
Zapytaliśmy, odpowiedziałeś: Czy Google powinien dodać obsługę noindex do robots.txt? Wyniki ankiety
Opublikowany: 2021-10-05We wrześniu opublikowałem ankietę w Search Engine Land, aby sprawdzić, czy czytelnicy chcieliby otrzymać w robots.txt instrukcję oznaczania stron jako bez indeksacji. Dzisiaj przedstawię wyniki wraz z omówieniem, jakie są kluczowe kwestie (i dlaczego Google nie doda do tego wsparcia).
- Dlaczego miałoby to być interesujące?
- Jakie są wady tego pomysłu?
- Ogólne wyniki ankiety w pliku robots.txt
Dlaczego miałoby to być interesujące?
W obecnym środowisku plik robots.txt jest używany wyłącznie do sterowania zachowaniem indeksowania sieci. Co więcej, obecne podejście do oznaczania strony „NoIndex” polega na umieszczeniu tagu na samej stronie. Niestety, jeśli zablokujesz go w pliku robots.txt, Google nigdy nie zobaczy tagu i nadal może potencjalnie zaindeksować stronę, nawet jeśli nie chcesz, aby tak się stało.
W dużych witrynach stanowi to pewne wyzwanie, gdy masz różne klasy stron, których indeksowanie chcesz zablokować ORAZ trzymać z dala od indeksu Google. Jednym ze sposobów, w jaki może się to stać, są złożone implementacje nawigacji wieloaspektowej, w których tworzone są strony, które mają znaczną wartość dla użytkowników, ale w efekcie prezentują zbyt wiele stron Google. Na przykład spojrzałem na witrynę jednego sprzedawcy obuwia i odkryłem, że ma ponad 70 000 różnych stron związanych z „męskimi butami Nike”. Obejmuje to szeroką gamę rozmiarów, szerokości, kolorów i nie tylko.
W niektórych testach, w których brałem udział w przypadku witryn ze złożoną nawigacją aspektową, takich jak przykład, który udostępniłem powyżej, stwierdziliśmy, że duża liczba stron stanowi poważny problem. W jednym z tych testów pracowaliśmy z klientem, aby zaimplementować większość jego nawigacji aspektowej w AJAX, więc obecność większości stron nawigacji aspektowej była niewidoczna dla Google, ale nadal łatwo dostępna dla użytkowników. Liczba stron w tej witrynie wzrosła z 200 mln stron do 200 tys. – spadek o tysiąc do jednego. W ciągu następnego roku ruch na stronie potroił się – to zadziwiająco dobry wynik. Jednak początkowo ruch spadł, a powrót do poprzednich poziomów zajęło około 4 miesięcy, a następnie wzrósł.
W innym scenariuszu widziałem, jak witryna wdraża nową platformę e-commerce, a liczba jej stron wzrosła z około 5000 do ponad 1 miliona. Ich ruch gwałtownie spadł i zostaliśmy wezwani, aby pomóc im dojść do siebie. Poprawka? Aby przywrócić odliczanie indeksowanych stron z powrotem do miejsca, w którym było wcześniej. Niestety, ponieważ zostało to zrobione za pomocą narzędzi takich jak tagi NoIndex i Canonical, na szybkość odzyskiwania w dużej mierze wpłynął czas, jaki zajęło Google ponowne odwiedzenie znacznej liczby stron w witrynie.
W obu przypadkach wyniki dla zaangażowanych firm były uzależnione od budżetu indeksowania Google i czasu potrzebnego na wykonanie wystarczającego indeksowania, aby w pełni zrozumieć nową strukturę witryny. Posiadanie instrukcji w pliku Robots.txt przyspieszyłoby tego typu procesy.
Jakie są wady tego pomysłu?
Miałem okazję porozmawiać o tym z Patrickiem Stoxem, doradcą produktowym i ambasadorem marki w Ahrefs, który szybko zauważył: „Po prostu nie sądzę, żeby miało to miejsce przynajmniej w pliku robots.txt, być może w innym systemie, takim jak GSC. Google było jasne, że chce pliku robots.txt tylko do kontroli indeksowania. Największym minusem będą prawdopodobnie wszyscy ludzie, którzy przypadkowo usuną całą swoją witrynę z indeksu”.
I oczywiście problem usunięcia całej witryny (lub jej kluczowych części) z indeksu jest dużym problemem. W całym zakresie sieci nie musimy kwestionować, czy tak się stanie, czy nie – ZDARZE SIĘ. Niestety, może się to zdarzyć w przypadku niektórych ważnych witryn i niestety będzie się to zdarzać często.
W moim 20-letnim doświadczeniu SEO odkryłem, że nieporozumienie dotyczące korzystania z różnych tagów SEO jest powszechne. Na przykład w czasach, gdy autorstwo Google było czymś, a mieliśmy tagi rel=author, przeprowadziłem badanie, jak dobrze je zaimplementowały witryny i stwierdziłem, że 72% witryn używało tagów niepoprawnie. Obejmuje to kilka naprawdę znanych witryn w naszej branży!
W mojej rozmowie ze Stoxem zauważył dalej: „Myśląc o kolejnych wadach, muszą wymyślić, jak sobie z tym poradzić, gdy plik robots.txt nie jest tymczasowo dostępny. Czy nagle zaczynają indeksować strony, które wcześniej były oznaczone jako noindex?”
Skontaktowałem się również z Google w celu uzyskania komentarza i wskazano mi na ich wpis na blogu, gdy w 2014 r. porzucili obsługę noindex w pliku robots.txt. Oto, co ten post mówił w tej sprawie:
„Podczas gdy udostępnialiśmy naszą bibliotekę parserów, przeanalizowaliśmy wykorzystanie reguł w pliku robots.txt. W szczególności skupiliśmy się na regułach nieobsługiwanych przez wersję roboczą Internetu, takich jak opóźnienie indeksowania, nofollow i noindex. Ponieważ reguły te nigdy nie zostały udokumentowane przez Google, ich użycie w odniesieniu do Googlebota jest bardzo niskie. Poszukując dalej, zauważyliśmy, że ich użycie było sprzeczne z innymi zasadami we wszystkich plikach robots.txt z wyjątkiem 0,001% w Internecie. Błędy te szkodzą obecności witryn w wynikach wyszukiwania Google w sposób, który naszym zdaniem nie był zamierzony przez webmasterów. “
* Pogrubienie ostatniego zdania przeze mnie zostało wykonane dla podkreślenia.

Myślę, że to jest tutaj czynnikiem napędzającym. Google podejmuje działania w celu ochrony jakości swojego indeksu i to, co może wydawać się dobrym pomysłem, może mieć wiele niezamierzonych konsekwencji. Osobiście chciałbym mieć możliwość oznaczania stron dla NoCrawl i NoIndex w jasny i łatwy sposób, ale prawda jest taka, że nie sądzę, że to się stanie.
Ogólne wyniki ankiety w pliku robots.txt
Po pierwsze, chciałbym przyznać się do błędu w ankiecie w pytaniu 2, pytaniu wymaganym, zakładającym, że na pytanie 1 odpowiedziałeś „tak”. Na szczęście większość osób, które odpowiedziały „nie” na pytanie 1, kliknęło „Inne” na pytanie 2, a następnie podało powód, dla którego nie chcieli tej możliwości. Jedna z tych odpowiedzi zwróciła uwagę na tę wadę i powiedziała: „Twoja ankieta jest myląca”. Przepraszam za tę usterkę.
Ogólne wyniki przedstawiały się następująco:
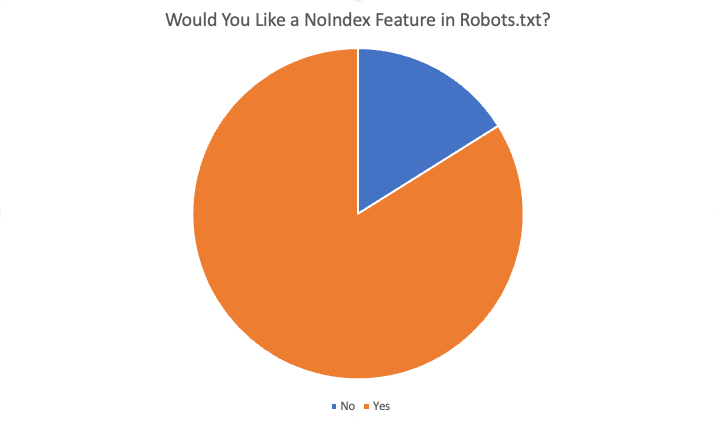
W sumie 84% z 87 respondentów odpowiedziało „tak”, chciałoby tej funkcji. Niektóre z powodów, dla których chciano skorzystać z tej funkcji, to:
- Nie ma sytuacji, w których chcę zablokować indeksowanie, ale zaindeksować strony.
- Brak indeksowania dużej liczby stron zajmuje dużo czasu, ponieważ Google musi zaindeksować stronę, aby zobaczyć noindex. Kiedy mieliśmy dyrektywę noindex, mogliśmy osiągnąć szybsze rezultaty dla klientów z problemami z nadindeksacją.
- Mamy bardzo duży problem z cruftem… bardzo stare treści… setki starych katalogów i podkatalogów, a ich odindeksowanie zajmuje pozornie miesiące, jeśli nie lata, gdy je usuniemy i ergo 404. Wygląda na to, że moglibyśmy po prostu dodać regułę NoIndex do pliku robots.txt i wierzyć, że Google zastosuje się do tej instrukcji znacznie szybciej niż przemierzanie wszystkich starych adresów URL w czasie… i wielokrotne… znajdowanie powtarzających się błędów 404, aby w końcu je usunąć… więc , jednym ze sposobów może pomóc wyczyszczenie naszych domen.
- Oszczędzaj nakłady na rozwój i łatwo regulowaj, jeśli coś się zepsuje z powodu zmian
- Nie można zawsze używać „noindex” i zbyt wielu zindeksowanych stron, które nie powinny być indeksowane. Standardowe blokowanie dla pająka powinno również „noindeksować” przynajmniej strony. Jeśli chcę, aby wyszukiwarka nie indeksowała adresu URL/folderu, dlaczego miałabym indeksować te „puste” strony?
- Dodawanie nowych instrukcji do pliku .txt jest znacznie szybsze niż uzyskiwanie zasobów deweloperskich
- Tak, trudno jest zmienić meta w głowie dla CRM dla przedsiębiorstw, więc indywidualna funkcja noindex w robots.txt rozwiązałaby ten problem.
- Szybsze, mniej problematyczne blokowanie indeksowania witryn :)
Inne powody odmowy:
- Tag Noindex jest wystarczająco dobry
- Nowe dyrektywy w pliku robots.txt nie są konieczne
- Nie potrzebuję tego i nie widzę, jak działa
- Nie kłopocz się
- Nie zmieniaj
Streszczenie
Masz to. Większość osób, które odpowiedziały na tę ankietę, opowiada się za dodaniem tej funkcji. Należy jednak pamiętać, że czytelnictwo SEL składa się z bardzo dobrze poinformowanych odbiorców – o znacznie większej wiedzy i wiedzy niż przeciętny webmaster. Ponadto, nawet wśród odpowiedzi twierdzących otrzymanych w ankiecie było kilka odpowiedzi na pytanie 4 („czy ta funkcja przyniesie korzyści jako SEO? Jeśli tak, to w jaki sposób”), które wskazywały na niezrozumienie sposobu działania obecnego systemu.
Ostatecznie jednak, chociaż osobiście chciałbym mieć tę funkcję, jest to bardzo mało prawdopodobne.
Opinie wyrażone w tym artykule są opiniami gościa i niekoniecznie Search Engine Land. Lista autorów personelu znajduje się tutaj.