
GoogleDiscoverでランクを上げるための6つの戦術
公開: 2021-11-24GoogleのDiscoverフィードは、モバイルユーザーにユーザーの興味に基づいたコンテンツのストリームを提供します。 コンテンツを掲載することに成功した出版物の場合、Discoverフィードは大量のトラフィックを促進する可能性がありますが、残念ながら、「Discoverのインタレストマッチングを明示的にターゲットとするコンテンツを作成する方法はありません」と、グローバルオーディエンス開発戦略担当副社長のJohnShehata氏は述べています。コンデナストのCRMは、SMXNextでのセッション中にGoogleを引用して述べました。
「それは絶対に真実ですが、GoogleDiscoverで上位にランクインする可能性を高めるために[できること]がいくつかあります」と彼は付け加えました。 Shehataは、過去90日間に100万ページ(270億インプレッションに相当)から取得したデータを使用して、自身の経験と並行して、パブリッシャーがGoogleDiscoverでランク付けする能力を強化するために使用できる次の戦術を提供しました。
クリックベイトではなく、感情的なタイトルを使用する
「GoogleDiscoverで非常に優れたパフォーマンスを発揮するタイトルを分析したところ、[CTRが25%を超え、インプレッション数が10,000以上の上位のタイトル]です。 。 。 それらの多くが「クリックベイト」のその領域にあることがわかります。それで、おとり商法はありますか?」 シェハタは言った。

「いいえ、それはうまくいきません。1つのことを約束してサイトにアクセスし、それがまったく別のものである場合、Googleはこれを非常によく認識できますが、感情的なタイトルは依然として非常にうまく機能します」と彼は指摘し、クリックベイト、とんでもないタイトル、効果的な感情的要素を持つタイトルの間の細い線。
さらに、Shehataがプレゼンテーション全体で使用したGD Dashのデータによると、Discoverの上位100件の記事(25%以上のCTRと10,000回を超えるインプレッション)の13%がリスティクルでした。 Discoverトラフィックを引き付けようとしているブランドの場合、Shehataは10項目のリスティクルを使用しないように警告しています。 人々はそれが一般的であり、作り上げられたリストであると考えているので、「10」を避けるようにしてください」と彼は言いました。
高品質のビジュアルを含める
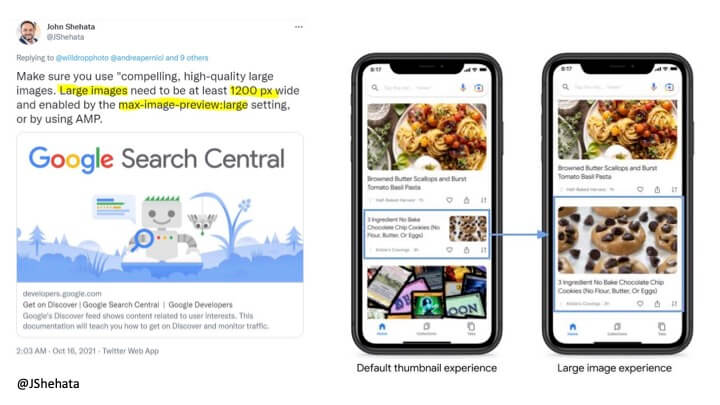
「これがどれほど重要かを強調することはできません」とシェハタは強調し、次のガイダンスを提供しました。
- 大きな画像は、幅が1200ピクセル以上で、max-image-preview:large設定またはAMPを使用して有効にする必要があります。 「これにより、左側の[上のスクリーンショットの]このような小さな画像が、全幅の画像である右側のサイズに転送されます」と彼は付け加えました。 。」
- ヒーロー画像には16:9のアスペクト比を使用します。
- 画像としてサイトのロゴを使用することは避けてください。
- 操作されたメディアは避けてください。
- 画像にはわかりやすいファイル名を使用してください。
- 適切な代替テキストを追加します。
- 説明的なキャプションを使用します。
EAT信号を理解して強化する
SearchとDiscoverは異なる製品ですが、コンテンツに適用されるEATの全体的な原則は類似しています。 2020年に、GoogleはDiscoverガイドラインにEAT(専門知識、信頼性、信頼性)という用語を追加しました。 「このフレーズはこれまでにありませんでした。彼らはGoogleDiscoverのコンテンツを評価するときにEATを検討する予定です。」とShehata氏は述べています。

コンテンツ内でEATをデモンストレーションすると、信頼性が高く、誤った情報がなく、ユーザーにサービスを提供するため、推奨する価値があることをGoogleに納得させることができます。 EATを増やす1つの方法は、作成者ページを最適化することです。

「特定の例外があるため、できる限り避けるようにしてください。「スタッフによる作成」または「管理者による作成」」とシェハタ氏は記事の執筆について述べています。「これは、適切なEATまたは信頼のシグナルを転送しません。」
彼はまた、グーグルとあなたの読者のためにあなたのEATを強化するために以下の方法を提供しました:

- HTTPSを使用してサイトを保護します。
- 記事に日付、署名記事、著者に関する情報を含めます。
- 出版物、出版社、および/またはその背後にある会社に関する情報を提供します。
- 信頼性と透明性を高めるために連絡先情報を含めます。
- 著者のソーシャルメディアプロファイルへのリンク。
APIを使用して、ブランドに役立つトピックとエンティティを特定します
DiscoverデータがGoogleSearchConsole Search Analytics APIで利用できるようになったため、パブリッシャーはGoogleの自然言語処理を利用して、どのエンティティがオーディエンスに関心を持ち、出版物に取り組んでいるかを特定できます。
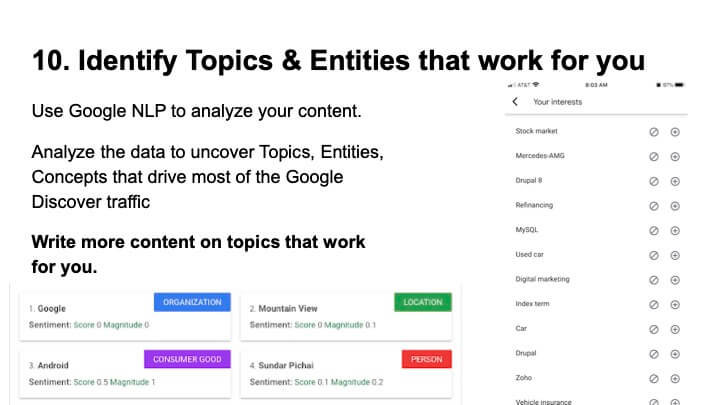
「GoogleDiscoverAPIを利用してGoogleの自然言語処理を実行すると、どのトピックが効果的かがわかり始めます」とShehata氏は述べ、Googleはすでにこれらのトピックを考慮しているため、サイト運営者は「これらのトピックを2倍にする」必要があると付け加えました。それらの主題に関する権威。
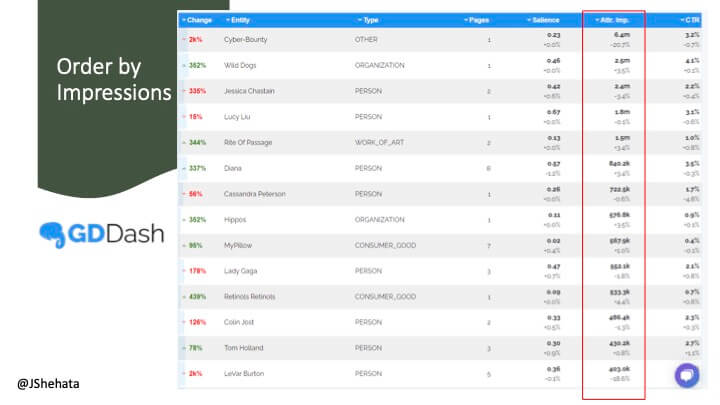
これらのトピックは、表示回数、クリック率、またはページ数で並べ替えることができます。 インプレッションで並べ替えると、最も可視性が高く、ひいては権限を持つトピックが表示されます。 CTRで注文すると、視聴者がどのトピックに取り組んでいるかがわかります。 また、たとえば、ページ数で並べ替えたり、CTRを参照したりすると、コンテンツを改善する機会を特定するのに役立ちます。
常緑のコンテンツを更新する
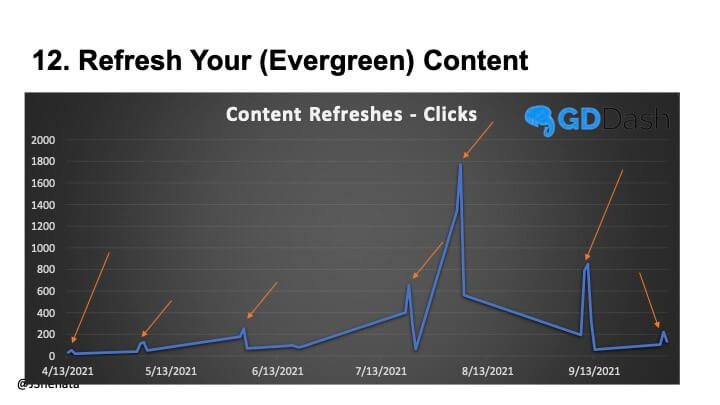
常緑樹のコンテンツを更新すると、追加のDiscoverトラフィックを促進するのに役立ちます。 下の画像では、記事が更新されるたびにクリック数が急増しています。
関連:常緑樹のコンテンツに新鮮な生命を吹き込む方法(そして新鮮なトラフィックを獲得する方法)
出版社は必ず同じURLを使用し、時々見出しを微調整する必要があります、とShehataは推奨しました。
GoogleDiscoverデータを理解する
ベースラインを確立すると、データがコンテキスト化され、平均を上回った、または下回ったストーリーがわかります。 そのためには、次のことを理解することが重要です。
- カテゴリごとの平均CTR。
- ストーリーごとの平均インプレッション。 と
- ストーリーごとの平均寿命。
Discoverからのトラフィックは、Google Analyticsでは「直接」に分類されることを理解することも重要です(上のスクリーンショットを参照)。 「GoogleAnalyticsの直接トラフィックの約25%から30%がDiscoverトラフィックであると想定しているので、これに注意してください」とShehata氏は述べています。
GoogleDiscoverは補足チャネルであることを忘れないでください
「注意の言葉。 。 。 Google Discoveryのトラフィックに夢中になってはいけないことを知ってもらいたいと思います。それは予測不可能であり、SEOのコア戦略と見なされるべきではありません」とShehata氏は述べています。 追加のトラフィックはビジネス目標の達成に役立つ可能性がありますが、ユーザーや関心事をターゲットにする方法がないため、Discoverに依存してトラフィックの一貫したストリームを配信することはできません。
そうは言っても、Shehataが取り上げたトピックのほとんどは、通常の検索戦略にも役立つため、Discoverを特に最適化するために追加の作業を行う必要はほとんどありませんが、トラフィックが増える可能性があります。
ここで完全なSMXNextプレゼンテーションをご覧ください(登録が必要です)。
この記事で表明された意見はゲスト著者の意見であり、必ずしも検索エンジンランドではありません。 スタッフの作者はここにリストされています。