
Un guide pour l'apprentissage automatique dans la recherche : termes clés, concepts et algorithmes
Publié: 2022-05-02En ce qui concerne l'apprentissage automatique, il existe des concepts et des termes généraux que tout le monde dans la recherche devrait connaître. Nous devrions tous savoir où l'apprentissage automatique est utilisé et les différents types d'apprentissage automatique qui existent.
Lisez la suite pour mieux comprendre l'impact de l'apprentissage automatique sur la recherche, ce que font les moteurs de recherche et comment reconnaître l'apprentissage automatique au travail. Commençons par quelques définitions. Ensuite, nous aborderons les algorithmes et les modèles d'apprentissage automatique.
Termes d'apprentissage automatique
Ce qui suit sont des définitions de certains termes importants d'apprentissage automatique, dont la plupart seront discutés à un moment donné dans l'article. Il ne s'agit pas d'un glossaire complet de chaque terme d'apprentissage automatique. Si vous le souhaitez, Google en fournit un bon ici.
- Algorithme : Un processus mathématique exécuté sur des données pour produire une sortie. Il existe différents types d'algorithmes pour différents problèmes d'apprentissage automatique.
- Intelligence artificielle (IA) : Un domaine de l'informatique axé sur l'équipement des ordinateurs avec des compétences ou des capacités qui reproduisent ou s'inspirent de l'intelligence humaine.
- Corpus : Ensemble de textes écrits. Habituellement organisé d'une manière ou d'une autre.
- Entité : Une chose ou un concept qui est unique, singulier, bien défini et distinctif. Vous pouvez vaguement le considérer comme un nom, bien que ce soit un peu plus large que cela. Une teinte spécifique de rouge serait une entité. Est-il unique et singulier en ce que rien d'autre ne lui ressemble exactement, il est bien défini (pensez au code hexadécimal) et il se distingue en ce sens que vous pouvez le distinguer de toute autre couleur.
- Machine Learning : Un domaine de l'intelligence artificielle, axé sur la création d'algorithmes, de modèles et de systèmes pour effectuer des tâches et généralement pour s'améliorer dans l'exécution de cette tâche sans être explicitement programmé.
- Modèle : Un modèle est souvent confondu avec un algorithme. La distinction peut devenir floue (sauf si vous êtes un ingénieur en apprentissage automatique). Essentiellement, la différence est que là où un algorithme est simplement une formule qui produit une valeur de sortie, un modèle est la représentation de ce que cet algorithme a produit après avoir été formé pour une tâche spécifique. Ainsi, lorsque nous disons «modèle BERT», nous faisons référence au BERT qui a été formé pour une tâche NLP spécifique (quelle tâche et quelle taille de modèle dicteront quel modèle BERT spécifique).
- Traitement du langage naturel (TLN) : Terme général pour décrire le domaine de travail dans le traitement des informations basées sur le langage pour accomplir une tâche.
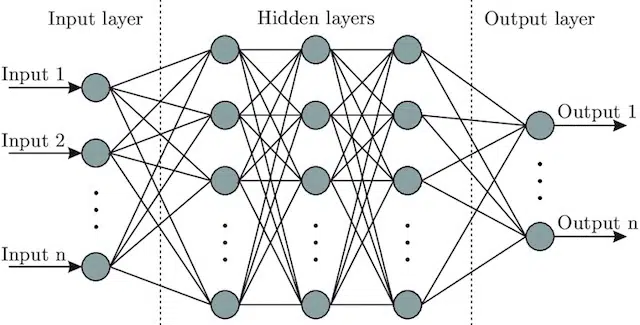
- Réseau de neurones : une architecture modèle qui, s'inspirant du cerveau, comprend une couche d'entrée (où les signaux entrent - chez un humain, vous pourriez le considérer comme le signal envoyé au cerveau lorsqu'un objet est touché)), un certain nombre de couches cachées (fournissant un certain nombre de chemins différents, l'entrée peut être ajustée pour produire une sortie) et la couche de sortie. Les signaux entrent, testent plusieurs «chemins» différents pour produire la couche de sortie et sont programmés pour graviter vers des conditions de sortie toujours meilleures. Visuellement, il peut être représenté par :
Intelligence artificielle vs machine learning : quelle est la différence ?
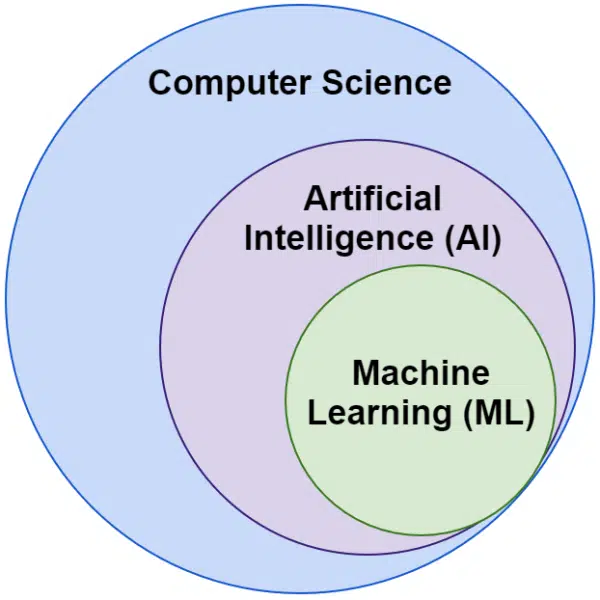
Nous entendons souvent les mots intelligence artificielle et apprentissage automatique utilisés de manière interchangeable. Ils ne sont pas exactement les mêmes.
L'intelligence artificielle consiste à faire en sorte que les machines imitent l'intelligence, tandis que l'apprentissage automatique consiste à rechercher des systèmes capables d'apprendre sans être explicitement programmés pour une tâche.
Visuellement, vous pouvez y penser comme ceci :
Algorithmes liés à l'apprentissage automatique de Google
Tous les principaux moteurs de recherche utilisent l'apprentissage automatique d'une ou de plusieurs façons. En fait, Microsoft produit des percées importantes. Il en va de même pour les réseaux sociaux comme Facebook via Meta AI avec des modèles tels que WebFormer.
Mais notre objectif ici est le référencement. Et bien que Bing soit un moteur de recherche, avec une part de marché de 6,61 % aux États-Unis, nous ne nous concentrerons pas dessus dans cet article car nous explorons les technologies de recherche populaires et importantes.
Google utilise une pléthore d'algorithmes d'apprentissage automatique. Il n'y a littéralement aucun moyen que vous, moi ou probablement un ingénieur Google puisse tous les connaître. En plus de cela, beaucoup sont simplement des héros méconnus de la recherche, et nous n'avons pas besoin de les explorer pleinement car ils améliorent simplement le fonctionnement d'autres systèmes.
Pour le contexte, ceux-ci incluraient des algorithmes et des modèles tels que :
- Google FLAN - qui accélère simplement et rend moins coûteux en calcul le transfert de l'apprentissage d'un domaine à un autre. À noter : dans l'apprentissage automatique, un domaine ne fait pas référence à un site Web, mais plutôt à la tâche ou aux groupes de tâches qu'il accomplit, comme l'analyse des sentiments dans le traitement du langage naturel (NLP) ou la détection d'objets dans la vision par ordinateur (CV).
- V-MoE - le seul travail de ce modèle est de permettre la formation de grands modèles de vision avec moins de ressources. Ce sont des développements comme celui-ci qui permettent de progresser en élargissant ce qui peut être fait techniquement.
- Sous-pseudo étiquettes - ce système améliore la reconnaissance des actions dans la vidéo, aidant à une variété de compréhensions et de tâches liées à la vidéo.
Aucun de ceux-ci n'a d'impact direct sur le classement ou les mises en page. Mais ils ont un impact sur le succès de Google.
Examinons maintenant les algorithmes et modèles de base impliqués dans les classements Google.
RankBrain
C'est là que tout a commencé, l'introduction du machine learning dans les algorithmes de Google.
Introduit en 2015, l'algorithme RankBrain a été appliqué à des requêtes que Google n'avait pas vues auparavant (représentant 15% d'entre elles). En juin 2016, il a été étendu pour inclure toutes les requêtes.
Suite à d'énormes progrès comme Hummingbird et le Knowledge Graph, RankBrain a aidé Google à passer de la vision du monde sous forme de chaînes (mots clés et ensembles de mots et de caractères) à des choses (entités). Par exemple, avant cela, Google considérait essentiellement la ville dans laquelle j'habite (Victoria, Colombie-Britannique) comme deux mots qui coexistent régulièrement, mais aussi se produisent régulièrement séparément et peuvent mais ne signifient pas toujours quelque chose de différent lorsqu'ils le font.
Après RankBrain, ils ont vu Victoria, BC comme une entité - peut-être l'ID de la machine (/m/07ypt) - et donc même s'ils frappaient juste le mot "Victoria", s'ils pouvaient établir le contexte, ils le traiteraient comme la même entité que Victoria, C.-B.
Avec cela, ils "voient" au-delà des simples mots-clés et du sens, seuls nos cerveaux le font. Après tout, lorsque vous lisez « pizza près de chez moi », comprenez-vous cela en termes de trois mots individuels ou avez-vous un visuel dans votre tête de pizza et une compréhension de vous dans l'endroit où vous vous trouvez ?
En bref, RankBrain aide les algorithmes à appliquer leurs signaux à des choses plutôt qu'à des mots-clés.
BERT
BERT (représentations de codeurs bidirectionnels à partir de transformateurs ).
Avec l'introduction d'un modèle BERT dans les algorithmes de Google en 2019, Google est passé d'une compréhension unidirectionnelle des concepts à une compréhension bidirectionnelle.
Ce n'était pas un changement banal.
Le visuel Google inclus dans leur annonce de leur open-sourcing du modèle BERT en 2018 aide à peindre le tableau :
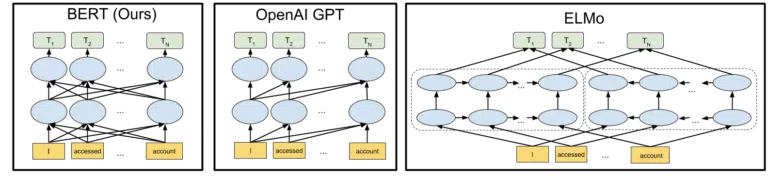
Sans entrer dans les détails du fonctionnement des jetons et des transformateurs dans l'apprentissage automatique, il suffit pour nos besoins ici de simplement regarder les trois images et les flèches et de réfléchir à la façon dont dans la version BERT, chacun des mots obtient des informations à partir de ceux sur l'un ou l'autre côté, y compris ces plusieurs mots de suite.
Alors qu'auparavant, un modèle ne pouvait appliquer la compréhension des mots que dans une seule direction, il acquiert désormais une compréhension contextuelle basée sur les mots dans les deux sens.
Un exemple simple pourrait être "la voiture est rouge".
Ce n'est qu'après que BERT a été correctement compris que le rouge était la couleur de la voiture, car jusque-là, le mot rouge venait après le mot voiture, et cette information n'était pas renvoyée.
En passant, si vous souhaitez jouer avec BERT, différents modèles sont disponibles sur GitHub.
LaMDA
LaMDA n'a pas encore été déployé dans la nature et a été annoncé pour la première fois à Google I/O en mai 2021.
Pour clarifier, quand j'écris "n'a pas encore été déployé", je veux dire "à ma connaissance". Après tout, nous avons découvert RankBrain des mois après son déploiement dans les algorithmes. Cela dit, quand ce sera le cas, ce sera révolutionnaire.
LaMDA est un modèle de langage conversationnel, qui écrase apparemment l'état de l'art actuel.
L'objectif de LaMDA est essentiellement double :
- Améliorer le caractère raisonnable et la spécificité de la conversation. Essentiellement, pour s'assurer qu'une réponse dans un chat est raisonnable ET spécifique. Par exemple, à la plupart des questions, la réponse « Je ne sais pas » est raisonnable, mais elle n'est pas précise. D'un autre côté, une réponse à une question comme "Comment vas-tu?" c'est-à-dire "J'aime la soupe au canard un jour de pluie. C'est un peu comme faire du cerf-volant. est très spécifique mais peu raisonnable.
LaMDA aide à résoudre ces deux problèmes. - Lorsque nous communiquons, il s'agit rarement d'une conversation linéaire. Lorsque nous pensons à l'endroit où une discussion pourrait commencer et où elle se termine, même s'il s'agissait d'un seul sujet (par exemple, « Pourquoi notre trafic est-il en baisse cette semaine ? »), nous aurons généralement couvert différents sujets que nous n'aurions pas prévu d'entrer.
Quiconque a utilisé un chatbot sait qu'il est catastrophique dans ces scénarios. Ils ne s'adaptent pas bien et ne transportent pas bien les informations passées dans le futur (et vice-versa).
LaMDA résout en outre ce problème.
Voici un exemple de conversation de Google :


Nous pouvons le voir s'adapter bien mieux que ce à quoi on pourrait s'attendre d'un chatbot.
Je vois que LaMDA est implémenté dans l'Assistant Google. Mais si nous y réfléchissons, des capacités améliorées pour comprendre le fonctionnement d'un flux de requêtes au niveau individuel aideraient certainement à la fois à personnaliser les mises en page des résultats de recherche et à présenter des sujets et des requêtes supplémentaires à l'utilisateur.
Fondamentalement, je suis à peu près sûr que nous verrons des technologies inspirées de LaMDA imprégner les zones de recherche autres que le chat.
KELM
Ci-dessus, lorsque nous parlions de RankBrain, nous avons abordé les ID de machine et les entités. Eh bien, KELM, qui a été annoncé en mai 2021, le porte à un tout autre niveau.
KELM est né de l'effort visant à réduire les biais et les informations toxiques dans la recherche. Parce qu'il est basé sur des informations fiables (Wikidata), il peut être bien utilisé à cette fin.
Plutôt qu'un modèle, KELM ressemble plus à un ensemble de données. Fondamentalement, il s'agit de données d'entraînement pour les modèles d'apprentissage automatique. Plus intéressant pour nos besoins ici, c'est qu'il nous parle d'une approche que Google adopte en matière de données.
En un mot, Google a pris le Wikidata Knowledge Graph anglais, qui est une collection de triplets (entité sujet, relation, entité objet (voiture, couleur, rouge) et l'a transformé en divers sous-graphes d'entités et l'a verbalisé. Ceci est plus facilement expliqué dans une image:
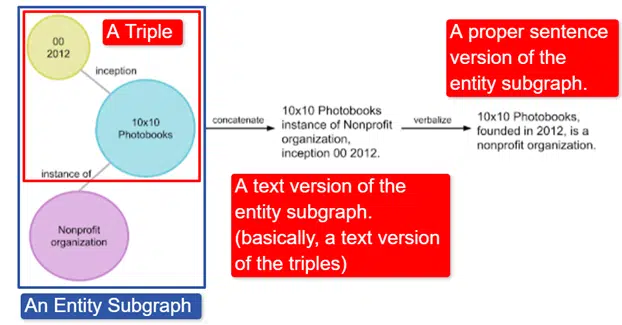
Sur cette image nous voyons :
- Le triple décrit une relation individuelle.
- Le sous-graphe d'entité mappe une pluralité de triplets liés à une entité centrale.
- La version texte du sous-graphe d'entité.
- La phrase appropriée.
Ceci est ensuite utilisable par d'autres modèles pour aider à les former à reconnaître les faits et à filtrer les informations toxiques.
Google a ouvert le corpus et il est disponible sur GitHub. Regarder leur description vous aidera à comprendre comment cela fonctionne et sa structure, si vous souhaitez plus d'informations.
MAMAN
MUM a également été annoncé à Google I/O en mai 2021.
Alors que c'est révolutionnaire, c'est trompeusement simple à décrire.
MUM signifie M ultitask Unified M odel et il est multimodal. Cela signifie qu'il «comprend» différents formats de contenu tels que test, images, vidéo, etc. Cela lui donne le pouvoir d'obtenir des informations à partir de plusieurs modalités, ainsi que de répondre.
A part : Ce n'est pas la première utilisation de l'architecture MultiModel. Il a été présenté pour la première fois par Google en 2017.
De plus, étant donné que MUM fonctionne dans des objets et non dans des chaînes, il peut collecter des informations dans toutes les langues, puis fournir une réponse dans la propre langue de l'utilisateur. Cela ouvre la porte à de vastes améliorations dans l'accès à l'information, en particulier pour ceux qui parlent des langues qui ne sont pas prises en charge sur Internet, mais même les anglophones en bénéficieront directement.
L'exemple utilisé par Google est un randonneur voulant gravir le mont Fuji. Certains des meilleurs conseils et informations peuvent être écrits en japonais et complètement indisponibles pour l'utilisateur car ils ne sauront pas comment les faire apparaître même s'ils peuvent les traduire.
Une note importante sur MUM est que le modèle non seulement comprend le contenu, mais peut le produire. Ainsi, plutôt que d'envoyer passivement un utilisateur vers un résultat, il peut faciliter la collecte de données à partir de plusieurs sources et fournir lui-même le retour (page, voix, etc.).
Cela peut également être un aspect préoccupant de cette technologie pour beaucoup, moi y compris.
Où d'autre l'apprentissage automatique est-il utilisé ?
Nous n'avons abordé que certains des algorithmes clés dont vous avez entendu parler et qui, je pense, ont un impact significatif sur la recherche organique. Mais c'est loin d'être la totalité des endroits où l'apprentissage automatique est utilisé.
Par exemple, on peut aussi demander :
- Dans Ads, qu'est-ce qui motive les systèmes derrière les stratégies d'enchères automatisées et l'automatisation des annonces ?
- Dans News, comment le système sait-il comment regrouper les articles ?
- Dans Images, comment le système identifie-t-il des objets spécifiques et des types d'objets ?
- Dans Email, comment le système filtre-t-il les spams ?
- Dans la traduction, comment le système s'occupe-t-il d'apprendre de nouveaux mots et expressions ?
- Dans Vidéo, comment le système apprend-il quelles vidéos recommander ensuite ?
Toutes ces questions et des centaines sinon plusieurs milliers d'autres ont toutes la même réponse :
Apprentissage automatique.
Types d'algorithmes et de modèles d'apprentissage automatique
Passons maintenant en revue deux niveaux de supervision des algorithmes et des modèles d'apprentissage automatique : l'apprentissage supervisé et non supervisé. Il est important de comprendre le type d'algorithme que nous examinons et où les rechercher.
Enseignement supervisé
En termes simples, avec l'apprentissage supervisé, l'algorithme reçoit des données de formation et de test entièrement étiquetées.
C'est-à-dire que quelqu'un a fait l'effort d'étiqueter des milliers (ou des millions) d'exemples pour former un modèle sur des données fiables. Par exemple, étiqueter des chemises rouges dans x nombre de photos de personnes portant des chemises rouges.
L'apprentissage supervisé est utile dans les problèmes de classification et de régression. Les problèmes de classification sont assez simples. Déterminer si quelque chose fait ou non partie d'un groupe.
Un exemple simple est Google Photos.
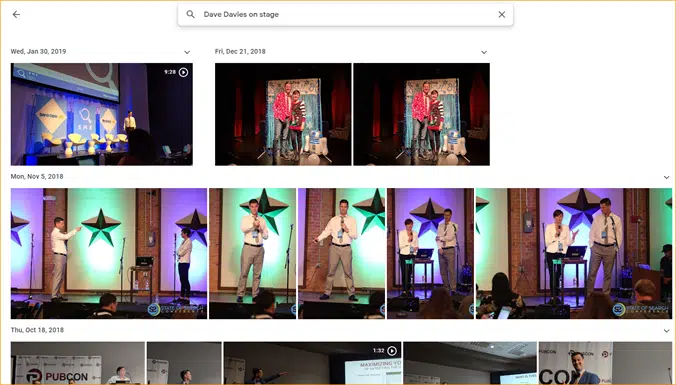
Google m'a classé, ainsi que les étapes. Ils n'ont pas étiqueté manuellement chacune de ces images. Mais le modèle aura été formé sur des données étiquetées manuellement pour les étapes. Et tous ceux qui ont utilisé Google Photos savent qu'ils vous demandent périodiquement de confirmer les photos et les personnes qu'elles contiennent. Nous sommes les étiqueteuses manuelles.
Avez-vous déjà utilisé ReCAPTCHA ? Devine ce que tu fais ? C'est vrai. Vous aidez régulièrement à former des modèles d'apprentissage automatique.
Les problèmes de régression, en revanche, traitent des problèmes où il existe un ensemble d'entrées qui doivent être mappées à une valeur de sortie.
Un exemple simple est de penser à un système d'estimation du prix de vente d'une maison avec l'entrée de pieds carrés, le nombre de chambres, le nombre de salles de bains, la distance de l'océan, etc.
Pouvez-vous penser à d'autres systèmes qui pourraient transporter un large éventail de fonctionnalités/signaux et qui doivent ensuite attribuer une valeur à l'entité (/site) en question ?
Bien que certainement plus complexe et prenant en compte une vaste gamme d'algorithmes individuels remplissant diverses fonctions, la régression est probablement l'un des types d'algorithmes qui pilote les fonctions de base de la recherche.
Je soupçonne que nous passons ici à des modèles semi-supervisés - avec un étiquetage manuel (pensez aux évaluateurs de qualité) effectué à certaines étapes et des signaux collectés par le système déterminant la satisfaction des utilisateurs avec les ensembles de résultats utilisés pour ajuster et élaborer les modèles en jeu .
Apprentissage non supervisé
Dans l'apprentissage non supervisé, un système reçoit un ensemble de données non étiquetées et laisse le soin de déterminer lui-même quoi en faire.
Aucun objectif final n'est spécifié. Le système peut regrouper des éléments similaires, rechercher des valeurs aberrantes, trouver une corrélation, etc.
L'apprentissage non supervisé est utilisé lorsque vous avez beaucoup de données et que vous ne pouvez pas ou ne savez pas à l'avance comment elles doivent être utilisées.
Un bon exemple pourrait être Google Actualités.
Google regroupe des actualités similaires et présente également des actualités qui n'existaient pas auparavant (ce sont donc des actualités).
Ces tâches seraient mieux exécutées par des modèles principalement (mais pas exclusivement) non supervisés. Des modèles qui ont « vu » le succès ou l'échec du regroupement ou du surfaçage précédent, mais qui ne sont pas en mesure de l'appliquer pleinement aux données actuelles, qui ne sont pas étiquetées (comme l'étaient les nouvelles précédentes) et de prendre des décisions.
C'est un domaine extrêmement important de l'apprentissage automatique en ce qui concerne la recherche, en particulier à mesure que les choses se développent.
Google Traduction est un autre bon exemple. Pas la traduction un à un qui existait auparavant, où le système a été formé pour comprendre que le mot x en anglais est égal au mot y en espagnol, mais plutôt des techniques plus récentes qui recherchent des modèles dans l'utilisation des deux, améliorant la traduction par semi -apprentissage supervisé (certaines données étiquetées et beaucoup non) et apprentissage non supervisé, traduisant d'une langue vers une langue complètement inconnue (du système).
On a vu ça avec MUM plus haut, mais ça existe dans d'autres papiers et les modèles sont bien.
Juste le commencement
Espérons que cela a fourni une base de référence pour l'apprentissage automatique et son utilisation dans la recherche.
Mes futurs articles ne porteront pas seulement sur comment et où trouver l'apprentissage automatique (même si certains le feront). Nous plongerons également dans les applications pratiques de l'apprentissage automatique que vous pouvez utiliser pour améliorer votre référencement. Ne vous inquiétez pas, dans ces cas, j'aurai fait le codage pour vous et fournirai généralement un Google Colab facile à utiliser à suivre, vous aidant à répondre à certaines questions importantes sur le référencement et les affaires.
Par exemple, vous pouvez utiliser des modèles d'apprentissage automatique direct pour faire évoluer votre compréhension de vos sites, de votre contenu, de votre trafic, etc. Mon prochain article vous montrera comment. Teaser : prévision de séries chronologiques.
Les opinions exprimées dans cet article sont celles de l'auteur invité et pas nécessairement Search Engine Land. Les auteurs du personnel sont répertoriés ici.