
Ein Leitfaden für maschinelles Lernen in der Suche: Schlüsselbegriffe, Konzepte und Algorithmen
Veröffentlicht: 2022-05-02Wenn es um maschinelles Lernen geht, gibt es einige allgemeine Konzepte und Begriffe, die jeder Suchende kennen sollte. Wir sollten alle wissen, wo maschinelles Lernen eingesetzt wird und welche verschiedenen Arten von maschinellem Lernen es gibt.
Lesen Sie weiter, um besser zu verstehen, wie sich maschinelles Lernen auf die Suche auswirkt, was die Suchmaschinen tun und wie man maschinelles Lernen bei der Arbeit erkennt. Beginnen wir mit ein paar Definitionen. Dann werden wir uns mit maschinellen Lernalgorithmen und -modellen befassen.
Begriffe für maschinelles Lernen
Was folgt, sind Definitionen einiger wichtiger Begriffe des maschinellen Lernens, von denen die meisten irgendwann in diesem Artikel besprochen werden. Dies soll kein umfassendes Glossar aller Begriffe des maschinellen Lernens sein. Wenn Sie das möchten, bietet Google hier eine gute an.
- Algorithmus : Ein mathematischer Prozess, der auf Daten ausgeführt wird, um eine Ausgabe zu erzeugen. Es gibt verschiedene Arten von Algorithmen für verschiedene Probleme des maschinellen Lernens.
- Künstliche Intelligenz (KI) : Ein Bereich der Informatik, der sich darauf konzentriert, Computer mit Fertigkeiten oder Fähigkeiten auszustatten, die die menschliche Intelligenz replizieren oder von dieser inspiriert sind.
- Corpus : Eine Sammlung von geschriebenem Text. Normalerweise irgendwie organisiert.
- Entität : Eine Sache oder ein Konzept, das einzigartig, singulär, gut definiert und unterscheidbar ist. Sie können es sich locker als Substantiv vorstellen, obwohl es ein bisschen breiter ist. Ein bestimmter Rotton wäre eine Entität. Ist es einzigartig und einzigartig, da nichts anderes genau so ist, es ist gut definiert (denken Sie an Hex-Code) und es ist dadurch unterscheidbar, dass Sie es von jeder anderen Farbe unterscheiden können.
- Maschinelles Lernen : Ein Bereich der künstlichen Intelligenz, der sich auf die Erstellung von Algorithmen, Modellen und Systemen konzentriert, um Aufgaben auszuführen und sich allgemein bei der Ausführung dieser Aufgabe zu verbessern, ohne explizit programmiert zu werden.
- Modell: Ein Modell wird oft mit einem Algorithmus verwechselt. Die Unterscheidung kann unscharf werden (es sei denn, Sie sind ein Ingenieur für maschinelles Lernen). Der Unterschied besteht im Wesentlichen darin, dass, wo ein Algorithmus einfach eine Formel ist, die einen Ausgabewert erzeugt, ein Modell die Darstellung dessen ist, was dieser Algorithmus produziert hat, nachdem er für eine bestimmte Aufgabe trainiert wurde. Wenn wir also „BERT-Modell“ sagen, beziehen wir uns auf das BERT, das für eine bestimmte NLP-Aufgabe trainiert wurde (welche Aufgabe und Modellgröße bestimmen welches spezifische BERT-Modell).
- Natural Language Processing (NLP): Ein allgemeiner Begriff zur Beschreibung des Arbeitsbereichs der Verarbeitung sprachbasierter Informationen zur Erledigung einer Aufgabe.
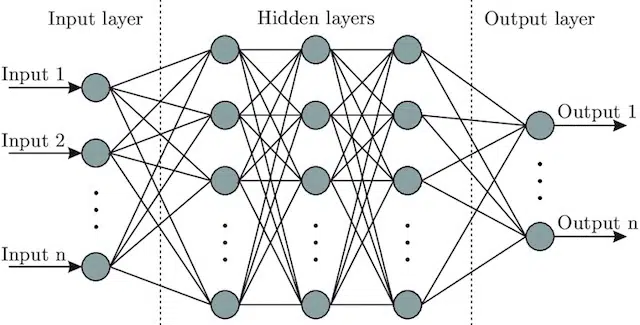
- Neuronales Netzwerk : Eine Modellarchitektur, die, inspiriert vom Gehirn, eine Eingabeschicht (wo die Signale eingehen – bei einem Menschen könnte man es als das Signal betrachten, das an das Gehirn gesendet wird, wenn ein Objekt berührt wird)), eine Reihe von enthält verborgene Schichten (die eine Reihe verschiedener Pfade bereitstellen, die die Eingabe anpassen können, um eine Ausgabe zu erzeugen) und die Ausgabeschicht. Die Signale gehen ein, testen mehrere unterschiedliche „Pfade“, um die Ausgangsschicht zu erzeugen, und sind so programmiert, dass sie zu immer besseren Ausgangsbedingungen tendieren. Visuell kann es dargestellt werden durch:
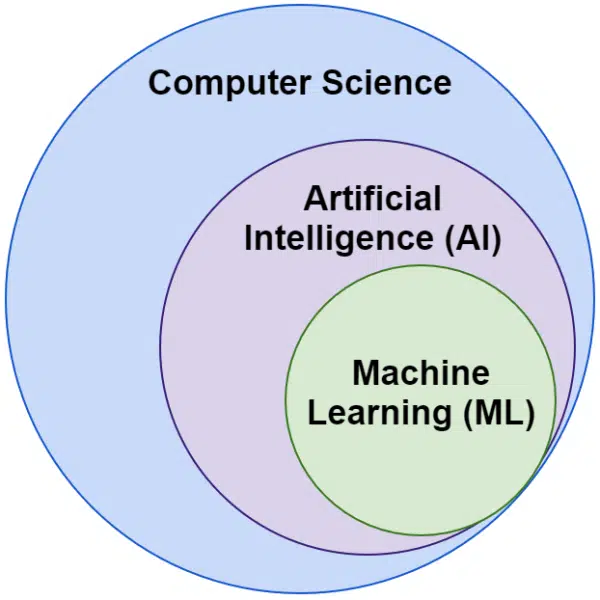
Künstliche Intelligenz vs. maschinelles Lernen: Was ist der Unterschied?
Oft hören wir die Wörter künstliche Intelligenz und maschinelles Lernen synonym verwendet. Sie sind nicht genau gleich.
Künstliche Intelligenz ist das Gebiet, Maschinen dazu zu bringen, Intelligenz nachzuahmen, während maschinelles Lernen das Streben nach Systemen ist, die lernen können, ohne explizit für eine Aufgabe programmiert zu werden.
Optisch kann man sich das so vorstellen:
Die auf maschinelles Lernen bezogenen Algorithmen von Google
Alle großen Suchmaschinen nutzen maschinelles Lernen auf eine oder mehrere Arten. Tatsächlich produziert Microsoft einige bedeutende Durchbrüche. So sind soziale Netzwerke wie Facebook über Meta AI mit Modellen wie WebFormer.
Aber unser Fokus liegt hier auf SEO. Und obwohl Bing eine Suchmaschine mit einem Marktanteil von 6,61 % in den USA ist, werden wir uns in diesem Artikel nicht darauf konzentrieren, da wir beliebte und wichtige suchbezogene Technologien untersuchen.
Google verwendet eine Vielzahl von Algorithmen für maschinelles Lernen. Es gibt buchstäblich keine Möglichkeit, dass Sie, ich oder wahrscheinlich irgendein Google-Ingenieur sie alle kennen könnte. Darüber hinaus sind viele einfach unbesungene Helden der Suche, und wir müssen sie nicht vollständig untersuchen, da sie einfach dazu beitragen, dass andere Systeme besser funktionieren.
Für den Kontext wären dies Algorithmen und Modelle wie:
- Google FLAN – was die Übertragung von Lerninhalten von einer Domäne auf eine andere einfach beschleunigt und weniger rechenintensiv macht. Bemerkenswert: Beim maschinellen Lernen bezieht sich eine Domäne nicht auf eine Website, sondern auf die Aufgabe oder Cluster von Aufgaben, die sie erfüllt, wie z. B. die Sentimentanalyse in Natural Language Processing (NLP) oder die Objekterkennung in Computer Vision (CV).
- V-MoE – Die einzige Aufgabe dieses Modells besteht darin, das Training großer Vision-Modelle mit weniger Ressourcen zu ermöglichen. Es sind Entwicklungen wie diese, die den Fortschritt ermöglichen, indem sie das technisch Machbare erweitern.
- Sub-Pseudo-Labels – dieses System verbessert die Aktionserkennung in Videos und hilft bei einer Vielzahl von videobezogenen Verständnissen und Aufgaben.
Keines davon wirkt sich direkt auf das Ranking oder Layout aus. Aber sie beeinflussen, wie erfolgreich Google ist.
Schauen wir uns nun die Kernalgorithmen und -modelle an, die mit Google-Rankings zu tun haben.
RankBrain
Hier fing alles an, mit der Einführung von maschinellem Lernen in die Algorithmen von Google.
Der 2015 eingeführte RankBrain-Algorithmus wurde auf Suchanfragen angewendet, die Google zuvor noch nicht gesehen hatte (was 15 % davon ausmacht). Bis Juni 2016 wurde es auf alle Abfragen erweitert.
Nach großen Fortschritten wie Hummingbird und dem Knowledge Graph half RankBrain Google dabei, die Welt von der Betrachtung der Welt als Zeichenfolgen (Schlüsselwörter und Sätze von Wörtern und Zeichen) zu Dingen (Entitäten) zu erweitern. Vorher würde Google beispielsweise die Stadt, in der ich lebe (Victoria, BC) im Wesentlichen als zwei Wörter sehen, die regelmäßig zusammen vorkommen, aber auch regelmäßig getrennt vorkommen und dabei etwas anderes bedeuten können, aber nicht immer bedeuten müssen.
Nach RankBrain sahen sie Victoria, BC als eine Entität – vielleicht die Maschinen-ID (/m/07ypt) – und selbst wenn sie nur das Wort „Victoria“ trafen, würden sie es als dieselbe Entität behandeln, wenn sie den Kontext herstellen könnten Viktoria, BC.
Damit „sehen“ sie über bloße Stichworte hinaus und auf Sinn, wie es eben unser Gehirn tut. Wenn Sie „Pizza in meiner Nähe“ lesen, verstehen Sie das schließlich in Form von drei einzelnen Wörtern oder haben Sie ein Bild von Pizza im Kopf und ein Verständnis von Ihnen an dem Ort, an dem Sie sich befinden?
Kurz gesagt, RankBrain hilft den Algorithmen, ihre Signale auf Dinge statt auf Schlüsselwörter anzuwenden.
Bert
BERT ( B idirectional Encoder Representations from T ransformers).
Mit der Einführung eines BERT-Modells in die Algorithmen von Google im Jahr 2019 wechselte Google von einem unidirektionalen Verständnis von Konzepten zu einem bidirektionalen Verständnis.
Dies war keine alltägliche Änderung.
Das visuelle Google, das Google in seine Ankündigung des Open-Sourcing des BERT-Modells im Jahr 2018 aufgenommen hat, hilft, das Bild zu zeichnen:
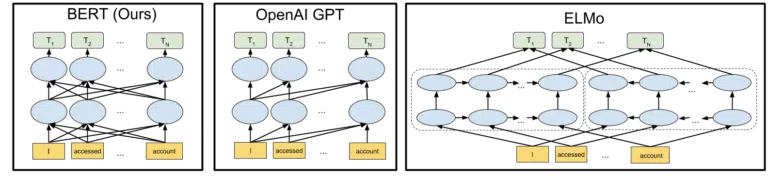
Ohne ins Detail zu gehen, wie Token und Transformer beim maschinellen Lernen funktionieren, reicht es für unsere Bedürfnisse hier aus, einfach die drei Bilder und die Pfeile zu betrachten und darüber nachzudenken, wie in der BERT-Version jedes der Wörter Informationen von den anderen erhält Seite, einschließlich dieser mehreren Wörter weg.
Wo früher ein Modell Erkenntnisse aus den Wörtern nur in eine Richtung anwenden konnte, gewinnen sie jetzt ein kontextuelles Verständnis, das auf Wörtern in beiden Richtungen basiert.
Ein einfaches Beispiel könnte sein: „Das Auto ist rot“.
Erst nach BERT wurde Rot richtig als die Farbe des Autos verstanden, denn bis dahin kam das Wort Rot nach dem Wort Auto, und diese Information wurde nicht zurückgesendet.
Übrigens, wenn Sie mit BERT spielen möchten, sind verschiedene Modelle auf GitHub verfügbar.
LaMDA
LaMDA wurde noch nicht in freier Wildbahn eingesetzt und wurde erstmals auf der Google I/O im Mai 2021 angekündigt.
Zur Verdeutlichung: Wenn ich „noch nicht eingesetzt“ schreibe, meine ich „nach bestem Wissen“. Schließlich haben wir Monate nach der Implementierung in die Algorithmen von RankBrain erfahren. Das heißt, wenn es soweit ist, wird es revolutionär sein.
LaMDA ist ein Konversations-Sprachmodell, das den aktuellen Stand der Technik scheinbar über den Haufen wirft.
Der Fokus bei LaMDA ist grundsätzlich zweifach:
- Verbessern Sie die Angemessenheit und Spezifität im Gespräch. Im Wesentlichen, um sicherzustellen, dass eine Antwort in einem Chat angemessen UND spezifisch ist. Beispielsweise ist die Antwort „Ich weiß nicht“ auf die meisten Fragen angemessen, aber nicht spezifisch. Andererseits ist eine Antwort auf eine Frage wie „Wie geht es dir?“ das heißt: „Ich mag Entensuppe an einem regnerischen Tag. Es ist wie Drachenfliegen.“ ist sehr spezifisch, aber kaum vernünftig.
LaMDA hilft bei der Lösung beider Probleme. - Wenn wir kommunizieren, ist es selten ein lineares Gespräch. Wenn wir darüber nachdenken, wo eine Diskussion beginnen und wo sie enden könnte, haben wir im Allgemeinen verschiedene Themen behandelt, die wir nicht hätten, selbst wenn es um ein einzelnes Thema ging (z. B. „Warum ist unser Traffic diese Woche rückläufig?“) vorausgesagt, hineinzugehen.
Jeder, der einen Chatbot verwendet hat, weiß, dass er in diesen Szenarien miserabel ist. Sie passen sich nicht gut an, und sie tragen vergangene Informationen nicht gut in die Zukunft (und umgekehrt).
LaMDA befasst sich weiter mit diesem Problem.
Eine Beispielkonversation von Google ist:


Wir können sehen, dass es sich viel besser anpasst, als man es von einem Chatbot erwarten würde.
Ich sehe, dass LaMDA im Google Assistant implementiert wird. Aber wenn wir darüber nachdenken, würden verbesserte Fähigkeiten zum Verständnis, wie ein Abfragefluss auf individueller Ebene funktioniert, sicherlich sowohl bei der Anpassung von Suchergebnissen als auch bei der Präsentation zusätzlicher Themen und Abfragen für den Benutzer hilfreich sein.
Grundsätzlich bin ich mir ziemlich sicher, dass von LaMDA inspirierte Technologien die Nicht-Chat-Suchbereiche durchdringen werden.
KELM
Als wir oben über RankBrain gesprochen haben, haben wir Maschinen-IDs und Entitäten angesprochen. Nun, KELM, das im Mai 2021 angekündigt wurde, bringt es auf eine ganz neue Ebene.
KELM entstand aus dem Bemühen, Verzerrungen und toxische Informationen bei der Suche zu reduzieren. Da es auf vertrauenswürdigen Informationen (Wikidata) basiert, kann es für diesen Zweck gut verwendet werden.
KELM ist kein Modell, sondern eher ein Datensatz. Im Grunde handelt es sich um Trainingsdaten für maschinelle Lernmodelle. Interessanter für unsere Zwecke hier ist, dass es uns etwas über die Herangehensweise von Google an Daten mitteilt.
Kurz gesagt, Google nahm den englischen Wikidata Knowledge Graph, der eine Sammlung von Tripeln (Subjekt-Entität, Beziehung, Objekt-Entität (Auto, Farbe, Rot) ist, und verwandelte ihn in verschiedene Entitäts-Subgraphen und verbalisierte ihn. Dies ist am einfachsten erklärt in ein Bild:
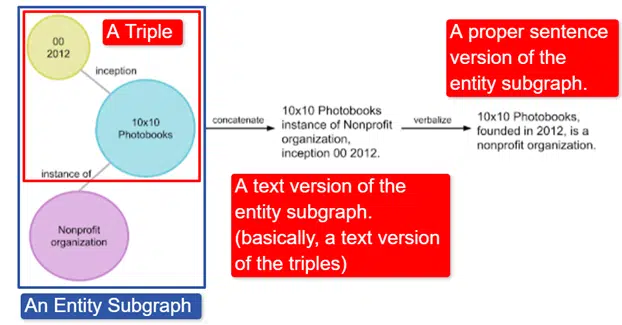
In diesem Bild sehen wir:
- Das Tripel beschreibt eine individuelle Beziehung.
- Der Entitätsuntergraph bildet eine Vielzahl von Tripeln ab, die sich auf eine zentrale Entität beziehen.
- Die Textversion des Entitätsunterdiagramms.
- Der richtige Satz.
Dies kann dann von anderen Modellen verwendet werden, um ihnen beizubringen, Fakten zu erkennen und toxische Informationen herauszufiltern.
Google hat das Korpus als Open Source veröffentlicht und ist auf GitHub verfügbar. Wenn Sie sich ihre Beschreibung ansehen, können Sie besser verstehen, wie es funktioniert und wie es aufgebaut ist, wenn Sie weitere Informationen wünschen.
MAMA
MUM wurde auch auf der Google I/O im Mai 2021 angekündigt.
Obwohl es revolutionär ist, ist es täuschend einfach zu beschreiben.
MUM steht für Multitask Unified Model und ist multimodal. Dies bedeutet, dass es verschiedene Inhaltsformate wie Tests, Bilder, Videos usw. „versteht“. Dadurch kann es Informationen aus mehreren Modalitäten gewinnen und darauf reagieren.
Übrigens: Dies ist nicht der erste Einsatz der MultiModel-Architektur. Es wurde erstmals 2017 von Google vorgestellt.
Da MUM außerdem in Dingen und nicht in Strings funktioniert, kann es Informationen über Sprachen hinweg sammeln und dann eine Antwort in der eigenen Sprache des Benutzers liefern. Dies öffnet die Tür zu enormen Verbesserungen beim Informationszugang, insbesondere für diejenigen, die Sprachen sprechen, die im Internet nicht berücksichtigt werden, aber auch Englischsprachige werden direkt davon profitieren.
Das Beispiel, das Google verwendet, ist ein Wanderer, der den Berg Fuji besteigen möchte. Einige der besten Tipps und Informationen sind möglicherweise auf Japanisch verfasst und stehen dem Benutzer überhaupt nicht zur Verfügung, da er nicht weiß, wie er sie an die Oberfläche bringen soll, selbst wenn er sie übersetzen könnte.
Ein wichtiger Hinweis zu MUM ist, dass das Modell Inhalte nicht nur versteht, sondern produzieren kann. Anstatt also einen Benutzer passiv zu einem Ergebnis zu schicken, kann es die Erfassung von Daten aus mehreren Quellen erleichtern und das Feedback (Seite, Stimme usw.) selbst bereitstellen.
Dies mag für viele, mich eingeschlossen, auch ein besorgniserregender Aspekt dieser Technologie sein.
Wo sonst maschinelles Lernen eingesetzt wird
Wir haben nur einige der Schlüsselalgorithmen angesprochen, von denen Sie sicher schon gehört haben und von denen ich glaube, dass sie einen erheblichen Einfluss auf die organische Suche haben. Aber das ist noch lange nicht alles, wo maschinelles Lernen eingesetzt wird.
Wir können zum Beispiel auch fragen:
- Was treibt in Ads die Systeme hinter automatisierten Gebotsstrategien und Anzeigenautomatisierung an?
- Woher weiß das System in News, wie Storys gruppiert werden?
- Wie identifiziert das System in Bildern bestimmte Objekte und Objekttypen?
- Wie filtert das System in E-Mail Spam?
- Wie geht das System beim Übersetzen mit dem Lernen neuer Wörter und Sätze um?
- Wie lernt das System in Video, welche Videos als nächstes empfohlen werden?
All diese Fragen und Hunderte, wenn nicht viele Tausende mehr haben alle die gleiche Antwort:
Maschinelles Lernen.
Arten von Algorithmen und Modellen für maschinelles Lernen
Gehen wir nun durch zwei Überwachungsebenen von Algorithmen und Modellen für maschinelles Lernen – überwachtes und unüberwachtes Lernen. Es ist wichtig zu verstehen, welche Art von Algorithmus wir betrachten und wo wir danach suchen müssen.
Überwachtes Lernen
Einfach ausgedrückt: Beim überwachten Lernen werden dem Algorithmus vollständig gekennzeichnete Trainings- und Testdaten übergeben.
Das heißt, jemand hat sich die Mühe gemacht, Tausende (oder Millionen) von Beispielen zu kennzeichnen, um ein Modell mit zuverlässigen Daten zu trainieren. Zum Beispiel rote Hemden in x Fotos von Personen mit roten Hemden kennzeichnen.
Überwachtes Lernen ist nützlich bei Klassifizierungs- und Regressionsproblemen. Klassifizierungsprobleme sind ziemlich einfach. Feststellen, ob etwas Teil einer Gruppe ist oder nicht.
Ein einfaches Beispiel ist Google Fotos.
Google hat mich sowie Stadien klassifiziert. Sie haben nicht jedes dieser Bilder manuell beschriftet. Das Modell wurde jedoch mit manuell beschrifteten Daten für Phasen trainiert. Und jeder, der Google Fotos verwendet hat, weiß, dass er Sie regelmäßig auffordert, Fotos und die darauf abgebildeten Personen zu bestätigen. Wir sind die manuellen Etikettierer.
Schon mal ReCAPTCHA verwendet? Rate mal, was du tust? Das stimmt. Du hilfst regelmäßig beim Trainieren von Machine-Learning-Modellen.
Regressionsprobleme hingegen befassen sich mit Problemen, bei denen es eine Reihe von Eingaben gibt, die einem Ausgabewert zugeordnet werden müssen.
Ein einfaches Beispiel ist ein System zur Schätzung des Verkaufspreises eines Hauses mit der Eingabe von Quadratmetern, Anzahl der Schlafzimmer, Anzahl der Badezimmer, Entfernung vom Meer usw.
Können Sie sich andere Systeme vorstellen, die eine Vielzahl von Merkmalen/Signalen enthalten und dann der betreffenden Entität (/Site) einen Wert zuweisen müssen?
Regression ist zwar sicherlich komplexer und umfasst eine enorme Anzahl individueller Algorithmen, die verschiedene Funktionen erfüllen, aber Regression ist wahrscheinlich einer der Algorithmustypen, der die Kernfunktionen der Suche antreibt.
Ich vermute, wir bewegen uns hier in halbüberwachte Modelle – mit manueller Kennzeichnung (denken Sie an Qualitätsbewerter) in einigen Phasen und systemerfassten Signalen, die die Zufriedenheit der Benutzer mit den Ergebnissätzen bestimmen, die zum Anpassen und Erstellen der verwendeten Modelle verwendet werden .
Unbeaufsichtigtes Lernen
Beim unüberwachten Lernen erhält ein System einen Satz unbeschrifteter Daten und muss selbst bestimmen, was damit geschehen soll.
Es wird kein Endziel angegeben. Das System kann ähnliche Elemente gruppieren, nach Ausreißern suchen, Korrelationen finden usw.
Unüberwachtes Lernen wird verwendet, wenn Sie viele Daten haben und nicht im Voraus wissen können oder wissen, wie sie verwendet werden sollen.
Ein gutes Beispiel könnte Google News sein.
Google bündelt ähnliche Nachrichten und bringt auch Nachrichten zum Vorschein, die vorher nicht existierten (es handelt sich also um Nachrichten).
Diese Aufgaben würden am besten von hauptsächlich (aber nicht ausschließlich) unbeaufsichtigten Modellen durchgeführt. Modelle, die „gesehen“ haben, wie erfolgreich oder erfolglos vorheriges Clustering oder Surface-Darstellung verlaufen ist, aber nicht in der Lage sind, dies vollständig auf die aktuellen Daten anzuwenden, die nicht gekennzeichnet sind (wie die vorherigen Nachrichten), und Entscheidungen treffen können.
Es ist ein unglaublich wichtiger Bereich des maschinellen Lernens in Bezug auf die Suche, insbesondere wenn sich die Dinge erweitern.
Google Translate ist ein weiteres gutes Beispiel. Nicht die Eins-zu-eins-Übersetzung, die früher existierte, bei der das System darauf trainiert wurde, zu verstehen, dass das Wort x im Englischen gleich dem Wort y im Spanischen ist, sondern neuere Techniken, die nach Mustern in der Verwendung beider suchen und die Übersetzung durch Semi verbessern -überwachtes Lernen (einige beschriftete Daten und viele nicht) und unüberwachtes Lernen, Übersetzen von einer Sprache in eine (dem System) völlig unbekannte Sprache.
Wir haben das oben bei MUM gesehen, aber es existiert in anderen Zeitungen und Modellen sind gut.
Nur der Anfang
Hoffentlich hat dies eine Grundlage für maschinelles Lernen und seine Verwendung bei der Suche geschaffen.
In meinen zukünftigen Artikeln wird es nicht nur darum gehen, wie und wo maschinelles Lernen zu finden ist (obwohl einige dies tun werden). Wir werden auch in praktische Anwendungen des maschinellen Lernens eintauchen, die Sie nutzen können, um ein besserer SEO zu sein. Keine Sorge, in diesen Fällen habe ich die Programmierung für Sie übernommen und im Allgemeinen ein benutzerfreundliches Google Colab bereitgestellt, dem Sie folgen können und das Ihnen bei der Beantwortung einiger wichtiger SEO- und Geschäftsfragen hilft.
Sie können beispielsweise direkte maschinelle Lernmodelle verwenden, um Ihr Verständnis Ihrer Websites, Inhalte, Zugriffe und mehr zu erweitern. Mein nächster Artikel zeigt Ihnen wie. Teaser: Zeitreihenprognose.
Die in diesem Artikel geäußerten Meinungen sind die des Gastautors und nicht unbedingt Search Engine Land. Mitarbeiter Autoren sind hier aufgelistet.