
Una guida all'apprendimento automatico nella ricerca: termini chiave, concetti e algoritmi
Pubblicato: 2022-05-02Quando si tratta di machine learning, ci sono alcuni concetti e termini generali che tutti coloro che effettuano ricerche dovrebbero conoscere. Dovremmo tutti sapere dove viene utilizzato l'apprendimento automatico e i diversi tipi di apprendimento automatico esistenti.
Continua a leggere per comprendere meglio come l'apprendimento automatico influisce sulla ricerca, cosa stanno facendo i motori di ricerca e come riconoscere l'apprendimento automatico sul lavoro. Cominciamo con alcune definizioni. Quindi entreremo negli algoritmi e nei modelli di apprendimento automatico.
Termini di apprendimento automatico
Quelle che seguono sono le definizioni di alcuni importanti termini di apprendimento automatico, la maggior parte dei quali sarà discussa ad un certo punto nell'articolo. Questo non vuole essere un glossario completo di ogni termine di machine learning. Se lo desideri, Google ne fornisce uno buono qui.
- Algoritmo : un processo matematico eseguito sui dati per produrre un output. Esistono diversi tipi di algoritmi per diversi problemi di apprendimento automatico.
- Intelligenza artificiale (AI) : un campo dell'informatica incentrato sull'equipaggiamento dei computer con abilità o abilità che replicano o sono ispirate dall'intelligenza umana.
- Corpus : una raccolta di testi scritti. Di solito organizzato in qualche modo.
- Entità : una cosa o un concetto unico, singolare, ben definito e distinguibile. Puoi pensarlo vagamente come un sostantivo, anche se è un po' più ampio di così. Una specifica tonalità di rosso sarebbe un'entità. È unico e singolare in quanto nient'altro è esattamente come questo, è ben definito (pensa al codice esadecimale) ed è distinguibile in quanto puoi distinguerlo da qualsiasi altro colore.
- Machine Learning : un campo dell'intelligenza artificiale, incentrato sulla creazione di algoritmi, modelli e sistemi per eseguire compiti e in generale per migliorare se stessi nell'esecuzione di quel compito senza essere esplicitamente programmati.
- Modello: un modello viene spesso confuso con un algoritmo. La distinzione può diventare sfocata (a meno che tu non sia un ingegnere di apprendimento automatico). In sostanza, la differenza è che mentre un algoritmo è semplicemente una formula che produce un valore di output, un modello è la rappresentazione di ciò che quell'algoritmo ha prodotto dopo essere stato addestrato per un'attività specifica. Quindi, quando diciamo "modello BERT" ci riferiamo al BERT che è stato addestrato per uno specifico compito NLP (quale compito e dimensione del modello determineranno quale specifico modello BERT).
- Natural Language Processing (NLP): un termine generico per descrivere il campo di lavoro nell'elaborazione di informazioni basate sul linguaggio per completare un'attività.
- Rete neurale : un'architettura modello che, prendendo ispirazione dal cervello, include uno strato di input (dove entrano i segnali - in un essere umano potresti pensarlo come il segnale inviato al cervello quando un oggetto viene toccato)), un certo numero di livelli nascosti (fornendo un numero di percorsi diversi l'input può essere regolato per produrre un output) e il livello di output. I segnali entrano, testano più "percorsi" diversi per produrre lo strato di uscita e sono programmati per gravitare verso condizioni di uscita sempre migliori. Visivamente può essere rappresentato da:
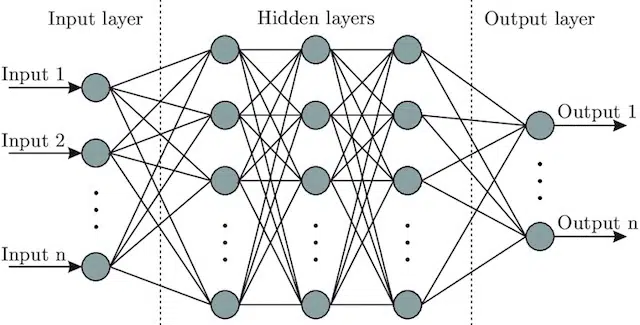
Intelligenza artificiale vs. machine learning: qual è la differenza?
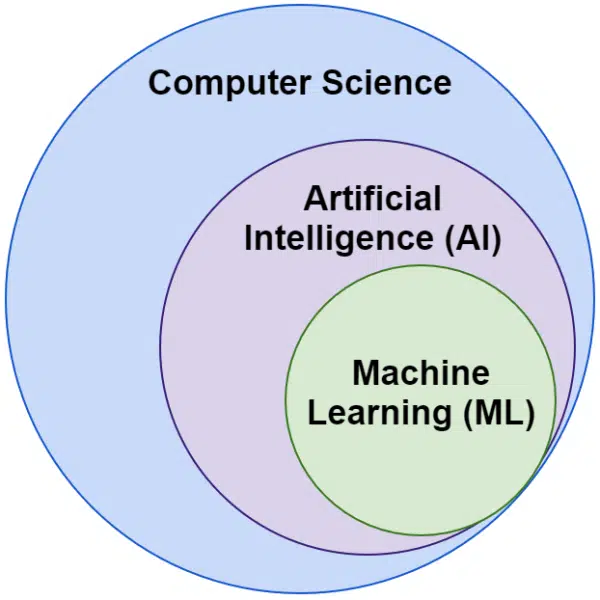
Spesso sentiamo le parole intelligenza artificiale e machine learning usate in modo intercambiabile. Non sono esattamente la stessa cosa.
L'intelligenza artificiale è il campo in cui le macchine imitano l'intelligenza, mentre l'apprendimento automatico è la ricerca di sistemi in grado di apprendere senza essere esplicitamente programmati per un'attività.
Visivamente, puoi pensarlo in questo modo:
Gli algoritmi di Google relativi all'apprendimento automatico
Tutti i principali motori di ricerca utilizzano l'apprendimento automatico in uno o più modi. In effetti, Microsoft sta producendo alcune scoperte significative. Così sono i social network come Facebook attraverso Meta AI con modelli come WebFormer.
Ma il nostro obiettivo qui è SEO. E sebbene Bing sia un motore di ricerca, con una quota di mercato statunitense del 6,61%, non ci concentreremo su di esso in questo articolo mentre esploriamo le tecnologie di ricerca popolari e importanti.
Google utilizza una pletora di algoritmi di apprendimento automatico. Non c'è letteralmente modo che tu, io o qualsiasi ingegnere di Google possiate conoscerli tutti. Inoltre, molti sono semplicemente eroi sconosciuti della ricerca e non abbiamo bisogno di esplorarli completamente poiché semplicemente fanno funzionare meglio altri sistemi.
Per il contesto, questi includerebbero algoritmi e modelli come:
- Google FLAN – che semplicemente velocizza e rende meno costoso dal punto di vista computazionale il trasferimento dell'apprendimento da un dominio all'altro. Vale la pena notare: nell'apprendimento automatico, un dominio non fa riferimento a un sito Web ma piuttosto all'attività o ai gruppi di attività che svolge, come l'analisi del sentimento in Natural Language Processing (NLP) o il rilevamento di oggetti in Computer Vision (CV).
- V-MoE : l'unico compito di questo modello è consentire l'addestramento di modelli di visione di grandi dimensioni con meno risorse. Sono sviluppi come questo che consentono il progresso ampliando ciò che può essere fatto tecnicamente.
- Sub-Pseudo etichette : questo sistema migliora il riconoscimento delle azioni nei video, aiutandoti in una varietà di comprensioni e attività relative ai video.
Nessuno di questi ha un impatto diretto sulla classifica o sui layout. Ma influiscono sul successo di Google.
Quindi ora diamo un'occhiata agli algoritmi e ai modelli principali coinvolti con le classifiche di Google.
RankBrain
È qui che è iniziato tutto, l'introduzione del machine learning negli algoritmi di Google.
Introdotto nel 2015, l'algoritmo RankBrain è stato applicato a query che Google non aveva mai visto prima (rappresentando il 15% di esse). Entro giugno 2016 è stato ampliato per includere tutte le query.
A seguito di enormi progressi come Hummingbird e Knowledge Graph, RankBrain ha aiutato Google a espandersi dalla visione del mondo come stringhe (parole chiave e insiemi di parole e caratteri) alle cose (entità). Ad esempio, prima di questo Google essenzialmente vedeva la città in cui vivo (Victoria, BC) come due parole che si verificano regolarmente insieme, ma che ricorrono anche regolarmente separatamente e possono, ma non sempre, significare qualcosa di diverso quando lo fanno.
Dopo RankBrain hanno visto Victoria, BC come un'entità - forse l'ID macchina (/m/07ypt) - e quindi anche se avessero colpito solo la parola "Victoria", se potessero stabilire il contesto lo tratterebbero come la stessa entità di Vittoria, BC.
Con questo "vedono" oltre le semplici parole chiave e il significato, solo il nostro cervello lo fa. Dopotutto, quando leggi "pizza vicino a me" lo capisci in termini di tre singole parole o hai un'idea visiva nella tua testa di pizza e una comprensione di te nel luogo in cui ti trovi?
In breve, RankBrain aiuta gli algoritmi ad applicare i loro segnali alle cose invece che alle parole chiave.
BERT
BERT ( R epresentazioni di encoder bidirezionali da trasformatori).
Con l'introduzione di un modello BERT negli algoritmi di Google nel 2019, Google è passato dalla comprensione unidirezionale dei concetti a quella bidirezionale.
Questo non è stato un cambiamento banale.
La visuale di Google inclusa nell'annuncio dell'open-sourcing del modello BERT nel 2018 aiuta a dipingere il quadro:
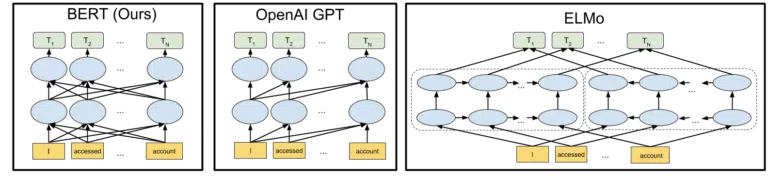
Senza entrare nei dettagli su come funzionano i token e i trasformatori nell'apprendimento automatico, è sufficiente per le nostre esigenze qui guardare semplicemente le tre immagini e le frecce e pensare a come nella versione BERT, ciascuna delle parole ottenga informazioni da quelle su una delle due lato, comprese quelle più parole di distanza.
Laddove in precedenza un modello poteva applicare l'intuizione dalle parole solo in una direzione, ora acquisiscono una comprensione contestuale basata sulle parole in entrambe le direzioni.
Un semplice esempio potrebbe essere "l'auto è rossa".
Solo dopo che il BERT fu rosso si capì propriamente di essere il colore dell'auto, perché fino ad allora la parola rosso veniva dopo la parola auto, e quell'informazione non veniva rispedita.
Per inciso, se desideri giocare con BERT, su GitHub sono disponibili vari modelli.
LaMDA
LaMDA non è stato ancora distribuito in natura ed è stato annunciato per la prima volta a Google I/O nel maggio del 2021.
Per chiarire, quando scrivo "non è stato ancora schierato" intendo "al meglio delle mie conoscenze". Dopotutto, abbiamo scoperto RankBrain mesi dopo che era stato implementato negli algoritmi. Detto questo, quando sarà sarà rivoluzionario.
LaMDA è un modello di linguaggio conversazionale, che apparentemente schiaccia lo stato dell'arte attuale.
L'attenzione con LaMDA è fondamentalmente duplice:
- Migliora la ragionevolezza e la specificità nella conversazione. In sostanza, per garantire che una risposta in una chat sia ragionevole E specifica. Ad esempio, alla maggior parte delle domande la risposta "Non lo so" è ragionevole ma non specifica. D'altra parte, una risposta a una domanda del tipo "Come stai?" cioè: "Mi piace la zuppa d'anatra in una giornata piovosa. È molto simile al volo degli aquiloni. è molto specifico ma difficilmente ragionevole.
LaMDA aiuta a risolvere entrambi i problemi. - Quando comunichiamo, raramente è una conversazione lineare. Quando pensiamo a dove potrebbe iniziare e dove finire una discussione, anche se riguardasse un singolo argomento (ad esempio, "Perché il nostro traffico è diminuito questa settimana?"), generalmente avremo trattato diversi argomenti che non avremmo previsto di entrare.
Chiunque abbia utilizzato un chatbot sa che sono abissali in questi scenari. Non si adattano bene e non trasportano bene le informazioni passate nel futuro (e viceversa).
LaMDA affronta ulteriormente questo problema.
Un esempio di conversazione di Google è:


Possiamo vederlo adattarsi molto meglio di quanto ci si aspetterebbe da un chatbot.
Vedo che LaMDA viene implementato nell'Assistente Google. Ma se ci riflettiamo, le capacità avanzate nel comprendere come funziona un flusso di query a livello individuale sarebbero sicuramente d'aiuto sia nella personalizzazione dei layout dei risultati di ricerca, sia nella presentazione di argomenti e query aggiuntivi all'utente.
Fondamentalmente, sono abbastanza sicuro che vedremo tecnologie ispirate a LaMDA permeare aree di ricerca non chat.
KELM
Sopra, quando stavamo discutendo di RankBrain, abbiamo toccato gli ID macchina e le entità. Bene, KELM, che è stato annunciato a maggio 2021, lo porta a un livello completamente nuovo.
KELM è nato dallo sforzo di ridurre i pregiudizi e le informazioni tossiche nella ricerca. Poiché si basa su informazioni attendibili (Wikidata), può essere utilizzato bene per questo scopo.
Piuttosto che essere un modello, KELM è più simile a un set di dati. Fondamentalmente, si tratta di dati di addestramento per modelli di apprendimento automatico. Più interessante per i nostri scopi qui, è che ci parla di un approccio che Google adotta ai dati.
In poche parole, Google ha preso il Wikidata Knowledge Graph inglese, che è una raccolta di triple (entità soggetto, relazione, entità oggetto (auto, colore, rosso) e lo ha trasformato in vari sottografi di entità e lo ha verbalizzato. Questo è più facilmente spiegato in un'immagine:
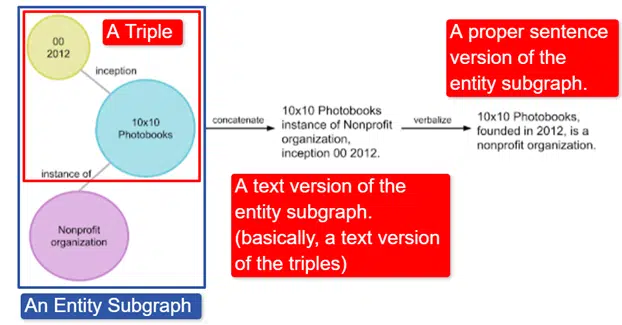
In questa immagine vediamo:
- Il triplo descrive una relazione individuale.
- Il sottografo dell'entità che mappa una pluralità di triple relative a un'entità centrale.
- La versione testuale del sottografo dell'entità.
- La frase giusta.
Questo è quindi utilizzabile da altri modelli per addestrarli a riconoscere i fatti e filtrare le informazioni tossiche.
Google ha reso open source il corpus ed è disponibile su GitHub. Guardare la loro descrizione ti aiuterà a capire come funziona e la sua struttura, se desideri maggiori informazioni.
MAMMA
MUM è stato anche annunciato a Google I/O nel maggio 2021.
Sebbene sia rivoluzionario, è ingannevolmente semplice da descrivere.
MUM sta per M ultitask Unified M odel ed è multimodale. Ciò significa che "capisce" diversi formati di contenuto come test, immagini, video, ecc. Ciò gli conferisce il potere di ottenere informazioni da più modalità e di rispondere.
A parte: questo non è il primo utilizzo dell'architettura MultiModel. È stato presentato per la prima volta da Google nel 2017.
Inoltre, poiché MUM funziona nelle cose e non nelle stringhe, può raccogliere informazioni in tutte le lingue e quindi fornire una risposta nell'ambito dell'utente. Questo apre la porta a grandi miglioramenti nell'accesso alle informazioni, soprattutto per coloro che parlano lingue che non sono soddisfatte su Internet, ma anche gli anglofoni ne trarranno vantaggio diretto.
L'esempio utilizzato da Google è un escursionista che vuole scalare il Monte Fuji. Alcuni dei migliori suggerimenti e informazioni potrebbero essere scritti in giapponese e completamente non disponibili per l'utente in quanto non sapranno come farne emergere anche se potrebbero tradurli.
Una nota importante su MUM è che il modello non solo comprende il contenuto, ma può produrlo. Quindi, anziché inviare passivamente un utente a un risultato, può facilitare la raccolta di dati da più fonti e fornire il feedback stesso (pagina, voce, ecc.).
Questo può anche essere un aspetto preoccupante di questa tecnologia per molti, me compreso.
Dove altro viene utilizzato l'apprendimento automatico
Abbiamo solo toccato alcuni degli algoritmi chiave di cui avrai sentito parlare e che credo stiano avendo un impatto significativo sulla ricerca organica. Ma questo è lontano dalla totalità di dove viene utilizzato l'apprendimento automatico.
Ad esempio, possiamo anche chiedere:
- In Ads, cosa guida i sistemi alla base delle strategie di offerte automatiche e dell'automazione degli annunci?
- In News, come fa il sistema a sapere come raggruppare le storie?
- In Immagini, in che modo il sistema identifica oggetti e tipi di oggetti specifici?
- In Email, in che modo il sistema filtra lo spam?
- In Translation, come fa il sistema a imparare nuove parole e frasi?
- In Video, in che modo quelli del sistema imparano quali video consigliare dopo?
Tutte queste domande e centinaia se non molte migliaia di altre hanno tutte la stessa risposta:
Apprendimento automatico.
Tipi di algoritmi e modelli di machine learning
Ora esaminiamo due livelli di supervisione di algoritmi e modelli di apprendimento automatico: apprendimento supervisionato e non supervisionato. Comprendere il tipo di algoritmo che stiamo esaminando e dove cercarli è importante.
Apprendimento supervisionato
In poche parole, con l'apprendimento supervisionato l'algoritmo riceve dati di addestramento e test completamente etichettati.
Vale a dire, qualcuno ha compiuto lo sforzo di etichettare migliaia (o milioni) di esempi per addestrare un modello su dati affidabili. Ad esempio, etichettare magliette rosse in x numero di foto di persone che indossano magliette rosse.
L'apprendimento supervisionato è utile nei problemi di classificazione e regressione. I problemi di classificazione sono abbastanza semplici. Determinare se qualcosa è o non fa parte di un gruppo.
Un semplice esempio è Google Foto.
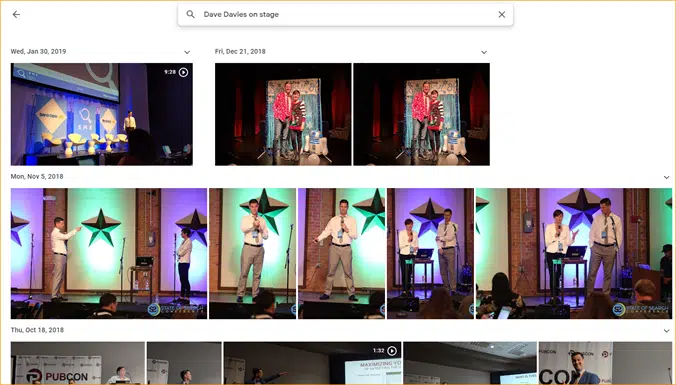
Google mi ha classificato, così come le fasi. Non hanno etichettato manualmente ciascuna di queste immagini. Ma il modello sarà stato addestrato su dati etichettati manualmente per le fasi. E chiunque abbia utilizzato Google Foto sa che ti chiedono periodicamente di confermare le foto e le persone in esse contenute. Noi siamo le etichettatrici manuali.
Hai mai usato ReCAPTCHA? Indovina cosa stai facendo? Giusto. Aiuti regolarmente ad addestrare modelli di machine learning.
I problemi di regressione, d'altra parte, trattano problemi in cui esiste un insieme di input che devono essere mappati su un valore di output.
Un semplice esempio è pensare ad un sistema per stimare il prezzo di vendita di una casa inserendo i metri quadrati, il numero delle camere da letto, il numero dei bagni, la distanza dall'oceano, ecc.
Riuscite a pensare ad altri sistemi che potrebbero contenere un'ampia gamma di funzioni/segnali e quindi dover assegnare un valore all'entità (/sito) in questione?
Sebbene sia certamente più complesso e includa un'enorme gamma di singoli algoritmi che servono varie funzioni, la regressione è probabilmente uno dei tipi di algoritmi che guidano le funzioni principali della ricerca.
Sospetto che qui ci stiamo spostando verso modelli semi-supervisionati, con l'etichettatura manuale (pensa ai valutatori della qualità) eseguita in alcune fasi e i segnali raccolti dal sistema che determinano la soddisfazione degli utenti con i set di risultati utilizzati per regolare e creare i modelli in gioco .
Apprendimento senza supervisione
Nell'apprendimento non supervisionato, un sistema riceve una serie di dati senza etichetta e lascia che decida da solo cosa farne.
Non è specificato alcun obiettivo finale. Il sistema può raggruppare elementi simili, cercare valori anomali, trovare correlazioni, ecc.
L'apprendimento non supervisionato viene utilizzato quando hai molti dati e non puoi o non sai in anticipo come dovrebbe essere utilizzato.
Un buon esempio potrebbe essere Google News.
Google raggruppa notizie simili e fa emergere anche notizie che in precedenza non esistevano (quindi sono notizie).
Questi compiti sarebbero svolti al meglio da modelli principalmente (sebbene non esclusivamente) non supervisionati. Modelli che hanno “visto” quanto successo o insuccesso sono stati i precedenti raggruppamenti o emersioni, ma non sono in grado di applicarli completamente ai dati attuali, che non sono etichettati (come lo era la notizia precedente) e di prendere decisioni.
È un'area incredibilmente importante dell'apprendimento automatico in quanto riguarda la ricerca, soprattutto quando le cose si espandono.
Google Translate è un altro buon esempio. Non la traduzione uno-a-uno che esisteva, in cui il sistema è stato addestrato a comprendere che la parola x in inglese è uguale alla parola y in spagnolo, ma piuttosto tecniche più recenti che cercano modelli nell'uso di entrambi, migliorando la traduzione attraverso semi -apprendimento supervisionato (alcuni dati etichettati e molto altro) e apprendimento non supervisionato, traducendo da una lingua in una lingua completamente sconosciuta (al sistema).
L'abbiamo visto con MUM sopra, ma esiste in altri documenti e i modelli vanno bene.
Solo l'inizio
Si spera che questo abbia fornito una linea di base per l'apprendimento automatico e il modo in cui viene utilizzato nella ricerca.
I miei articoli futuri non riguarderanno solo come e dove è possibile trovare l'apprendimento automatico (anche se alcuni lo faranno). Approfondiremo anche le applicazioni pratiche dell'apprendimento automatico che puoi utilizzare per essere un SEO migliore. Non preoccuparti, in questi casi avrò fatto la codifica per te e generalmente fornirò un Google Colab facile da usare da seguire, aiutandoti a rispondere ad alcune importanti domande SEO e aziendali.
Ad esempio, puoi utilizzare modelli di apprendimento automatico diretto per far evolvere la tua comprensione di siti, contenuti, traffico e altro ancora. Il mio prossimo articolo ti mostrerà come fare. Teaser: previsioni di serie temporali.
Le opinioni espresse in questo articolo sono quelle dell'autore ospite e non necessariamente di Search Engine Land. Gli autori dello staff sono elencati qui.