
Przewodnik po uczeniu maszynowym w wyszukiwaniu: kluczowe terminy, koncepcje i algorytmy
Opublikowany: 2022-05-02Jeśli chodzi o uczenie maszynowe, istnieje kilka ogólnych pojęć i terminów, które każdy użytkownik powinien znać. Wszyscy powinniśmy wiedzieć, gdzie używane jest uczenie maszynowe i jakie istnieją rodzaje uczenia maszynowego.
Czytaj dalej, aby lepiej zrozumieć, jak uczenie maszynowe wpływa na wyszukiwanie, co robią wyszukiwarki i jak rozpoznawać uczenie maszynowe w pracy. Zacznijmy od kilku definicji. Następnie przejdziemy do algorytmów i modeli uczenia maszynowego.
Terminy uczenia maszynowego
Poniżej znajdują się definicje niektórych ważnych terminów uczenia maszynowego, z których większość zostanie omówiona w pewnym momencie artykułu. Nie jest to obszerny słowniczek wszystkich terminów dotyczących uczenia maszynowego. Jeśli chcesz, Google zapewnia tutaj dobry.
- Algorytm : proces matematyczny uruchamiany na danych w celu uzyskania danych wyjściowych. Istnieją różne typy algorytmów dla różnych problemów z uczeniem maszynowym.
- Sztuczna inteligencja (AI) : Dziedzina informatyki skupiająca się na wyposażaniu komputerów w umiejętności lub zdolności, które replikują lub są inspirowane ludzką inteligencją.
- Korpus : zbiór tekstu pisanego. Zwykle w jakiś sposób zorganizowany.
- Jednostka : rzecz lub koncepcja, która jest unikalna, pojedyncza, dobrze zdefiniowana i rozpoznawalna. Możesz swobodnie myśleć o tym jako o rzeczowniku, chociaż jest nieco szerszy. Specyficzny odcień czerwieni byłby bytem. Czy jest wyjątkowy i wyjątkowy, ponieważ nic innego nie jest dokładnie takie, jak to, jest dobrze zdefiniowane (pomyśl o kodzie szesnastkowym) i można go odróżnić od każdego innego koloru.
- Uczenie maszynowe : Dziedzina sztucznej inteligencji, skupiająca się na tworzeniu algorytmów, modeli i systemów do wykonywania zadań i ogólnie poprawy w wykonywaniu tego zadania bez wyraźnego zaprogramowania.
- Model: model jest często mylony z algorytmem. Rozróżnienie może być niewyraźne (chyba że jesteś inżynierem zajmującym się uczeniem maszynowym). Zasadniczo różnica polega na tym, że gdy algorytm jest po prostu formułą, która daje wartość wyjściową, model jest reprezentacją tego, co ten algorytm wytworzył po przeszkoleniu do określonego zadania. Tak więc, kiedy mówimy „model BERT”, mamy na myśli BERT, który został przeszkolony do określonego zadania NLP (które zadanie i rozmiar modelu będą decydować o tym, który konkretny model BERT).
- Przetwarzanie języka naturalnego (NLP): Ogólny termin opisujący dziedzinę pracy związaną z przetwarzaniem informacji językowych w celu wykonania zadania.
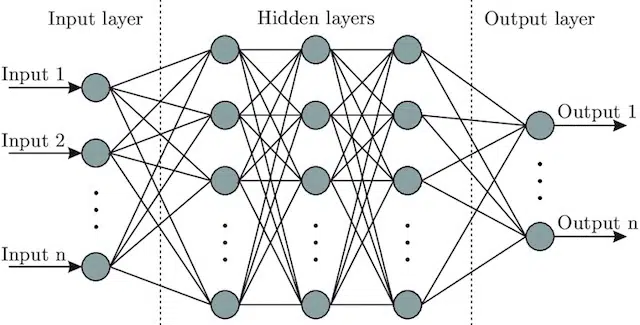
- Sieć neuronowa : architektura modelu, która czerpiąc inspirację z mózgu, zawiera warstwę wejściową (gdzie wchodzą sygnały – u człowieka można to traktować jako sygnał wysyłany do mózgu, gdy obiekt jest dotykany)), szereg warstwy ukryte (zapewniające szereg różnych ścieżek, które można dostosować do danych wejściowych w celu uzyskania danych wyjściowych) oraz warstwę wyjściową. Sygnały wchodzą, testują wiele różnych „ścieżek”, aby wytworzyć warstwę wyjściową, i są zaprogramowane tak, aby zmierzały w kierunku coraz lepszych warunków wyjściowych. Wizualnie można to przedstawić za pomocą:
Sztuczna inteligencja a uczenie maszynowe: jaka jest różnica?
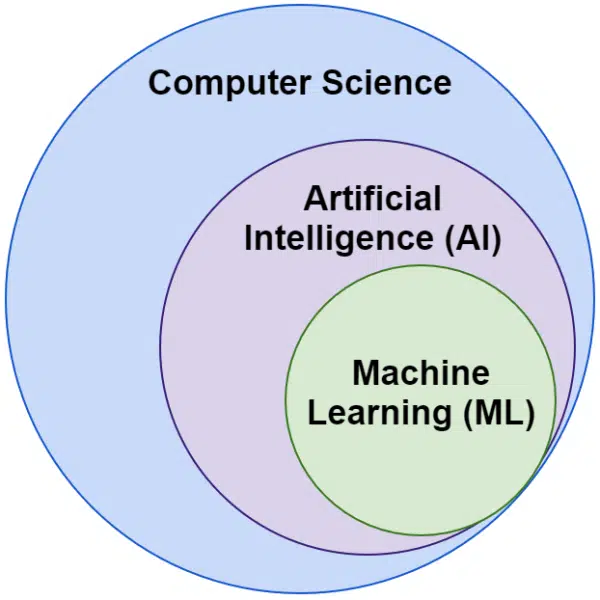
Często słyszymy zamiennie słowa sztuczna inteligencja i uczenie maszynowe. Nie są dokładnie takie same.
Sztuczna inteligencja to dziedzina, w której maszyny naśladują inteligencję, podczas gdy uczenie maszynowe to poszukiwanie systemów, które mogą się uczyć bez wyraźnego zaprogramowania zadania.
Wizualnie możesz o tym pomyśleć tak:
Algorytmy Google związane z uczeniem maszynowym
Wszystkie główne wyszukiwarki wykorzystują uczenie maszynowe na jeden lub wiele sposobów. W rzeczywistości Microsoft dokonuje znaczących przełomów. Podobnie jak sieci społecznościowe, takie jak Facebook, za pośrednictwem Meta AI z modelami takimi jak WebFormer.
Ale skupiamy się tutaj na SEO. I chociaż Bing to wyszukiwarka z 6,61% udziałem w rynku w USA, nie będziemy się na niej koncentrować w tym artykule, ponieważ badamy popularne i ważne technologie związane z wyszukiwaniem.
Google korzysta z wielu algorytmów uczenia maszynowego. Dosłownie nie ma możliwości, aby Ty, ja lub jakikolwiek inżynier Google mógł je wszystkie poznać. Co więcej, wielu z nich to po prostu niedoceniani bohaterowie wyszukiwania i nie musimy ich w pełni odkrywać, ponieważ po prostu poprawiają one działanie innych systemów.
Dla kontekstu obejmowałyby to algorytmy i modele, takie jak:
- Google FLAN – który po prostu przyspiesza i sprawia, że transfer nauki z jednej domeny do drugiej jest mniej kosztowny obliczeniowo. Warto zauważyć: w uczeniu maszynowym domena nie odnosi się do strony internetowej, ale raczej do zadania lub klastrów zadań, które wykonuje, takich jak analiza sentymentu w Przetwarzaniu języka naturalnego (NLP) lub wykrywanie obiektów w Wizji komputerowej (CV).
- V-MoE – jedynym zadaniem tego modelu jest umożliwienie trenowania dużych modeli wizyjnych przy mniejszych zasobach. To takie rozwiązania, które pozwalają na postęp, rozszerzając to, co można zrobić technicznie.
- Sub-Pseudo Labels – ten system poprawia rozpoznawanie akcji w wideo, pomagając w różnych zrozumieniach i zadaniach związanych z wideo.
Żaden z nich nie wpływa bezpośrednio na ranking ani układy. Ale mają wpływ na sukces Google.
Przyjrzyjmy się więc teraz podstawowym algorytmom i modelom związanym z rankingami Google.
RangaBrain
I tu wszystko się zaczęło, czyli wprowadzenie uczenia maszynowego do algorytmów Google.
Wprowadzony w 2015 roku algorytm RankBrain został zastosowany do zapytań, których Google wcześniej nie widział (stanowiło 15% z nich). Do czerwca 2016 została rozszerzona o wszystkie zapytania.
Po ogromnych postępach, takich jak Koliber i Graf wiedzy, RankBrain pomógł Google przejść od postrzegania świata jako ciągów (słów kluczowych oraz zestawów słów i znaków) do rzeczy (jednostek). Na przykład, wcześniej Google zasadniczo postrzegało miasto, w którym mieszkam (Victoria, BC) jako dwa słowa, które regularnie występują razem, ale również regularnie występują osobno i mogą, ale nie zawsze, znaczyć coś innego, kiedy to robią.
Po RankBrain widzieli Victoria, BC jako byt – być może identyfikator maszyny (/m/07ypt) – i nawet jeśli trafią tylko na słowo „Victoria”, gdyby mogli ustalić kontekst, potraktowaliby go jako tę samą jednostkę, co Wiktoria, BC.
Dzięki temu „widzą” poza zwykłymi słowami kluczowymi i znaczeniem, tak jak nasze mózgi. W końcu, kiedy czytasz „pizza blisko mnie”, czy rozumiesz to w kategoriach trzech pojedynczych słów, czy też masz wizualizację w swojej głowie pizzy i rozumiesz siebie w miejscu, w którym się znajdujesz?
Krótko mówiąc, RankBrain pomaga algorytmom zastosować swoje sygnały do rzeczy zamiast słów kluczowych.
BERT
BERT ( dwukierunkowe reprezentacje enkoderów z transformatorów ).
Wraz z wprowadzeniem modelu BERT do algorytmów Google w 2019 roku, Google przeszło z jednokierunkowego rozumienia pojęć na dwukierunkowe.
To nie była przyziemna zmiana.
Wizualizacja Google zawarta w ogłoszeniu otwarcia modelu BERT w 2018 r. pomaga nakreślić obraz:
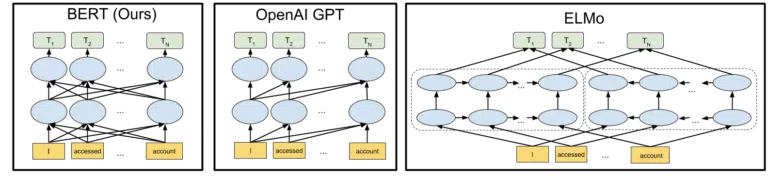
Nie wchodząc w szczegóły, jak działają tokeny i transformatory w uczeniu maszynowym, wystarczy, że przyjrzymy się tutaj trzem obrazom i strzałkom i zastanowimy się, jak w wersji BERT każde ze słów uzyskuje informacje od tych na którymkolwiek z nich. strony, w tym te wiele słów z dala.
Tam, gdzie wcześniej model mógł stosować wgląd ze słów tylko w jednym kierunku, teraz zyskują zrozumienie kontekstowe oparte na słowach w obu kierunkach.
Prostym przykładem może być „samochód jest czerwony”.
Dopiero po tym, jak BERT zrozumiano, że czerwony jest kolorem samochodu, ponieważ do tego czasu słowo czerwony pojawiało się po słowie samochód, a informacja ta nie była odsyłana.
Nawiasem mówiąc, jeśli chcesz pograć z BERT, różne modele są dostępne na GitHub.
LaMDA
LaMDA nie został jeszcze wdrożony na wolności i został po raz pierwszy ogłoszony na Google I/O w maju 2021 roku.
Aby wyjaśnić, kiedy piszę „nie został jeszcze wdrożony”, mam na myśli „według mojej najlepszej wiedzy”. W końcu dowiedzieliśmy się o RankBrain kilka miesięcy po wdrożeniu go do algorytmów. To powiedziawszy, kiedy to będzie rewolucyjne.
LaMDA to model języka konwersacyjnego, który pozornie miażdży obecny stan wiedzy.
Koncentracja na LaMDA jest zasadniczo dwojaka:
- Popraw rozsądek i szczegółowość w rozmowie. Zasadniczo, aby upewnić się, że odpowiedź na czacie jest rozsądna ORAZ konkretna. Na przykład na większość pytań odpowiedź „nie wiem” jest rozsądna, ale nie jest konkretna. Z drugiej strony odpowiedź na pytanie typu „Jak się masz?” czyli „Lubię zupę z kaczki w deszczowy dzień. Przypomina to latanie latawcem”. jest bardzo konkretny, ale mało rozsądny.
LaMDA pomaga rozwiązać oba problemy. - Kiedy się komunikujemy, rzadko jest to rozmowa linearna. Kiedy myślimy o tym, gdzie może się rozpocząć i gdzie może się skończyć dyskusja, nawet jeśli dotyczyła jednego tematu (na przykład „Dlaczego nasz ruch w tym tygodniu jest mniejszy?”), zazwyczaj omawiamy różne tematy, których nie mielibyśmy przewidywane wejście.
Każdy, kto korzystał z chatbota, wie, że w takich sytuacjach jest fatalny. Nie dostosowują się dobrze i nie przenoszą dobrze informacji z przeszłości w przyszłość (i vice versa).
LaMDA dalej zajmuje się tym problemem.
Przykładowa rozmowa z Google to:


Widzimy, jak dostosowuje się znacznie lepiej, niż można by oczekiwać od chatbota.
Widzę implementację LaMDA w Asystencie Google. Ale jeśli się nad tym zastanowimy, ulepszone możliwości zrozumienia, jak działa przepływ zapytań na poziomie indywidualnym, z pewnością pomogłyby zarówno w dostosowaniu układu wyników wyszukiwania, jak i prezentacji dodatkowych tematów i zapytań użytkownikowi.
Zasadniczo jestem pewien, że technologie inspirowane LaMDA przenikają obszary wyszukiwania bez czatu.
KELM
Powyżej, kiedy omawialiśmy RankBrain, dotknęliśmy identyfikatorów maszyn i encji. Cóż, KELM, który został ogłoszony w maju 2021 roku, przenosi go na zupełnie nowy poziom.
KELM narodził się z wysiłków mających na celu zmniejszenie tendencyjności i toksycznych informacji w wyszukiwarce. Ponieważ opiera się na zaufanych informacjach (Wikidata), może być dobrze wykorzystany do tego celu.
Zamiast być modelem, KELM bardziej przypomina zbiór danych. Zasadniczo są to dane szkoleniowe dla modeli uczenia maszynowego. Bardziej interesujące dla naszych celów jest to, że mówi nam o podejściu Google do danych.
W skrócie, Google wziął angielski Wikidata Knowledge Graph, który jest zbiorem trójek (obiekt, związek, obiekt (samochód, kolor, czerwony) i przekształcił go w różne podgrafy encji i zwerbalizował. Najłatwiej to wyjaśnić w obraz:
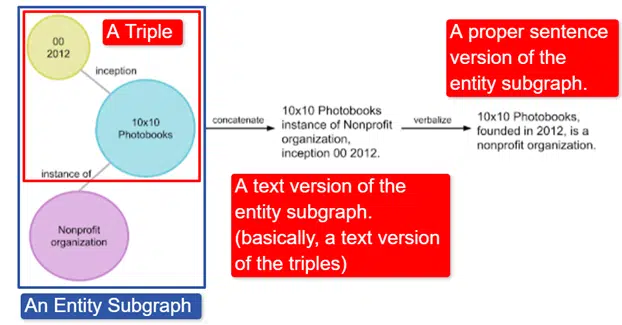
Na tym obrazie widzimy:
- Trójka opisuje indywidualny związek.
- Podgraf encji odwzorowujący wiele trójek związanych z encją centralną.
- Wersja tekstowa podpunktu podmiotu.
- Właściwe zdanie.
Jest to następnie wykorzystywane przez inne modele, aby pomóc im nauczyć się rozpoznawania faktów i filtrowania toksycznych informacji.
Google udostępnił korpus na zasadach open source i jest on dostępny w serwisie GitHub. Jeśli potrzebujesz więcej informacji, zapoznanie się z ich opisem pomoże Ci zrozumieć, jak działa i jaka jest jego struktura.
MILCZĄCY
MUM został również ogłoszony na Google I/O w maju 2021 roku.
Choć jest to rewolucyjne, to zwodniczo proste do opisania.
MUM oznacza M ultitask Unified Model i jest multimodalny. Oznacza to, że „rozumie” różne formaty treści, takie jak test, obrazy, wideo itp. Daje mu to możliwość pozyskiwania informacji z wielu modalności, a także odpowiadania.
Na marginesie: To nie jest pierwsze użycie architektury MultiModel. Po raz pierwszy został zaprezentowany przez Google w 2017 roku.
Dodatkowo, ponieważ MUM działa w rzeczach, a nie w ciągach, może zbierać informacje w różnych językach, a następnie udzielać odpowiedzi we własnym języku. To otwiera drzwi do ogromnej poprawy dostępu do informacji, szczególnie dla tych, którzy mówią w językach, które nie są obsługiwane w Internecie, ale nawet osoby mówiące po angielsku odniosą bezpośrednie korzyści.
Przykładem, którego używa Google, jest turysta chcący wspiąć się na górę Fuji. Niektóre z najlepszych wskazówek i informacji mogą być napisane w języku japońskim i całkowicie niedostępne dla użytkownika, ponieważ nie będzie on wiedział, jak je ujawnić, nawet gdyby mógł je przetłumaczyć.
Ważną informacją na temat MUM jest to, że model nie tylko rozumie treść, ale może ją wyprodukować. Więc zamiast biernie wysyłać użytkownikowi wyniki, może ułatwić zbieranie danych z wielu źródeł i dostarczać informacji zwrotnych (strona, głos itp.).
Dla wielu, w tym dla mnie, może to być niepokojący aspekt tej technologii.
Gdzie jeszcze używane jest uczenie maszynowe
Dotknęliśmy tylko niektórych kluczowych algorytmów, o których słyszałeś i które moim zdaniem mają znaczący wpływ na bezpłatne wyniki wyszukiwania. Jest to jednak dalekie od ogółu zastosowań uczenia maszynowego.
Na przykład możemy również zapytać:
- Co kieruje systemami strategii automatycznego określania stawek i automatyzacji reklam w reklamach?
- W News, skąd system wie, jak grupować historie?
- W obrazach, jak system identyfikuje określone obiekty i typy obiektów?
- Jak system filtruje spam w poczcie e-mail?
- W tłumaczeniu, jak system radzi sobie z nauką nowych słów i zwrotów?
- W wideo, w jaki sposób system dowiaduje się, które filmy polecić jako następne?
Wszystkie te pytania i setki, jeśli nie wiele tysięcy, wszystkie mają tę samą odpowiedź:
Nauczanie maszynowe.
Rodzaje algorytmów i modeli uczenia maszynowego
Przejdźmy teraz przez dwa poziomy nadzoru algorytmów i modeli uczenia maszynowego – uczenie nadzorowane i nienadzorowane. Zrozumienie rodzaju algorytmu, na który patrzymy, i tego, gdzie ich szukać, jest ważne.
Nadzorowana nauka
Mówiąc najprościej, z nadzorowanym uczeniem algorytm otrzymuje w pełni oznaczone dane treningowe i testowe.
Oznacza to, że ktoś wykonał trud oznakowania tysięcy (lub milionów) przykładów, aby wytrenować model na wiarygodnych danych. Na przykład oznaczenie czerwonych koszulek w x liczba zdjęć osób noszących czerwone koszule.
Uczenie nadzorowane jest przydatne w problemach klasyfikacji i regresji. Problemy z klasyfikacją są dość proste. Ustalenie, czy coś jest, czy nie jest częścią grupy.
Prostym przykładem są Zdjęcia Google.
Google sklasyfikował mnie, a także etapy. Nie oznaczyli ręcznie każdego z tych zdjęć. Ale model zostanie przeszkolony na ręcznie oznaczonych danych dla etapów. A każdy, kto używał Zdjęć Google, wie, że okresowo proszą o potwierdzenie zdjęć i osób na nich. Jesteśmy etykieciarkami ręcznymi.
Czy kiedykolwiek używałeś ReCAPTCHA? Zgadnij, co robisz? Zgadza się. Regularnie pomagasz trenować modele uczenia maszynowego.
Z drugiej strony problemy regresji dotyczą problemów, w których istnieje zestaw danych wejściowych, które należy zmapować na wartość wyjściową.
Prostym przykładem jest wymyślenie systemu szacowania ceny sprzedaży domu z uwzględnieniem stóp kwadratowych, liczby sypialni, liczby łazienek, odległości od oceanu itp.
Czy możesz pomyśleć o innych systemach, które mogą przenosić szeroką gamę funkcji/sygnałów, a następnie muszą przypisać wartość do danego podmiotu (/miejsca)?
Chociaż z pewnością bardziej złożony i obejmujący ogromną liczbę indywidualnych algorytmów obsługujących różne funkcje, regresja jest prawdopodobnie jednym z typów algorytmów, które sterują podstawowymi funkcjami wyszukiwania.
Podejrzewam, że przechodzimy tutaj do modeli częściowo nadzorowanych – z ręcznym etykietowaniem (pomyśl o wskaźnikach jakości) wykonywanym na niektórych etapach, a zebrane przez system sygnały określają zadowolenie użytkowników z zestawów wyników używanych do dostosowywania i tworzenia modeli w grze .
Nauka nienadzorowana
W nienadzorowanym uczeniu się system otrzymuje zestaw nieoznakowanych danych i pozostawia się do samodzielnego określenia, co z nim zrobić.
Nie określono celu końcowego. System może grupować podobne elementy, szukać wartości odstających, znajdować korelację itp.
Uczenie nienadzorowane jest stosowane, gdy masz dużo danych i nie możesz lub nie wiesz z góry, jak należy je wykorzystać.
Dobrym przykładem może być Google News.
Google grupuje podobne wiadomości, a także udostępnia wiadomości, które wcześniej nie istniały (a zatem są to wiadomości).
Najlepiej byłoby, gdyby zadania te wykonywały głównie (choć nie wyłącznie) modele nienadzorowane. Modele, które „widziały”, jak udane lub nieudane poprzednie grupowanie lub wynurzanie się zakończyły, ale nie są w stanie w pełni zastosować tego do bieżących danych, które są nieoznaczone (jak w poprzednich wiadomościach) i podejmują decyzje.
Jest to niezwykle ważny obszar uczenia maszynowego, ponieważ odnosi się do wyszukiwania, zwłaszcza gdy rzeczy się rozwijają.
Kolejnym dobrym przykładem jest Tłumacz Google. Nie tłumaczenie jeden-do-jednego, które kiedyś istniało, w którym system został przeszkolony, aby zrozumieć, że słowo x w języku angielskim jest równe słowu y w języku hiszpańskim, ale raczej nowsze techniki, które wyszukują wzorce użycia obu, poprawiając tłumaczenie poprzez pół -uczenie nadzorowane (niektóre oznaczone jako dane i wiele nie) i uczenie bez nadzoru, przekładające się z jednego języka na zupełnie nieznany (systemowi) język.
Widzieliśmy to z MUM powyżej, ale istnieje w innych gazetach i modele są dobre.
Tylko początek
Mamy nadzieję, że zapewniło to podstawę uczenia maszynowego i sposobu jego wykorzystania w wyszukiwarce.
Moje przyszłe artykuły nie będą dotyczyły tylko tego, jak i gdzie można znaleźć uczenie maszynowe (choć niektóre będą). Zagłębimy się również w praktyczne zastosowania uczenia maszynowego, które możesz wykorzystać, aby być lepszym SEO. Nie martw się, w takich przypadkach zrobię kod za Ciebie i ogólnie zapewnię łatwy w użyciu Google Colab do śledzenia, pomagając odpowiedzieć na kilka ważnych pytań dotyczących SEO i biznesu.
Na przykład możesz użyć modeli bezpośredniego uczenia maszynowego, aby lepiej zrozumieć swoje witryny, treści, ruch i nie tylko. Mój następny artykuł pokaże ci jak. Teaser: prognozowanie szeregów czasowych.
Opinie wyrażone w tym artykule są opiniami gościa i niekoniecznie Search Engine Land. Lista autorów personelu znajduje się tutaj.