
دليل للتعلم الآلي في البحث: المصطلحات الأساسية والمفاهيم والخوارزميات
نشرت: 2022-05-02عندما يتعلق الأمر بالتعلم الآلي ، هناك بعض المفاهيم والمصطلحات العامة التي يجب على كل شخص في البحث معرفتها. يجب أن نعرف جميعًا أين يتم استخدام التعلم الآلي ، وأنواع التعلم الآلي المختلفة الموجودة.
تابع القراءة للحصول على فهم أفضل لكيفية تأثير التعلم الآلي على البحث ، وما تفعله محركات البحث وكيفية التعرف على التعلم الآلي في العمل. لنبدأ ببعض التعريفات. ثم ندخل في خوارزميات ونماذج التعلم الآلي.
شروط التعلم الآلي
فيما يلي تعريفات لبعض مصطلحات التعلم الآلي المهمة ، والتي سيتم مناقشة معظمها في مرحلة ما من المقالة. لا يُقصد بهذا أن يكون مسردًا شاملاً لكل مصطلح من مصطلحات التعلم الآلي. إذا كنت تريد ذلك ، فإن Google تقدم خدمة جيدة هنا.
- الخوارزمية : عملية حسابية يتم تشغيلها على البيانات لإنتاج مخرجات. هناك أنواع مختلفة من الخوارزميات لمشاكل التعلم الآلي المختلفة.
- الذكاء الاصطناعي (AI) : مجال من مجالات علوم الكمبيوتر يركز على تزويد أجهزة الكمبيوتر بالمهارات أو القدرات التي تتكرر أو تستلهم من الذكاء البشري.
- كوربوس : مجموعة من النصوص المكتوبة. عادة ما تكون منظمة بطريقة ما.
- الكيان : شيء أو مفهوم فريد ومفرد ومحدد ومميز. يمكنك التفكير فيه بشكل فضفاض على أنه اسم ، على الرغم من أنه أوسع قليلاً من ذلك. سيكون اللون الأحمر كيانًا معينًا. هل هي فريدة ومميزة من حيث أنه لا يوجد شيء آخر يشبهها تمامًا ، فهي محددة جيدًا (فكر في الكود السداسي) ويمكن تمييزها من حيث أنه يمكنك تمييزها عن أي لون آخر.
- التعلم الآلي : مجال من مجالات الذكاء الاصطناعي ، يركز على إنشاء الخوارزميات والنماذج والأنظمة لأداء المهام وبشكل عام لتحسين أداء أنفسهم في أداء تلك المهمة دون أن تتم برمجتهم بشكل صريح.
- النموذج: غالبًا ما يتم الخلط بين النموذج والخوارزمية. يمكن أن يصبح التمييز ضبابيًا (إلا إذا كنت مهندسًا لتعلم الآلة). بشكل أساسي ، يتمثل الاختلاف في أنه عندما تكون الخوارزمية مجرد صيغة تنتج قيمة مخرجات ، فإن النموذج هو تمثيل ما أنتجته تلك الخوارزمية بعد تدريبها على مهمة محددة. لذلك ، عندما نقول "نموذج BERT" فإننا نشير إلى BERT الذي تم تدريبه لمهمة محددة في البرمجة اللغوية العصبية (أي المهمة وحجم النموذج سيحددان نموذج BERT المحدد).
- معالجة اللغة الطبيعية (NLP): مصطلح عام لوصف مجال العمل في معالجة المعلومات المستندة إلى اللغة لإكمال مهمة.
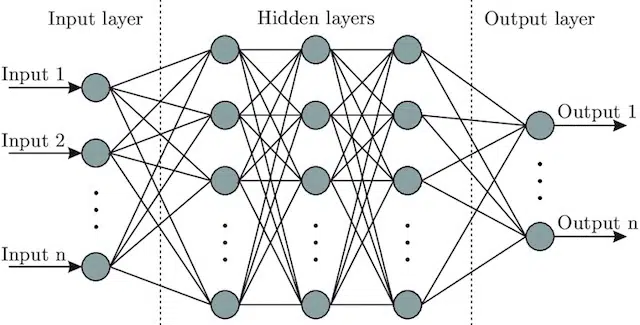
- الشبكة العصبية : بنية نموذجية ، مستوحاة من الدماغ ، تتضمن طبقة إدخال (حيث تدخل الإشارات - في الإنسان قد تعتقد أنها إشارة مرسلة إلى الدماغ عند لمس شيء ما)) ، عدد من الطبقات المخفية (توفير عدد من المسارات المختلفة يمكن تعديل المدخلات لإنتاج مخرجات) وطبقة الإخراج. تدخل الإشارات وتختبر "مسارات" مختلفة متعددة لإنتاج طبقة الإخراج ، وهي مبرمجة للانجذاب نحو ظروف خرج أفضل من أي وقت مضى. بصريا يمكن تمثيلها من قبل:
الذكاء الاصطناعي مقابل التعلم الآلي: ما الفرق؟
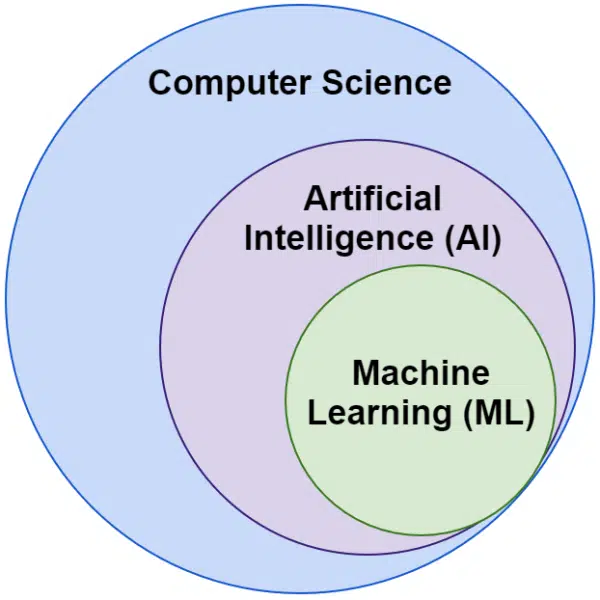
غالبًا ما نسمع كلمات الذكاء الاصطناعي والتعلم الآلي تستخدم بالتبادل. هم ليسا نفس الشيء بالضبط.
الذكاء الاصطناعي هو مجال صنع الآلات التي تحاكي الذكاء ، في حين أن التعلم الآلي هو السعي وراء أنظمة يمكنها التعلم دون أن تكون مبرمجة بشكل صريح لمهمة ما.
بصريًا ، يمكنك التفكير في الأمر على النحو التالي:
خوارزميات Google المتعلقة بالتعلم الآلي
تستخدم جميع محركات البحث الرئيسية التعلم الآلي بطريقة واحدة أو عدة طرق. في الواقع ، تحقق Microsoft بعض الاختراقات المهمة. وكذلك الشبكات الاجتماعية مثل Facebook من خلال Meta AI مع نماذج مثل WebFormer.
لكن تركيزنا هنا هو تحسين محركات البحث. وعلى الرغم من أن Bing هو محرك بحث ، بحصة سوقية أمريكية تبلغ 6.61٪ ، فإننا لن نركز عليه في هذه المقالة بينما نستكشف التقنيات الشائعة والمهمة المتعلقة بالبحث.
تستخدم Google عددًا كبيرًا من خوارزميات التعلم الآلي. لا توجد طريقة حرفيًا يمكنك أنت أو أنا أو أي مهندس في Google من معرفتهم جميعًا. علاوة على ذلك ، فإن الكثير منهم مجرد أبطال غير معروفين للبحث ، ولا نحتاج إلى استكشافهم بالكامل لأنهم ببساطة يجعلون الأنظمة الأخرى تعمل بشكل أفضل.
للسياق ، قد تشمل هذه الخوارزميات والنماذج مثل:
- Google FLAN - الذي يعمل ببساطة على تسريع عملية نقل التعلم من مجال إلى آخر وجعله أقل تكلفة من الناحية الحسابية. تجدر الإشارة إلى: في التعلم الآلي ، لا يشير المجال إلى موقع ويب بل إلى المهمة أو مجموعات المهام التي ينجزها ، مثل تحليل المشاعر في معالجة اللغة الطبيعية (NLP) أو اكتشاف الكائن في رؤية الكمبيوتر (CV).
- V-MoE - الوظيفة الوحيدة لهذا النموذج هي السماح بتدريب نماذج الرؤية الكبيرة بموارد أقل. إن مثل هذه التطورات هي التي تسمح بإحراز تقدم من خلال توسيع ما يمكن القيام به تقنيًا.
- التسميات الزائفة الفرعية - يعمل هذا النظام على تحسين التعرف على الإجراءات في الفيديو ، مما يساعد في مجموعة متنوعة من المفاهيم والمهام المتعلقة بالفيديو.
لا يؤثر أي من هذه بشكل مباشر على الترتيب أو التخطيطات. لكنها تؤثر على مدى نجاح Google.
لنلقِ نظرة الآن على الخوارزميات الأساسية والنماذج المتضمنة في تصنيفات Google.
الرتبة
هذا هو المكان الذي بدأ فيه كل شيء ، إدخال التعلم الآلي في خوارزميات Google.
تم تقديم خوارزمية RankBrain عام 2015 ، وتم تطبيقها على الاستفسارات التي لم ترها Google من قبل (تمثل 15٪ منها). بحلول يونيو 2016 تم توسيعه ليشمل جميع الاستفسارات.
بعد التطورات الهائلة مثل Hummingbird و Knowledge Graph ، ساعد RankBrain Google على التوسع من عرض العالم كسلاسل (كلمات رئيسية ومجموعات من الكلمات والأحرف) إلى أشياء (كيانات). على سبيل المثال ، قبل ذلك ، سترى Google بشكل أساسي المدينة التي أعيش فيها (فيكتوريا ، كولومبيا البريطانية) كلمتين تتواجدان بشكل متزامن ، ولكنهما تحدثان بشكل منفصل أيضًا ويمكن ولكن لا تعني دائمًا شيئًا مختلفًا عند حدوث ذلك.
بعد RankBrain ، رأوا فيكتوريا ، كولومبيا البريطانية ككيان - ربما معرف الجهاز (/ m / 07ypt) - ولذا حتى إذا قاموا فقط بالضغط على كلمة "Victoria" ، إذا تمكنوا من إنشاء السياق ، فسوف يعاملونه على أنه نفس الكيان مثل فيكتوريا ، كولومبيا البريطانية.
مع هذا "يرون" ما وراء مجرد الكلمات الرئيسية والمعنى ، فقط أدمغتنا تفعل ذلك. بعد كل شيء ، عندما تقرأ "بيتزا بالقرب مني" ، هل تفهم ذلك من حيث ثلاث كلمات فردية أو هل لديك صورة مرئية في رأسك للبيتزا ، وفهم لك في الموقع الذي تتواجد فيه؟
باختصار ، تساعد RankBrain الخوارزميات في تطبيق إشاراتها على الأشياء بدلاً من الكلمات الرئيسية.
بيرت
BERT (عروض B idirectional E ncoder R من T ransformers).
مع إدخال نموذج BERT في خوارزميات Google في عام 2019 ، تحولت Google من الفهم أحادي الاتجاه للمفاهيم إلى ثنائي الاتجاه.
لم يكن هذا تغييرا عاديا.
يساعد Google المرئي الذي تم تضمينه في إعلانهم عن المصادر المفتوحة لنموذج BERT في 2018 في رسم الصورة:
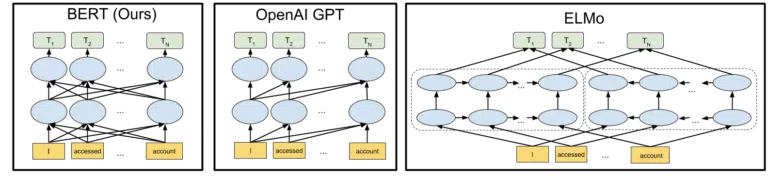
دون الخوض في التفاصيل حول كيفية عمل الرموز والمحولات في التعلم الآلي ، يكفي لاحتياجاتنا هنا أن ننظر ببساطة إلى الصور الثلاث والأسهم والتفكير في كيفية اكتساب كل كلمة في إصدار BERT معلومات من الكلمات الموجودة على أي منهما الجانب ، بما في ذلك تلك الكلمات المتعددة بعيدًا.
حيث كان يمكن للنموذج في السابق أن يطبق نظرة ثاقبة من الكلمات في اتجاه واحد فقط ، فإنهم يكتسبون الآن فهمًا سياقيًا يعتمد على الكلمات في كلا الاتجاهين.
مثال بسيط قد يكون "السيارة حمراء".
فقط بعد أن تم فهم BERT بشكل صحيح على أنه لون السيارة ، لأنه حتى ذلك الحين جاءت كلمة أحمر بعد كلمة car ، ولم يتم إرسال هذه المعلومات مرة أخرى.
جانبا ، إذا كنت ترغب في اللعب مع BERT ، تتوفر نماذج مختلفة على GitHub.
لامدا
لم يتم نشر LaMDA بعد في البرية ، وتم الإعلان عنه لأول مرة في Google I / O في مايو من عام 2021.
للتوضيح ، عندما أكتب عبارة "لم يتم نشرها بعد" أعني "على حد علمي." بعد كل شيء ، اكتشفنا معلومات عن RankBrain بعد أشهر من نشرها في الخوارزميات. بعد قولي هذا ، عندما يكون ذلك سيكون ثوريًا.
LaMDA هو نموذج لغة محادثة ، يبدو أنه يسحق أحدث ما توصلت إليه التكنولوجيا.
التركيز مع LaMDA ينقسم أساسًا إلى شقين:
- تحسين المعقولية والخصوصية في المحادثة. بشكل أساسي ، لضمان أن تكون الاستجابة في الدردشة معقولة ومحددة . على سبيل المثال ، بالنسبة لمعظم الأسئلة ، يكون الرد "لا أعرف" معقولًا ولكنه ليس محددًا. من ناحية أخرى ، رد على سؤال مثل "كيف حالك؟" وهذا يعني ، "أنا أحب حساء البط في يوم ممطر. إنه يشبه إلى حد كبير تحليق الطائرات الورقية ". محددة للغاية ولكنها ليست معقولة.
يساعد LaMDA في معالجة كلتا المشكلتين. - عندما نتواصل ، نادراً ما تكون محادثة خطية. عندما نفكر في المكان الذي يمكن أن تبدأ فيه المناقشة وأين تنتهي ، حتى لو كانت تدور حول موضوع واحد (على سبيل المثال ، "لماذا انخفضت حركة المرور لدينا هذا الأسبوع؟") ، سنكون عمومًا قد غطينا موضوعات مختلفة لم يكن لدينا توقع الدخول.
يعرف أي شخص استخدم روبوت الدردشة أنه سيئ للغاية في هذه السيناريوهات. إنها لا تتكيف بشكل جيد ، ولا تنقل المعلومات السابقة إلى المستقبل بشكل جيد (والعكس صحيح).
يعالج LaMDA كذلك هذه المشكلة.
نموذج محادثة من Google هو:

يمكننا أن نرى أنه يتكيف بشكل أفضل بكثير مما يتوقعه المرء من روبوت المحادثة.

أرى تطبيق LaMDA في مساعد Google. ولكن إذا فكرنا في الأمر ، فإن القدرات المحسّنة في فهم كيفية عمل تدفق الاستعلامات على المستوى الفردي ستساعد بالتأكيد في كل من تصميم تخطيطات نتائج البحث ، وعرض الموضوعات والاستفسارات الإضافية للمستخدم.
بشكل أساسي ، أنا متأكد من أننا سنرى تقنيات مستوحاة من LaMDA تتخلل مجالات البحث غير الدردشة.
KELM
أعلاه ، عندما كنا نناقش RankBrain ، تطرقنا إلى معرفات الأجهزة والكيانات. حسنًا ، KELM ، التي تم الإعلان عنها في مايو 2021 ، تأخذها إلى مستوى جديد تمامًا.
نشأت شركة KELM من الجهد المبذول لتقليل التحيز والمعلومات السامة في البحث. نظرًا لأنه يعتمد على معلومات موثوقة (ويكي بيانات) ، يمكن استخدامه جيدًا لهذا الغرض.
بدلاً من أن تكون KELM نموذجًا ، فهي أشبه بمجموعة بيانات. في الأساس ، إنها بيانات تدريبية لنماذج التعلم الآلي. الأكثر إثارة للاهتمام فيما يتعلق بأغراضنا هنا ، هو أنه يخبرنا عن نهج تتبعه Google في التعامل مع البيانات.
باختصار ، أخذ Google الرسم البياني المعرفي لـ Wikidata باللغة الإنجليزية ، وهو عبارة عن مجموعة من ثلاثيات (كيان الموضوع ، والعلاقة ، وكيان الكائن (السيارة ، واللون ، والأحمر) وحولته إلى رسوم بيانية فرعية مختلفة للكيان وقام بلفظه. ويمكن شرح ذلك بسهولة في صورة:
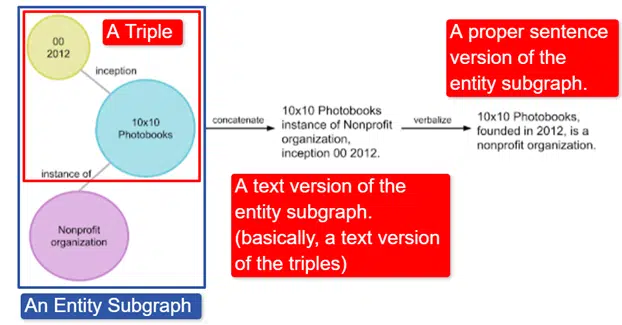
في هذه الصورة نرى:
- يصف الثلاثي علاقة فردية.
- يرسم الرسم البياني الفرعي للكيان مجموعة من ثلاثيات مرتبطة بكيان مركزي.
- النسخة النصية للرسم البياني الفرعي للكيان.
- الجملة الصحيحة.
يمكن استخدام هذا بعد ذلك بواسطة نماذج أخرى للمساعدة في تدريبهم على التعرف على الحقائق وتصفية المعلومات السامة.
قامت Google بفتح مجموعة المصادر ، وهي متوفرة على GitHub. سيساعدك النظر إلى وصفهم على فهم كيفية عمله وهيكله ، إذا كنت ترغب في مزيد من المعلومات.
ماما
تم الإعلان عن MUM أيضًا في Google I / O في مايو 2021.
على الرغم من كونها ثورية ، إلا أنه من السهل وصفها بشكل مخادع.
MUM تعني M ultitask U nified M odel وهو متعدد الوسائط. وهذا يعني أنه "يفهم" تنسيقات المحتوى المختلفة مثل الاختبار ، والصور ، والفيديو ، وما إلى ذلك. وهذا يمنحه القدرة على اكتساب المعلومات من طرائق متعددة ، وكذلك الاستجابة.
جانبا: هذا ليس أول استخدام لهندسة MultiModel. تم تقديمه لأول مرة بواسطة Google في عام 2017.
بالإضافة إلى ذلك ، نظرًا لأن MUM تعمل في الأشياء وليس في السلاسل ، يمكنها جمع المعلومات عبر اللغات ثم تقديم إجابة خاصة بالمستخدم. هذا يفتح الباب أمام تحسينات كبيرة في الوصول إلى المعلومات ، خاصة لأولئك الذين يتحدثون لغات لا يتم توفيرها على الإنترنت ، ولكن حتى المتحدثين باللغة الإنجليزية سيستفيدون بشكل مباشر.
المثال الذي تستخدمه Google هو متجول يريد تسلق جبل فوجي. قد تكون بعض أفضل النصائح والمعلومات مكتوبة باللغة اليابانية وهي غير متاحة تمامًا للمستخدم لأنهم لن يعرفوا كيفية عرضها على السطح حتى لو كان بإمكانهم ترجمتها.
ملاحظة مهمة على MUM هي أن النموذج لا يفهم المحتوى فحسب ، بل يمكنه أيضًا إنتاجه. لذلك ، بدلاً من إرسال المستخدم بشكل سلبي إلى نتيجة ما ، يمكن أن يسهل جمع البيانات من مصادر متعددة وتقديم الملاحظات (الصفحة ، والصوت ، وما إلى ذلك) نفسها.
قد يكون هذا أيضًا جانبًا مثيرًا للقلق من هذه التكنولوجيا بالنسبة للكثيرين ، بمن فيهم أنا.
في أي مكان آخر يتم استخدام التعلم الآلي
لقد تطرقنا فقط إلى بعض الخوارزميات الرئيسية التي سمعت عنها والتي أعتقد أن لها تأثيرًا كبيرًا على البحث العضوي. لكن هذا بعيد كل البعد عن مجمل مكان استخدام التعلم الآلي.
على سبيل المثال ، يمكننا أيضًا أن نسأل:
- في الإعلانات ، ما الذي يدفع الأنظمة وراء إستراتيجيات عروض الأسعار التلقائية وأتمتة الإعلانات؟
- في الأخبار ، كيف يعرف النظام كيفية تجميع القصص؟
- في الصور ، كيف يحدد النظام كائنات وأنواع كائنات معينة؟
- في البريد الإلكتروني ، كيف يقوم النظام بتصفية البريد العشوائي؟
- في الترجمة ، كيف يتعلم النظام الكلمات والعبارات الجديدة؟
- في الفيديو ، كيف يتعرف هؤلاء النظام على مقاطع الفيديو التي يجب التوصية بها بعد ذلك؟
كل هذه الأسئلة ومئات إن لم يكن عدة آلاف أخرى جميعها لها نفس الإجابة:
التعلم الالي.
أنواع خوارزميات ونماذج التعلم الآلي
الآن دعنا نتصفح مستويين من خوارزميات ونماذج التعلم الآلي - التعلم الخاضع للإشراف والتعلم غير الخاضع للإشراف. من المهم فهم نوع الخوارزمية التي نبحث عنها وأين نبحث عنها.
التعلم تحت الإشراف
ببساطة ، من خلال التعلم الخاضع للإشراف ، يتم تسليم الخوارزمية بيانات تدريب واختبار مصنفة بالكامل.
هذا يعني أن شخصًا ما قد بذل جهدًا في تصنيف آلاف (أو ملايين) الأمثلة لتدريب نموذج على بيانات موثوقة. على سبيل المثال ، وضع علامة على القمصان الحمراء بعدد x من صور الأشخاص الذين يرتدون قمصانًا حمراء.
التعلم تحت الإشراف مفيد في مشاكل التصنيف والانحدار. مشاكل التصنيف واضحة إلى حد ما. تحديد ما إذا كان شيء ما جزءًا من مجموعة أم لا.
من الأمثلة السهلة صور Google.
لقد صنفتني جوجل وكذلك المراحل. لم يقوموا بتسمية كل صورة من هذه الصور يدويًا. ولكن سيتم تدريب النموذج على البيانات المصنفة يدويًا للمراحل. وأي شخص استخدم صور Google يعرف أنه يطلب منك تأكيد الصور والأشخاص الموجودين فيها بشكل دوري. نحن الملصقات اليدوية.
هل سبق لك استخدام ReCAPTCHA؟ خمن ماذا تفعل؟ هذا صحيح. أنت تساعد بانتظام في تدريب نماذج التعلم الآلي.
من ناحية أخرى ، تتعامل مشكلات الانحدار مع المشكلات التي توجد فيها مجموعة من المدخلات التي يجب تعيينها إلى قيمة الإخراج.
مثال بسيط هو التفكير في نظام لتقدير سعر بيع منزل مع إدخال قدم مربع ، وعدد غرف النوم ، وعدد الحمامات ، والمسافة من المحيط ، وما إلى ذلك.
هل يمكنك التفكير في أي أنظمة أخرى قد تحمل في مجموعة واسعة من الميزات / الإشارات ثم تحتاج إلى تعيين قيمة للكيان (/ الموقع) المعني؟
في حين أنه بالتأكيد أكثر تعقيدًا ويتضمن مجموعة هائلة من الخوارزميات الفردية التي تخدم وظائف مختلفة ، فمن المحتمل أن يكون الانحدار أحد أنواع الخوارزميات التي تقود الوظائف الأساسية للبحث.
أظن أننا ننتقل إلى نماذج شبه خاضعة للإشراف هنا - مع وضع العلامات اليدوية (أعتقد أن مقيمي الجودة) يتم إجراؤه في بعض المراحل والإشارات التي يجمعها النظام تحدد رضا المستخدمين عن مجموعات النتائج المستخدمة لضبط وصياغة النماذج أثناء اللعب .
تعليم غير مشرف عليه
في التعلم غير الخاضع للإشراف ، يتم إعطاء النظام مجموعة من البيانات غير المسماة ويترك ليحدد بنفسه ما يجب فعله به.
لم يتم تحديد هدف نهائي. قد يقوم النظام بتجميع العناصر المتشابهة معًا ، والبحث عن القيم المتطرفة ، والعثور على علاقة مشتركة ، وما إلى ذلك.
يتم استخدام التعلم غير الخاضع للإشراف عندما يكون لديك الكثير من البيانات ، ولا يمكنك أو لا تعرف مسبقًا كيف يجب استخدامها.
قد تكون أخبار Google خير مثال على ذلك.
تجمع Google قصصًا إخبارية متشابهة وتكشف أيضًا عن قصص إخبارية لم تكن موجودة من قبل (وبالتالي ، فهي أخبار).
من الأفضل أداء هذه المهام بواسطة نماذج غير خاضعة للإشراف بشكل أساسي (وإن لم يكن حصريًا). النماذج التي "شاهدت" مدى نجاح أو فشل التجميع أو الظهور السابق ولكن لم تكن قادرة على تطبيق ذلك بالكامل على البيانات الحالية ، والتي لم يتم تسميتها (كما كانت الأخبار السابقة) واتخاذ القرارات.
إنه مجال مهم للغاية للتعلم الآلي من حيث علاقته بالبحث ، خاصة مع توسع الأشياء.
ترجمة جوجل هي مثال جيد آخر. ليست الترجمة الفردية التي كانت موجودة في السابق ، حيث تم تدريب النظام على فهم أن الكلمة x في اللغة الإنجليزية تساوي الكلمة y باللغة الإسبانية ، ولكن بالأحرى تقنيات أحدث تبحث عن أنماط في استخدام كليهما ، وتحسين الترجمة من خلال شبه - التعلم الخاضع للإشراف (بعض البيانات المصنفة وغير ذلك الكثير) والتعلم غير الخاضع للإشراف ، والترجمة من لغة واحدة إلى لغة غير معروفة تمامًا (للنظام).
لقد رأينا هذا مع MUM أعلاه ، لكنه موجود في أوراق أخرى والنماذج جيدة.
مجرد البداية
نأمل أن يكون هذا قد وفر أساسًا للتعلم الآلي وكيفية استخدامه في البحث.
لن تتناول مقالاتي المستقبلية فقط كيف وأين يمكن العثور على التعلم الآلي (على الرغم من أن البعض سيفعل ذلك). سنغوص أيضًا في التطبيقات العملية للتعلم الآلي التي يمكنك استخدامها لتحسين محركات البحث. لا تقلق ، في هذه الحالات ، سأقوم بالترميز نيابة عنك وأوفر بشكل عام برنامج Google Colab سهل الاستخدام لمتابعة معه ، مما يساعدك في الإجابة على بعض الأسئلة المهمة بشأن تحسين محركات البحث والعمل.
على سبيل المثال ، يمكنك استخدام نماذج التعلم الآلي المباشرة لتطوير فهمك لمواقعك ومحتواك وحركة المرور وغير ذلك. مقالتي القادمة سوف تظهر لك كيف. إعلان تشويقي: توقع السلاسل الزمنية.
الآراء الواردة في هذا المقال هي آراء المؤلف الضيف وليست بالضرورة آراء محرك البحث. يتم سرد المؤلفين الموظفين هنا.