
Um guia para aprendizado de máquina na pesquisa: principais termos, conceitos e algoritmos
Publicados: 2022-05-02Quando se trata de aprendizado de máquina, existem alguns conceitos e termos amplos que todos os pesquisados devem conhecer. Todos devemos saber onde o aprendizado de máquina é usado e os diferentes tipos de aprendizado de máquina que existem.
Continue lendo para entender melhor como o aprendizado de máquina afeta a pesquisa, o que os mecanismos de pesquisa estão fazendo e como reconhecer o aprendizado de máquina no trabalho. Vamos começar com algumas definições. Em seguida, entraremos em algoritmos e modelos de aprendizado de máquina.
Termos de aprendizado de máquina
O que segue são definições de alguns termos importantes de aprendizado de máquina, a maioria dos quais será discutida em algum momento do artigo. Este não pretende ser um glossário abrangente de todos os termos de aprendizado de máquina. Se você quiser isso, o Google oferece uma boa aqui.
- Algoritmo : Um processo matemático executado em dados para produzir uma saída. Existem diferentes tipos de algoritmos para diferentes problemas de aprendizado de máquina.
- Inteligência Artificial (IA) : Um campo da ciência da computação focado em equipar computadores com habilidades ou habilidades que replicam ou são inspiradas pela inteligência humana.
- Corpus : coleção de textos escritos. Geralmente organizado de alguma forma.
- Entidade : Uma coisa ou conceito que é único, singular, bem definido e distinguível. Você pode pensar vagamente nisso como um substantivo, embora seja um pouco mais amplo do que isso. Um tom específico de vermelho seria uma entidade. É único e singular, pois nada mais é exatamente igual a ele, é bem definido (pense em código hexadecimal) e é distinguível, pois você pode distingui-lo de qualquer outra cor.
- Aprendizado de Máquina : Um campo da inteligência artificial, focado na criação de algoritmos, modelos e sistemas para executar tarefas e, geralmente, melhorar a si mesmos na execução dessa tarefa sem serem explicitamente programados.
- Modelo: Um modelo é frequentemente confundido com um algoritmo. A distinção pode ficar embaçada (a menos que você seja um engenheiro de aprendizado de máquina). Essencialmente, a diferença é que onde um algoritmo é simplesmente uma fórmula que produz um valor de saída, um modelo é a representação do que aquele algoritmo produziu após ser treinado para uma tarefa específica. Então, quando dizemos “modelo de BERT” estamos nos referindo ao BERT que foi treinado para uma tarefa específica de PNL (qual tarefa e tamanho de modelo irá ditar qual modelo de BERT específico).
- Processamento de linguagem natural (NLP): Um termo geral para descrever o campo de trabalho no processamento de informações baseadas em linguagem para concluir uma tarefa.
- Rede Neural : Uma arquitetura modelo que, inspirando-se no cérebro, inclui uma camada de entrada (onde os sinais entram – em um ser humano você pode pensar nisso como o sinal enviado ao cérebro quando um objeto é tocado)), uma série de camadas ocultas (fornecendo vários caminhos diferentes, a entrada pode ser ajustada para produzir uma saída) e a camada de saída. Os sinais entram, testam vários “caminhos” diferentes para produzir a camada de saída e são programados para gravitar em direção a condições de saída cada vez melhores. Visualmente pode ser representado por:
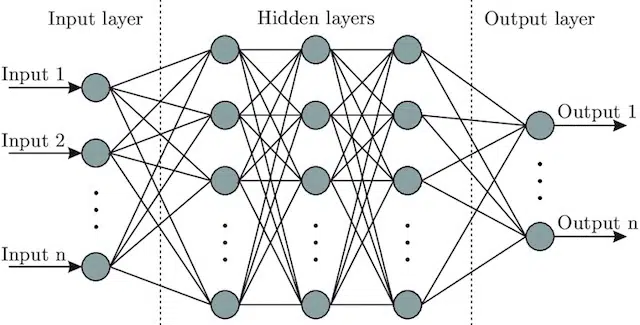
Inteligência artificial versus aprendizado de máquina: qual é a diferença?
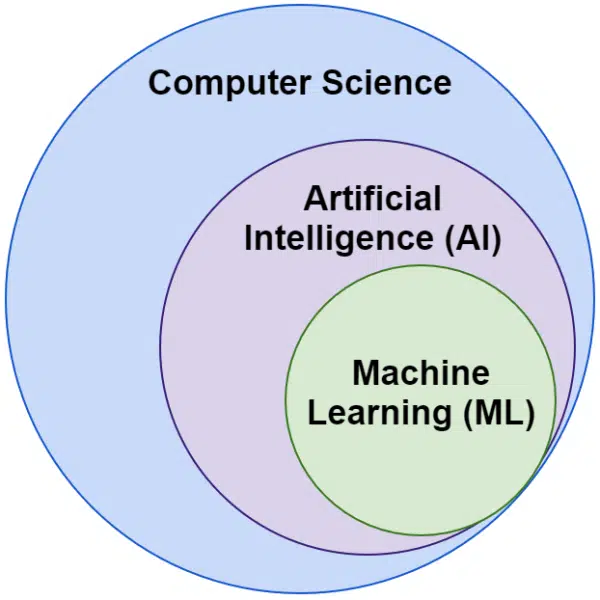
Muitas vezes ouvimos as palavras inteligência artificial e aprendizado de máquina usadas de forma intercambiável. Eles não são exatamente iguais.
A inteligência artificial é o campo de fazer as máquinas imitarem a inteligência, enquanto o aprendizado de máquina é a busca de sistemas que podem aprender sem serem explicitamente programados para uma tarefa.
Visualmente, você pode pensar assim:
Algoritmos relacionados ao aprendizado de máquina do Google
Todos os principais mecanismos de pesquisa usam o aprendizado de máquina de uma ou várias maneiras. Na verdade, a Microsoft está produzindo alguns avanços significativos. Assim são as redes sociais como o Facebook através do Meta AI com modelos como o WebFormer.
Mas nosso foco aqui é SEO. E embora o Bing seja um mecanismo de pesquisa, com uma participação de mercado de 6,61% nos EUA, não vamos nos concentrar nele neste artigo, pois exploramos tecnologias populares e importantes relacionadas à pesquisa.
O Google usa uma infinidade de algoritmos de aprendizado de máquina. Literalmente, não há como você, eu ou provavelmente qualquer engenheiro do Google conhecer todos eles. Além disso, muitos são simplesmente heróis desconhecidos da pesquisa, e não precisamos explorá-los completamente, pois eles simplesmente fazem outros sistemas funcionarem melhor.
Para contextualizar, isso inclui algoritmos e modelos como:
- Google FLAN – que simplesmente acelera e torna menos custosa computacionalmente a transferência de aprendizado de um domínio para outro. Vale a pena notar: no aprendizado de máquina, um domínio não se refere a um site, mas sim à tarefa ou grupos de tarefas que ele realiza, como análise de sentimentos em Processamento de linguagem natural (NLP) ou detecção de objetos em Visão Computacional (CV).
- V-MoE – o único trabalho deste modelo é permitir o treinamento de grandes modelos de visão com menos recursos. São desenvolvimentos como este que permitem o progresso ao expandir o que pode ser feito tecnicamente.
- Sub-Pseudo Labels – este sistema melhora o reconhecimento de ação em vídeo, auxiliando em uma variedade de entendimentos e tarefas relacionadas a vídeo.
Nada disso afeta diretamente a classificação ou os layouts. Mas eles afetam o sucesso do Google.
Então agora vamos olhar para os principais algoritmos e modelos envolvidos com os rankings do Google.
RankBrain
Foi aí que tudo começou, a introdução do aprendizado de máquina nos algoritmos do Google.
Introduzido em 2015, o algoritmo RankBrain foi aplicado a consultas que o Google não tinha visto antes (representando 15% delas). Em junho de 2016, foi expandido para incluir todas as consultas.
Seguindo grandes avanços como o Hummingbird e o Knowledge Graph, o RankBrain ajudou o Google a expandir a visão do mundo como strings (palavras-chave e conjuntos de palavras e caracteres) para coisas (entidades). Por exemplo, antes disso, o Google veria essencialmente a cidade em que moro (Victoria, BC) como duas palavras que ocorrem regularmente, mas também ocorrem regularmente separadamente e podem, mas nem sempre, significam algo diferente quando ocorrem.
Depois do RankBrain, eles viram Victoria, BC como uma entidade – talvez o ID da máquina (/m/07ypt) – e assim, mesmo que atingissem apenas a palavra “Victoria”, se pudessem estabelecer o contexto, eles a tratariam como a mesma entidade que Vitória, BC.
Com isso, eles “vêem” além de meras palavras-chave e significados, apenas nossos cérebros. Afinal, quando você lê “pizza perto de mim” você entende isso em termos de três palavras individuais ou você tem um visual em sua cabeça de pizza e uma compreensão de você no local em que está?
Resumindo, o RankBrain ajuda os algoritmos a aplicar seus sinais a coisas em vez de palavras-chave.
BERT
BERT ( R epresentações de codificador bidirecional de transformadores).
Com a introdução de um modelo BERT nos algoritmos do Google em 2019, o Google mudou da compreensão unidirecional de conceitos para bidirecional.
Esta não foi uma mudança mundana.
O visual que o Google incluiu em seu anúncio de código aberto do modelo BERT em 2018 ajuda a pintar a imagem:
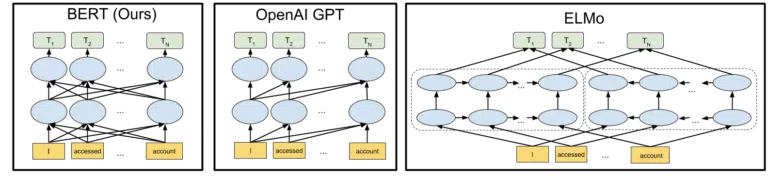
Sem entrar em detalhes sobre como os tokens e os transformadores funcionam no aprendizado de máquina, é suficiente para nossas necessidades aqui simplesmente olhar para as três imagens e as setas e pensar em como na versão BERT, cada uma das palavras ganha informações das de cada lado, incluindo essas várias palavras de distância.
Onde antes um modelo só podia aplicar o insight das palavras em uma direção, agora eles ganham uma compreensão contextual baseada em palavras em ambas as direções.
Um exemplo simples pode ser “o carro é vermelho”.
Só depois do BERT o vermelho passou a ser entendido corretamente como a cor do carro, pois até então a palavra vermelho vinha depois da palavra carro, e essa informação não era enviada de volta.
Além disso, se você quiser jogar com o BERT, vários modelos estão disponíveis no GitHub.
LaMDA
O LaMDA ainda não foi implantado na natureza e foi anunciado pela primeira vez no Google I/O em maio de 2021.
Para esclarecer, quando escrevo “ainda não foi implantado”, quero dizer “até onde sei”. Afinal, descobrimos o RankBrain meses depois que ele foi implantado nos algoritmos. Dito isto, quando for, será revolucionário.
LaMDA é um modelo de linguagem de conversação, que aparentemente esmaga o estado da arte atual.
O foco com o LaMDA é basicamente duplo:
- Melhorar a razoabilidade e especificidade na conversação. Essencialmente, para garantir que uma resposta em um bate-papo seja razoável E específica. Por exemplo, para a maioria das perguntas, a resposta “não sei” é razoável, mas não específica. Por outro lado, uma resposta a uma pergunta como: “Como você está?” isto é, “Eu gosto de sopa de pato em um dia chuvoso. É muito como empinar pipa.” é muito específico, mas dificilmente razoável.
LaMDA ajuda a resolver ambos os problemas. - Quando nos comunicamos, raramente é uma conversa linear. Quando pensamos em onde uma discussão pode começar e onde ela termina, mesmo que seja sobre um único tópico (por exemplo, "Por que nosso tráfego está baixo esta semana?"), geralmente abordamos tópicos diferentes que não teríamos previsto entrar.
Qualquer um que tenha usado um chatbot sabe que eles são péssimos nesses cenários. Eles não se adaptam bem e não carregam bem as informações passadas para o futuro (e vice-versa).
LaMDA aborda ainda mais este problema.
Um exemplo de conversa do Google é:


Podemos vê-lo se adaptando muito melhor do que se esperaria de um chatbot.
Vejo LaMDA sendo implementado no Google Assistant. Mas, se pensarmos bem, recursos aprimorados para entender como um fluxo de consultas funciona em um nível individual certamente ajudariam tanto na adaptação dos layouts de resultados de pesquisa quanto na apresentação de tópicos e consultas adicionais ao usuário.
Basicamente, tenho certeza de que veremos tecnologias inspiradas no LaMDA permeando áreas de pesquisa que não são de bate-papo.
KELM
Acima, quando estávamos discutindo o RankBrain, tocamos em IDs de máquina e entidades. Bem, KELM, que foi anunciado em maio de 2021, leva a um nível totalmente novo.
A KELM nasceu do esforço para reduzir vieses e informações tóxicas na busca. Por ser baseado em informações confiáveis (Wikidata), pode ser bem utilizado para esse fim.
Em vez de ser um modelo, o KELM é mais como um conjunto de dados. Basicamente, são dados de treinamento para modelos de aprendizado de máquina. Mais interessante para nossos propósitos aqui, é que ele nos fala sobre uma abordagem que o Google adota aos dados.
Em poucas palavras, o Google pegou o Wikidata Knowledge Graph em inglês, que é uma coleção de triplos (entidade de assunto, relacionamento, entidade de objeto (carro, cor, vermelho) e o transformou em vários subgráficos de entidade e o verbalizou. Isso é mais facilmente explicado em uma imagem:
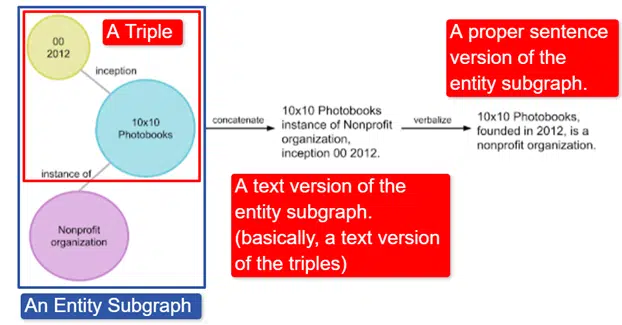
Nesta imagem vemos:
- O triplo descreve um relacionamento individual.
- O subgráfico de entidade mapeando uma pluralidade de triplos relacionados a uma entidade central.
- A versão de texto do subgráfico da entidade.
- A sentença adequada.
Isso pode ser usado por outros modelos para ajudar a treiná-los a reconhecer fatos e filtrar informações tóxicas.
O Google abriu o corpus e está disponível no GitHub. Observar a descrição deles ajudará você a entender como funciona e sua estrutura, caso queira mais informações.
MÃE
O MUM também foi anunciado no Google I/O em maio de 2021.
Embora seja revolucionário, é enganosamente simples de descrever.
MUM significa M ultitask Unified M odel e é multimodal. Isso significa que ele “entende” diferentes formatos de conteúdo como teste, imagens, vídeo, etc. Isso lhe dá o poder de obter informações de várias modalidades, além de responder.
Aparte: Este não é o primeiro uso da arquitetura MultiModel. Foi apresentado pela primeira vez pelo Google em 2017.
Além disso, como o MUM funciona em coisas e não em strings, ele pode coletar informações entre idiomas e fornecer uma resposta no próprio usuário. Isso abre a porta para grandes melhorias no acesso à informação, especialmente para aqueles que falam línguas que não são atendidas na Internet, mas mesmo os falantes de inglês serão beneficiados diretamente.
O exemplo que o Google usa é um alpinista querendo escalar o Monte Fuji. Algumas das melhores dicas e informações podem estar escritas em japonês e completamente indisponíveis para o usuário, pois eles não saberão como mostrá-las, mesmo que possam traduzi-las.
Uma observação importante sobre o MUM é que o modelo não apenas entende o conteúdo, mas pode produzi-lo. Assim, em vez de enviar passivamente um usuário a um resultado, ele pode facilitar a coleta de dados de várias fontes e fornecer o feedback (página, voz etc.) em si.
Este também pode ser um aspecto preocupante desta tecnologia para muitos, inclusive eu.
Onde mais o aprendizado de máquina é usado
Tocamos apenas em alguns dos principais algoritmos dos quais você já ouviu falar e que acredito que estão tendo um impacto significativo na pesquisa orgânica. Mas isso está longe de ser a totalidade de onde o aprendizado de máquina é usado.
Por exemplo, também podemos perguntar:
- Em anúncios, o que impulsiona os sistemas por trás das estratégias de lances automatizados e da automação de anúncios?
- Em Notícias, como o sistema sabe agrupar histórias?
- Em Imagens, como o sistema identifica objetos e tipos de objetos específicos?
- No Email, como o sistema filtra o spam?
- Na Tradução, como o sistema lida com o aprendizado de novas palavras e frases?
- Em Vídeo, como o sistema aprende quais vídeos recomendar a seguir?
Todas essas perguntas e centenas, senão muitos milhares, têm a mesma resposta:
Aprendizado de máquina.
Tipos de algoritmos e modelos de aprendizado de máquina
Agora vamos percorrer dois níveis de supervisão de algoritmos e modelos de aprendizado de máquina – aprendizado supervisionado e não supervisionado. Compreender o tipo de algoritmo que estamos analisando e onde procurá-los é importante.
Aprendizado supervisionado
Simplificando, com o aprendizado supervisionado, o algoritmo recebe dados de treinamento e teste totalmente rotulados.
Ou seja, alguém passou pelo esforço de rotular milhares (ou milhões) de exemplos para treinar um modelo em dados confiáveis. Por exemplo, rotular camisas vermelhas em x número de fotos de pessoas vestindo camisas vermelhas.
O aprendizado supervisionado é útil em problemas de classificação e regressão. Os problemas de classificação são bastante simples. Determinar se algo é ou não parte de um grupo.
Um exemplo fácil é o Google Fotos.
O Google me classificou, assim como os estágios. Eles não rotularam manualmente cada uma dessas fotos. Mas o modelo terá sido treinado em dados rotulados manualmente para estágios. E quem já usou o Google Fotos sabe que eles pedem que você confirme as fotos e as pessoas nelas periodicamente. Nós somos os rotuladores manuais.
Já usou o ReCAPTCHA? Adivinha o que você está fazendo? Isso mesmo. Você ajuda regularmente a treinar modelos de aprendizado de máquina.
Os problemas de regressão, por outro lado, lidam com problemas onde há um conjunto de entradas que precisam ser mapeadas para um valor de saída.
Um exemplo simples é pensar em um sistema para estimar o preço de venda de uma casa com a entrada de metros quadrados, número de quartos, número de banheiros, distância do mar, etc.
Você consegue pensar em algum outro sistema que possa carregar uma ampla variedade de recursos/sinais e, em seguida, precisar atribuir um valor à entidade (/site) em questão?
Embora certamente seja mais complexo e inclua uma enorme variedade de algoritmos individuais que atendem a várias funções, a regressão é provavelmente um dos tipos de algoritmos que impulsiona as principais funções de pesquisa.
Suspeito que estamos migrando para modelos semi-supervisionados aqui - com rotulagem manual (pense em avaliadores de qualidade) sendo feita em alguns estágios e sinais coletados pelo sistema determinando a satisfação dos usuários com os conjuntos de resultados usados para ajustar e criar os modelos em jogo .
Aprendizado não supervisionado
No aprendizado não supervisionado, um sistema recebe um conjunto de dados não rotulados e deixa-se determinar por si mesmo o que fazer com eles.
Nenhum objetivo final é especificado. O sistema pode agrupar itens semelhantes, procurar outliers, encontrar correlações, etc.
O aprendizado não supervisionado é usado quando você tem muitos dados e não pode ou não sabe com antecedência como eles devem ser usados.
Um bom exemplo pode ser o Google Notícias.
O Google agrupa notícias semelhantes e também apresenta notícias que não existiam anteriormente (portanto, são notícias).
Essas tarefas seriam melhor executadas principalmente (embora não exclusivamente) por modelos não supervisionados. Modelos que “viram” quão bem-sucedidos ou malsucedidos o agrupamento ou a superfície anterior foi, mas não são capazes de aplicá-los totalmente aos dados atuais, que não são rotulados (como foi a notícia anterior) e tomar decisões.
É uma área incrivelmente importante de aprendizado de máquina no que se refere à pesquisa, especialmente à medida que as coisas se expandem.
O Google Tradutor é outro bom exemplo. Não a tradução one-to-one que existia, onde o sistema foi treinado para entender que a palavra x em inglês é igual à palavra y em espanhol, mas sim técnicas mais recentes que buscam padrões no uso de ambas, melhorando a tradução por meio de semi -aprendizado supervisionado (alguns dados rotulados e muitos não) e aprendizado não supervisionado, traduzindo de um idioma para um idioma completamente desconhecido (para o sistema).
Vimos isso com o MUM acima, mas existe em outros papéis e os modelos estão bem.
Apenas o começo
Felizmente, isso forneceu uma linha de base para o aprendizado de máquina e como ele é usado na pesquisa.
Meus artigos futuros não serão apenas sobre como e onde o aprendizado de máquina pode ser encontrado (embora alguns o façam). Também vamos mergulhar em aplicações práticas de aprendizado de máquina que você pode usar para ser um SEO melhor. Não se preocupe, nesses casos eu terei feito a codificação para você e geralmente fornecerei um Google Colab fácil de usar para acompanhar, ajudando você a responder a algumas perguntas importantes sobre SEO e negócios.
Por exemplo, você pode usar modelos de aprendizado de máquina diretos para evoluir sua compreensão de seus sites, conteúdo, tráfego e muito mais. Meu próximo artigo mostrará como. Teaser: previsão de séries temporais.
As opiniões expressas neste artigo são do autor convidado e não necessariamente do Search Engine Land. Os autores da equipe estão listados aqui.