
Un ghid pentru învățarea automată în căutare: termeni cheie, concepte și algoritmi
Publicat: 2022-05-02Când vine vorba de învățarea automată, există câteva concepte și termeni largi pe care toți cei care caută ar trebui să le cunoască. Ar trebui să știm cu toții unde este folosită învățarea automată și diferitele tipuri de învățare automată care există.
Citiți mai departe pentru a înțelege mai bine modul în care învățarea automată afectează căutarea, ceea ce fac motoarele de căutare și cum să recunoașteți învățarea automată la locul de muncă. Să începem cu câteva definiții. Apoi vom intra în algoritmi și modele de învățare automată.
Termeni de învățare automată
Ceea ce urmează sunt definiții ale unor termeni importanți de învățare automată, dintre care majoritatea vor fi discutați la un moment dat în articol. Acesta nu intenționează să fie un glosar cuprinzător al fiecărui termen de învățare automată. Dacă doriți asta, Google oferă unul bun aici.
- Algoritm : un proces matematic rulat pe date pentru a produce o ieșire. Există diferite tipuri de algoritmi pentru diferite probleme de învățare automată.
- Inteligența artificială (IA) : un domeniu al informaticii axat pe dotarea computerelor cu abilități sau abilități care reproduc sau sunt inspirate de inteligența umană.
- Corpus : O colecție de texte scrise. De obicei organizat într-un fel.
- Entitate : Un lucru sau concept care este unic, singular, bine definit și distins. Vă puteți gândi la el ca un substantiv, deși este puțin mai larg decât atât. O nuanță specifică de roșu ar fi o entitate. Este unic și singular prin faptul că nimic altceva nu este exact ca acesta, este bine definit (gândiți-vă la codul hexadecimal) și se distinge prin faptul că îl puteți deosebi de orice altă culoare.
- Învățare automată : un domeniu al inteligenței artificiale, axat pe crearea de algoritmi, modele și sisteme pentru a îndeplini sarcini și, în general, pentru a se îmbunătăți pe ei înșiși în îndeplinirea acelei sarcini fără a fi programat în mod explicit.
- Model: Un model este adesea confundat cu un algoritm. Distincția poate deveni neclară (cu excepția cazului în care ești un inginer de învățare automată). În esență, diferența este că, atunci când un algoritm este pur și simplu o formulă care produce o valoare de ieșire, un model este reprezentarea a ceea ce a produs acel algoritm după ce a fost antrenat pentru o anumită sarcină. Deci, când spunem „model BERT” ne referim la BERT care a fost antrenat pentru o anumită sarcină NLP (care sarcină și dimensiunea modelului vor dicta ce model BERT specific).
- Procesarea limbajului natural (NLP): Un termen general pentru a descrie domeniul de lucru în procesarea informațiilor bazate pe limbaj pentru a finaliza o sarcină.
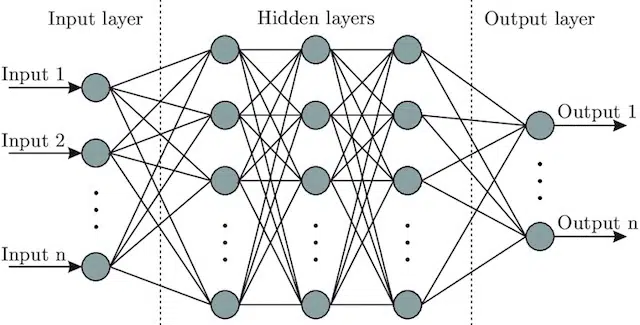
- Rețea neuronală : O arhitectură model care, inspirându-se din creier, include un strat de intrare (unde intră semnalele – la un om ați putea crede că este semnalul trimis creierului atunci când un obiect este atins)), o serie de straturi ascunse (oferind un număr de căi diferite, intrarea poate fi ajustată pentru a produce o ieșire) și stratul de ieșire. Semnalele intră, testează mai multe „căi” diferite pentru a produce stratul de ieșire și sunt programate pentru a gravita către condiții de ieșire din ce în ce mai bune. Vizual poate fi reprezentat prin:
Inteligența artificială vs. învățarea automată: care este diferența?
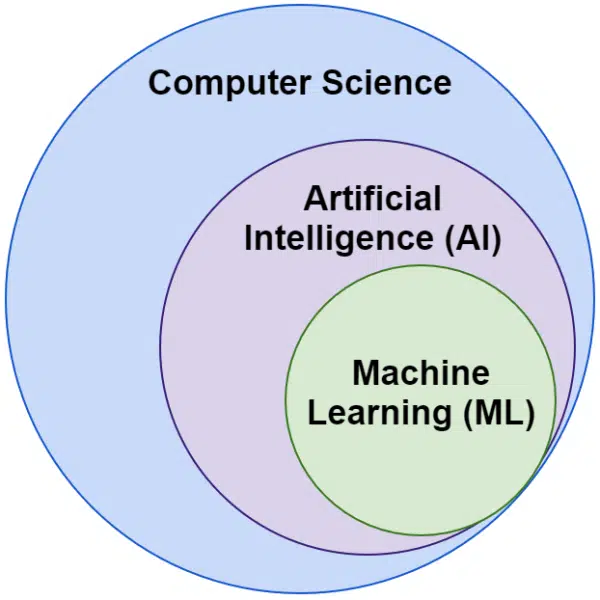
Adesea auzim cuvintele inteligență artificială și învățare automată folosite în mod interschimbabil. Nu sunt exact la fel.
Inteligența artificială este domeniul de a face ca mașinile să imite inteligența, în timp ce învățarea automată este urmărirea sistemelor care pot învăța fără a fi programate în mod explicit pentru o sarcină.
Vizual, vă puteți gândi astfel:
Algoritmii Google legați de învățarea automată
Toate motoarele de căutare majore folosesc învățarea automată în unul sau mai multe moduri. De fapt, Microsoft produce unele descoperiri semnificative. La fel și rețelele sociale precum Facebook prin Meta AI cu modele precum WebFormer.
Dar atenția noastră aici este SEO. Și în timp ce Bing este un motor de căutare, cu o cotă de piață de 6,61% din SUA, nu ne vom concentra asupra acestuia în acest articol, deoarece explorăm tehnologiile populare și importante legate de căutare.
Google folosește o mulțime de algoritmi de învățare automată. Literal, nu există nicio posibilitate ca tu, eu sau probabil orice inginer Google să le cunoașteți pe toate. În plus, mulți sunt pur și simplu eroi necunoscuți ai căutării și nu trebuie să-i explorăm pe deplin, deoarece pur și simplu fac ca alte sisteme să funcționeze mai bine.
Pentru context, acestea ar include algoritmi și modele precum:
- Google FLAN – care pur și simplu accelerează și face mai puțin costisitor din punct de vedere computațional transferul de învățare de la un domeniu la altul. De remarcat: în învățarea automată, un domeniu nu se referă la un site web, ci mai degrabă la sarcina sau grupurile de sarcini pe care le îndeplinește, cum ar fi analiza sentimentelor în procesarea limbajului natural (NLP) sau detectarea obiectelor în computer Vision (CV).
- V-MoE – singura sarcină a acestui model este de a permite antrenamentul modelelor de viziune mare cu mai puține resurse. Sunt evoluții ca aceasta care permit progresul prin extinderea a ceea ce se poate face din punct de vedere tehnic.
- Sub-pseudoetichete – acest sistem îmbunătățește recunoașterea acțiunilor în videoclipuri, ajutând la o varietate de înțelegeri și sarcini legate de video.
Niciuna dintre acestea nu afectează direct clasarea sau aspectul. Dar au impact asupra succesului Google.
Deci, acum să ne uităm la algoritmii și modelele de bază implicate în clasamentele Google.
RankBrain
Aici a început totul, introducerea învățării automate în algoritmii Google.
Introdus în 2015, algoritmul RankBrain a fost aplicat interogărilor pe care Google nu le-a văzut înainte (reprezentând 15% dintre ele). Până în iunie 2016, a fost extins pentru a include toate interogările.
În urma progreselor uriașe precum Hummingbird și Knowledge Graph, RankBrain a ajutat Google să se extindă de la vizualizarea lumii ca șiruri de caractere (cuvinte cheie și seturi de cuvinte și caractere) la lucruri (entități). De exemplu, înainte de aceasta, Google ar vedea în esență orașul în care locuiesc (Victoria, BC) ca două cuvinte care apar în mod regulat împreună, dar apar și în mod regulat separat și pot, dar nu înseamnă întotdeauna, ceva diferit atunci când o fac.
După RankBrain, au văzut Victoria, BC ca o entitate – poate ID-ul mașinii (/m/07ypt) – și așa că, chiar dacă ar apărea doar cuvântul „Victoria”, dacă ar putea stabili contextul, l-ar trata ca aceeași entitate ca și Victoria, BC.
Cu aceasta, ei „văd” dincolo de simple cuvinte cheie și de sens, doar creierul nostru o face. La urma urmei, când citești „pizza lângă mine” înțelegi asta în termeni de trei cuvinte individuale sau ai un vizual în capul tău de pizza și o înțelegere a ta în locația în care te afli?
Pe scurt, RankBrain ajută algoritmii să-și aplice semnalele lucrurilor în loc de cuvinte cheie.
BERT
BERT ( Reprezentări ale codificatorului bidirecțional din transformatori).
Odată cu introducerea unui model BERT în algoritmii Google în 2019, Google a trecut de la înțelegerea unidirecțională a conceptelor la bidirecțională.
Aceasta nu a fost o schimbare banală.
Elementul vizual de Google inclus în anunțul lor privind achiziționarea deschisă a modelului BERT în 2018 ajută la pictarea tabloului:
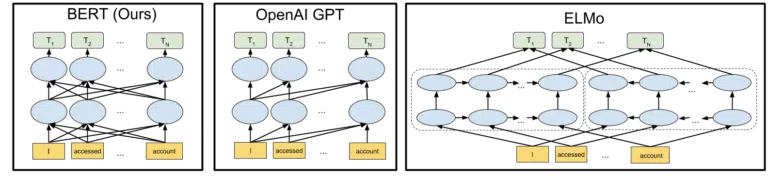
Fără a intra în detalii despre modul în care funcționează jetoanele și transformatoarele în învățarea automată, este suficient pentru nevoile noastre de aici să ne uităm pur și simplu la cele trei imagini și săgeți și să ne gândim cum, în versiunea BERT, fiecare dintre cuvinte obține informații de la cele de pe oricare dintre ele. lateral, inclusiv acele cuvinte multiple de la distanță.
Acolo unde anterior un model putea aplica doar o perspectivă a cuvintelor într-o singură direcție, acum dobândesc o înțelegere contextuală bazată pe cuvinte în ambele direcții.
Un exemplu simplu ar putea fi „mașina este roșie”.
Abia după ce BERT a fost roșu s-a înțeles corect că este culoarea mașinii, pentru că până atunci cuvântul roșu venea după cuvântul mașină, iar informația respectivă nu a fost trimisă înapoi.
Deoparte, dacă doriți să jucați cu BERT, pe GitHub sunt disponibile diverse modele.
LaMDA
LaMDA nu a fost încă implementat în sălbăticie și a fost anunțat pentru prima dată la Google I/O în mai 2021.
Pentru a clarifica, când scriu „nu a fost încă implementat” mă refer la „din câte știu”. La urma urmei, am aflat despre RankBrain la câteva luni după ce a fost implementat în algoritmi. Acestea fiind spuse, atunci când va fi, va fi revoluționar.
LaMDA este un model de limbaj conversațional, care aparent zdrobește stadiul actual al tehnicii.
Accentul cu LaMDA este practic dublu:
- Îmbunătățiți caracterul rezonabil și specificul conversației. În esență, pentru a vă asigura că un răspuns într-un chat este rezonabil ȘI specific. De exemplu, la majoritatea întrebărilor răspunsul „Nu știu” este rezonabil, dar nu este specific. Pe de altă parte, un răspuns la o întrebare de genul „Ce mai faci?” adică „Îmi place supa de rață într-o zi ploioasă. Seamănă mult cu zborul cu zmee.” este foarte specific, dar deloc rezonabil.
LaMDA ajută la rezolvarea ambelor probleme. - Când comunicăm, rareori este o conversație liniară. Când ne gândim unde ar putea începe și unde se termină o discuție, chiar dacă a fost vorba despre un singur subiect (de exemplu, „De ce a scăzut traficul în această săptămână?”), în general, vom fi acoperit diferite subiecte pe care nu le-am fi avut. a prezis intrarea.
Oricine a folosit un chatbot știe că este abisal în aceste scenarii. Ei nu se adaptează bine și nu transportă bine informațiile din trecut în viitor (și invers).
LaMDA abordează în continuare această problemă.
Un exemplu de conversație de la Google este:


Putem vedea că se adaptează mult mai bine decât ne-am aștepta de la un chatbot.
Văd că LaMDA este implementat în Asistentul Google. Dar dacă ne gândim bine, capabilitățile îmbunătățite de înțelegere a modului în care funcționează un flux de interogări la nivel individual ar ajuta cu siguranță atât la adaptarea aspectului rezultatelor căutării, cât și la prezentarea de subiecte și interogări suplimentare pentru utilizator.
Practic, sunt destul de sigur că vom vedea tehnologii inspirate de LaMDA pătrunzând în zonele de căutare non-chat.
KELM
Mai sus, când discutam despre RankBrain, am atins despre ID-urile și entitățile mașinilor. Ei bine, KELM, care a fost anunțat în mai 2021, îl duce la un nivel cu totul nou.
KELM s-a născut din efortul de a reduce părtinirea și informațiile toxice în căutare. Deoarece se bazează pe informații de încredere (Wikidata), poate fi folosit bine în acest scop.
În loc să fie un model, KELM este mai mult ca un set de date. Practic, este vorba de date de antrenament pentru modelele de învățare automată. Mai interesant pentru scopurile noastre de aici, este că ne vorbește despre o abordare pe care Google o adoptă asupra datelor.
Pe scurt, Google a luat Wikidata Knowledge Graph în engleză, care este o colecție de triple (entitate subiect, relație, entitate obiect (mașină, culoare, roșu) și l-a transformat în diferite subgrafe de entitate și l-a verbalizat. Acest lucru este cel mai ușor explicat în o imagine:
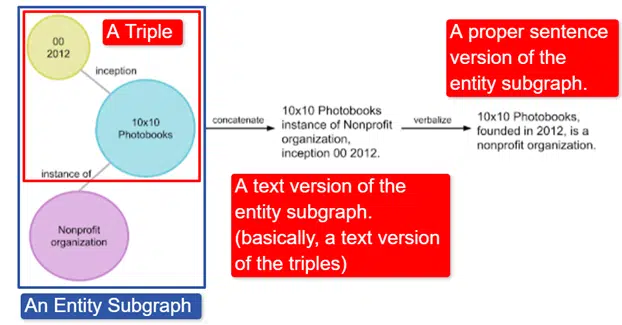
În această imagine vedem:
- Triplul descrie o relație individuală.
- Subgraful entității mapează o multitudine de triple legate de o entitate centrală.
- Versiunea text a subgrafului entității.
- Propozitia potrivita.
Acesta este apoi utilizat de alte modele pentru a le ajuta să recunoască faptele și să filtreze informațiile toxice.
Google a creat corpus în sursă deschisă și este disponibil pe GitHub. Privind descrierea lor, vă va ajuta să înțelegeți cum funcționează și structura sa, dacă doriți mai multe informații.
MĂMICĂ
MUM a fost anunțat și la Google I/O în mai 2021.
Deși este revoluționar, este înșelător de simplu de descris.
MUM înseamnă M ultitask Unified Model și este multimodal. Aceasta înseamnă că „înțelege” diferite formate de conținut, cum ar fi test, imagini, video etc. Acest lucru îi oferă puterea de a obține informații din mai multe modalități, precum și de a răspunde.
Deoparte: aceasta nu este prima utilizare a arhitecturii MultiModel. A fost prezentat pentru prima dată de Google în 2017.
În plus, deoarece MUM funcționează în lucruri și nu în șiruri, poate colecta informații în diferite limbi și apoi poate oferi un răspuns propriu al utilizatorului. Acest lucru deschide ușa către îmbunătățiri vaste în accesul la informații, în special pentru cei care vorbesc limbi care nu sunt abordate pe internet, dar chiar și vorbitorii de engleză vor beneficia în mod direct.
Exemplul pe care îl folosește Google este un drumeț care dorește să urce pe Muntele Fuji. Unele dintre cele mai bune sfaturi și informații pot fi scrise în japoneză și complet indisponibile pentru utilizator, deoarece acesta nu va ști cum să le scoată la suprafață, chiar dacă ar putea să le traducă.
O notă importantă despre MUM este că modelul nu numai că înțelege conținutul, dar îl poate produce. Deci, în loc să trimită pasiv un utilizator la un rezultat, poate facilita colectarea de date din mai multe surse și poate oferi feedback (pagină, voce etc.) în sine.
Acesta poate fi, de asemenea, un aspect îngrijorător al acestei tehnologii pentru mulți, inclusiv pentru mine.
Unde se mai folosește învățarea automată
Am atins doar câțiva dintre algoritmii cheie despre care ați auzit și despre care cred că au un impact semnificativ asupra căutării organice. Dar aceasta este departe de totalitatea în care este folosită învățarea automată.
De exemplu, putem să întrebăm și:
- În reclame, ce determină sistemele din spatele strategiilor de licitare automată și automatizării anunțurilor?
- În Știri, cum știe sistemul să grupeze poveștile?
- În imagini, cum identifică sistemul anumite obiecte și tipuri de obiecte?
- În e-mail, cum filtrează sistemul spam-ul?
- În traducere, cum face sistemul să învețe cuvinte și expresii noi?
- În Video, cum învață sistemul ce videoclipuri să recomande în continuare?
Toate aceste întrebări și alte sute, dacă nu multe mii, toate au același răspuns:
Învățare automată.
Tipuri de algoritmi și modele de învățare automată
Acum să trecem prin două niveluri de supraveghere ale algoritmilor și modelelor de învățare automată – învățarea supravegheată și nesupravegheată. Este importantă înțelegerea tipului de algoritm la care ne uităm și unde să-i căutăm.
Învățare supravegheată
Mai simplu spus, cu învățarea supravegheată, algoritmul primește date de antrenament și test complet etichetate.
Aceasta înseamnă că cineva a trecut prin efortul de a eticheta mii (sau milioane) de exemple pentru a instrui un model pe date fiabile. De exemplu, etichetarea cămășilor roșii în număr x de fotografii cu persoane care poartă cămăși roșii.
Învățarea supravegheată este utilă în problemele de clasificare și regresie. Problemele de clasificare sunt destul de simple. Stabilirea dacă ceva face sau nu parte dintr-un grup.
Un exemplu simplu este Google Foto.
Google m-a clasificat, precum și etapele. Nu au etichetat manual fiecare dintre aceste imagini. Dar modelul va fi fost instruit pe date etichetate manual pentru etape. Și oricine a folosit Google Foto știe că vă cere să confirmați periodic fotografiile și persoanele din ele. Noi suntem etichetatorii manuali.
Ați folosit vreodată ReCAPTCHA? Ghici ce faci? Asta e corect. Ajuți în mod regulat să antrenezi modele de învățare automată.
Problemele de regresie, pe de altă parte, se ocupă de probleme în care există un set de intrări care trebuie mapate la o valoare de ieșire.
Un exemplu simplu este să ne gândim la un sistem de estimare a prețului de vânzare al unei case cu intrarea de metri pătrați, numărul de dormitoare, numărul de băi, distanța față de ocean etc.
Vă puteți gândi la alte sisteme care ar putea include o gamă largă de caracteristici/semnale și apoi ar trebui să atribuie o valoare entității (/site-ului) în cauză?
Deși cu siguranță este mai complexă și preia o gamă enormă de algoritmi individuali care servesc diferite funcții, regresia este probabil unul dintre tipurile de algoritm care conduce funcțiile de bază ale căutării.
Bănuiesc că ne trecem la modele semi-supravegheate aici – cu etichetarea manuală (gândiți-vă la evaluatorii de calitate) fiind făcută în unele etape și semnalele colectate de sistem care determină satisfacția utilizatorilor cu seturile de rezultate fiind folosite pentru a ajusta și crea modelele în joc. .
Învățare nesupravegheată
În învățarea nesupravegheată, unui sistem i se oferă un set de date neetichetate și lăsat să determine singur ce să facă cu el.
Nu este specificat niciun obiectiv final. Sistemul poate grupa elemente similare, poate căuta valori aberante, poate găsi corelații etc.
Învățarea nesupravegheată este folosită atunci când aveți o mulțime de date și nu puteți sau nu știți dinainte cum ar trebui să fie utilizate.
Un exemplu bun ar putea fi Știri Google.
Google grupează știri similare și, de asemenea, scoate la suprafață știri care nu existau anterior (astfel, sunt știri).
Aceste sarcini ar fi cel mai bine îndeplinite de modele în principal (deși nu exclusiv) nesupravegheate. Modelele care au „văzut” cât de reușită sau nereușită a decurs gruparea sau suprafața anterioară, dar care nu pot aplica pe deplin acest lucru datelor curente, care sunt neetichetate (cum era știrile anterioare) și iau decizii.
Este un domeniu incredibil de important al învățării automate, deoarece este legat de căutare, mai ales pe măsură ce lucrurile se extind.
Google Translate este un alt exemplu bun. Nu traducerea unu-la-unu care exista, în care sistemul a fost instruit să înțeleagă că cuvântul x în engleză este egal cu cuvântul y în spaniolă, ci mai degrabă tehnici mai noi care caută modele în utilizarea ambelor, îmbunătățind traducerea prin semi -învățarea supravegheată (unele date etichetate și multe nu) și învățarea nesupravegheată, traducerea dintr-o limbă într-o limbă complet necunoscută (de sistem).
Am văzut asta cu MUM mai sus, dar există în alte lucrări și modelele sunt bine.
Doar începutul
Sperăm că acest lucru a oferit o bază pentru învățarea automată și modul în care este utilizată în căutare.
Articolele mele viitoare nu vor fi doar despre cum și unde poate fi găsită învățarea automată (deși unele o vor face). De asemenea, vom aborda aplicațiile practice ale învățării automate pe care le puteți utiliza pentru a fi un SEO mai bun. Nu vă faceți griji, în acele cazuri, voi fi făcut codificarea pentru dvs. și, în general, vă voi oferi un Google Colab ușor de utilizat pe care să îl urmăriți împreună, ajutându-vă să răspundeți la câteva întrebări importante privind SEO și afaceri.
De exemplu, puteți utiliza modele de învățare automată directă pentru a vă dezvolta înțelegerea site-urilor, conținutului, traficului și multe altele. Următorul meu articol vă va arăta cum. Teaser: prognoza serii temporale.
Opiniile exprimate în acest articol sunt cele ale autorului invitat și nu neapărat Search Engine Land. Autorii personalului sunt enumerați aici.