
Aramada makine öğrenimi kılavuzu: Anahtar terimler, kavramlar ve algoritmalar
Yayınlanan: 2022-05-02Makine öğrenimi söz konusu olduğunda, arama yapan herkesin bilmesi gereken bazı genel kavramlar ve terimler vardır. Hepimiz makine öğreniminin nerede kullanıldığını ve var olan farklı makine öğrenimi türlerini bilmeliyiz.
Makine öğreniminin aramayı nasıl etkilediğini, arama motorlarının ne yaptığını ve iş yerinde makine öğrenimini nasıl tanıyacağınızı daha iyi anlamak için okumaya devam edin. Birkaç tanımla başlayalım. Ardından makine öğrenimi algoritmalarına ve modellerine gireceğiz.
Makine öğrenimi terimleri
Aşağıda, çoğu makalenin bir noktasında tartışılacak olan bazı önemli makine öğrenimi terimlerinin tanımları yer almaktadır. Bu, her makine öğrenimi teriminin kapsamlı bir sözlüğü olmayı amaçlamamaktadır. Bunu istiyorsanız, Google burada iyi bir tane sağlar.
- Algoritma : Bir çıktı üretmek için veriler üzerinde yürütülen matematiksel bir süreç. Farklı makine öğrenimi problemleri için farklı algoritma türleri vardır.
- Yapay Zeka (AI) : Bilgisayarları, insan zekasını taklit eden veya ondan ilham alan beceri veya yeteneklerle donatmaya odaklanan bir bilgisayar bilimi alanı.
- Corpus : Yazılı metin topluluğu. Genellikle bir şekilde organize edilir.
- Varlık : Benzersiz, tekil, iyi tanımlanmış ve ayırt edilebilir bir şey veya kavram. Bundan biraz daha geniş olmasına rağmen, gevşek bir şekilde bir isim olarak düşünebilirsiniz. Belirli bir kırmızı tonu bir varlık olacaktır. Başka hiçbir şeyin tam olarak ona benzememesi, iyi tanımlanmış (hex kodunu düşünün) ve onu diğer herhangi bir renkten ayırt edebilmeniz açısından ayırt edilebilir olması bakımından benzersiz ve tekil midir?
- Makine Öğrenimi : Görevleri gerçekleştirmek için algoritmalar, modeller ve sistemler oluşturmaya ve genel olarak açıkça programlanmadan bu görevi yerine getirirken kendilerini geliştirmeye odaklanan bir yapay zeka alanı.
- Model: Bir model genellikle bir algoritma ile karıştırılır. Ayrım bulanıklaşabilir (bir makine öğrenimi mühendisi değilseniz). Esasen fark, bir algoritmanın yalnızca bir çıktı değeri üreten bir formül olduğu yerde, bir modelin, belirli bir görev için eğitildikten sonra o algoritmanın ürettiği şeyin temsilidir. Dolayısıyla, “BERT modeli” dediğimizde, belirli bir NLP görevi için eğitilmiş BERT'ye atıfta bulunuyoruz (hangi görev ve model boyutu, hangi belirli BERT modelini belirleyecektir).
- Doğal Dil İşleme (NLP): Bir görevi tamamlamak için dil tabanlı bilgilerin işlenmesindeki çalışma alanını tanımlayan genel bir terim.
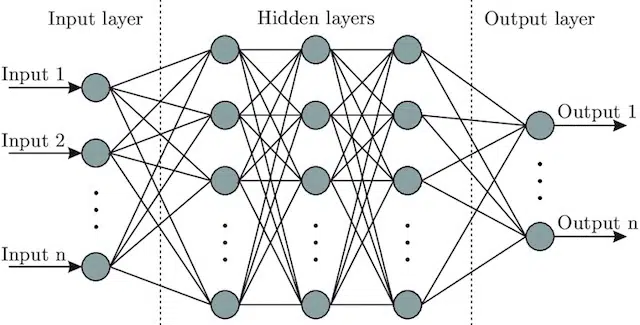
- Sinir Ağı : Beyinden ilham alan, bir girdi katmanı (sinyallerin girdiği yer - bir insanda bunu bir nesneye dokunulduğunda beyne gönderilen sinyal olarak düşünebilirsiniz) içeren bir model mimarisi. gizli katmanlar (bir çıktı üretmek için girdinin ayarlanabileceği bir dizi farklı yol sağlayarak) ve çıktı katmanı. Sinyaller girer, çıktı katmanını üretmek için birden fazla farklı “yolu” test eder ve her zamankinden daha iyi çıktı koşullarına yönelmek üzere programlanır. Görsel olarak şu şekilde temsil edilebilir:
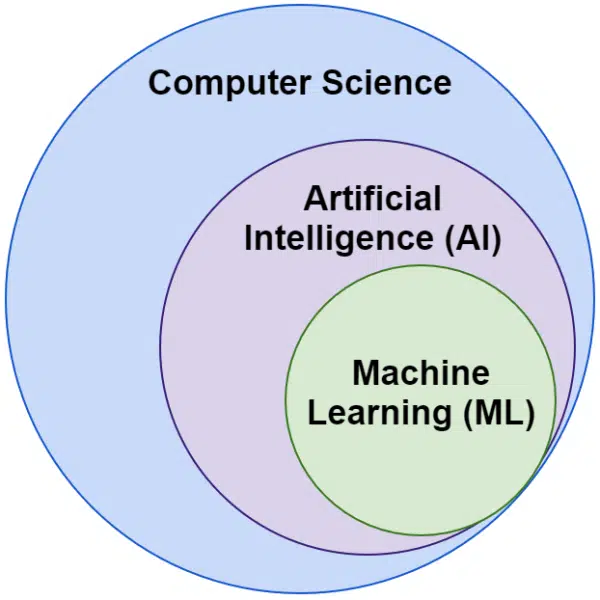
Yapay zeka ve makine öğrenimi arasındaki fark nedir?
Yapay zeka ve makine öğrenimi kelimelerinin birbirinin yerine kullanıldığını sıklıkla duyarız. Tam olarak aynı değiller.
Yapay zeka, makinelerin zekayı taklit etme alanıyken, makine öğrenimi, bir görev için açıkça programlanmadan öğrenebilen sistemlerin arayışıdır.
Görsel olarak şöyle düşünebilirsiniz:
Google'ın makine öğrenimi ile ilgili algoritmaları
Tüm büyük arama motorları, makine öğrenimini bir veya birçok şekilde kullanır. Aslında, Microsoft bazı önemli atılımlar yapıyor. WebFormer gibi modellerle Meta AI aracılığıyla Facebook gibi sosyal ağlar da öyle.
Ancak buradaki odak noktamız SEO. Bing, %6.61 ABD pazar payına sahip bir arama motoru olsa da, popüler ve önemli aramayla ilgili teknolojileri keşfederken bu makalede buna odaklanmayacağız.
Google, çok sayıda makine öğrenimi algoritması kullanır. Kelimenin tam anlamıyla sizin, benim veya muhtemelen herhangi bir Google mühendisinin hepsini bilmesine imkan yok. Bunun da ötesinde, birçoğu aramanın isimsiz kahramanlarıdır ve diğer sistemlerin daha iyi çalışmasını sağladıklarından onları tam olarak keşfetmemize gerek yoktur.
Bağlam için bunlar, aşağıdaki gibi algoritmaları ve modelleri içerir:
- Google FLAN – öğrenmenin bir alandan diğerine transferini basitçe hızlandırır ve hesaplama açısından daha az maliyetli hale getirir. Kayda değer: Makine öğreniminde, bir alan bir web sitesine değil, Doğal Dil İşleme'de (NLP) duygu analizi veya Computer Vision'da (CV) nesne algılama gibi görev veya gerçekleştirdiği görev kümelerine atıfta bulunur.
- V-MoE – bu modelin tek işi, daha az kaynakla büyük vizyon modellerinin eğitimine izin vermektir. Teknik olarak yapılabilecekleri genişleterek ilerlemeyi sağlayan bu gibi gelişmelerdir.
- Alt Sözde Etiketler - bu sistem videoda eylem tanımayı iyileştirerek videoyla ilgili çeşitli anlayış ve görevlere yardımcı olur.
Bunların hiçbiri sıralamayı veya düzenleri doğrudan etkilemez. Ancak Google'ın ne kadar başarılı olduğunu etkilerler.
Şimdi, Google sıralamalarıyla ilgili temel algoritmalara ve modellere bakalım.
Sıra Beyin
Her şey burada başladı, makine öğreniminin Google'ın algoritmalarına dahil edilmesi.
2015 yılında tanıtılan RankBrain algoritması, Google'ın daha önce görmediği (%15'ini oluşturan) sorgulara uygulandı. Haziran 2016'ya kadar tüm sorguları içerecek şekilde genişletildi.
Hummingbird ve Bilgi Grafiği gibi büyük ilerlemelerin ardından RankBrain, Google'ın dünyayı dizeler (anahtar kelimeler ve kelime ve karakter kümeleri) olarak görmekten nesnelere (varlıklara) doğru genişlemesine yardımcı oldu. Örneğin, bundan önce Google, esasen içinde yaşadığım şehri (Victoria, BC) düzenli olarak bir arada bulunan, ancak aynı zamanda düzenli olarak ayrı ayrı ortaya çıkan ve her zaman farklı bir anlama gelebilen ancak her zaman farklı olmayan iki kelime olarak görürdü.
RankBrain'den sonra Victoria, BC'yi bir varlık olarak gördüler - belki de makine kimliği (/m/07ypt) - ve bu nedenle sadece “Victoria” kelimesine bassalar bile, bağlamı kurabilselerdi, ona aynı varlık olarak muamele edeceklerdi. Victoria, M.Ö.
Bununla, sadece anahtar kelimelerin ve anlamın ötesinde “görüyorlar”, sadece beynimiz görüyor. Ne de olsa, “yakınımdaki pizza”yı okuduğunuzda bunu üç ayrı kelimeden mi anlıyorsunuz yoksa pizza deyince aklınıza bir görsel mi geliyor, bulunduğunuz mekanda size dair bir anlayış var mı?
Kısacası RankBrain, algoritmaların sinyallerini anahtar kelimeler yerine nesnelere uygulamalarına yardımcı olur.
BERT
BERT ( Transformatörlerden Çift Yönlü Kodlayıcı Gösterimleri).
2019'da Google'ın algoritmalarına bir BERT modelinin eklenmesiyle Google, kavramların tek yönlü anlayışından çift yönlü hale geldi.
Bu sıradan bir değişiklik değildi.
2018'de BERT modelinin açık kaynak kullanımına ilişkin duyurularında yer alan görsel Google, resmin çizilmesine yardımcı oluyor:
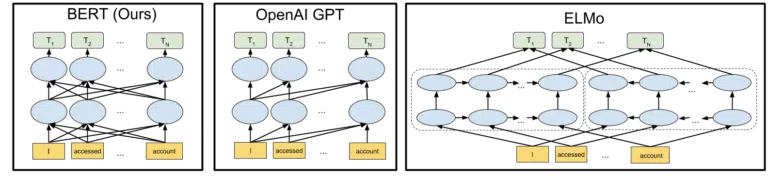
Makine öğreniminde belirteçlerin ve transformatörlerin nasıl çalıştığına dair ayrıntılara girmeden, buradaki ihtiyaçlarımız için sadece üç resme ve oklara bakmak ve BERT versiyonunda her bir kelimenin her ikisinden de nasıl bilgi aldığını düşünmek yeterlidir. yan, bu birden fazla kelime de dahil olmak üzere.
Daha önce bir modelin sadece bir yönde kelimelerden içgörü uygulayabildiği yerde, şimdi her iki yöndeki kelimelere dayalı bağlamsal bir anlayış kazanıyorlar.
Basit bir örnek "araba kırmızı" olabilir.
Ancak BERT kırmızı olduktan sonra arabanın rengi olduğu doğru bir şekilde anlaşıldı, çünkü o zamana kadar kırmızı kelimesi araba kelimesinin ardından geldi ve bu bilgi geri gönderilmedi.
Bir kenara, BERT ile oynamak isterseniz GitHub'da çeşitli modeller mevcut.
LaMDA
LaMDA henüz doğada konuşlandırılmadı ve ilk olarak 2021 Mayıs'ında Google I/O'da duyuruldu.
Açıklığa kavuşturmak için, “henüz konuşlandırılmadı” yazdığımda, “bildiğim kadarıyla” demek istiyorum. Sonuçta, RankBrain'i algoritmalara yerleştirildikten aylar sonra öğrendik. Bu, olduğu zaman devrimci olacağını söyledi.
LaMDA, görünüşte mevcut en son teknolojiyi ezen bir konuşma dili modelidir.
LaMDA ile odak temelde iki yönlüdür:
- Konuşmada mantıklılığı ve özgünlüğü geliştirin. Esasen, bir sohbetteki yanıtın makul VE spesifik olduğundan emin olmak için. Örneğin, çoğu soruya “Bilmiyorum” yanıtı mantıklıdır ancak spesifik değildir. Öte yandan, “Nasılsın?” Gibi bir soruya verilen yanıt. yani, “Yağmurlu bir günde ördek çorbasını severim. Uçurtma uçurmaya çok benziyor.” çok spesifik ama pek mantıklı değil.
LaMDA, her iki sorunu da çözmeye yardımcı olur. - İletişim kurduğumuzda, nadiren doğrusal bir konuşma olur. Bir tartışmanın nerede başlayıp nerede biteceğini düşündüğümüzde, tek bir konuyla ilgili olsa bile (örneğin, “Bu hafta trafiğimiz neden azaldı?”), genellikle ele almayacağımız farklı konuları ele almış olacağız. gireceğini tahmin etti.
Chatbot kullanmış olan herkes, bu senaryolarda berbat olduklarını bilir. İyi uyum sağlamazlar ve geçmiş bilgileri geleceğe iyi taşımazlar (ve tam tersi).
LaMDA bu sorunu daha da giderir.
Google'dan örnek bir konuşma:


Bir sohbet robotundan beklediğinizden çok daha iyi adapte olduğunu görebiliriz.
LaMDA'nın Google Asistan'da uygulandığını görüyorum. Ancak, bunu düşünürsek, bireysel düzeyde bir sorgu akışının nasıl çalıştığını anlama konusundaki gelişmiş yetenekler, hem arama sonucu düzenlerinin uyarlanmasında hem de ek konuların ve sorguların kullanıcıya sunulmasında kesinlikle yardımcı olacaktır.
Temel olarak, LaMDA'dan ilham alan teknolojilerin sohbet dışı arama alanlarına nüfuz ettiğini göreceğimizden oldukça eminim.
KELM
Yukarıda, RankBrain'i tartışırken, makine kimliklerine ve varlıklarına değindik. Mayıs 2021'de duyurulan KELM, işi bambaşka bir boyuta taşıyor.
KELM, aramadaki yanlılığı ve toksik bilgiyi azaltma çabasından doğdu. Güvenilir bilgilere (Vikiveri) dayandığından, bu amaç için iyi kullanılabilir.
KELM bir model olmaktan çok bir veri kümesi gibidir. Temel olarak, makine öğrenimi modelleri için eğitim verileridir. Buradaki amaçlarımız için daha ilginç olanı, bize Google'ın verilere uyguladığı bir yaklaşımı anlatmasıdır.
Özetle Google, üçlülerin (özne varlığı, ilişki, nesne varlığı (araba, renk, kırmızı) koleksiyonu olan İngilizce Vikiveri Bilgi Grafiği'ni alıp çeşitli varlık alt grafiklerine dönüştürdü ve sözlü hale getirdi. bir şekil:
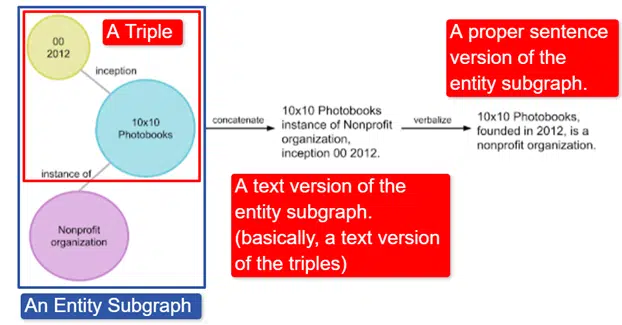
Bu resimde görüyoruz:
- Üçlü, bireysel bir ilişkiyi tanımlar.
- Bir merkezi varlıkla ilgili çok sayıda üçlüyü eşleyen varlık alt grafiği.
- Varlık alt grafiğinin metin versiyonu.
- Uygun cümle.
Bu, daha sonra diğer modeller tarafından, gerçekleri tanımaları ve toksik bilgileri filtrelemeleri için eğitilmesine yardımcı olmak için kullanılabilir.
Google, derlemi açık kaynaklı hale getirdi ve GitHub'da mevcut. Daha fazla bilgi istiyorsanız, açıklamalarına bakmak, nasıl çalıştığını ve yapısını anlamanıza yardımcı olacaktır.
ANNE
MUM, Mayıs 2021'de Google I/O'da da duyuruldu.
Devrim niteliğinde olsa da, tanımlaması aldatıcı bir şekilde basittir.
MUM , Çok Görevli Birleşik Model anlamına gelir ve çok modludur . Bu, test, resim, video vb. gibi farklı içerik formatlarını "anladığı" anlamına gelir. Bu, ona yanıt vermenin yanı sıra birden fazla modaliteden bilgi alma gücü verir.
Bir yana: Bu, MultiModel mimarisinin ilk kullanımı değil. İlk olarak 2017 yılında Google tarafından sunuldu.
Ek olarak, MUM dizelerde değil şeylerde çalıştığından, diller arasında bilgi toplayabilir ve ardından kullanıcının kendi yanıtını sağlayabilir. Bu, özellikle internette hitap edilmeyen dilleri konuşanlar için bilgi erişiminde büyük gelişmelerin kapısını açar, ancak İngilizce konuşanlar bile doğrudan faydalanacaktır.
Google'ın kullandığı örnek, Fuji Dağı'na tırmanmak isteyen bir uzun yürüyüşçü. En iyi ipuçlarından ve bilgilerden bazıları Japonca yazılmış olabilir ve çevirebilseler bile onu nasıl yüzeye çıkaracaklarını bilemeyecekleri için kullanıcı tarafından tamamen kullanılamayabilir.
MUM ile ilgili önemli bir not, modelin yalnızca içeriği anlaması değil, aynı zamanda onu üretebilmesidir. Yani pasif olarak bir kullanıcıyı bir sonuca göndermek yerine, birden fazla kaynaktan veri toplanmasını kolaylaştırabilir ve geri bildirimi (sayfa, ses vb.) kendisi sağlayabilir.
Bu, ben de dahil olmak üzere birçok kişi için bu teknolojinin endişe verici bir yönü olabilir.
Makine öğrenimi başka nerelerde kullanılır?
Organik arama üzerinde önemli bir etkisi olduğuna inandığım ve adını duyacağınız bazı temel algoritmalara değindik. Ancak bu, makine öğreniminin kullanıldığı yerlerin bütününden uzaktır.
Mesela şunu da sorabiliriz:
- Reklamlarda, otomatik teklif stratejilerinin ve reklam otomasyonunun arkasındaki sistemleri yönlendiren nedir?
- Haberlerde, sistem hikayeleri nasıl gruplayacağını nasıl biliyor?
- Görüntülerde, sistem belirli nesneleri ve nesne türlerini nasıl tanımlar?
- E-postada, sistem spam'i nasıl filtreler?
- Çeviride, sistem yeni kelimeleri ve deyimleri nasıl öğrenir?
- Video'da, sistem bundan sonra hangi videoları önereceğini nasıl öğreniyor?
Tüm bu sorular ve yüzlerce hatta binlercesi aynı cevaba sahiptir:
Makine öğrenme.
Makine öğrenimi algoritmaları ve modelleri türleri
Şimdi, makine öğrenimi algoritmalarının ve modellerinin iki denetim düzeyinden geçelim: denetimli ve denetimsiz öğrenme. Baktığımız algoritma türünü ve onları nerede arayacağımızı anlamak önemlidir.
denetimli öğrenme
Basitçe söylemek gerekirse, denetimli öğrenme ile algoritmaya tam olarak etiketlenmiş eğitim ve test verileri verilir.
Bu demektir ki, birisi güvenilir veriler üzerine bir model eğitmek için binlerce (veya milyonlarca) örneği etiketleme çabasından geçmiştir. Örneğin, kırmızı gömlek giyen kişilerin x sayıda fotoğrafında kırmızı gömlek etiketleme.
Denetimli öğrenme, sınıflandırma ve regresyon problemlerinde faydalıdır. Sınıflandırma problemleri oldukça basittir. Bir şeyin bir grubun parçası olup olmadığını belirleme.
Kolay bir örnek Google Fotoğraflar'dır.
Google beni aşamaların yanı sıra sınıflandırdı. Bu resimlerin her birini manuel olarak etiketlemediler. Ancak model, aşamalar için manuel olarak etiketlenmiş veriler üzerinde eğitilmiş olacaktır. Google Fotoğraflar'ı kullanan herkes, fotoğrafları ve içindeki kişileri düzenli aralıklarla onaylamanızı istediklerini bilir. Biz manuel etiketleyicileriz.
Hiç ReCAPTCHA kullandınız mı? Bil bakalım ne yapıyorsun? Doğru. Düzenli olarak makine öğrenimi modellerinin eğitilmesine yardımcı oluyorsunuz.
Öte yandan, regresyon problemleri, bir çıktı değerine eşlenmesi gereken bir dizi girdinin olduğu problemlerle ilgilenir.
Basit bir örnek, bir evin satış fiyatını ayak kare, yatak odası sayısı, banyo sayısı, okyanustan uzaklık vb. girdileriyle tahmin etmek için bir sistem düşünmektir.
Çok çeşitli özellikler/sinyaller taşıyabilecek ve ardından söz konusu varlığa (/site) bir değer ataması gerekebilecek başka sistemler düşünebiliyor musunuz?
Kesinlikle daha karmaşık ve çeşitli işlevlere hizmet eden muazzam bir bireysel algoritma dizisini alırken, regresyon muhtemelen aramanın temel işlevlerini yönlendiren algoritma türlerinden biridir.
Burada yarı denetimli modellere geçtiğimizden şüpheleniyorum - bazı aşamalarda yapılan manuel etiketleme (kalite değerlendiricileri düşünün) ve oyundaki modelleri ayarlamak ve oluşturmak için kullanılan sonuç kümeleriyle kullanıcıların memnuniyetini belirleyen sistem tarafından toplanan sinyaller .
denetimsiz öğrenme
Denetimsiz öğrenmede, bir sisteme bir dizi etiketlenmemiş veri verilir ve onunla ne yapacağını kendisi belirlemesi için bırakılır.
Nihai hedef belirtilmemiştir. Sistem, benzer öğeleri bir araya toplayabilir, aykırı değerler arayabilir, ortak ilişki bulabilir, vb.
Denetimsiz öğrenme, çok fazla veriye sahip olduğunuzda ve bunların nasıl kullanılması gerektiğini önceden bilmiyorsanız veya bilmiyorsanız kullanılır.
İyi bir örnek Google Haberler olabilir.
Google, benzer haberleri kümeler ve ayrıca daha önce var olmayan haberleri de ortaya çıkarır (böylece bunlar haberdir).
Bu görevler, en iyi, esas olarak (yalnızca olmasa da) denetimsiz modeller tarafından gerçekleştirilecektir. Önceki kümelemenin veya yüzeye çıkmanın ne kadar başarılı veya başarısız olduğunu “gören”, ancak bunu etiketlenmemiş (önceki haberlerde olduğu gibi) mevcut verilere tam olarak uygulayamayan ve kararlar alamayan modeller.
Özellikle işler genişledikçe, arama ile ilgili olduğu için makine öğreniminin inanılmaz derecede önemli bir alanıdır.
Google Çeviri başka bir iyi örnektir. Sistemin, İngilizce'deki x kelimesinin İspanyolca'daki y kelimesine eşit olduğunu anlamak için eğitildiği, eskiden var olan bire bir çeviri değil, daha ziyade her ikisinin kullanım kalıplarını araştıran ve yarı yoluyla çeviriyi geliştiren daha yeni teknikler. - denetimli öğrenme (bazı etiketli veriler ve çoğu değil) ve denetimsiz öğrenme, bir dilden tamamen bilinmeyen (sisteme) bir dile çeviri.
Bunu yukarıda MUM ile gördük, ancak diğer makalelerde var ve modeller iyi.
Sadece başlangıç
Umarım bu, makine öğrenimi ve aramada nasıl kullanıldığı için bir temel sağlamıştır.
Gelecekteki makalelerim sadece makine öğreniminin nasıl ve nerede bulunabileceğiyle ilgili olmayacak (bazıları olsa da). Ayrıca, daha iyi bir SEO olmak için kullanabileceğiniz pratik makine öğrenimi uygulamalarına da dalacağız. Endişelenmeyin, bu durumlarda sizin için kodlamayı yapmış olacağım ve genel olarak kullanımı kolay bir Google Colab ile birlikte takip edeceğim ve bazı önemli SEO ve iş sorularını yanıtlamanıza yardımcı olacağım.
Örneğin, sitelerinize, içeriğinize, trafiğinize ve daha fazlasına ilişkin anlayışınızı geliştirmek için doğrudan makine öğrenimi modellerini kullanabilirsiniz. Bir sonraki makalem size nasıl olduğunu gösterecek. Teaser: zaman serisi tahmini.
Bu makalede ifade edilen görüşler konuk yazara aittir ve mutlaka Search Engine Land değildir. Personel yazarları burada listelenir.