
لقد سألنا ، وأجبت: هل يجب على Google إضافة دعم noindex إلى ملف robots.txt؟ نتائج الاستطلاع
نشرت: 2021-10-05في أيلول (سبتمبر) ، قدمت استطلاعًا هنا على Search Engine Land لمعرفة ما إذا كان القراء يرغبون في الحصول على تعليمات في ملف robots.txt لتمييز الصفحات لعدم وجود فهرسة. سأقدم اليوم النتائج جنبًا إلى جنب مع مراجعة ماهية المشكلات الرئيسية (ولماذا لن تضيف Google دعمًا لذلك).
- لماذا قد يكون هذا من الفائدة؟
- ما هي سلبيات هذه الفكرة؟
- نتائج استطلاع robots.txt العامة
لماذا قد يكون هذا من الفائدة؟
في البيئة الحالية ، يتم استخدام ملف robots.txt حصريًا لتوجيه سلوك زحف الويب. علاوة على ذلك ، فإن الطريقة الحالية لتمييز الصفحة "NoIndex" هي وضع علامة على الصفحة نفسها. لسوء الحظ ، إذا قمت بحظره في ملف robots.txt ، فلن يرى محرك بحث Google العلامة مطلقًا ولا يزال بإمكانه فهرسة الصفحة على الرغم من أنك لا تريد حدوث ذلك.
في المواقع الكبيرة ، يمثل هذا بعض التحديات عندما يكون لديك فئات مختلفة من الصفحات التي ترغب في منعها من الزحف وإبقائها خارج فهرس Google. تتمثل إحدى الطرق التي يمكن أن يحدث بها ذلك في عمليات تنفيذ التنقل المعقدة ذات الأوجه حيث يكون لديك صفحات تقوم بإنشائها ذات قيمة كبيرة للمستخدمين ولكنها تنتهي في النهاية بتقديم عدد كبير جدًا من الصفحات إلى Google. على سبيل المثال ، نظرت إلى أحد مواقع بيع الأحذية بالتجزئة ووجدت أن لديهم أكثر من 70000 صفحة مختلفة تتعلق بـ "أحذية نايك للرجال". يتضمن ذلك مجموعة متنوعة من الأحجام والعروض والألوان والمزيد.
في بعض الاختبارات التي شاركت فيها مع مواقع ذات تنقل معقد متعدد الأوجه مثل المثال الذي شاركته أعلاه ، وجدنا أن هذه الكمية الكبيرة من الصفحات تمثل مشكلة كبيرة. في أحد هذه الاختبارات ، عملنا مع أحد العملاء لتنفيذ معظم التنقل ذي الأوجه في AJAX ، لذا كان وجود معظم صفحات التنقل ذات الأوجه غير مرئي لـ Google ولكن لا يزال من السهل على المستخدمين الوصول إليها. انتقل عدد الصفحات لهذا الموقع من 200 مليون صفحة إلى 200 ألف صفحة - من ألف إلى واحد. خلال العام التالي ، تضاعف عدد الزيارات إلى الموقع ثلاث مرات - وكانت النتيجة جيدة بشكل مذهل. ومع ذلك ، انخفضت حركة المرور في البداية ، واستغرق الأمر حوالي 4 أشهر للعودة إلى المستويات السابقة ثم قفزت من هناك.
في سيناريو آخر ، رأيت موقعًا ينفذ نظامًا أساسيًا جديدًا للتجارة الإلكترونية وارتفع عدد صفحاته من حوالي 5000 صفحة إلى أكثر من مليون. تراجعت حركة المرور الخاصة بهم وتم إحضارنا لمساعدتهم على التعافي. المأزق؟ لإعادة الصفحة القابلة للفهرسة عد تنازليًا مرة أخرى إلى ما كانت عليه من قبل. لسوء الحظ ، نظرًا لأن هذا تم باستخدام أدوات مثل NoIndex و Canonical ، فقد تأثرت سرعة الاسترداد إلى حد كبير بالوقت الذي استغرقته Google لإعادة زيارة عدد كبير من الصفحات على الموقع.
في كلتا الحالتين ، كانت النتائج للشركات المعنية مدفوعة بميزانية الزحف الخاصة بـ Google والوقت الذي يستغرقه الزحف الكافي لفهم الهيكل الجديد للموقع بشكل كامل. سيؤدي وجود تعليمات في ملف robots.txt إلى تسريع هذه الأنواع من العمليات بسرعة.
ما هي سلبيات هذه الفكرة؟
لقد أتيحت لي الفرصة لمناقشة هذا الأمر مع باتريك ستوكس ، مستشار المنتج وسفير العلامة التجارية لشركة Ahrefs ، وكان نصه السريع: "لا أعتقد أنه سيحدث داخل ملف robots.txt على الأقل ، ربما في نظام آخر مثل GSC. كان Google واضحًا أنهم يريدون ملف robots.txt للتحكم في الزحف فقط. من المحتمل أن يكون الجانب السلبي الأكبر هو كل الأشخاص الذين يأخذون موقعهم بالكامل من الفهرس عن طريق الخطأ ".
وبالطبع ، فإن مشكلة إخراج الموقع بالكامل (أو الأجزاء الرئيسية منه) من الفهرس هي المشكلة الكبرى في هذا المجال. عبر النطاق الكامل للويب ، لا يتعين علينا التساؤل عما إذا كان هذا سيحدث أم لا - سيحدث. للأسف ، من المحتمل أن يحدث هذا مع بعض المواقع المهمة ، ولسوء الحظ ، من المحتمل أن يحدث كثيرًا.
من خلال تجربتي عبر 20 عامًا من تحسين محركات البحث ، وجدت أن سوء الفهم حول كيفية استخدام علامات تحسين محركات البحث المختلفة منتشر. على سبيل المثال ، في اليوم الذي كانت فيه حقوق التأليف في Google شيئًا وكان لدينا علامات rel = author ، قمت بدراسة مدى جودة تنفيذ المواقع لها ووجدت أن 72٪ من المواقع قد استخدمت العلامات بشكل غير صحيح. وشمل ذلك بعض المواقع المعروفة حقًا في صناعتنا!
في نقاشي مع Stox ، أشار أيضًا إلى: "عند التفكير في المزيد من الجوانب السلبية ، يجب عليهم معرفة كيفية التعامل معها عندما لا يكون ملف robots.txt متاحًا بشكل مؤقت. هل بدأوا فجأة في فهرسة الصفحات التي تم وضع علامة noindex عليها من قبل؟ "
لقد تواصلت أيضًا مع Google للتعليق ، وأشير إلى منشور المدونة الخاص بهم عندما أسقطوا دعم noindex في ملف robots.txt مرة أخرى في عام 2014. هذا ما قاله المنشور حول الأمر:
"أثناء فتح مكتبة المحلل اللغوي لدينا ، قمنا بتحليل استخدام قواعد robots.txt. على وجه الخصوص ، ركزنا على القواعد التي لا تدعمها مسودة الإنترنت ، مثل crawl-delay و nofollow و noindex. نظرًا لأن Google لم يوثق هذه القواعد مطلقًا ، فمن الطبيعي أن يكون استخدامها فيما يتعلق بـ Googlebot منخفضًا جدًا. لمزيد من البحث ، وجدنا أن استخدامها يتعارض مع القواعد الأخرى في جميع ملفات robots.txt على الإنترنت باستثناء 0.001٪. تضر هذه الأخطاء بوجود مواقع الويب في نتائج بحث Google بطرق لا نعتقد أن مشرفي المواقع يقصدونها. "
* تم كتابة الجملة الأخيرة من قبلي للتأكيد.

أعتقد أن هذا هو العامل الدافع هنا. تعمل Google على حماية جودة فهرسها وما قد يبدو فكرة جيدة يمكن أن يكون له العديد من النتائج غير المقصودة. أنا شخصياً أحب أن أمتلك القدرة على تمييز الصفحات لكل من NoCrawl و NoIndex بطريقة واضحة وسهلة ، لكن حقيقة الأمر هي أنني لا أعتقد أن ذلك سيحدث.
نتائج استطلاع robots.txt العامة
أولاً ، أود أن أقر بوجود خلل في الاستطلاع في هذا السؤال 2 ، وهو سؤال مطلوب ، يفترض أنك أجبت على السؤال 1 بـ "نعم". لحسن الحظ ، قام معظم الأشخاص الذين أجابوا بـ "لا" على السؤال 1 بالنقر فوق "أخرى" للسؤال 2 ثم أدخلوا سببًا لعدم رغبتهم في هذه الإمكانية. لاحظ أحد هذه الردود هذا الخلل وقال ، "استطلاعك مضلل". اعتذاري عن الخلل هناك.
وجاءت النتائج الإجمالية على النحو التالي:
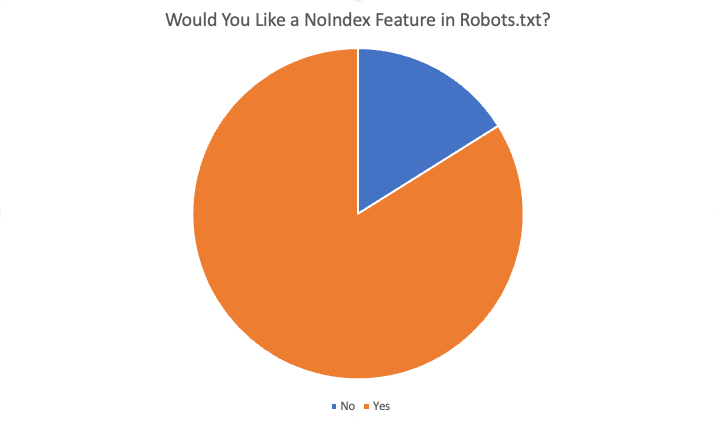
في المجموع ، قال 84٪ من المجيبين البالغ عددهم 87 "نعم" ، إنهم يرغبون في هذه الميزة. بعض الأسباب التي قدمت لرغبتك في هذه الميزة هي:
- لا توجد مواقف أريد فيها منع الزحف ولكن لدي صفحات مفهرسة.
- يستغرق Noindexing عددًا كبيرًا من الصفحات وقتًا طويلاً لأن Google يتعين عليه الزحف إلى الصفحة لرؤية noindex. عندما كان لدينا توجيه noindex ، تمكنا من تحقيق نتائج أسرع للعملاء الذين يعانون من مشاكل الإفراط في الفهرسة.
- لدينا مشكلة تلاعب كبيرة جدًا ... محتوى قديم جدًا ... مئات من الدلائل والأدلة الفرعية القديمة ويستغرق الأمر على ما يبدو شهورًا إن لم يكن سنوات لإلغاء فهرستها بمجرد حذفها و ergo 404. يبدو أنه يمكننا فقط إضافة قاعدة NoIndex في ملف robots.txt ونعتقد أن Google ستلتزم بهذه التعليمات بشكل أسرع بكثير من الاضطرار إلى الزحف إلى جميع عناوين URL القديمة بمرور الوقت ... وبشكل متكرر ... للعثور على تكرار 404 لحذفها نهائيًا ... لذلك ، فإن تنظيف المجال (المجالات) الخاص بنا هو إحدى الطرق التي قد تساعد.
- وفر جهد التطوير وقابل للتعديل بسهولة إذا حدث شيء ما بسبب التغييرات
- لا يمكن دائمًا استخدام "noindex" والعديد من الصفحات المفهرسة والتي لا يجب فهرستها. يجب أن يكون الحظر القياسي للعنكبوت أيضًا "noindex" للصفحات على الأقل. إذا كنت أرغب في عدم قيام محرك بحث بالزحف إلى عنوان URL / مجلد ، فلماذا أرغب في فهرسة هذه الصفحات "الفارغة"؟
- تعد إضافة إرشادات جديدة إلى ملف .txt أسرع بكثير من الحصول على موارد Dev
- نعم ، من الصعب تغيير التعريف في إدارة علاقات العملاء للمؤسسات ، لذا فإن ميزة noindex الفردية في ملف robots.txt ستحل هذه المشكلة.
- حظر فهرسة المواقع بشكل أسرع وأقل إشكالية :)
تشمل الأسباب الأخرى لقول لا:
- علامة Noindex جيدة بما فيه الكفاية
- التوجيهات الجديدة في ملف robots.txt ليست ضرورية
- لا أحتاجه ولا أرى أنه يعمل
- لا تهتم
- لا تغير
ملخص
ها أنت ذا. يفضل معظم الأشخاص الذين أجابوا على هذا الاستطلاع إضافة هذه الميزة. ومع ذلك ، ضع في اعتبارك أن قراء SEL يتألفون من جمهور واسع المعرفة - يتمتعون بفهم وخبرة أكبر بكثير من مشرف الموقع العادي. بالإضافة إلى ذلك ، حتى بين الردود التي تم تلقيها بنعم في الاستطلاع ، كانت هناك بعض الردود على السؤال 4 ("هل ستفيدك هذه الميزة كمحسِّن لمحركات البحث؟ إذا كان الأمر كذلك ، كيف") التي تشير إلى سوء فهم لطريقة عمل النظام الحالي.
في النهاية ، على الرغم من أنني شخصياً أحب أن أمتلك هذه الميزة ، فمن غير المرجح أن تحدث.
الآراء الواردة في هذا المقال هي آراء المؤلف الضيف وليست بالضرورة آراء محرك البحث. يتم سرد المؤلفين الموظفين هنا.