
Мы спросили, вы ответили: следует ли Google добавить поддержку noindex в robots.txt? Результаты опроса
Опубликовано: 2021-10-05В сентябре я провел опрос здесь, на сайте Search Engine Land, чтобы узнать, не хотят ли читатели иметь инструкцию в файле robots.txt для пометки страниц как не индексируемых. Сегодня я представлю результаты вместе с обзором ключевых проблем (и почему Google не будет добавлять поддержку для этого).
- Почему это может представлять интерес?
- Каковы недостатки этой идеи?
- Общие результаты опроса robots.txt
Почему это может представлять интерес?
В текущей среде файл robots.txt используется исключительно для управления поведением при сканировании веб-страниц. Кроме того, текущий подход к пометке страницы как «NoIndex» заключается в размещении тега на самой странице. К сожалению, если вы заблокируете его в robots.txt, Google никогда не увидит этот тег и потенциально может проиндексировать страницу, даже если вы этого не хотите.
На больших сайтах это создает некоторые проблемы, когда у вас есть разные классы страниц, которые вы хотели бы заблокировать от сканирования и исключить из индекса Google. Один из способов, которым это может произойти, — это сложные многогранные реализации навигации, когда у вас есть страницы, которые вы создаете, которые имеют значительную ценность для пользователей, но в конечном итоге представляют слишком много страниц для Google. Например, я заглянул на сайт одного обувного ритейлера и обнаружил, что у них более 70 000 различных страниц, посвященных «мужской обуви Nike». Это включает в себя широкий спектр размеров, ширины, цвета и многое другое.
В некоторых тестах, в которых я участвовал с сайтами со сложной многогранной навигацией, как в примере, который я привел выше, мы обнаружили, что большое количество страниц является серьезной проблемой. Для одного из этих тестов мы работали с клиентом над реализацией большей части их фасетной навигации в AJAX, поэтому присутствие большинства их фасетных навигационных страниц было невидимым для Google, но по-прежнему легко доступным для пользователей. Количество страниц на этом сайте выросло с 200 миллионов страниц до 200 тысяч страниц — сокращение с тысячи к одному. В течение следующего года посещаемость сайта увеличилась втрое — поразительно хороший результат. Тем не менее, трафик сначала упал, и потребовалось около 4 месяцев, чтобы вернуться к прежним уровням, а затем он поднялся оттуда.
В другом сценарии я видел, как сайт внедрил новую платформу электронной коммерции, и количество его страниц выросло с примерно 5000 до более чем 1 миллиона. Их трафик резко упал, и мы были привлечены, чтобы помочь им восстановиться. Исправление? Чтобы снова уменьшить количество индексируемых страниц до того места, где оно было раньше. К сожалению, поскольку это было сделано с помощью таких инструментов, как теги NoIndex и Canonical, на скорость восстановления в значительной степени повлияло время, которое потребовалось Google для повторного посещения значительного количества страниц на сайте.
В обоих случаях результаты для вовлеченных компаний определялись краулинговым бюджетом Google и временем, которое потребовалось на сканирование, достаточное для полного понимания новой структуры сайта. Наличие инструкции в Robots.txt значительно ускорит такие процессы.
Каковы недостатки этой идеи?
У меня была возможность обсудить это с Патриком Стоксом, консультантом по продуктам и послом бренда Ahrefs, и его краткое мнение было следующим: «Я просто не думаю, что это произойдет, по крайней мере, в robots.txt, может быть, в другой системе, такой как GSC. Google ясно дал понять, что им нужен файл robots.txt только для контроля сканирования. Самым большим недостатком, вероятно, будут все люди, которые случайно удалят весь свой сайт из индекса».
И, конечно же, эта проблема с удалением всего сайта (или его ключевых частей) из индекса является большой проблемой. Во всем масштабе сети нам не нужно задаваться вопросом, произойдет это или нет — это ПРОИСХОДИТ. К сожалению, это, вероятно, произойдет с некоторыми важными сайтами, и, к сожалению, это, вероятно, произойдет во многих случаях.
За 20 лет работы в SEO я обнаружил, что неправильное понимание того, как использовать различные SEO-теги, широко распространено. Например, в те дни, когда Google Authorship был в моде и у нас были теги rel=author, я провел исследование того, насколько хорошо сайты их реализовали, и обнаружил, что 72% сайтов использовали теги неправильно. Это включало некоторые действительно известные сайты в нашей отрасли!
В моем обсуждении со Stox он далее отметил: «Думая о других недостатках, они должны выяснить, как обращаться с этим, когда файл robots.txt временно недоступен. Они вдруг начинают индексировать страницы, которые раньше были помечены как noindex?»
Я также обратился к Google за комментариями, и мне указали на их сообщение в блоге, когда они отказались от поддержки noindex в robots.txt еще в 2014 году. Вот что говорится в сообщении по этому поводу:

«Открывая исходный код нашей библиотеки синтаксического анализатора, мы проанализировали использование правил robots.txt. В частности, мы сосредоточились на правилах, не поддерживаемых интернет-проектом, таких как задержка сканирования, nofollow и noindex. Поскольку эти правила никогда не документировались Google, естественно, их использование в отношении Googlebot очень мало. Копнув дальше, мы увидели, что их использование противоречит другим правилам во всех, кроме 0,001%, всех файлах robots.txt в Интернете. Эти ошибки вредят присутствию веб-сайтов в результатах поиска Google так, как мы думаем, веб-мастера этого не хотели. “
* Последнее предложение выделено мной жирным шрифтом для акцента.
Я думаю, что это движущий фактор здесь. Google действует, чтобы защитить качество своего индекса, и то, что может показаться хорошей идеей, может иметь много непредвиденных последствий. Лично я хотел бы иметь возможность помечать страницы как для NoCrawl, так и для NoIndex четким и простым способом, но правда в том, что я не думаю, что это произойдет.
Общие результаты опроса robots.txt
Во-первых, я хотел бы признать недостаток опроса в том, что вопрос 2, обязательный вопрос, предполагал, что вы ответили на вопрос 1 «да». К счастью, большинство людей, ответивших «нет» на вопрос 1, нажали «Другое» на вопрос 2, а затем указали причину, по которой им не нужна эта возможность. Один из этих ответов отметил этот недостаток и сказал: «Ваш опрос вводит в заблуждение». Мои извинения за недостаток там.
Общие результаты были следующими:
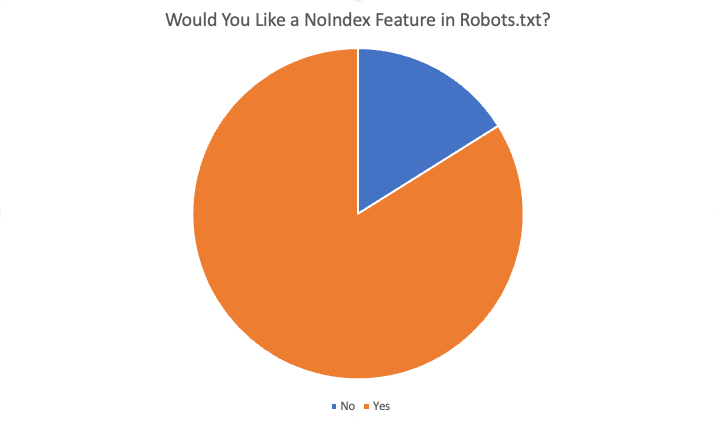
В общей сложности 84% из 87 респондентов сказали «да», они хотели бы эту функцию. Вот некоторые из причин, по которым была предложена эта функция:
- Не бывает ситуаций, когда я хочу заблокировать сканирование, но проиндексировать страницы.
- Неиндексирование большого количества страниц занимает много времени, потому что Google должен просканировать страницу, чтобы увидеть noindex. Когда у нас была директива noindex, мы могли добиться более быстрых результатов для клиентов с проблемами чрезмерной индексации.
- У нас очень большая проблема с мусором… очень старый контент… сотни старых каталогов и подкаталогов, и, по-видимому, требуются месяцы, если не годы, чтобы деиндексировать их, как только мы удаляем их и, следовательно, 404. Похоже, мы могли бы просто добавить правило NoIndex в файл robots.txt и поверить, что Google будет следовать этой инструкции гораздо быстрее, чем сканировать все старые URL-адреса с течением времени… и многократно… чтобы найти повторяющиеся ошибки 404, чтобы окончательно удалить их… так что , очистка нашего домена (доменов) — это один из способов, которым это может помочь.
- Сэкономьте усилия на разработке и легко настраивайте, если что-то сломается из-за изменений
- Невозможно всегда использовать «noindex» и проиндексировано слишком много страниц, которые не должны быть проиндексированы. Стандартная блокировка для паука также должна как минимум «не индексировать» страницы. Если я хочу, чтобы поисковая система не сканировала URL-адрес/папку, зачем мне хотеть, чтобы они индексировали эти «пустые» страницы?
- Добавление новых инструкций в файл .txt выполняется намного быстрее, чем получение ресурсов для разработчиков.
- Да, трудно изменить метаданные для корпоративной CRM, поэтому отдельная функция noindex в файле robots.txt решит эту проблему.
- Более быстрая и менее проблематичная блокировка индексации сайта :)
Другие причины для отказа включены:
- Тег noindex достаточно хорош
- Новые директивы в файле robots.txt не нужны.
- Мне это не нужно и не вижу, чтобы это работало
- Не беспокойся
- Не меняй
Резюме
Вот оно. Большинство людей, принявших участие в этом опросе, выступают за добавление этой функции. Однако имейте в виду, что читательская аудитория SEL состоит из хорошо осведомленной аудитории, обладающей гораздо большим пониманием и опытом, чем средний веб-мастер. Кроме того, даже среди положительных ответов, полученных в ходе опроса, были некоторые ответы на вопрос 4 («Получит ли эта функция вас как оптимизатора? Если да, то как»), которые указывали на непонимание того, как работает текущая система.
В конечном счете, хотя я лично хотел бы иметь эту функцию, это маловероятно.
Мнения, выраженные в этой статье, принадлежат приглашенному автору, а не обязательно поисковой системе. Штатные авторы перечислены здесь.