen bu özelliğe sahip olmayı çok istesem de, gerçekleşmesi pek olası değil.
Bu makalede ifade edilen görüşler konuk yazara aittir ve mutlaka Search Engine Land değildir. Personel yazarları burada listelenir.