
Руководство по машинному обучению в поиске: ключевые термины, концепции и алгоритмы
Опубликовано: 2022-05-02Когда дело доходит до машинного обучения, есть несколько общих понятий и терминов, которые должен знать каждый, кто занимается поиском. Мы все должны знать, где используется машинное обучение, и какие существуют различные типы машинного обучения.
Читайте дальше, чтобы лучше понять, как машинное обучение влияет на поиск, что делают поисковые системы и как распознать машинное обучение в действии. Начнем с нескольких определений. Затем мы перейдем к алгоритмам и моделям машинного обучения.
Термины машинного обучения
Ниже приведены определения некоторых важных терминов машинного обучения, большинство из которых будут обсуждаться в какой-то момент в статье. Это не претендует на то, чтобы быть исчерпывающим глоссарием всех терминов машинного обучения. Если вы хотите этого, Google предлагает хороший здесь.
- Алгоритм : Математический процесс, выполняемый с данными для получения результата. Существуют разные типы алгоритмов для разных задач машинного обучения.
- Искусственный интеллект (ИИ) : область компьютерных наук, направленная на оснащение компьютеров навыками или способностями, которые воспроизводят или вдохновляются человеческим интеллектом.
- Корпус : собрание письменного текста. Обычно как-то организованно.
- Сущность : Вещь или концепция, которая является уникальной, единственной, четко определенной и различимой. Вы можете свободно думать об этом как о существительном, хотя это немного шире. Определенный оттенок красного будет сущностью. Является ли он уникальным и единственным в том смысле, что ничто другое не похоже на него, он хорошо определен (например, шестнадцатеричный код) и его можно отличить от любого другого цвета.
- Машинное обучение : область искусственного интеллекта, ориентированная на создание алгоритмов, моделей и систем для выполнения задач и, как правило, для улучшения выполнения этой задачи без явного программирования.
- Модель: модель часто путают с алгоритмом. Различие может стать размытым (если вы не инженер по машинному обучению). По сути, разница в том, что если алгоритм — это просто формула, которая выдает выходное значение, то модель — это представление того, что этот алгоритм произвел после обучения для конкретной задачи. Итак, когда мы говорим «модель BERT», мы имеем в виду BERT, который был обучен для конкретной задачи NLP (какая задача и размер модели будут определять, какая конкретная модель BERT).
- Обработка естественного языка (NLP): общий термин для описания области работы по обработке языковой информации для выполнения задачи.
- Нейронная сеть : Архитектура модели, вдохновленная мозгом, включает в себя входной слой (где поступают сигналы — у человека вы можете думать об этом как о сигнале, посылаемом в мозг при прикосновении к объекту)), ряд скрытые слои (предоставляющие несколько различных путей, которые можно настроить для получения выходных данных) и выходной слой. Сигналы поступают, проверяют несколько различных «путей» для создания выходного слоя и запрограммированы на стремление к еще лучшим условиям вывода. Визуально это может быть представлено:
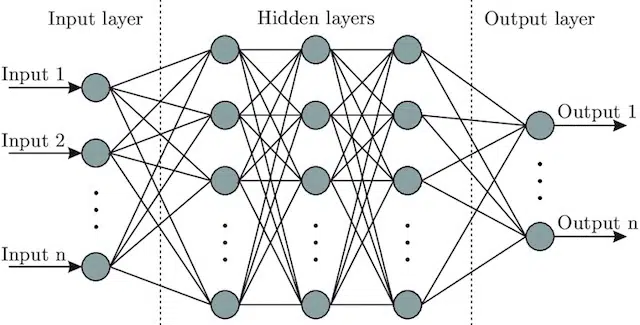
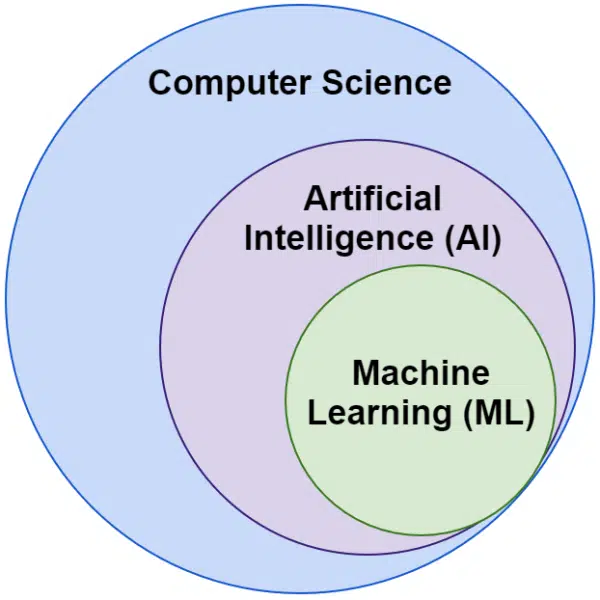
Искусственный интеллект и машинное обучение: в чем разница?
Часто мы слышим, что слова «искусственный интеллект» и «машинное обучение» используются взаимозаменяемо. Они не совсем одинаковы.
Искусственный интеллект — это область, в которой машины имитируют интеллект, тогда как машинное обучение — это поиск систем, которые могут обучаться без явного программирования для выполнения задачи.
Визуально это можно представить так:
Алгоритмы Google, связанные с машинным обучением
Все основные поисковые системы используют машинное обучение одним или несколькими способами. На самом деле, Microsoft делает несколько значительных прорывов. Так же как и социальные сети, такие как Facebook, через мета-ИИ с такими моделями, как WebFormer.
Но наше внимание здесь SEO. И хотя Bing является поисковой системой с долей рынка США 6,61%, мы не будем фокусироваться на ней в этой статье, поскольку будем изучать популярные и важные технологии, связанные с поиском.
Google использует множество алгоритмов машинного обучения. Буквально ни вы, ни я, ни любой инженер Google не могли бы знать их все. Вдобавок ко всему, многие из них просто невоспетые герои поиска, и нам не нужно полностью исследовать их, поскольку они просто улучшают работу других систем.
Для контекста они будут включать алгоритмы и модели, такие как:
- Google FLAN , который просто ускоряет и делает менее затратным в вычислительном отношении перенос обучения из одного домена в другой. Стоит отметить: в машинном обучении домен относится не к веб-сайту, а скорее к задаче или кластерам задач, которые он выполняет, например анализ настроений в обработке естественного языка (NLP) или обнаружение объектов в компьютерном зрении (CV).
- V-MoE — единственная задача этой модели — обеспечить обучение больших моделей зрения с меньшими ресурсами. Именно такие разработки позволяют прогрессировать, расширяя то, что можно сделать технически.
- Sub-Pseudo Labels — эта система улучшает распознавание действий в видео, помогая в различных задачах и задачах, связанных с видео.
Ни один из них напрямую не влияет на ранжирование или макеты. Но они влияют на успех Google.
Итак, теперь давайте рассмотрим основные алгоритмы и модели, связанные с ранжированием в Google.
RankBrain
С этого все и началось, внедрение машинного обучения в алгоритмы Google.
Представленный в 2015 году алгоритм RankBrain применялся к запросам, которые Google раньше не видел (составляя 15% из них). К июню 2016 года он был расширен и теперь включает все запросы.
После огромных достижений, таких как Hummingbird и Knowledge Graph, RankBrain помог Google перейти от представления мира как строк (ключевых слов и наборов слов и символов) к вещам (сущностям). Например, до этого Google по существу рассматривал город, в котором я живу (Виктория, Британская Колумбия), как два слова, которые регулярно встречаются вместе, но также регулярно встречаются по отдельности и могут, но не всегда, означать что-то другое, когда они это делают.
После RankBrain они увидели Викторию, Британская Колумбия, как объект — возможно, идентификатор машины (/m/07ypt) — и поэтому, даже если бы они нажали просто слово «Виктория», если бы они могли установить контекст, они бы рассматривали его как тот же объект, что и Виктория, Британская Колумбия.
При этом они «видят» не только ключевые слова и значение, но и наш мозг. В конце концов, когда вы читаете «пицца рядом со мной», вы понимаете это с точки зрения трех отдельных слов или у вас в голове есть образ пиццы и понимание вас в том месте, где вы находитесь?
Короче говоря, RankBrain помогает алгоритмам применять свои сигналы к вещам, а не к ключевым словам.
БЕРТ
BERT (представления двунаправленного энкодера от трансформаторов ).
С введением модели BERT в алгоритмы Google в 2019 году Google перешел от однонаправленного понимания концепций к двунаправленному.
Это не было мирским изменением.
Изображение, которое Google включила в свое объявление об открытии исходного кода модели BERT в 2018 году, помогает нарисовать картину:
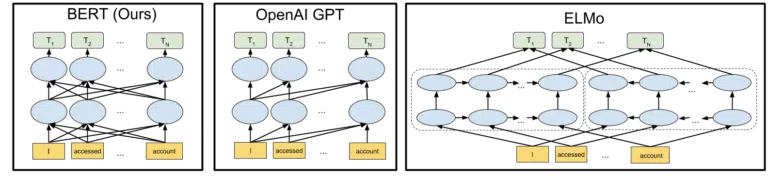
Не вдаваясь в подробности о том, как токены и преобразователи работают в машинном обучении, для наших целей здесь достаточно просто посмотреть на три изображения и стрелки и подумать о том, как в версии BERT каждое из слов получает информацию от слов на любом из них. сторона, в том числе те несколько слов прочь.
Если раньше модель могла применять понимание слов только в одном направлении, то теперь они получают контекстуальное понимание, основанное на словах в обоих направлениях.
Простым примером может быть «машина красная».
Только после того, как BERT под красным правильно понимали цвет автомобиля, потому что до этого слово «красный» шло после слова «автомобиль», и эта информация не отправлялась обратно.
Кроме того, если вы хотите поиграть с BERT, на GitHub доступны различные модели.
ЛаМДА
LaMDA еще не была развернута в реальных условиях и впервые была анонсирована на Google I/O в мае 2021 года.
Чтобы уточнить, когда я пишу «еще не развернуто», я имею в виду «насколько мне известно». В конце концов, мы узнали о RankBrain через несколько месяцев после того, как его внедрили в алгоритмы. Тем не менее, когда это произойдет, это будет революционно.
LaMDA — это модель разговорного языка, которая, казалось бы, превосходит современные достижения.
Фокус с LaMDA в основном двоякий:
- Улучшите разумность и конкретность в разговоре. По сути, чтобы гарантировать, что ответ в чате будет разумным и конкретным. Например, на большинство вопросов ответ «не знаю» разумен, но не конкретен. С другой стороны, ответ на вопрос типа «Как дела?» то есть: «Я люблю утиный суп в дождливый день. Это очень похоже на запуск воздушного змея». очень конкретно, но вряд ли разумно.
LaMDA помогает решить обе проблемы. - Когда мы общаемся, это редко бывает линейным разговором. Когда мы думаем о том, где может начаться обсуждение и где оно закончится, даже если речь идет об одной теме (например, «Почему наш трафик упал на этой неделе?»), мы, как правило, затрагиваем разные темы, которых у нас не было бы. предсказал вход.
Любой, кто использовал чат-ботов, знает, что они ужасны в этих сценариях. Они плохо адаптируются и плохо переносят прошлую информацию в будущее (и наоборот).
LaMDA дополнительно решает эту проблему.
Пример диалога от Google:


Мы видим, что он адаптируется гораздо лучше, чем можно было бы ожидать от чат-бота.
Я вижу, как LaMDA внедряется в Google Assistant. Но если подумать, расширенные возможности понимания того, как работает поток запросов на индивидуальном уровне, безусловно, помогут как в настройке макетов результатов поиска, так и в представлении пользователю дополнительных тем и запросов.
По сути, я почти уверен, что мы увидим, как технологии, вдохновленные LaMDA, проникнут в нечатовые области поиска.
КЕЛЬМ
Выше, когда мы обсуждали RankBrain, мы коснулись идентификаторов машин и сущностей. Что ж, KELM, о котором было объявлено в мае 2021 года, выводит его на совершенно новый уровень.
KELM родился в результате усилий по уменьшению предвзятости и токсичной информации в поиске. Поскольку он основан на надежной информации (Викиданные), его можно хорошо использовать для этой цели.
KELM больше похож не на модель, а на набор данных. По сути, это обучающие данные для моделей машинного обучения. Более интересным для наших целей здесь является то, что он рассказывает нам о подходе Google к данным.
В двух словах, Google взял английскую графу знаний Викиданных, которая представляет собой набор троек (субъект, отношения, объект (автомобиль, цвет, красный)), превратил его в различные подграфы сущностей и вербализовал. Это проще всего объяснить в изображение:
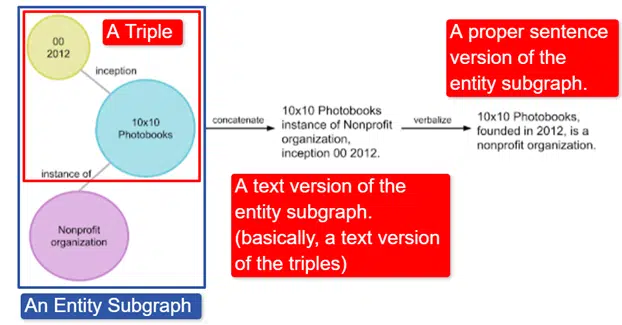
На этом изображении мы видим:
- Тройка описывает индивидуальные отношения.
- Подграф объекта, отображающий множество троек, связанных с центральным объектом.
- Текстовая версия подграфа объекта.
- Правильная фраза.
Затем это может использоваться другими моделями, чтобы научить их распознавать факты и фильтровать токсичную информацию.
Google предоставил корпус с открытым исходным кодом, и он доступен на GitHub. Просмотр их описания поможет вам понять, как он работает и его структуру, если вам нужна дополнительная информация.
МАМА
MUM также был анонсирован на Google I/O в мае 2021 года.
Хотя это революционно, это обманчиво просто описать.
MUM расшифровывается как многозадачная унифицированная модель и является мультимодальной. Это означает, что он «понимает» различные форматы контента, такие как тесты, изображения, видео и т. д. Это дает ему возможность получать информацию из нескольких модальностей, а также реагировать.
В сторону : это не первое использование архитектуры MultiModel. Впервые он был представлен Google в 2017 году.
Кроме того, поскольку MUM функционирует в вещах, а не в строках, он может собирать информацию на разных языках, а затем предоставлять ответ на языке пользователя. Это открывает двери для значительного улучшения доступа к информации, особенно для тех, кто говорит на языках, которые не обслуживаются в Интернете, но даже носители английского языка получат непосредственную выгоду.
Пример, который использует Google, — турист, желающий подняться на гору Фудзи. Некоторые из лучших советов и информации могут быть написаны на японском языке и совершенно недоступны для пользователя, так как они не будут знать, как вывести их на поверхность, даже если смогут перевести.
Важным примечанием к MUM является то, что модель не только понимает контент, но и может его создавать. Таким образом, вместо того, чтобы пассивно отправлять пользователя к результату, он может облегчить сбор данных из нескольких источников и сам обеспечить обратную связь (страница, голос и т. д.).
Это также может быть важным аспектом этой технологии для многих, включая меня.
Где еще используется машинное обучение
Мы коснулись только некоторых ключевых алгоритмов, о которых вы наверняка слышали и которые, как мне кажется, оказывают значительное влияние на органический поиск. Но это далеко не все области применения машинного обучения.
Например, мы также можем спросить:
- Что в рекламе движет системами автоматизированных стратегий назначения ставок и автоматизации рекламы?
- В новостях, как система знает, как группировать истории?
- Как в изображениях система идентифицирует конкретные объекты и типы объектов?
- В электронной почте, как система фильтрует спам?
- В переводе, как система справляется с изучением новых слов и фраз?
- Что касается видео, как система узнает, какие видео рекомендовать дальше?
На все эти вопросы и сотни, если не тысячи других, есть один и тот же ответ:
Машинное обучение.
Типы алгоритмов и моделей машинного обучения
Теперь давайте рассмотрим два уровня контроля алгоритмов и моделей машинного обучения — контролируемое и неконтролируемое обучение. Понимание типа рассматриваемого алгоритма и того, где его искать, важно.
контролируемое обучение
Проще говоря, при обучении с учителем алгоритм получает полностью помеченные обучающие и тестовые данные.
Другими словами, кто-то приложил усилия, чтобы пометить тысячи (или миллионы) примеров, чтобы обучить модель на надежных данных. Например, пометка красных рубашек на x фотографиях людей в красных рубашках.
Обучение с учителем полезно в задачах классификации и регрессии. Проблемы классификации довольно просты. Определение того, является ли что-либо частью группы.
Простой пример — Google Фото.
Google классифицировал меня, а также этапы. Они не маркировали вручную каждое из этих изображений. Но модель будет обучена на вручную размеченных данных для этапов. И любой, кто использовал Google Фото, знает, что они периодически просят вас подтверждать фотографии и людей на них. Мы ручные этикетировщики.
Вы когда-нибудь использовали ReCAPTCHA? Угадай, что ты делаешь? Вот так. Вы регулярно помогаете обучать модели машинного обучения.
Проблемы регрессии, с другой стороны, имеют дело с проблемами, в которых есть набор входных данных, которые необходимо сопоставить с выходным значением.
Простым примером является система оценки продажной цены дома с вводом квадратных футов, количества спален, количества ванных комнат, расстояния от океана и т. д.
Можете ли вы подумать о каких-либо других системах, которые могут содержать широкий спектр функций/сигналов, а затем должны присваивать значение рассматриваемому объекту (/сайту)?
Хотя регрессия, безусловно, является более сложной и включает в себя огромное количество отдельных алгоритмов, выполняющих различные функции, она, вероятно, является одним из типов алгоритмов, управляющих основными функциями поиска.
Я подозреваю, что здесь мы переходим к частично контролируемым моделям — с ручной маркировкой (например, оценщики качества) на некоторых этапах и собираемыми системой сигналами, определяющими удовлетворенность пользователей наборами результатов, которые используются для настройки и создания моделей в игре. .
Неконтролируемое обучение
При неконтролируемом обучении системе предоставляется набор неразмеченных данных, и она сама решает, что с ними делать.
Конечная цель не указана. Система может группировать похожие элементы вместе, искать выбросы, находить взаимосвязь и т. д.
Неконтролируемое обучение используется, когда у вас много данных, и вы не можете или не знаете заранее, как их следует использовать.
Хорошим примером могут быть новости Google.
Google группирует похожие новости, а также показывает новости, которых раньше не было (таким образом, они являются новостями).
Эти задачи лучше всего выполнять в основном (хотя и не исключительно) неконтролируемыми моделями. Модели, которые «видели», насколько успешной или неудачной была предыдущая кластеризация или всплытие, но не могут полностью применить это к текущим данным, которые не размечены (как это было в предыдущих новостях), и принимать решения.
Это невероятно важная область машинного обучения, поскольку она связана с поиском, особенно по мере расширения.
Google Translate — еще один хороший пример. Не однозначный перевод, который существовал раньше, когда система была обучена понимать, что слово x в английском равно слову y в испанском, а скорее новые методы, которые ищут шаблоны в использовании обоих, улучшая перевод с помощью полуперевода. -обучение с учителем (некоторые размеченные данные и многое другое) и обучение без учителя, перевод с одного языка на совершенно неизвестный (системе) язык.
Мы видели это с MUM выше, но это существует и в других статьях, и модели в порядке.
Только начало
Надеюсь, это послужило основой для машинного обучения и его использования в поиске.
Мои будущие статьи будут не только о том, как и где можно найти машинное обучение (хотя некоторые будут). Мы также углубимся в практические применения машинного обучения, которые вы можете использовать, чтобы улучшить SEO. Не волнуйтесь, в этих случаях я сделаю код за вас и, как правило, предоставлю простой в использовании Google Colab, который поможет вам ответить на некоторые важные вопросы SEO и бизнеса.
Например, вы можете использовать модели прямого машинного обучения, чтобы лучше понять свои сайты, контент, трафик и многое другое. Моя следующая статья покажет вам, как это сделать. Тизер: прогнозирование временных рядов.
Мнения, выраженные в этой статье, принадлежат приглашенному автору, а не обязательно поисковой системе. Штатные авторы перечислены здесь.