
検索における機械学習のガイド:重要な用語、概念、アルゴリズム
公開: 2022-05-02機械学習に関しては、検索対象のすべての人が知っておくべき幅広い概念と用語がいくつかあります。 機械学習がどこで使用されているか、そして存在するさまざまな種類の機械学習を知っておく必要があります。
機械学習が検索に与える影響、検索エンジンが実行していること、機械学習が機能していることを認識する方法をよりよく理解するために読んでください。 いくつかの定義から始めましょう。 次に、機械学習のアルゴリズムとモデルについて説明します。
機械学習用語
以下は、いくつかの重要な機械学習用語の定義です。これらのほとんどは、記事のある時点で説明されます。 これは、すべての機械学習用語の包括的な用語集を意図したものではありません。 あなたがそれを望むなら、グーグルはここに良いものを提供します。
- アルゴリズム:出力を生成するためにデータに対して実行される数学的プロセス。 機械学習の問題には、さまざまな種類のアルゴリズムがあります。
- 人工知能(AI) :人間の知能を複製するか、それに触発されたスキルや能力をコンピューターに装備することに焦点を当てたコンピューターサイエンスの分野。
- コーパス:書かれたテキストのコレクション。 通常、何らかの方法で編成されます。
- エンティティ:ユニークで、特異で、明確に定義され、区別できるものまたは概念。 それより少し広いですが、大まかに名詞と考えることができます。 赤の特定の色相はエンティティになります。 それは、他にまったく同じものがなく、明確に定義されており(16進コードを考えてください)、他の色と区別できるという点で独特で特異なものですか。
- 機械学習:人工知能の分野で、タスクを実行するためのアルゴリズム、モデル、システムの作成に焦点を当てており、一般に、明示的にプログラムせずにそのタスクを実行する際に自分自身を改善します。
- モデル:モデルはアルゴリズムと混同されることがよくあります。 区別が曖昧になる可能性があります(機械学習エンジニアでない限り)。 基本的に、違いは、アルゴリズムが単に出力値を生成する式である場合、モデルは、特定のタスク用にトレーニングされた後にそのアルゴリズムが生成したものの表現であるということです。 したがって、「BERTモデル」とは、特定のNLPタスク用にトレーニングされたBERTを指します(どのタスクとモデルサイズがどの特定のBERTモデルを決定するか)。
- 自然言語処理(NLP):タスクを完了するために言語ベースの情報を処理する作業の分野を説明する一般的な用語。
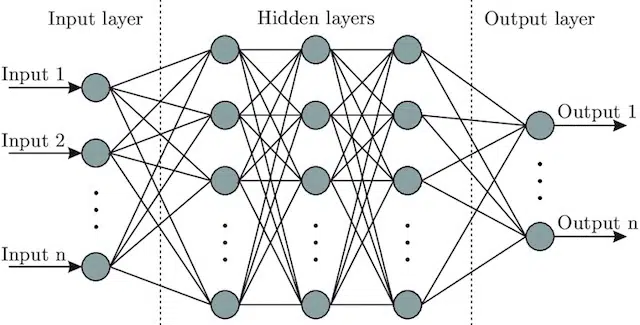
- ニューラルネットワーク:脳からインスピレーションを得て、入力層(信号が入る場所-人間では、オブジェクトに触れたときに脳に送信される信号と考えることができます)を含むモデルアーキテクチャ。隠れ層(入力を調整して出力を生成できるさまざまなパスを提供)、および出力層。 信号が入り、複数の異なる「パス」をテストして出力層を生成し、より良い出力条件に引き寄せられるようにプログラムされています。 視覚的には次のように表すことができます。
人工知能と機械学習:違いは何ですか?
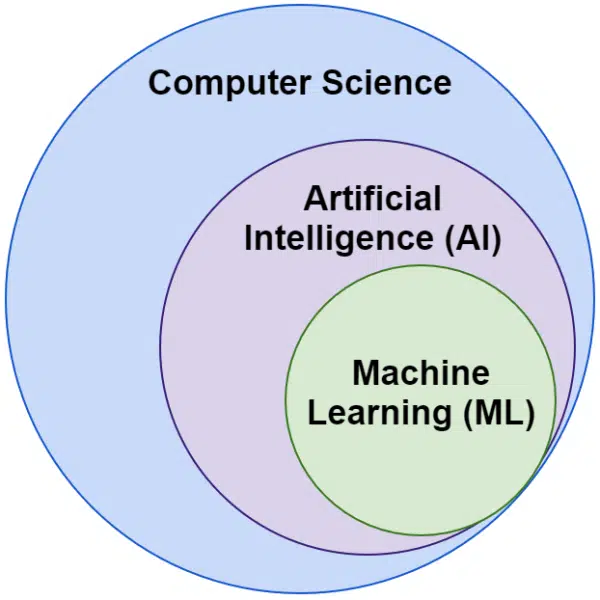
人工知能と機械学習という言葉は同じ意味で使われることがよくあります。 それらは完全に同じではありません。
人工知能は、機械に知能を模倣させる分野ですが、機械学習は、タスク用に明示的にプログラムされていなくても学習できるシステムの追求です。
視覚的には、次のように考えることができます。
Googleの機械学習関連のアルゴリズム
すべての主要な検索エンジンは、1つまたは多くの方法で機械学習を使用します。 実際、Microsoftはいくつかの重要なブレークスルーを生み出しています。 WebFormerなどのモデルを使用したMetaAIを介したFacebookなどのソーシャルネットワークも同様です。
しかし、ここでの焦点はSEOです。 また、Bingは検索エンジンであり、米国の市場シェアは6.61%ですが、この記事では、人気のある重要な検索関連テクノロジーについて説明するため、この検索エンジンに焦点を当てません。
Googleは、多数の機械学習アルゴリズムを使用しています。 文字通り、あなた、私、またはおそらくGoogleのエンジニアがそれらすべてを知る方法はありません。 その上、多くは単に検索の陰のヒーローであり、他のシステムをより良く機能させるだけなので、それらを完全に調査する必要はありません。
コンテキストとして、これらには次のようなアルゴリズムとモデルが含まれます。
- Google FLAN –単純に高速化し、あるドメインから別のドメインへの学習の転送にかかる計算コストを削減します。 注目に値する:機械学習では、ドメインはWebサイトを参照するのではなく、自然言語処理(NLP)の感情分析やコンピュータービジョン(CV)のオブジェクト検出など、実行するタスクまたはタスクのクラスターを参照します。
- V-MoE –このモデルの唯一の仕事は、より少ないリソースで大規模なビジョンモデルのトレーニングを可能にすることです。 技術的にできることを拡大することによって進歩を可能にするのは、このような開発です。
- サブ疑似ラベル–このシステムは、ビデオのアクション認識を改善し、ビデオ関連のさまざまな理解とタスクを支援します。
これらはいずれも、ランキングやレイアウトに直接影響を与えません。 しかし、それらはグーグルの成功に影響を与えます。
それでは、Googleのランキングに関連するコアアルゴリズムとモデルを見てみましょう。
ランクブレイン
これがすべての始まりであり、Googleのアルゴリズムへの機械学習の導入です。
2015年に導入されたRankBrainアルゴリズムは、Googleがこれまでに見たことのないクエリに適用されました(それらの15%を占めています)。 2016年6月までに、すべてのクエリを含むように拡張されました。
HummingbirdやKnowledgeGraphのような大きな進歩に続いて、RankBrainは、Googleが世界を文字列(キーワードと単語と文字のセット)として表示することから物(エンティティ)に拡張するのを支援しました。 たとえば、これ以前は、Googleは基本的に、私が住んでいる都市(ブリティッシュコロンビア州ビクトリア)を、定期的に共起する2つの単語と見なしていましたが、定期的に別々に出現することもあります。
ランクブレインの後、彼らはブリティッシュコロンビア州ビクトリアをエンティティ(おそらくマシンID(/ m / 07ypt))と見なしました。したがって、「ビクトリア」という単語だけをヒットしたとしても、コンテキストを確立できれば、それを同じエンティティとして扱います。ブリティッシュコロンビア州ビクトリア。
これにより、彼らは単なるキーワードや意味を超えて「見る」ことができ、私たちの脳だけがそうします。 結局のところ、「私の近くのピザ」を読んだとき、3つの個別の言葉でそれを理解しますか、それともピザの頭にビジュアルがあり、あなたがいる場所であなたを理解していますか?
つまり、RankBrainは、アルゴリズムがキーワードではなくシグナルを物事に適用するのに役立ちます。
BERT
BERT (トランスフォーマーからの双方向エンコーダー表現)。
2019年にGoogleのアルゴリズムにBERTモデルが導入されたことで、Googleは概念の一方向の理解から双方向に移行しました。
これはありふれた変化ではありませんでした。
2018年のBERTモデルのオープンソーシングの発表に含まれているビジュアルGoogleは、全体像を描くのに役立ちます。
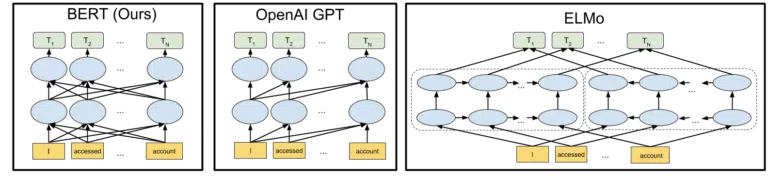
機械学習でトークンとトランスフォーマーがどのように機能するかを詳しく説明することなく、ここでのニーズは、3つの画像と矢印を見て、BERTバージョンで各単語がどちらかの単語からどのように情報を取得するかを考えるだけで十分です。離れたそれらの複数の単語を含む側。
以前はモデルが一方向の単語からの洞察しか適用できなかったのに対し、今では両方向の単語に基づいて文脈理解を得ることができます。
簡単な例として、「車は赤い」などがあります。
それまでは赤という言葉が車という言葉の後にあり、その情報は返送されなかったので、BERTが赤が車の色であると正しく理解されて初めてでした。
余談ですが、BERTで遊んでみたい場合は、GitHubでさまざまなモデルを利用できます。
LaMDA
LaMDAはまだ実際に展開されておらず、2021年5月にGoogle I/Oで最初に発表されました。
明確にするために、私が「まだ展開されていない」と書くとき、私は「私の知る限り」を意味します。 結局のところ、RankBrainがアルゴリズムにデプロイされてから数か月後にわかりました。 そうは言っても、それが革命的であるとき。
LaMDAは会話型言語モデルであり、現在の最先端技術を押しつぶしているように見えます。
LaMDAの焦点は、基本的に2つあります。
- 会話の合理性と特異性を向上させます。 基本的に、チャットでの応答が合理的かつ具体的であることを確認するため。 たとえば、ほとんどの質問に対して、「わからない」という回答は合理的ですが、具体的ではありません。 一方、「お元気ですか?」などの質問への回答。 つまり、「雨の日の鴨汁が好きです。 凧揚げによく似ています。」 非常に具体的ですが、ほとんど合理的ではありません。
LaMDAは、両方の問題に対処するのに役立ちます。 - 私たちがコミュニケーションをとるとき、それが直線的な会話になることはめったにありません。 ディスカッションがどこから始まりどこで終わるかを考えるとき、たとえそれが単一のトピックに関するものであったとしても(たとえば、「今週のトラフィックが減少するのはなぜですか?」)、通常、私たちが持っていないさまざまなトピックをカバーします。入ると予測されました。
チャットボットを使用したことのある人なら誰でも、これらのシナリオでは彼らがひどいことを知っています。 それらはうまく適応せず、過去の情報を将来にうまく伝えません(逆もまた同様です)。
LaMDAはさらにこの問題に対処します。
Googleからの会話の例は次のとおりです。


チャットボットから予想されるよりもはるかにうまく適応していることがわかります。
LaMDAがGoogleアシスタントに実装されているのがわかります。 しかし、考えてみると、クエリのフローが個々のレベルでどのように機能するかを理解するための拡張機能は、検索結果のレイアウトの調整と、ユーザーへの追加のトピックやクエリの提示の両方に確かに役立ちます。
基本的に、LaMDAに触発されたテクノロジーがチャット以外の検索領域に浸透することは間違いありません。
ケルム
上記では、RankBrainについて説明したときに、マシンIDとエンティティに触れました。 さて、2021年5月に発表されたKELMはそれをまったく新しいレベルに引き上げます。
KELMは、検索における偏見や有毒な情報を減らす努力から生まれました。 信頼できる情報(ウィキデータ)に基づいているため、この目的に適しています。
KELMはモデルではなく、データセットのようなものです。 基本的には、機械学習モデルのトレーニングデータです。 ここでの私たちの目的にとってより興味深いのは、Googleがデータに対して採用しているアプローチについて教えてくれることです。
一言で言えば、Googleはトリプル(サブジェクトエンティティ、リレーションシップ、オブジェクトエンティティ(車、色、赤))のコレクションである英語のウィキデータナレッジグラフを取得し、それをさまざまなエンティティサブグラフに変換して言語化しました。これは、で最も簡単に説明されます。画像:
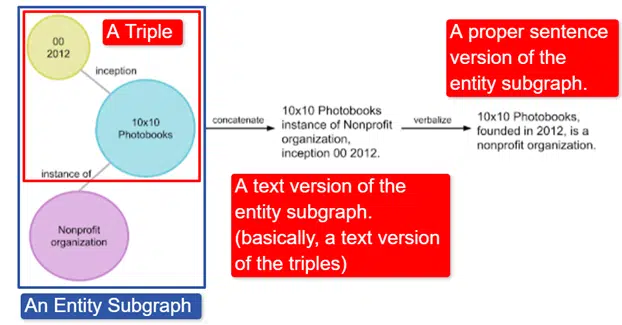
この画像では、次のように表示されます。
- トリプルは、個々の関係を表します。
- 中央エンティティに関連する複数のトリプルをマッピングするエンティティサブグラフ。
- エンティティサブグラフのテキストバージョン。
- 適切な文。
これは、他のモデルで使用して、事実を認識し、有毒な情報をフィルタリングするようにトレーニングするのに役立ちます。
Googleはコーパスをオープンソース化しており、GitHubで入手できます。 詳細については、説明を参照すると、その機能と構造を理解するのに役立ちます。
MUM
MUMは、2021年5月のGoogle I/Oでも発表されました。
それは革命的ですが、一見簡単に説明できます。
MUMはMultitaskU nified M odelの略で、マルチモーダルです。 これは、テスト、画像、ビデオなどのさまざまなコンテンツ形式を「理解」することを意味します。これにより、複数のモダリティから情報を取得し、応答することができます。
余談ですが、これはMultiModelアーキテクチャの最初の使用ではありません。 これは、2017年にGoogleによって最初に提示されました。
さらに、MUMは文字列ではなく物事で機能するため、言語を超えて情報を収集し、ユーザー自身で回答を提供できます。 これにより、特にインターネットに対応していない言語を話す人々にとって、情報アクセスの大幅な改善への扉が開かれますが、英語を話す人でさえ直接恩恵を受けるでしょう。
Googleが使用している例は、富士山に登りたいハイカーです。 最高のヒントや情報のいくつかは日本語で書かれている可能性があり、翻訳できたとしてもそれを表示する方法がわからないため、ユーザーは完全に利用できません。
MUMに関する重要な注意点は、モデルがコンテンツを理解するだけでなく、コンテンツを生成できることです。 そのため、ユーザーを結果に受動的に送信するのではなく、複数のソースからのデータの収集を容易にし、フィードバック(ページ、音声など)自体を提供できます。
これは、私を含め、多くの人にとってこのテクノロジーの懸念事項でもあるかもしれません。
他に機械学習が使用される場所
聞いたことがある主要なアルゴリズムのいくつかに触れただけで、オーガニック検索に大きな影響を与えていると思います。 しかし、これは機械学習が使用される場所の全体からはほど遠いものです。
たとえば、次のように尋ねることもできます。
- 広告では、自動入札戦略と広告自動化の背後にあるシステムを推進するものは何ですか?
- ニュースでは、システムはストーリーをグループ化する方法をどのように知っていますか?
- 画像では、システムはどのようにして特定のオブジェクトとオブジェクトのタイプを識別しますか?
- 電子メールでは、システムはどのようにスパムをフィルタリングしますか?
- 翻訳では、システムはどのようにして新しい単語やフレーズを学習しますか?
- ビデオでは、システムはどのビデオを次に推奨するかをどのように学習しますか?
これらの質問のすべてと、数千とは言わないまでも数百のすべてが同じ答えを持っています。
機械学習。
機械学習アルゴリズムとモデルの種類
次に、機械学習アルゴリズムとモデルの2つの監視レベル(教師あり学習と教師なし学習)について説明します。 私たちが見ているアルゴリズムのタイプと、それらを探す場所を理解することは重要です。
教師あり学習
簡単に言えば、教師あり学習により、アルゴリズムには完全にラベル付けされたトレーニングおよびテストデータが渡されます。
つまり、信頼できるデータでモデルをトレーニングするために、誰かが数千(または数百万)の例にラベルを付ける努力をしました。 たとえば、赤いシャツを着ている人のx枚の写真に赤いシャツのラベルを付けます。
教師あり学習は、分類と回帰の問題に役立ちます。 分類の問題はかなり簡単です。 何かがグループの一部であるかどうかを判断する。
簡単な例はGoogleフォトです。
グーグルは私とステージを分類しました。 彼らはこれらの写真のそれぞれに手動でラベルを付けていません。 ただし、モデルは、ステージの手動でラベル付けされたデータでトレーニングされています。 また、Googleフォトを使用したことのある人なら誰でも、写真とその中の人物を定期的に確認するように求められることを知っています。 私たちは手動ラベラーです。
ReCAPTCHAを使用したことがありますか? あなたがしていることを推測しますか? それは正しい。 あなたは定期的に機械学習モデルのトレーニングを手伝っています。
一方、回帰問題は、出力値にマップする必要のある一連の入力がある問題を処理します。
簡単な例は、平方フィート、寝室の数、浴室の数、海からの距離などを入力して、家の販売価格を見積もるシステムを考えることです。
さまざまな機能/信号を伝送し、問題のエンティティ(/サイト)に値を割り当てる必要がある他のシステムについて考えてみてください。
確かにもっと複雑で、さまざまな機能を提供する個々のアルゴリズムの膨大な配列を取り入れていますが、回帰は、検索のコア機能を駆動するアルゴリズムタイプの1つである可能性があります。
ここでは、半教師ありモデルに移行していると思われます。手動のラベル付け(品質評価者を考えてください)がいくつかの段階で行われ、システムで収集された信号によって、ユーザーの満足度が決定されます。結果セットは、プレイ中のモデルの調整と作成に使用されます。 。
教師なし学習
教師なし学習では、システムにラベルのないデータのセットが与えられ、システムがそれをどう処理するかを自分で決定するために残されます。
最終目標は指定されていません。 システムは、類似したアイテムをクラスター化したり、外れ値を探したり、相互関係を見つけたりする場合があります。
教師なし学習は、データが多く、どのように使用すべきかを事前に知ることができない、またはわからない場合に使用されます。
良い例はGoogleニュースかもしれません。
Googleは同様のニュース記事をクラスター化し、以前は存在しなかったニュース記事も表示します(したがって、それらはニュースです)。
これらのタスクは、主に(排他的ではありませんが)教師なしモデルによって実行するのが最適です。 以前のクラスタリングまたはサーフェシングがどの程度成功または失敗したかを「確認」したが、(以前のニュースのように)ラベルが付けられていない現在のデータにそれを完全に適用して決定を下すことができないモデル。
特に物事が拡大するにつれて、検索に関連するため、機械学習の非常に重要な領域です。
Google翻訳は別の良い例です。 英語の単語xがスペイン語の単語yと等しいことを理解するようにシステムが訓練された、以前は存在していた1対1の翻訳ではなく、両方の使用パターンを探し出し、半教師あり翻訳を改善する新しい手法-監視あり学習(一部のラベル付きデータとほとんどない)および監視なし学習。1つの言語から完全に未知の(システムにとって)言語に翻訳します。
上記のMUMでこれを見ましたが、他の論文にも存在し、モデルは良好です。
ほんの始まり
うまくいけば、これが機械学習のベースラインと、それが検索でどのように使用されるかを提供します。
私の将来の記事は、機械学習をどこでどのように見つけることができるかについてだけではありません(一部はそうなるでしょうが)。 また、より優れたSEOになるために使用できる機械学習の実用的なアプリケーションについても詳しく説明します。 心配しないでください。そのような場合は、コーディングを行い、一般的に使いやすいGoogle Colabを提供して、SEOやビジネスに関する重要な質問に答えられるようにします。
たとえば、直接機械学習モデルを使用して、サイト、コンテンツ、トラフィックなどの理解を深めることができます。 次の記事でその方法を説明します。 ティーザー:時系列予測。
この記事で表明された意見はゲスト著者の意見であり、必ずしも検索エンジンランドではありません。 スタッフの作者はここにリストされています。