
Abbiamo chiesto, hai risposto: Google dovrebbe aggiungere il supporto noindex a robots.txt? Risultati del sondaggio
Pubblicato: 2021-10-05A settembre, ho pubblicato un sondaggio qui su Search Engine Land per vedere se i lettori vorrebbero avere un'istruzione in robots.txt per contrassegnare le pagine per Nessuna indicizzazione. Oggi presenterò i risultati insieme a una rassegna di quali sono i problemi chiave (e perché Google non aggiungerà il supporto per questo).
- Perché questo dovrebbe interessare?
- Quali sono gli svantaggi di questa idea?
- Risultati complessivi del sondaggio robots.txt
Perché questo dovrebbe interessare?
Nell'ambiente attuale, robots.txt viene utilizzato esclusivamente per guidare il comportamento della scansione web. Inoltre, l'approccio corrente per contrassegnare una pagina "NoIndex" consiste nel posizionare un tag sulla pagina stessa. Sfortunatamente, se lo blocchi in robots.txt, Google non vedrà mai il tag e potrebbe comunque indicizzare la pagina anche se non vuoi che ciò accada.
Sui siti di grandi dimensioni, ciò presenta alcune difficoltà quando si hanno classi diverse di pagine di cui si desidera bloccare la scansione E tenere fuori dall'indice di Google. Un modo in cui ciò può accadere è in complesse implementazioni di navigazione a faccette in cui hai pagine che crei che hanno un valore significativo per gli utenti ma finiscono per presentare troppe pagine a Google. Ad esempio, ho esaminato il sito Web di un rivenditore di scarpe e ho scoperto che ha oltre 70.000 pagine diverse relative a "Scarpe Nike da uomo". Ciò include un'ampia varietà di dimensioni, larghezze, colori e altro ancora.
In alcuni test a cui ho partecipato con siti con una navigazione complessa a faccette come l'esempio che ho condiviso sopra, abbiamo riscontrato che questa grande quantità di pagine è un problema significativo. Per uno di questi test, abbiamo collaborato con un cliente per implementare la maggior parte della sua navigazione a faccette in AJAX in modo che la presenza della maggior parte delle sue pagine di navigazione a faccette fosse invisibile a Google ma comunque facilmente accessibile dagli utenti. Il conteggio delle pagine per questo sito è passato da 200 milioni di pagine a 200.000 pagine, da mille a una riduzione. Nel corso dell'anno successivo, il traffico verso il sito è triplicato, un risultato sorprendentemente buono. Tuttavia, inizialmente il traffico è diminuito e ci sono voluti circa 4 mesi per tornare ai livelli precedenti e da lì è salito.
In un altro scenario, ho visto un sito implementare una nuova piattaforma di e-commerce e il numero di pagine è aumentato da circa 5.000 pagine a oltre 1 milione. Il loro traffico è precipitato e siamo stati portati per aiutarli a riprendersi. La soluzione? Per riportare la pagina indicizzabile di nuovo al punto in cui era prima. Sfortunatamente, poiché ciò è stato fatto con strumenti come NoIndex e tag Canonical, la velocità di ripristino è stata ampiamente influenzata dal tempo impiegato da Google per rivisitare un numero significativo di pagine del sito.
In entrambi i casi, i risultati per le aziende coinvolte sono stati guidati dal budget di scansione di Google e dal tempo impiegato per eseguire una scansione sufficiente per comprendere appieno la nuova struttura del sito. Avere un'istruzione in Robots.txt accelererebbe rapidamente questi tipi di processi.
Quali sono gli svantaggi di questa idea?
Ho avuto l'opportunità di discuterne con Patrick Stox, consulente di prodotto e ambasciatore del marchio per Ahrefs, e la sua rapida opinione è stata: “Semplicemente non credo che accadrà almeno all'interno di robots.txt, forse all'interno di un altro sistema come GSC. Google era chiaro che volevano robots.txt solo per il controllo della scansione. Il più grande svantaggio saranno probabilmente tutte le persone che eliminano accidentalmente l'intero sito dall'indice".
E, naturalmente, questo problema dell'intero sito (o parti chiave di un sito) che viene rimosso dall'indice è il grosso problema con esso. Nell'intero ambito del Web, non dobbiamo chiederci se ciò accadrà o meno: accadrà. Purtroppo, è probabile che accada con alcuni siti importanti e, sfortunatamente, probabilmente accadrà molto.
Nella mia esperienza in 20 anni di SEO, ho scoperto che un malinteso su come utilizzare vari tag SEO è dilagante. Ad esempio, ai tempi in cui Google Authorship era una cosa e avevamo i tag rel=author, ho fatto uno studio su come i siti li implementassero e ho scoperto che il 72% dei siti aveva utilizzato i tag in modo errato. Ciò includeva alcuni siti davvero famosi nel nostro settore!
Nella mia discussione con Stox, ha inoltre osservato: “Pensando a più aspetti negativi, devono capire come trattarlo quando un file robots.txt non è temporaneamente disponibile. Improvvisamente iniziano a indicizzare le pagine che prima erano contrassegnate come noindex?"
Ho anche contattato Google per un commento e sono stato indirizzato al loro post sul blog quando hanno abbandonato il supporto per noindex in robots.txt nel 2014. Ecco cosa diceva il post sulla questione:

"Durante l'open source della nostra libreria di parser, abbiamo analizzato l'utilizzo delle regole robots.txt. In particolare, ci siamo concentrati sulle regole non supportate dalla bozza di Internet, come crawl-delay, nofollow e noindex. Poiché queste regole non sono mai state documentate da Google, naturalmente il loro utilizzo in relazione a Googlebot è molto basso. Scavando ulteriormente, abbiamo visto che il loro utilizzo era contraddetto da altre regole in tutto tranne lo 0,001% di tutti i file robots.txt su Internet. Questi errori danneggiano la presenza dei siti web nei risultati di ricerca di Google in modi che non pensiamo siano pensati dai webmaster. “
* Il grassetto dell'ultima frase da parte mia è stato fatto per enfasi.
Penso che questo sia il fattore trainante qui. Google agisce per proteggere la qualità del suo indice e quella che può sembrare una buona idea può avere molte conseguenze indesiderate. Personalmente, mi piacerebbe avere la possibilità di contrassegnare le pagine sia per NoCrawl che per NoIndex in modo chiaro e semplice, ma la verità è che non credo che accadrà.
Risultati complessivi del sondaggio robots.txt
In primo luogo, vorrei riconoscere un difetto nel sondaggio in quella domanda 2, una domanda obbligatoria, presupponendo che tu abbia risposto alla domanda 1 con un "sì". Per fortuna, la maggior parte delle persone che hanno risposto "no" alla domanda 1 hanno fatto clic su "Altro" per la domanda 2 e quindi hanno inserito un motivo per cui non volevano questa capacità. Una di queste risposte ha notato questo difetto e ha detto: "Il tuo sondaggio è fuorviante". Mi scuso per il difetto lì.
I risultati complessivi sono stati i seguenti:
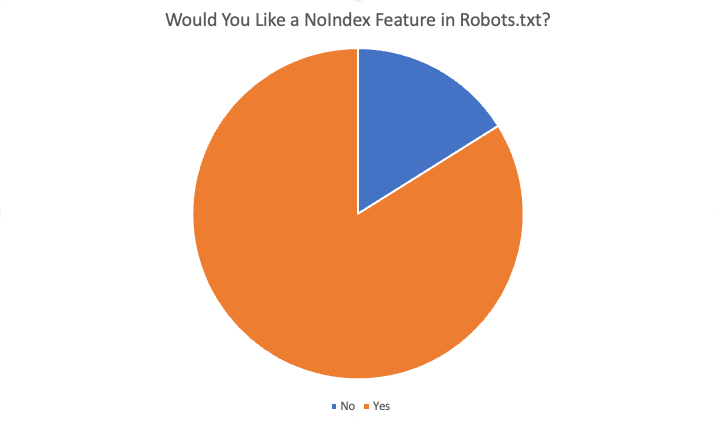
In totale l'84% degli 87 intervistati ha detto "sì", vorrebbe questa funzione. Alcuni dei motivi offerti per volere questa funzione sono stati:
- Non ci sono situazioni in cui voglio bloccare la scansione ma avere le pagine indicizzate.
- Il noindex di un gran numero di pagine richiede molto tempo perché Google deve eseguire la scansione della pagina per vedere il noindex. Quando abbiamo avuto la direttiva noindex abbiamo potuto ottenere risultati più rapidi per i clienti con problemi di sovraindicizzazione.
- Abbiamo un grosso problema di cruft... contenuto molto vecchio... centinaia di vecchie directory e sottodirectory e ci vogliono apparentemente mesi se non anni per dei-indicizzarle una volta che le eliminiamo ed ergo 404. Sembra che potremmo semplicemente aggiungere la regola NoIndex nel file robots.txt e credere che Google aderirebbe a questa istruzione molto più velocemente che dover eseguire la scansione di tutti i vecchi URL nel tempo ... e ripetutamente ... per trovare 404 ripetuti per eliminarli finalmente ... quindi , ripulire i nostri domini è un modo per aiutare.
- Risparmia lo sforzo di sviluppo e facilmente regolabile se qualcosa si rompe a causa delle modifiche
- Non è possibile utilizzare sempre un "noindex" e troppe pagine indicizzate che non dovrebbero essere indicizzate. Il blocco standard per spider dovrebbe anche "noindex" almeno le pagine. Se voglio che un motore di ricerca non esegua la scansione di un URL/cartella, perché dovrei voler indicizzare queste pagine "vuote"?
- L'aggiunta di nuove istruzioni a un file .txt è molto più veloce che ottenere le risorse di sviluppo
- Sì, è difficile cambiare meta in testa per il CRM aziendale, quindi la singola funzione noindex in robots.txt risolverebbe il problema.
- Blocco dell'indicizzazione del sito più rapido e meno problematico :)
Altri motivi per dire di no includevano:
- Il tag Noindex è abbastanza buono
- Non sono necessarie nuove direttive nel file robots.txt
- Non mi serve e non lo vedo funzionare
- Non preoccuparti
- Non cambiare
Sommario
Ecco qua. La maggior parte delle persone che hanno risposto a questo sondaggio è favorevole all'aggiunta di questa funzione. Tuttavia, tieni presente che i lettori di SEL sono costituiti da un pubblico altamente competente, con molta più comprensione e competenza rispetto al webmaster medio. Inoltre, anche tra le risposte sì ricevute nel sondaggio, c'erano alcune risposte alla domanda 4 ("questa funzionalità ti gioverebbe come SEO? Se sì, come") che indicavano un malinteso sul modo in cui funziona il sistema attuale.
In definitiva, però, mentre personalmente mi piacerebbe avere questa funzione, è altamente improbabile che accada.
Le opinioni espresse in questo articolo sono quelle dell'autore ospite e non necessariamente di Search Engine Land. Gli autori dello staff sono elencati qui.