
Panduan pembelajaran mesin dalam penelusuran: Istilah, konsep, dan algoritme utama
Diterbitkan: 2022-05-02Dalam hal pembelajaran mesin, ada beberapa konsep dan istilah umum yang harus diketahui semua orang dalam penelusuran. Kita semua harus tahu di mana pembelajaran mesin digunakan, dan berbagai jenis pembelajaran mesin yang ada.
Baca terus untuk mendapatkan pemahaman yang lebih baik tentang bagaimana pembelajaran mesin memengaruhi penelusuran, apa yang dilakukan mesin telusur, dan cara mengenali pembelajaran mesin di tempat kerja. Mari kita mulai dengan beberapa definisi. Kemudian kita akan masuk ke algoritma dan model pembelajaran mesin.
Istilah pembelajaran mesin
Berikut ini adalah definisi dari beberapa istilah pembelajaran mesin yang penting, yang sebagian besar akan dibahas di beberapa titik dalam artikel. Ini tidak dimaksudkan untuk menjadi glosarium yang komprehensif dari setiap istilah pembelajaran mesin. Jika Anda menginginkannya, Google menyediakan yang bagus di sini.
- Algoritma : Suatu proses matematis yang dijalankan pada data untuk menghasilkan suatu keluaran. Ada berbagai jenis algoritma untuk masalah pembelajaran mesin yang berbeda.
- Artificial Intelligence (AI) : Bidang ilmu komputer yang berfokus pada melengkapi komputer dengan keterampilan atau kemampuan yang meniru atau terinspirasi oleh kecerdasan manusia.
- Corpus : Kumpulan teks tertulis. Biasanya diatur dalam beberapa cara.
- Entity : Suatu hal atau konsep yang unik, tunggal, terdefinisi dengan baik dan dapat dibedakan. Anda dapat dengan bebas menganggapnya sebagai kata benda, meskipun sedikit lebih luas dari itu. Rona merah tertentu akan menjadi entitas. Apakah unik dan tunggal karena tidak ada yang persis seperti itu, itu didefinisikan dengan baik (pikirkan kode hex) dan dapat dibedakan karena Anda dapat membedakannya dari warna lain.
- Pembelajaran Mesin : Bidang kecerdasan buatan, yang berfokus pada pembuatan algoritme, model, dan sistem untuk melakukan tugas dan umumnya meningkatkan diri mereka sendiri dalam melakukan tugas itu tanpa diprogram secara eksplisit.
- Model: Model sering dikacaukan dengan algoritma. Perbedaannya bisa menjadi kabur (kecuali Anda seorang insinyur pembelajaran mesin). Pada dasarnya, perbedaannya adalah di mana algoritma hanyalah formula yang menghasilkan nilai keluaran, model adalah representasi dari apa yang telah dihasilkan oleh algoritma setelah dilatih untuk tugas tertentu. Jadi, ketika kita mengatakan "model BERT" kita mengacu pada BERT yang telah dilatih untuk tugas NLP tertentu (tugas dan ukuran model mana yang akan menentukan model BERT tertentu).
- Natural Language Processing (NLP): Istilah umum untuk menggambarkan bidang kerja dalam memproses informasi berbasis bahasa untuk menyelesaikan suatu tugas.
- Neural Network : Sebuah arsitektur model yang, mengambil inspirasi dari otak, termasuk lapisan input (di mana sinyal masuk – pada manusia Anda mungkin menganggapnya sebagai sinyal yang dikirim ke otak ketika suatu objek disentuh)), sejumlah lapisan tersembunyi (menyediakan sejumlah jalur yang berbeda input dapat disesuaikan untuk menghasilkan output), dan lapisan output. Sinyal masuk, menguji beberapa "jalur" yang berbeda untuk menghasilkan lapisan keluaran, dan diprogram untuk condong ke arah kondisi keluaran yang lebih baik. Secara visual dapat diwakili oleh:
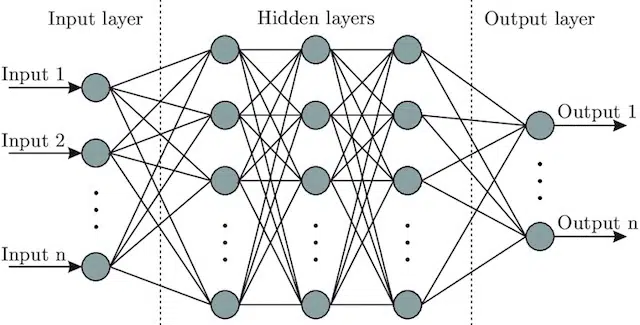
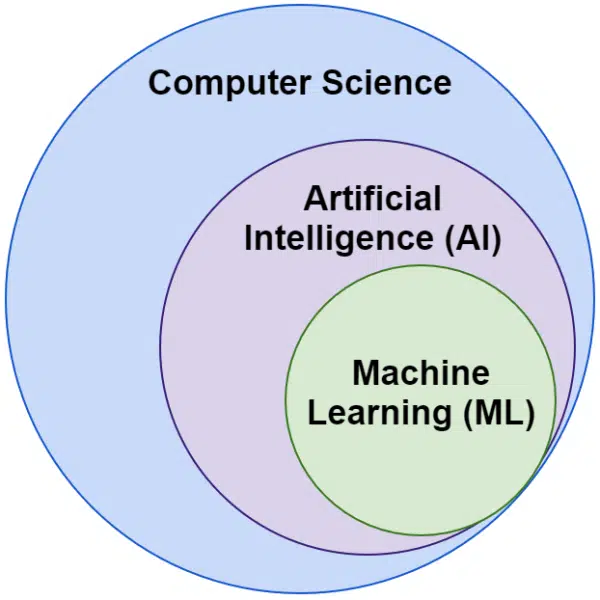
Kecerdasan buatan vs. pembelajaran mesin: Apa bedanya?
Seringkali kita mendengar kata kecerdasan buatan dan pembelajaran mesin digunakan secara bergantian. Mereka tidak persis sama.
Kecerdasan buatan adalah bidang membuat mesin meniru kecerdasan, sedangkan pembelajaran mesin adalah mengejar sistem yang dapat belajar tanpa secara eksplisit diprogram untuk suatu tugas.
Secara visual, Anda dapat memikirkannya seperti ini:
Algoritme terkait pembelajaran mesin Google
Semua mesin pencari utama menggunakan pembelajaran mesin dalam satu atau banyak cara. Bahkan, Microsoft menghasilkan beberapa terobosan signifikan. Begitu juga jejaring sosial seperti Facebook melalui Meta AI dengan model seperti WebFormer.
Tapi fokus kami di sini adalah SEO. Dan sementara Bing adalah mesin pencari, dengan 6,61% pangsa pasar AS, kami tidak akan fokus pada itu dalam artikel ini karena kami menjelajahi teknologi terkait pencarian yang populer dan penting.
Google menggunakan banyak algoritma pembelajaran mesin. Secara harfiah tidak mungkin Anda, saya, atau insinyur Google mana pun dapat mengetahui semuanya. Selain itu, banyak yang hanya pahlawan pencarian tanpa tanda jasa, dan kita tidak perlu menjelajahinya sepenuhnya karena mereka hanya membuat sistem lain bekerja lebih baik.
Untuk konteks, ini akan mencakup algoritme dan model seperti:
- Google FLAN – yang hanya mempercepat, dan membuat transfer pembelajaran dari satu domain ke domain lain menjadi lebih murah secara komputasi. Perlu diperhatikan: Dalam pembelajaran mesin, domain tidak merujuk ke situs web melainkan ke tugas atau kelompok tugas yang diselesaikannya, seperti analisis sentimen di Natural language Processing (NLP) atau deteksi objek di Computer Vision (CV).
- V-MoE – satu-satunya tugas model ini adalah memungkinkan pelatihan model visi besar dengan sumber daya lebih sedikit. Perkembangan seperti inilah yang memungkinkan kemajuan dengan memperluas apa yang bisa dilakukan secara teknis.
- Label Sub-Pseudo – sistem ini meningkatkan pengenalan tindakan dalam video, membantu dalam berbagai pemahaman dan tugas terkait video.
Tak satu pun dari ini berdampak langsung pada peringkat atau tata letak. Tetapi mereka memengaruhi seberapa sukses Google.
Jadi sekarang mari kita lihat algoritma inti dan model yang terlibat dengan peringkat Google.
RankBrain
Di sinilah semuanya dimulai, pengenalan pembelajaran mesin ke dalam algoritme Google.
Diperkenalkan pada tahun 2015, algoritme RankBrain diterapkan pada kueri yang belum pernah dilihat Google sebelumnya (menyumbang 15% dari kueri tersebut). Pada Juni 2016 diperluas untuk mencakup semua kueri.
Mengikuti kemajuan besar seperti Hummingbird dan Grafik Pengetahuan, RankBrain membantu Google berkembang dari melihat dunia sebagai string (kata kunci dan kumpulan kata dan karakter) menjadi sesuatu (entitas). Misalnya, sebelum ini Google pada dasarnya akan melihat kota tempat saya tinggal (Victoria, BC) sebagai dua kata yang sering muncul bersamaan, tetapi juga sering muncul secara terpisah dan dapat tetapi tidak selalu berarti sesuatu yang berbeda ketika itu terjadi.
Setelah RankBrain mereka melihat Victoria, BC sebagai suatu entitas – mungkin ID mesin (/m/07ypt) – dan bahkan jika mereka hanya menekan kata “Victoria,” jika mereka dapat menetapkan konteksnya, mereka akan memperlakukannya sebagai entitas yang sama dengan Victoria, SM.
Dengan ini mereka "melihat" lebih dari sekadar kata kunci dan makna, hanya otak kita yang melakukannya. Lagi pula, ketika Anda membaca "pizza di dekat saya" apakah Anda memahami bahwa dalam hal tiga kata individu atau apakah Anda memiliki visual di kepala Anda tentang pizza, dan pemahaman tentang Anda di lokasi Anda berada?
Singkatnya, RankBrain membantu algoritme menerapkan sinyalnya ke berbagai hal alih-alih kata kunci.
BERT
BERT (Representasi E ncoder B idirectional dari T ransformers).
Dengan diperkenalkannya model BERT ke dalam algoritme Google pada tahun 2019, Google beralih dari pemahaman konsep satu arah, menjadi dua arah.
Ini bukan perubahan biasa.
Visual yang disertakan Google dalam pengumuman sumber terbuka model BERT mereka pada tahun 2018 membantu melukiskan gambarannya:
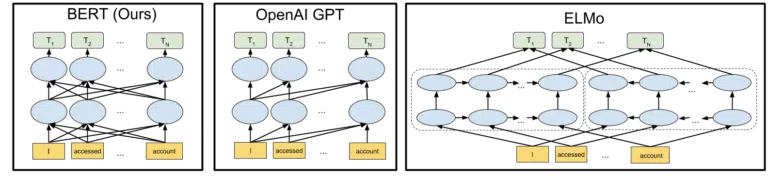
Tanpa merinci bagaimana token dan transformer bekerja dalam pembelajaran mesin, cukup untuk kebutuhan kita di sini untuk hanya melihat tiga gambar dan panah dan berpikir tentang bagaimana dalam versi BERT, masing-masing kata memperoleh informasi dari yang di kedua samping, termasuk beberapa kata itu.
Dimana sebelumnya seorang model hanya bisa menerapkan wawasan dari kata-kata dalam satu arah, sekarang mereka mendapatkan pemahaman kontekstual berdasarkan kata-kata di kedua arah.
Contoh sederhana mungkin "mobilnya merah".
Hanya setelah BERT merah dipahami dengan benar sebagai warna mobil, karena sampai saat itu kata merah muncul setelah kata mobil, dan informasi itu tidak dikirim kembali.
Selain itu, jika Anda ingin bermain dengan BERT, berbagai model tersedia di GitHub.
LaMDA
LaMDA belum diterapkan di alam liar, dan pertama kali diumumkan di Google I/O pada Mei 2021.
Untuk memperjelas, ketika saya menulis "belum dikerahkan" yang saya maksud adalah "sepengetahuan saya." Lagi pula, kami mengetahui tentang RankBrain beberapa bulan setelah diterapkan ke dalam algoritme. Yang mengatakan, ketika itu akan menjadi revolusioner.
LaMDA adalah model bahasa percakapan, yang tampaknya menghancurkan state-of-the-art saat ini.
Fokus dengan LaMDA pada dasarnya ada dua:
- Tingkatkan kewajaran dan kekhususan dalam percakapan. Intinya, untuk memastikan bahwa respons dalam obrolan masuk akal DAN spesifik. Misalnya, untuk sebagian besar pertanyaan, jawaban “Saya tidak tahu” masuk akal tetapi tidak spesifik. Di sisi lain, jawaban atas pertanyaan seperti, "Bagaimana kabarmu?" yaitu, “Saya suka sup bebek di hari hujan. Ini sangat mirip dengan layang-layang yang terbang.” sangat spesifik tetapi hampir tidak masuk akal.
LaMDA membantu mengatasi kedua masalah tersebut. - Ketika kita berkomunikasi, jarang terjadi percakapan linier. Ketika kita memikirkan di mana diskusi akan dimulai dan berakhir, bahkan jika itu tentang satu topik (misalnya, "Mengapa lalu lintas kita turun minggu ini?"), kita biasanya akan membahas berbagai topik yang tidak akan kita bahas. diprediksi masuk.
Siapa pun yang telah menggunakan chatbot tahu bahwa mereka sangat buruk dalam skenario ini. Mereka tidak beradaptasi dengan baik, dan mereka tidak membawa informasi masa lalu ke masa depan dengan baik (dan sebaliknya).
LaMDA lebih lanjut mengatasi masalah ini.
Contoh percakapan dari Google adalah:


Kita bisa melihatnya beradaptasi jauh lebih baik daripada yang diharapkan dari chatbot.
Saya melihat LaMDA diimplementasikan di Asisten Google. Tetapi jika kita memikirkannya, peningkatan kemampuan dalam memahami bagaimana alur kueri bekerja pada tingkat individu tentu akan membantu dalam menyesuaikan tata letak hasil pencarian, dan penyajian topik dan kueri tambahan kepada pengguna.
Pada dasarnya, saya cukup yakin kita akan melihat teknologi yang terinspirasi oleh LaMDA menembus area pencarian non-obrolan.
KELM
Di atas, ketika kami membahas RankBrain, kami menyentuh ID dan entitas mesin. Nah, KELM, yang diumumkan pada Mei 2021, membawanya ke level yang sama sekali baru.
KELM lahir dari upaya untuk mengurangi bias dan toxic information dalam pencarian. Karena didasarkan pada informasi tepercaya (Wikidata), maka dapat digunakan dengan baik untuk tujuan ini.
Daripada menjadi model, KELM lebih seperti kumpulan data. Pada dasarnya, ini adalah data pelatihan untuk model pembelajaran mesin. Yang lebih menarik untuk tujuan kami di sini, adalah bahwa ini memberi tahu kami tentang pendekatan yang dilakukan Google terhadap data.
Singkatnya, Google mengambil Grafik Pengetahuan Wikidata Bahasa Inggris, yang merupakan kumpulan tiga kali lipat (entitas subjek, hubungan, entitas objek (mobil, warna, merah) dan mengubahnya menjadi berbagai subgraf entitas dan memverbalkannya. Ini paling mudah dijelaskan di sebuah gambar:
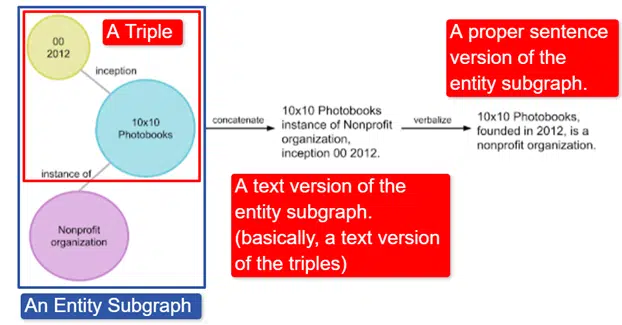
Dalam gambar ini kita melihat:
- Triple menggambarkan hubungan individu.
- Subgraf entitas memetakan pluralitas rangkap tiga yang terkait dengan entitas pusat.
- Versi teks dari subgraf entitas.
- Kalimat yang tepat.
Ini kemudian dapat digunakan oleh model lain untuk membantu melatih mereka mengenali fakta dan menyaring informasi beracun.
Google memiliki korpus open-source, dan tersedia di GitHub. Melihat deskripsi mereka akan membantu Anda memahami cara kerjanya dan strukturnya, jika Anda menginginkan informasi lebih lanjut.
BUNGKAM
MUM juga diumumkan di Google I/O pada Mei 2021.
Meskipun revolusioner, itu tampak sederhana untuk dijelaskan.
MUM adalah singkatan dari M ultitask Unified Model dan multimodal. Ini berarti "memahami" format konten yang berbeda seperti tes, gambar, video, dll. Ini memberinya kekuatan untuk mendapatkan informasi dari berbagai modalitas, serta merespons.
Selain: Ini bukan penggunaan pertama dari arsitektur MultiModel. Ini pertama kali disajikan oleh Google pada tahun 2017.
Selain itu, karena MUM berfungsi dalam berbagai hal dan bukan string, MUM dapat mengumpulkan informasi lintas bahasa dan kemudian memberikan jawaban dalam bahasa pengguna sendiri. Ini membuka pintu untuk perbaikan besar dalam akses informasi, terutama bagi mereka yang berbicara bahasa yang tidak tersedia di Internet, tetapi bahkan penutur bahasa Inggris akan mendapat manfaat secara langsung.
Contoh yang digunakan Google adalah seorang pejalan kaki yang ingin mendaki Gunung Fuji. Beberapa tip dan informasi terbaik mungkin ditulis dalam bahasa Jepang dan sama sekali tidak tersedia bagi pengguna karena mereka tidak akan tahu bagaimana menampilkannya bahkan jika mereka dapat menerjemahkannya.
Catatan penting tentang MUM adalah model tidak hanya memahami konten, tetapi juga dapat memproduksinya. Jadi, daripada secara pasif mengirim pengguna ke suatu hasil, ini dapat memfasilitasi pengumpulan data dari berbagai sumber dan memberikan umpan balik (halaman, suara, dll.) itu sendiri.
Ini mungkin juga menjadi aspek yang mengkhawatirkan dari teknologi ini bagi banyak orang, termasuk saya sendiri.
Di mana lagi pembelajaran mesin digunakan?
Kami hanya menyentuh beberapa algoritme utama yang pernah Anda dengar dan saya yakin memiliki dampak signifikan pada penelusuran organik. Tapi ini jauh dari totalitas di mana pembelajaran mesin digunakan.
Misalnya, kita juga bisa bertanya:
- Di Iklan, apa yang mendorong sistem di balik strategi penawaran otomatis dan otomatisasi iklan?
- Di Berita, bagaimana sistem mengetahui cara mengelompokkan cerita?
- Dalam Gambar, bagaimana sistem mengidentifikasi objek dan jenis objek tertentu?
- Di Email, bagaimana sistem memfilter spam?
- Dalam Terjemahan, bagaimana sistem menangani mempelajari kata dan frasa baru?
- Dalam Video, bagaimana sistem mempelajari video mana yang akan direkomendasikan selanjutnya?
Semua pertanyaan ini dan ratusan bahkan ribuan lainnya memiliki jawaban yang sama:
Pembelajaran mesin.
Jenis algoritma dan model pembelajaran mesin
Sekarang mari kita telusuri dua tingkat pengawasan algoritme dan model pembelajaran mesin – pembelajaran terawasi dan tanpa pengawasan. Memahami jenis algoritme yang kita lihat, dan di mana mencarinya, adalah penting.
Pembelajaran yang diawasi
Sederhananya, dengan pembelajaran yang diawasi, algoritme diberikan pelatihan dan data uji yang sepenuhnya diberi label.
Artinya, seseorang telah melalui upaya pelabelan ribuan (atau jutaan) contoh untuk melatih model pada data yang dapat diandalkan. Misalnya, memberi label baju merah dalam x jumlah foto orang yang memakai baju merah.
Pembelajaran terawasi berguna dalam masalah klasifikasi dan regresi. Masalah klasifikasi cukup mudah. Menentukan apakah sesuatu merupakan bagian dari suatu kelompok atau bukan.
Contoh mudahnya adalah Google Foto.
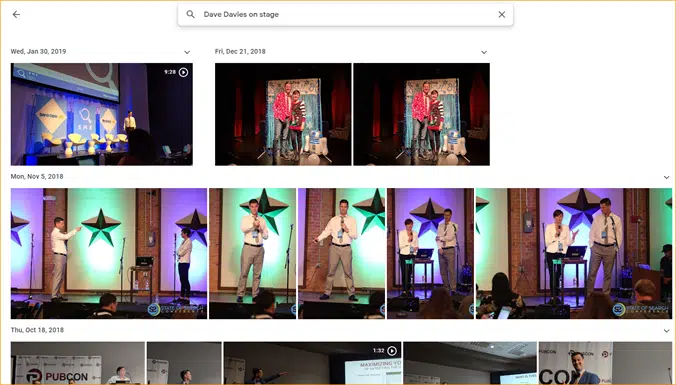
Google telah mengklasifikasikan saya, serta tahapan. Mereka belum secara manual memberi label masing-masing gambar ini. Tetapi model akan dilatih pada data berlabel manual untuk tahapan. Dan siapa pun yang telah menggunakan Google Foto tahu bahwa mereka meminta Anda untuk mengonfirmasi foto dan orang-orang di dalamnya secara berkala. Kami adalah pelabel manual.
Pernah menggunakan ReCAPTCHA? Tebak apa yang kamu lakukan? Betul sekali. Anda secara teratur membantu melatih model machine learning.
Masalah regresi, di sisi lain, menangani masalah di mana ada satu set input yang perlu dipetakan ke nilai output.
Contoh sederhananya adalah memikirkan suatu sistem untuk memperkirakan harga jual rumah dengan input meter persegi, jumlah kamar tidur, jumlah kamar mandi, jarak dari laut, dll.
Bisakah Anda memikirkan sistem lain yang mungkin membawa beragam fitur/sinyal dan kemudian perlu menetapkan nilai ke entitas (/ situs) yang dimaksud?
Meskipun tentu saja lebih kompleks dan mengambil sejumlah besar algoritme individual yang melayani berbagai fungsi, regresi kemungkinan merupakan salah satu jenis algoritme yang mendorong fungsi inti pencarian.
Saya menduga kami pindah ke model semi-diawasi di sini – dengan pelabelan manual (penilai kualitas pikir) dilakukan pada beberapa tahap dan sinyal yang dikumpulkan sistem menentukan kepuasan pengguna dengan rangkaian hasil yang digunakan untuk menyesuaikan dan menyusun model yang dimainkan .
Pembelajaran tanpa pengawasan
Dalam pembelajaran tanpa pengawasan, sebuah sistem diberikan satu set data yang tidak berlabel dan dibiarkan menentukan sendiri apa yang harus dilakukan dengannya.
Tidak ada tujuan akhir yang ditentukan. Sistem dapat mengelompokkan item yang serupa, mencari outlier, menemukan korelasi, dll.
Pembelajaran tanpa pengawasan digunakan ketika Anda memiliki banyak data, dan Anda tidak dapat atau tidak tahu sebelumnya bagaimana seharusnya digunakan.
Contoh yang bagus mungkin adalah Google News.
Google mengelompokkan berita serupa dan juga memunculkan berita yang sebelumnya tidak ada (dengan demikian, mereka adalah berita).
Tugas-tugas ini paling baik dilakukan oleh sebagian besar (meskipun tidak secara eksklusif) model tanpa pengawasan. Model yang telah "melihat" seberapa sukses atau tidak berhasilnya pengelompokan atau pemunculan sebelumnya tetapi tidak dapat sepenuhnya menerapkannya pada data saat ini, yang tidak berlabel (seperti berita sebelumnya) dan membuat keputusan.
Ini adalah area pembelajaran mesin yang sangat penting karena berkaitan dengan pencarian, terutama saat banyak hal berkembang.
Google Terjemahan adalah contoh bagus lainnya. Bukan terjemahan satu-ke-satu yang dulu ada, di mana sistem dilatih untuk memahami bahwa kata x dalam bahasa Inggris sama dengan kata y dalam bahasa Spanyol, melainkan teknik yang lebih baru yang mencari pola penggunaan keduanya, meningkatkan terjemahan melalui semi -pembelajaran yang diawasi (beberapa data berlabel dan banyak yang tidak) dan pembelajaran tanpa pengawasan, menerjemahkan dari satu bahasa ke bahasa yang sama sekali tidak dikenal (untuk sistem).
Kami melihat ini dengan MUM di atas, tetapi ada di kertas dan model lain dengan baik.
Hanya awal
Mudah-mudahan, ini telah memberikan dasar untuk pembelajaran mesin dan bagaimana itu digunakan dalam pencarian.
Artikel masa depan saya tidak hanya tentang bagaimana dan di mana pembelajaran mesin dapat ditemukan (meskipun beberapa akan). Kami juga akan mempelajari aplikasi praktis pembelajaran mesin yang dapat Anda gunakan untuk menjadi SEO yang lebih baik. Jangan khawatir, dalam kasus tersebut saya akan melakukan pengkodean untuk Anda dan umumnya menyediakan Google Colab yang mudah digunakan untuk diikuti, membantu Anda menjawab beberapa pertanyaan penting tentang SEO dan bisnis.
Misalnya, Anda dapat menggunakan model pembelajaran mesin langsung untuk mengembangkan pemahaman Anda tentang situs, konten, lalu lintas, dan lainnya. Artikel saya berikutnya akan menunjukkan caranya. Teaser: peramalan deret waktu.
Pendapat yang diungkapkan dalam artikel ini adalah dari penulis tamu dan belum tentu Search Engine Land. Penulis staf tercantum di sini.