
คู่มือการเรียนรู้ของเครื่องในการค้นหา: คำสำคัญ แนวคิด และอัลกอริทึม
เผยแพร่แล้ว: 2022-05-02เมื่อพูดถึงแมชชีนเลิร์นนิง มีแนวคิดและคำศัพท์กว้างๆ ที่ทุกคนในการค้นหาควรรู้ เราทุกคนควรรู้ว่าแมชชีนเลิร์นนิงใช้ที่ใด และแมชชีนเลิร์นนิงประเภทต่าง ๆ ที่มีอยู่
อ่านต่อไปเพื่อให้เข้าใจมากขึ้นว่าแมชชีนเลิร์นนิงส่งผลต่อการค้นหาอย่างไร สิ่งที่เสิร์ชเอ็นจิ้นกำลังทำ และวิธีรับรู้แมชชีนเลิร์นนิงในที่ทำงาน เริ่มจากคำจำกัดความกันก่อน จากนั้นเราจะเข้าสู่อัลกอริทึมและโมเดลการเรียนรู้ของเครื่อง
เงื่อนไขการเรียนรู้ของเครื่อง
ต่อไปนี้เป็นคำจำกัดความของคำศัพท์แมชชีนเลิร์นนิงที่สำคัญ ซึ่งส่วนใหญ่จะกล่าวถึงในบางประเด็นในบทความ ไม่ได้มีวัตถุประสงค์เพื่อเป็นอภิธานศัพท์ที่ครอบคลุมของคำศัพท์การเรียนรู้ของเครื่องทุกคำ หากคุณต้องการสิ่งนั้น Google มีข้อเสนอที่ดีที่นี่
- อัลกอริธึม : กระบวนการทางคณิตศาสตร์ทำงานบนข้อมูลเพื่อสร้างผลลัพธ์ มีอัลกอริธึมหลายประเภทสำหรับปัญหาการเรียนรู้ของเครื่องที่แตกต่างกัน
- ปัญญาประดิษฐ์ (AI) : สาขาวิทยาการคอมพิวเตอร์ที่เน้นการจัดเตรียมคอมพิวเตอร์ให้มีทักษะหรือความสามารถที่ทำซ้ำหรือได้รับแรงบันดาลใจจากสติปัญญาของมนุษย์
- คลัง ข้อมูล : ชุดข้อความที่เป็นลายลักษณ์อักษร มักจะจัดในลักษณะใด
- นิติบุคคล : สิ่งของหรือแนวคิดที่มีเอกลักษณ์เฉพาะ เอกพจน์ กำหนดชัดเจนและแยกแยะได้ คุณสามารถคิดคร่าวๆ ว่าเป็นคำนามได้ แม้ว่ามันจะกว้างกว่านั้นเล็กน้อย สีแดงที่เฉพาะเจาะจงจะเป็นตัวตน มันมีความพิเศษและเฉพาะตัวตรงที่ว่าไม่มีอย่างอื่นเหมือนหรือไม่ มันมีการกำหนดไว้อย่างดี (คิดว่าเป็นรหัสฐานสิบหก) และแยกแยะได้ตรงที่คุณสามารถแยกความแตกต่างจากสีอื่นๆ ได้
- การเรียนรู้ของเครื่อง : สาขาวิชาปัญญาประดิษฐ์ที่เน้นการสร้างอัลกอริธึม โมเดล และระบบเพื่อทำงาน และโดยทั่วไปจะปรับปรุงตัวเองในการทำงานนั้นโดยไม่ได้ตั้งโปรแกรมไว้อย่างชัดเจน
- โมเดล: โมเดลมักสับสนกับอัลกอริทึม ความแตกต่างอาจไม่ชัดเจน (เว้นแต่คุณจะเป็นวิศวกรการเรียนรู้ของเครื่อง) โดยพื้นฐานแล้ว ความแตกต่างก็คือเมื่ออัลกอริทึมเป็นเพียงสูตรที่สร้างมูลค่าเอาต์พุต โมเดลคือการแสดงสิ่งที่อัลกอริธึมสร้างขึ้นหลังจากผ่านการฝึกอบรมสำหรับงานเฉพาะ ดังนั้น เมื่อเราพูดว่า "แบบจำลอง BERT" เรากำลังหมายถึง BERT ที่ได้รับการฝึกอบรมสำหรับงาน NLP เฉพาะ (ซึ่งงานและขนาดของแบบจำลองจะกำหนดแบบจำลอง BERT เฉพาะใด)
- การประมวลผลภาษาธรรมชาติ (NLP): คำทั่วไปที่ใช้อธิบายสาขาของงานในการประมวลผลข้อมูลตามภาษาเพื่อให้งานเสร็จสมบูรณ์
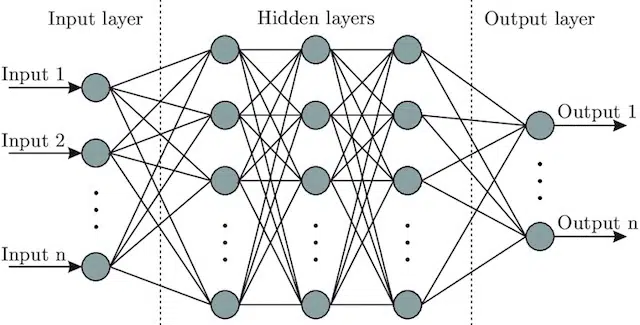
- โครงข่ายประสาทเทียม : สถาปัตยกรรมแบบจำลองที่รับแรงบันดาลใจจากสมองรวมถึงชั้นอินพุต (ที่สัญญาณเข้า – ในมนุษย์คุณอาจคิดว่ามันเป็นสัญญาณที่ส่งไปยังสมองเมื่อสัมผัสวัตถุ)) จำนวนหนึ่ง เลเยอร์ที่ซ่อนอยู่ (ระบุเส้นทางที่แตกต่างกันจำนวนหนึ่ง อินพุตสามารถปรับได้เพื่อสร้างเอาต์พุต) และเลเยอร์เอาต์พุต สัญญาณเข้า ทดสอบ "เส้นทาง" ต่างๆ เพื่อสร้างเลเยอร์เอาต์พุต และตั้งโปรแกรมให้โน้มน้าวไปสู่สภาวะเอาต์พุตที่ดีขึ้นกว่าเดิม สายตาสามารถแสดงได้โดย:
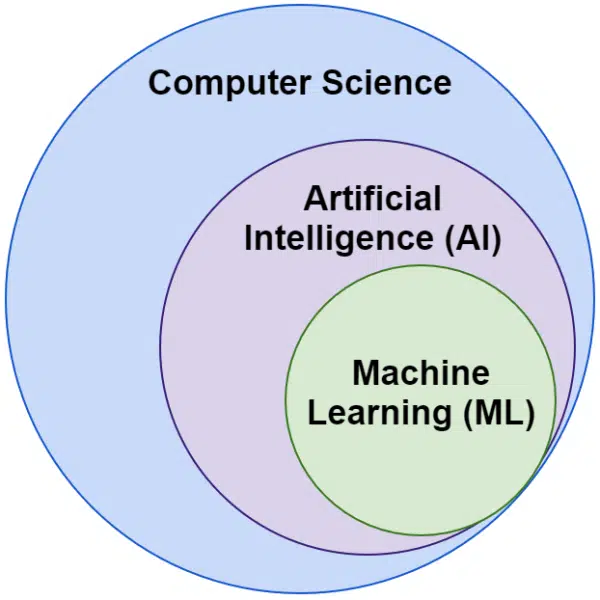
ปัญญาประดิษฐ์กับการเรียนรู้ของเครื่อง: อะไรคือความแตกต่าง?
บ่อยครั้งที่เราได้ยินคำว่าปัญญาประดิษฐ์และการเรียนรู้ของเครื่องที่ใช้แทนกันได้ พวกเขาไม่เหมือนกันทุกประการ
ปัญญาประดิษฐ์เป็นสาขาที่ทำให้เครื่องจักรเลียนแบบสติปัญญา ในขณะที่การเรียนรู้ของเครื่องคือการแสวงหาระบบที่สามารถเรียนรู้ได้โดยไม่ต้องตั้งโปรแกรมไว้สำหรับงานอย่างชัดเจน
ด้วยสายตาคุณสามารถคิดได้ดังนี้:
อัลกอริธึมที่เกี่ยวข้องกับการเรียนรู้ของเครื่องของ Google
เสิร์ชเอ็นจิ้นหลักๆ ทั้งหมดใช้แมชชีนเลิร์นนิงด้วยวิธีใดวิธีหนึ่งหรือหลายวิธี อันที่จริง Microsoft กำลังสร้างความก้าวหน้าครั้งสำคัญบางอย่าง โซเชียลเน็ตเวิร์กอย่าง Facebook ผ่าน Meta AI กับโมเดลอย่าง WebFormer ก็เช่นกัน
แต่จุดสนใจของเราที่นี่คือ SEO และในขณะที่ Bing เป็นเสิร์ชเอ็นจิ้นที่มีส่วนแบ่งตลาด 6.61% ในสหรัฐอเมริกา เราจะไม่เน้นเรื่องนี้ในบทความนี้ในขณะที่เราสำรวจเทคโนโลยีที่เกี่ยวข้องกับการค้นหาที่สำคัญและเป็นที่นิยม
Google ใช้อัลกอริธึมการเรียนรู้ของเครื่องจำนวนมาก ไม่มีทางที่คุณ ฉัน หรือวิศวกรของ Google จะรู้จักพวกเขาทั้งหมด ยิ่งไปกว่านั้น หลายๆ อันเป็นเพียงวีรบุรุษแห่งการค้นหาที่ไม่มีใครรู้จัก และเราไม่จำเป็นต้องสำรวจพวกมันทั้งหมดเพราะมันทำให้ระบบอื่นๆ ทำงานได้ดีขึ้น
สำหรับบริบท สิ่งเหล่านี้จะรวมถึงอัลกอริธึมและแบบจำลองต่างๆ เช่น:
- Google FLAN – ซึ่งช่วยเพิ่มความเร็วและทำให้การถ่ายโอนการเรียนรู้จากโดเมนหนึ่งไปยังอีกโดเมนหนึ่งมีค่าใช้จ่ายน้อยลง ที่น่าสังเกต: ในการเรียนรู้ของเครื่อง โดเมนไม่ได้อ้างถึงเว็บไซต์แต่หมายถึงงานหรือกลุ่มของงานที่ทำสำเร็จ เช่น การวิเคราะห์ความรู้สึกในการประมวลผลภาษาธรรมชาติ (NLP) หรือการตรวจจับวัตถุใน Computer Vision (CV)
- V-MoE – งานเดียวของโมเดลนี้คืออนุญาตให้มีการฝึกอบรมโมเดลการมองเห็นขนาดใหญ่โดยใช้ทรัพยากรน้อยลง เป็นการพัฒนาในลักษณะนี้ที่ช่วยให้มีความคืบหน้าโดยการขยายสิ่งที่สามารถทำได้ในทางเทคนิค
- Sub-Pseudo Labels – ระบบนี้ปรับปรุงการจดจำการกระทำในวิดีโอ ช่วยในการทำความเข้าใจและงานต่างๆ ที่เกี่ยวข้องกับวิดีโอ
สิ่งเหล่านี้ไม่ส่งผลกระทบโดยตรงต่อการจัดอันดับหรือเลย์เอาต์ แต่สิ่งเหล่านี้ส่งผลต่อความสำเร็จของ Google
ตอนนี้เรามาดูอัลกอริธึมหลักและโมเดลที่เกี่ยวข้องกับการจัดอันดับของ Google
RankBrain
นี่คือจุดเริ่มต้นทั้งหมด การแนะนำแมชชีนเลิร์นนิงในอัลกอริทึมของ Google
อัลกอริทึม RankBrain เปิดตัวในปี 2015 กับข้อความค้นหาที่ Google ไม่เคยเห็นมาก่อน (คิดเป็น 15% ของการค้นหาทั้งหมด) ภายในเดือนมิถุนายน 2016 ได้มีการขยายให้รวมการสืบค้นข้อมูลทั้งหมด
ตามความก้าวหน้าครั้งใหญ่อย่าง Hummingbird และกราฟความรู้ RankBrain ช่วยให้ Google ขยายจากการมองว่าโลกเป็นสตริง (คีย์เวิร์ดและชุดของคำและอักขระ) ไปจนถึงสิ่งต่างๆ (เอนทิตี) ตัวอย่างเช่น ก่อนหน้านี้ Google จะมองว่าเมืองที่ฉันอาศัยอยู่ (วิกตอเรีย บริติชโคลัมเบีย) เป็นคำสองคำที่มักเกิดขึ้นร่วมกัน แต่ก็มักจะเกิดขึ้นแยกจากกัน และสามารถแต่ไม่ได้หมายถึงสิ่งที่แตกต่างไปจากนี้เสมอไป
หลังจาก RankBrain พวกเขาเห็น Victoria, BC เป็นเอนทิตี – บางทีอาจเป็นหมายเลขเครื่อง (/m/07ypt) – และแม้ว่าพวกเขาจะตีแค่คำว่า “Victoria” หากพวกเขาสามารถสร้างบริบทได้ พวกเขาจะถือว่ามันเป็นเอนทิตีเดียวกันกับ วิกตอเรีย ก่อนคริสตกาล
ด้วยเหตุนี้พวกเขาจึง "มองเห็น" มากกว่าแค่คำหลักและความหมาย สมองของเราเท่านั้นที่มองเห็น ท้ายที่สุด เมื่อคุณอ่าน "พิซซ่าใกล้ฉัน" คุณเข้าใจหรือไม่ว่าในแง่ของคำสามคำหรือคุณมีภาพในหัวของพิซซ่า และเข้าใจคุณในสถานที่ที่คุณอยู่หรือไม่
กล่าวโดยย่อ RankBrain ช่วยให้อัลกอริทึมใช้สัญญาณกับสิ่งต่าง ๆ แทนคำหลัก
BERT
BERT ( การแสดงตัวเข้ารหัส E แบบทิศทางเดียว R จาก T ransformers )
ด้วยการเปิดตัวโมเดล BERT ในอัลกอริธึมของ Google ในปี 2019 Google ได้เปลี่ยนจากการทำความเข้าใจแนวคิดแบบทิศทางเดียวเป็นแบบสองทิศทาง
นี่ไม่ใช่การเปลี่ยนแปลงทางโลก
ภาพที่ Google รวมอยู่ในการประกาศโอเพนซอร์สของโมเดล BERT ในปี 2018 ช่วยวาดภาพ:
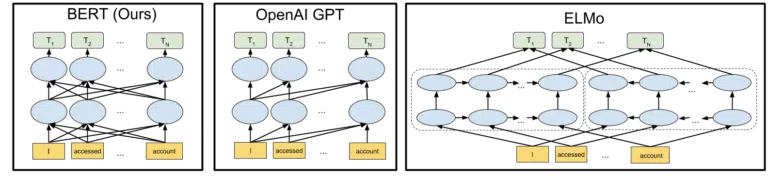
โดยไม่ต้องลงรายละเอียดว่าโทเค็นและหม้อแปลงทำงานอย่างไรในการเรียนรู้ของเครื่อง ก็เพียงพอแล้วสำหรับความต้องการของเราที่นี่เพียงแค่ดูภาพสามภาพและลูกศรแล้วคิดว่าในเวอร์ชัน BERT แต่ละคำได้รับข้อมูลจากคำใดคำหนึ่ง ด้านข้างรวมทั้งคำหลายคำออกไป
เมื่อก่อนหน้านี้ โมเดลสามารถใช้ข้อมูลเชิงลึกจากคำในทิศทางเดียวเท่านั้น ตอนนี้พวกเขาได้รับความเข้าใจตามบริบทตามคำในทั้งสองทิศทาง
ตัวอย่างง่ายๆ อาจเป็น “รถสีแดง”
หลังจากที่ BERT เป็นสีแดง เท่านั้นจึงจะเข้าใจได้อย่างถูกต้องว่าเป็นสีของรถ เพราะจนกระทั่งถึงตอนนั้น คำว่า red มาหลังคำว่า car และข้อมูลนั้นก็ไม่ถูกส่งกลับ
นอกจากนี้ หากคุณต้องการเล่นกับ BERT GitHub มีรุ่นต่างๆ ให้เลือก
ลาแมร์
LaMDA ยังไม่ได้ปรับใช้ในธรรมชาติ และได้รับการประกาศครั้งแรกที่ Google I/O ในเดือนพฤษภาคมปี 2021
เพื่อชี้แจงว่า เมื่อฉันเขียนว่า "ยังไม่ได้ใช้งาน" ฉันหมายถึง "เท่าที่ฉันรู้" ท้ายที่สุด เราค้นพบเกี่ยวกับ RankBrain หลายเดือนหลังจากที่มันถูกปรับใช้ในอัลกอริธึม ที่กล่าวว่าเมื่อมันจะเป็นการปฏิวัติ
LaMDA เป็นรูปแบบภาษาที่ใช้สนทนาซึ่งดูเหมือนจะทำลายความล้ำสมัยในปัจจุบัน
โฟกัสกับ LaMDA นั้นโดยทั่วไปแล้วมีสองส่วน:
- ปรับปรุงความสมเหตุสมผลและความเฉพาะเจาะจงในการสนทนา โดยพื้นฐานแล้ว เพื่อให้แน่ใจว่าการตอบกลับในแชทนั้นสมเหตุสมผล และ เฉพาะเจาะจง ตัวอย่างเช่น สำหรับคำถามส่วนใหญ่ คำตอบ "ฉันไม่รู้" มีเหตุผลแต่ไม่ได้เจาะจง ในทางกลับกัน การตอบคำถามเช่น “คุณเป็นอย่างไรบ้าง” นั่นก็คือ “ฉันชอบต้มเป็ดในวันฝนตก มันเหมือนกับว่าวกำลังบินอยู่” มีความเฉพาะเจาะจงมากแต่แทบจะไม่สมเหตุสมผล
LaMDA ช่วยแก้ไขปัญหาทั้งสอง - เมื่อเราสื่อสาร มักจะเป็นการสนทนาเชิงเส้น เมื่อเราคิดว่าการอภิปรายอาจเริ่มต้นที่ใดและสิ้นสุดที่ใด แม้ว่าจะเป็นเพียงหัวข้อเดียว (เช่น "ทำไมการเข้าชมของเราจึงลดลงในสัปดาห์นี้") โดยทั่วไปแล้ว เราจะกล่าวถึงหัวข้อต่างๆ ที่เราจะไม่พูดถึง ทำนายว่าจะเข้า
ใครก็ตามที่เคยใช้แชทบ็อตจะรู้ดีในสถานการณ์เหล่านี้ พวกเขาปรับตัวได้ไม่ดีและไม่ได้นำข้อมูลในอดีตไปสู่อนาคตด้วยดี (และในทางกลับกัน)
LaMDA กล่าวถึงปัญหานี้เพิ่มเติม
ตัวอย่างการสนทนาจาก Google คือ:


เราเห็นว่ามันปรับตัวได้ดีกว่าที่คาดไว้จากแชทบ็อต
ฉันเห็น LaMDA ถูกใช้งานใน Google Assistant แต่ถ้าเราลองคิดดูแล้ว ความสามารถที่เพิ่มขึ้นในการทำความเข้าใจว่าลำดับการสืบค้นทำงานอย่างไรในระดับบุคคลจะช่วยได้อย่างแน่นอนทั้งในด้านการปรับแต่งเค้าโครงผลการค้นหา และการนำเสนอหัวข้อและคำถามเพิ่มเติมแก่ผู้ใช้
โดยพื้นฐานแล้ว ฉันค่อนข้างแน่ใจว่าเราจะเห็นเทคโนโลยีที่ได้รับแรงบันดาลใจจาก LaMDA แทรกซึมเข้าไปในพื้นที่การค้นหาที่ไม่ใช่แชท
KELM
ด้านบน เมื่อเราพูดถึง RankBrain เราพูดถึงหมายเลขเครื่องและเอนทิตี KELM ซึ่งประกาศเมื่อเดือนพฤษภาคม 2564 ได้ก้าวไปสู่ระดับใหม่ทั้งหมด
KELM เกิดขึ้นจากความพยายามที่จะลดความลำเอียงและข้อมูลที่เป็นพิษในการค้นหา เนื่องจากใช้ข้อมูลที่เชื่อถือได้ (Wikidata) จึงสามารถใช้เพื่อการนี้ได้เป็นอย่างดี
KELM เป็นเหมือนชุดข้อมูลมากกว่าที่จะเป็นโมเดล โดยพื้นฐานแล้ว มันคือข้อมูลการฝึกสำหรับโมเดลแมชชีนเลิร์นนิง สิ่งที่น่าสนใจกว่าสำหรับจุดประสงค์ของเราในที่นี้คือ การบอกเราเกี่ยวกับวิธีการที่ Google นำไปใช้กับข้อมูล
โดยสังเขป Google นำกราฟความรู้ Wikidata ภาษาอังกฤษซึ่งเป็นชุดของสามส่วน (หัวเรื่อง ความสัมพันธ์ วัตถุ (รถ สี สีแดง) มาแปลงเป็นกราฟย่อยของเอนทิตีต่างๆ และพูดออกมา ซึ่งอธิบายได้ง่ายที่สุดใน ภาพ:
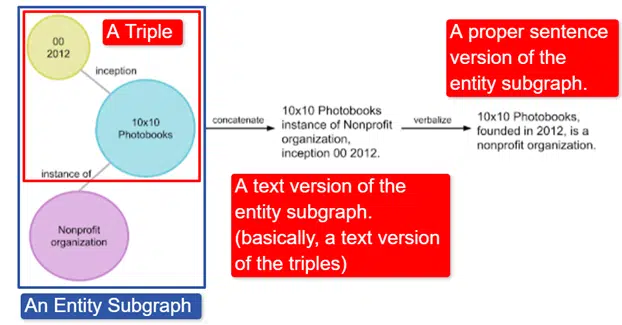
ในภาพนี้เราเห็น:
- ทั้งสามอธิบายถึงความสัมพันธ์ส่วนบุคคล
- กราฟย่อยของเอนทิตีที่จับคู่สามเท่าที่เกี่ยวข้องกับเอนทิตีส่วนกลาง
- เวอร์ชันข้อความของกราฟย่อยของเอนทิตี
- ประโยคที่ถูกต้อง.
จากนั้นโมเดลอื่นจะใช้งานได้เพื่อช่วยฝึกให้พวกเขารับรู้ข้อเท็จจริงและกรองข้อมูลที่เป็นพิษ
Google ได้เปิดคลังข้อมูลและเปิดให้ใช้งานบน GitHub การดูคำอธิบายจะช่วยให้คุณเข้าใจวิธีการทำงานและโครงสร้าง หากคุณต้องการข้อมูลเพิ่มเติม
แม่
MUM ได้รับการประกาศที่ Google I/O ในเดือนพฤษภาคม 2021 ด้วย
แม้ว่าจะเป็นการปฏิวัติ แต่ก็ง่ายต่อการอธิบาย
MUM ย่อมาจาก M ultitask U nified M odel และเป็นหลายรูปแบบ ซึ่งหมายความว่า "เข้าใจ" เนื้อหารูปแบบต่างๆ เช่น การทดสอบ รูปภาพ วิดีโอ ฯลฯ ซึ่งช่วยให้สามารถรับข้อมูลจากรูปแบบต่างๆ ได้ รวมทั้งตอบสนอง
นอกเหนือจากนี้: นี่ไม่ใช่ครั้งแรกที่ใช้สถาปัตยกรรม MultiModel Google เปิดตัวครั้งแรกในปี 2560
นอกจากนี้ เนื่องจาก MUM ทำงานในสิ่งต่าง ๆ ไม่ใช่สตริง จึงสามารถรวบรวมข้อมูลในภาษาต่างๆ แล้วให้คำตอบในตัวผู้ใช้เอง ซึ่งเปิดประตูสู่การปรับปรุงการเข้าถึงข้อมูลอย่างมากมาย โดยเฉพาะอย่างยิ่งสำหรับผู้ที่พูดภาษาที่ไม่ได้รับการสนับสนุนบนอินเทอร์เน็ต แต่แม้แต่ผู้พูดภาษาอังกฤษก็จะได้รับประโยชน์โดยตรง
ตัวอย่างที่ Google ใช้คือนักปีนเขาที่ต้องการปีนภูเขาไฟฟูจิ คำแนะนำและข้อมูลที่ดีที่สุดบางส่วนอาจเขียนเป็นภาษาญี่ปุ่นและผู้ใช้ไม่สามารถใช้งานได้อย่างสมบูรณ์ เนื่องจากผู้ใช้จะไม่ทราบวิธีการแสดงแม้ว่าจะสามารถแปลได้ก็ตาม
หมายเหตุสำคัญเกี่ยวกับ MUM คือโมเดลนี้ไม่เพียงแต่เข้าใจเนื้อหาเท่านั้น แต่ยังผลิตออกมาได้ ดังนั้น แทนที่จะส่งผู้ใช้ไปยังผลลัพธ์อย่างเฉยเมย มันสามารถอำนวยความสะดวกในการรวบรวมข้อมูลจากหลายแหล่งและให้ข้อเสนอแนะ (หน้า เสียง ฯลฯ) ได้ด้วยตัวมันเอง
นี่อาจเป็นประเด็นที่เกี่ยวข้องกับเทคโนโลยีนี้สำหรับหลาย ๆ คนรวมถึงตัวฉันด้วย
ที่อื่นใช้แมชชีนเลิร์นนิง
เราได้กล่าวถึงเฉพาะอัลกอริธึมหลักบางตัวที่คุณเคยได้ยินมา และฉันเชื่อว่ามีผลกระทบอย่างมากต่อการค้นหาทั่วไป แต่สิ่งนี้ยังห่างไกลจากการใช้แมชชีนเลิร์นนิงทั้งหมด
ตัวอย่างเช่น เราสามารถถาม:
- ในโฆษณา อะไรเป็นตัวขับเคลื่อนระบบที่อยู่เบื้องหลังกลยุทธ์การเสนอราคาอัตโนมัติและระบบโฆษณาอัตโนมัติ
- ใน News ระบบรู้วิธีจัดกลุ่ม Story อย่างไร?
- ใน Images ระบบระบุอ็อบเจ็กต์และประเภทของอ็อบเจ็กต์อย่างไร?
- ใน Email ระบบกรอง Spam อย่างไร?
- ในการแปล ระบบจะจัดการเรียนรู้คำและวลีใหม่อย่างไร
- ในวิดีโอระบบจะเรียนรู้ได้อย่างไรว่าวิดีโอใดที่จะแนะนำต่อไป
คำถามเหล่านี้ทั้งหมดและอีกหลายร้อยข้อหากไม่ใช่อีกหลายพันคำถามมีคำตอบเหมือนกัน:
การเรียนรู้ของเครื่อง
ประเภทของอัลกอริทึมและแบบจำลองแมชชีนเลิร์นนิง
ตอนนี้ มาดูขั้นตอนการควบคุมดูแลสองระดับของอัลกอริธึมและโมเดลการเรียนรู้ของเครื่อง – การเรียนรู้ภายใต้การดูแลและการเรียนรู้แบบไม่มีผู้ดูแล การทำความเข้าใจประเภทของอัลกอริทึมที่เรากำลังดูอยู่ และจะหาได้จากที่ใดเป็นสิ่งสำคัญ
การเรียนรู้ภายใต้การดูแล
พูดง่ายๆ ด้วยการเรียนรู้ภายใต้การดูแล อัลกอริธึมจะได้รับข้อมูลการฝึกอบรมและการทดสอบที่มีป้ายกำกับครบถ้วน
กล่าวคือ มีคนพยายามติดฉลากตัวอย่างนับพัน (หรือหลายล้าน) ตัวอย่างเพื่อฝึกแบบจำลองเกี่ยวกับข้อมูลที่เชื่อถือได้ เช่น การติดป้ายเสื้อแดงในรูป x จำนวนคนใส่เสื้อแดง
การเรียนรู้ภายใต้การดูแลมีประโยชน์ในการจัดหมวดหมู่และปัญหาการถดถอย ปัญหาการจำแนกค่อนข้างตรงไปตรงมา การพิจารณาว่ามีบางสิ่งหรือไม่ใช่ส่วนหนึ่งของกลุ่มหรือไม่
ตัวอย่างง่ายๆ คือ Google Photos
Google ได้จำแนกฉันรวมถึงขั้นตอนต่างๆ พวกเขาไม่ได้ติดป้ายกำกับรูปภาพเหล่านี้ด้วยตนเอง แต่โมเดลจะได้รับการฝึกอบรมเกี่ยวกับข้อมูลที่ติดป้ายกำกับด้วยตนเองสำหรับขั้นตอนต่างๆ และใครก็ตามที่ใช้ Google Photos จะรู้ดีว่าพวกเขาขอให้คุณยืนยันรูปภาพและผู้คนในรูปภาพเป็นระยะ เราคือผู้ติดฉลากด้วยมือ
เคยใช้ ReCAPTCHA หรือไม่? คาดเดาสิ่งที่คุณทำ? ถูกตัอง. คุณช่วยฝึกโมเดลแมชชีนเลิร์นนิงเป็นประจำ
ในทางกลับกัน ปัญหาการถดถอยจะจัดการกับปัญหาที่มีชุดของอินพุตที่จำเป็นต้องจับคู่กับค่าเอาต์พุต
ตัวอย่างง่ายๆ คือ ให้นึกถึงระบบการประมาณราคาขายบ้านที่มีพื้นที่เป็นตารางฟุต จำนวนห้องนอน จำนวนห้องน้ำ ระยะห่างจากทะเล เป็นต้น
คุณนึกถึงระบบอื่นๆ ที่อาจมีคุณสมบัติ/สัญญาณที่หลากหลาย จากนั้นจึงจำเป็นต้องกำหนดค่าให้กับเอนทิตี (/ไซต์) ที่เป็นปัญหาหรือไม่
แม้ว่าอัลกอรึทึมจะซับซ้อนกว่าและใช้อาร์เรย์ขนาดใหญ่ของอัลกอริธึมที่ให้บริการฟังก์ชันต่างๆ แต่การถดถอยอาจเป็นหนึ่งในประเภทอัลกอริธึมที่ขับเคลื่อนฟังก์ชันหลักของการค้นหา
ฉันสงสัยว่าเรากำลังเข้าสู่โมเดลกึ่งควบคุมที่นี่ - มีการติดฉลากด้วยตนเอง (คิดว่าผู้ประเมินคุณภาพ) ในบางขั้นตอนและสัญญาณที่ระบบรวบรวมซึ่งกำหนดความพึงพอใจของผู้ใช้ด้วยชุดผลลัพธ์ที่ใช้ในการปรับและสร้างแบบจำลองที่เล่น .
การเรียนรู้แบบไม่มีผู้ดูแล
ในการเรียนรู้แบบ unsupervised ระบบจะได้รับชุดข้อมูลที่ไม่มีป้ายกำกับและปล่อยให้กำหนดเองว่าจะทำอย่างไรกับข้อมูลนั้น
ไม่ได้ระบุเป้าหมายสุดท้าย ระบบอาจจัดกลุ่มรายการที่คล้ายกันเข้าด้วยกัน ค้นหาค่าผิดปกติ ค้นหาความสัมพันธ์ ฯลฯ
การเรียนรู้แบบไม่มีผู้ดูแลจะใช้เมื่อคุณมีข้อมูลจำนวนมาก และคุณไม่สามารถหรือไม่ทราบล่วงหน้าว่าควรใช้ข้อมูลนี้อย่างไร
ตัวอย่างที่ดีอาจเป็น Google News
Google จัดกลุ่มข่าวที่คล้ายคลึงกันและยังแสดงข่าวที่ไม่เคยมีมาก่อน (จึงเป็นข่าว)
งานเหล่านี้ควรดำเนินการโดยส่วนใหญ่ (แต่ไม่ใช่เฉพาะ) โมเดลที่ไม่ได้รับการดูแล โมเดลที่ "เห็น" แล้วว่าการจัดกลุ่มหรือการแสดงพื้นผิวก่อนหน้านี้ประสบความสำเร็จหรือไม่ประสบความสำเร็จ แต่ไม่สามารถใช้สิ่งนั้นกับข้อมูลปัจจุบันได้อย่างเต็มที่ซึ่งไม่มีป้ายกำกับ (เช่นเดียวกับข่าวก่อนหน้านี้) และตัดสินใจได้
เป็นพื้นที่ที่สำคัญอย่างเหลือเชื่อของการเรียนรู้ของเครื่องเนื่องจากเกี่ยวข้องกับการค้นหา โดยเฉพาะอย่างยิ่งเมื่อสิ่งต่างๆ ขยายตัว
Google Translate เป็นอีกตัวอย่างที่ดี ไม่ใช่การแปลแบบตัวต่อตัวที่เคยมี โดยระบบ ได้รับการฝึกฝนให้เข้าใจว่าคำว่า x ในภาษาอังกฤษ เท่ากับ คำว่า y ในภาษาสเปน แต่เป็นเทคนิคที่ใหม่กว่าที่แสวงหารูปแบบการใช้งานทั้งสองแบบ ปรับปรุงการแปลแบบกึ่ง - การเรียนรู้แบบมีผู้ดูแล (ข้อมูลที่มีป้ายกำกับบางส่วนและแทบไม่มีเลย) และการเรียนรู้แบบไม่มีผู้ดูแล โดยแปลจากภาษาหนึ่งเป็นภาษาที่ไม่รู้จัก (เป็นระบบ) โดยสิ้นเชิง
เราเห็นสิ่งนี้กับ MUM ด้านบน แต่มีอยู่ในเอกสารและรุ่นอื่นด้วย
แค่เริ่มต้น
หวังว่านี่จะเป็นพื้นฐานสำหรับแมชชีนเลิร์นนิงและวิธีการใช้ในการค้นหา
บทความในอนาคตของฉันจะไม่ใช่แค่เกี่ยวกับวิธีและที่ที่แมชชีนเลิร์นนิงสามารถพบได้ (แม้ว่าบางส่วนจะเป็นเช่นนั้น) นอกจากนี้เรายังจะเจาะลึกถึงการใช้งานจริงของการเรียนรู้ของเครื่องที่คุณสามารถใช้เป็น SEO ที่ดีขึ้นได้ ไม่ต้องกังวล ในกรณีเหล่านี้ ฉันจะเขียนโค้ดให้คุณ และโดยทั่วไปแล้วจะให้ Google Colab ที่ใช้งานง่ายติดตามไปด้วย ช่วยให้คุณตอบคำถาม SEO และธุรกิจที่สำคัญบางข้อได้
ตัวอย่างเช่น คุณสามารถใช้โมเดลแมชชีนเลิร์นนิงโดยตรงเพื่อพัฒนาความเข้าใจในไซต์ เนื้อหา การเข้าชม และอื่นๆ ของคุณ บทความถัดไปของฉันจะแสดงให้คุณเห็นว่า ทีเซอร์: การคาดการณ์อนุกรมเวลา
ความคิดเห็นที่แสดงในบทความนี้เป็นความคิดเห็นของผู้เขียนรับเชิญและไม่จำเป็นต้องเป็น Search Engine Land ผู้เขียนพนักงานอยู่ที่นี่