
精選片段框架:我如何成為精選片段
已發表: 2018-03-06
與 WordLift 的團隊一起,我們嘗試每天進行實驗以跟上 Google 搜索算法的發展。 事實上,谷歌的搜索算法是一種黑盒,你知道輸入A和輸出B,但不能確定黑盒中發生了什麼使A變成B。最有效的方法是測試看看什麼動作會觸發特定的結果。
基於幾個月前,WordLift 聯合創始人 Andrea Volpini ,我們開始在我的博客上試驗特色片段. 事實上,這是谷歌用來回答用戶特定問題的一項功能。 該功能非常重要,因為它在某種程度上與語音搜索相關聯。 事實上,谷歌作為特色片段提供的內容通常也會被用作由谷歌搜索算法提供支持的數字助理語音搜索的答案。
長話短說,幾個月前我很想知道我是否可以在一個簡單的問題上觸發精選片段:“誰是 Gennaro Cuofano?” 來自我在博客上創建的頁面.

自實驗開始近三個月後,特色片段終於被觸發了。
為什麼這很重要?
儘管這看起來微不足道,但事實並非如此。 事實上,當信息來自權威網頁時,通常會觸發精選片段。 此外,當涉及到人時,通常會在 Wikipedia 中存在頁面時觸發 Google 的精選片段。 它很少會觸發一個人的精選片段,這不是來自那裡。 然而,這一次不同。 谷歌的搜索算法在一個具有低域權限的網站上觸發了一個精選片段(當我開始實驗時,我的博客的域權限為 19)。 此外,精選片段是關於我自己的。 我既不是公眾人物,也沒有維基百科頁面。
這怎麼可能?
在我們開始之前,讓我澄清一下為什麼精選片段對個人品牌很重要。
為什麼選擇個人品牌的精選片段?
谷歌是信息的最終來源。 超過 40 億次搜索每天都要經歷它。 從諸如“如何打領帶”之類的實際問題到更複雜的問題“如何購買漣漪”,再到諸如“我為什麼如此情緒化”之類的存在性問題。 不管我們都期望谷歌給我們什麼最終的答案,可以解決我們的任何問題!
今天,人們對谷歌的信任超過了純在線媒體。 事實上,在對 28 個國家的 33,000 多人進行的一項調查中,63% 的人表示他們信任搜索引擎,而僅在線媒體的這一比例僅為 53%:
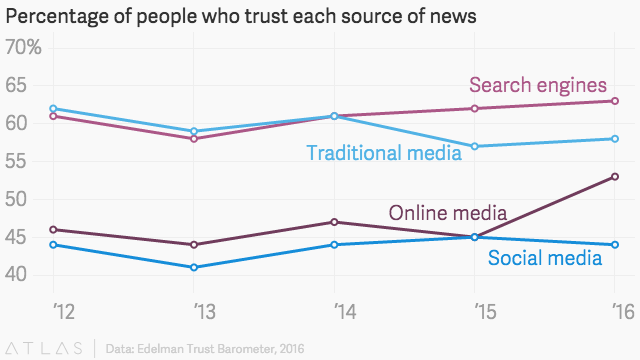
這是什麼意思呢?
簡而言之,如果“谷歌這麼說,那麼它一定是這樣”。 換句話說,能夠通過觸發 Google 的精選片段來控制您的個人和公司品牌可能是品牌的未來。 事實上,谷歌將使用相同的特色片段來執行通過谷歌主頁和其他個人數字助理髮出的語音搜索命令。
個人品牌的精選片段框架
通過 WordLift 的團隊,我們確定了一些關鍵步驟,可將您的內容從零變為精選片段,這些步驟圍繞以下五個支柱展開:
- 像維基百科一樣思考
- 使用基於實體的內容模型
- 將其轉換為 Google 喜歡的數據
- 向外鏈接
- 向內鏈接
讓我們一一深入了解它們。
想想維基百科:簡短、對話並避免講故事
要獲得精選片段,您必須將頁面上的內容視為您在 Wikipedia 上看到的個人簡介。 簡而言之,這是簡短的(至少是介紹),對話式的,但最重要的是它必須基於事實。
例如,如果您查看我設置的頁面戰略性地為特色片段有一些明顯的特點:
- 大約六十個字(更準確地說是58個字)
- 它針對一個特定問題(Gennaro Cuofano 是誰?)
- 它與我在 LinkedIn 個人資料中的信息相匹配(這對於允許 Google 的算法檢查數據的真實性很重要)
按照這些說明創建您的特色片段就緒頁面。

基於實體的內容模型:進入語義網
正如我在之前的 SEP Semantic SEO 文章中所解釋的那樣已成為您整體數字營銷策略中最強大的策略之一。 關鍵字仍然相對相關,但是,隨著 Google 變得越來越聰明,您可能希望在您的方法中包含基於實體的內容模型。

簡而言之,為了讓我的頁面更易於理解、為 Google 編制索引和排名,我將我的頁面轉換為實體頁面。 在語義 SEO 的上下文中,一個實體是存在於網絡上的獨特事物。 在這種特定情況下,我將頁面轉換為 Schema 實體類型“人”:
實際上,你是怎麼做到的? 為此,我使用了 WordLift:

這第一步有助於 Google 了解我設置的頁面是關於一個人的。 現在,我如何讓 Google 知道我們所說的人就是我自己?
從超鏈接到開放鏈接
正如我在 SEP 的文章中所解釋的:
當您在網頁上實現模式標記時,您已經生成了結構化數據。 在這些數據作為元數據發佈到網絡上的那一刻,它就變成了開放數據; 當該數據被連接時,它成為打開的鏈接數據。
那是一種簡化。 但主要的一點是,開放的鏈接數據是另一個對獲得精選片段有重大影響的方面。 事實上,谷歌的機器人喜歡 5 星開放數據,正如 5stardata.info 上所解釋的,它包括以下步驟:

資料來源: 我是如何設法在該頁面上生成 5 星開放數據的?
當我使用 WordLift 創建架構標記,軟件還會為頁面生成一個唯一的ID,遵循5星開放數據標準:

向外鏈接:參考的力量
當您設置了專用頁面並執行了上述所有步驟後,您需要為 Google 提供更多背景信息,並確保為其提供更多資源來備份您提供的信息。
這就是為什麼鏈接到 Google 可能能夠找到有關您的數據的網站至關重要的原因。 事實上,在我使用 WordLift 設置的這個頁面中,該軟件讓我可以選擇設置其他字段,這使我可以指向其他網站(LinkedIn、Quora、亞馬遜等),Google 可以在其中找到有關我的信息。 頁面上的用戶看不到這些鏈接。 然而谷歌做到了! 這就是您如何讓 Google 的機器人有機會“核實”所提供的數據。

向內鏈接:榨汁!
一旦創建了一個關於你的頁面。 確保將其鏈接回有意義的位置。 例如,如果您在另一個網站上發布訪客帖子,請確保將您的姓名鏈接到您的頁面,就像我在下面所做的那樣:

這將提高谷歌頁面的權威性,從而使其更接近片段!
總結和結論
過去幾個月在 WordLift 的團隊,我們一直在對精選片段進行大量試驗。 在從我們的行動中看到一致的結果後,我們組合了一個特色片段框架。 這包括一些關鍵策略,總結在上面的五個步驟中。
這些策略不能孤立地發揮作用,而是需要完全實施。 Schema 和 5 星開放數據共同構成了精選片段的支柱。 然而,為了幫助谷歌的機器人,用其他三種策略補充這一戰略至關重要。
首先,嘗試定位一個長尾關鍵詞,提供一個簡短的、對話式的但沒有講故事的答案。 其次,參考有助於 Google 評估所提供信息質量的其他來源。 第三,鏈接回該頁面,使其更相關,更接近代碼段。
要討論這個框架,請隨時在 LinkedIn 上與我聯繫.
一點警告:為此,請使用 Google 隱身。 然後點擊頁面右下角的“設置”。 選擇設置,然後選擇“搜索設置”。 在搜索設置中選擇“美國”並保存。 返回您的搜索框並詢問“誰是 Gennaro Cuofano?”