
เยี่ยมชมเทคนิคการจัดทำดัชนีและการจัดอันดับคำหลักอีกครั้ง: 20 ปีต่อมา
เผยแพร่แล้ว: 2022-08-04เมื่อลูกโอ๊กที่จะกลายเป็นอุตสาหกรรม SEO เริ่มเติบโต การจัดทำดัชนีและการจัดอันดับที่เครื่องมือค้นหาต่างก็ใช้คำหลักล้วนๆ
เสิร์ชเอ็นจิ้นจะจับคู่คีย์เวิร์ดในการค้นหากับคีย์เวิร์ดในดัชนีขนานกับคีย์เวิร์ดที่ปรากฏบนหน้าเว็บ
เพจที่มีคะแนนความเกี่ยวข้องสูงสุดจะถูกจัดลำดับโดยใช้หนึ่งในสามเทคนิคการดึงข้อมูลที่เป็นที่นิยมมากที่สุด:
- โมเดลบูลีน
- แบบจำลองความน่าจะเป็น
- แบบจำลองอวกาศเวกเตอร์
แบบจำลองพื้นที่เวกเตอร์กลายเป็นเครื่องมือที่มีความเกี่ยวข้องมากที่สุดสำหรับเครื่องมือค้นหา
ฉันจะทบทวนคำอธิบายพื้นฐานและค่อนข้างง่ายของแบบจำลองคลาสสิกที่ฉันใช้เมื่อก่อนในบทความนี้ (เพราะยังคงมีความเกี่ยวข้องในการผสมผสานเครื่องมือค้นหา)
ระหว่างทาง เราจะกำจัดตำนานหนึ่งหรือสองเรื่อง – เช่น แนวคิดเรื่อง “ความหนาแน่นของคำหลัก” ของหน้าเว็บ มาส่งตัวนั้นเข้านอนกันเถอะ
คำสำคัญ: หนึ่งในคำที่ใช้บ่อยที่สุดในสารสนเทศศาสตร์ ถึงนักการตลาด – ความลึกลับที่ซ่อนอยู่
“คีย์เวิร์ดคืออะไร”
คุณไม่รู้หรอกว่าฉันได้ยินคำถามนั้นกี่ครั้งเมื่ออุตสาหกรรม SEO กำลังเกิดขึ้น และหลังจากที่ฉันให้คำอธิบายสั้น ๆ แล้ว คำถามต่อจากนี้ก็คือ “แล้ว คีย์เวิร์ด ของฉัน ล่ะ ไมค์”
จริงๆ แล้ว มันค่อนข้างยากที่จะอธิบายให้นักการตลาดทราบว่าคำหลักเฉพาะที่ใช้ในการค้นหาคือสิ่งที่เรียกหน้าเว็บที่เกี่ยวข้องในผลลัพธ์ของเครื่องมือค้นหา
และใช่ นั่นเกือบจะทำให้เกิดคำถามขึ้นอีกว่า: "คำถามคืออะไร ไมค์"
ทุกวันนี้ คำต่างๆ เช่น คีย์เวิร์ด คำค้นหา ดัชนี การจัดอันดับ และอื่นๆ เป็นเรื่องปกติในพจนานุกรมการตลาดดิจิทัล
อย่างไรก็ตาม ในฐานะ SEO ฉันเชื่อว่ามีประโยชน์อย่างมากที่จะเข้าใจว่าพวกเขามาจากที่ใด และทำไม และอย่างไร เงื่อนไขเหล่านั้นยังคงมีผลใช้บังคับได้มากเท่าที่พวกเขาเคยทำในสมัยก่อน
ศาสตร์แห่งการดึงข้อมูล (IR) เป็นส่วนย่อยภายใต้คำว่า "ปัญญาประดิษฐ์" แต่ IR เองยังประกอบด้วยชุดย่อยหลายชุด รวมถึงชุดย่อยของห้องสมุดและสารสนเทศศาสตร์
และนั่นคือจุดเริ่มต้นของเราสำหรับส่วนที่สองของช่องทางหน่วยความจำ SEO ของฉัน (ครั้งแรกของฉันในกรณีที่คุณพลาดคือ: เรารวบรวมข้อมูลเว็บมา 32 ปี: มีอะไรเปลี่ยนแปลงบ้าง?)
บทความต่อเนื่องชุดนี้อิงจากสิ่งที่ฉันเขียนในหนังสือเกี่ยวกับ SEO เมื่อ 20 ปีที่แล้ว โดยสังเกตจากความทันสมัยตลอดหลายปีที่ผ่านมาและเปรียบเทียบกับที่ที่เราอยู่ทุกวันนี้
หญิงชราตัวน้อยในห้องสมุด
ดังนั้น เมื่อเน้นว่ามีองค์ประกอบของบรรณารักษศาสตร์ภายใต้แบนเนอร์การดึงข้อมูล ให้ฉันอธิบายให้ได้ว่าองค์ประกอบเหล่านี้อยู่ในการค้นหาเว็บอย่างไร
ดูเหมือนว่าบรรณารักษ์ส่วนใหญ่จะระบุว่าเป็นหญิงชราตัวน้อย ปรากฏเป็นอย่างนั้นอย่างแน่นอนเมื่อฉันสัมภาษณ์นักวิทยาศาสตร์ชั้นนำหลายคนในสาขาใหม่ที่เกิดขึ้นของ "web" Information Retrial (IR) เมื่อหลายปีก่อน
Brian Pinkerton ผู้ประดิษฐ์ WebCrawler พร้อมด้วย Andrei Broder รองประธานฝ่ายเทคโนโลยีและหัวหน้านักวิทยาศาสตร์ของ Alta Vista ซึ่งเป็นเสิร์ชเอ็นจิ้นอันดับหนึ่งก่อน Google และแน่นอน Craig Silverstein ผู้อำนวยการฝ่ายเทคโนโลยีของ Google (และที่โดดเด่นคือพนักงาน Google อันดับหนึ่ง) ล้วนอธิบายไว้ งานของพวกเขาในสาขาใหม่นี้โดยพยายามให้เสิร์ชเอ็นจิ้นเลียนแบบ “หญิงชราตัวน้อยในห้องสมุด”
ห้องสมุดตั้งอยู่บนแนวคิดของบัตรดัชนี ซึ่งมีจุดประสงค์เพื่อพยายามจัดระเบียบและจำแนกสัตว์ พืช และแร่ธาตุที่รู้จักทั้งหมดในโลก
บัตรดัชนีเป็นแกนหลักของระบบห้องสมุดทั้งหมด โดยจัดทำดัชนีข้อมูลจำนวนมหาศาลและหลากหลาย
นอกเหนือจากชื่อผู้แต่ง ชื่อหนังสือ หัวข้อเรื่องและ "คำดัชนี" ที่โดดเด่น (หรือที่รู้จักว่า คำหลัก) ฯลฯ บัตรดัชนีก็จะมีตำแหน่งของหนังสือด้วย และหลังจากนั้นไม่นาน “บรรณารักษ์หญิงชราตัวน้อย” เมื่อคุณถามเธอเกี่ยวกับหนังสือเล่มใดเล่มหนึ่ง จะสามารถชี้ไปที่ส่วนต่างๆ ของห้องสมุดได้โดยสัญชาตญาณเท่านั้น แต่ยังอาจถึงขั้นวางหนังสือไว้ด้วย วิธีการดึงข้อมูลอย่างรวดเร็ว
อย่างไรก็ตาม เมื่อฉันอธิบายความคล้ายคลึงของระบบการจัดทำดัชนีประเภทนั้นที่เครื่องมือค้นหาเช่นเดียวกับเมื่อหลายปีก่อน ฉันต้องเพิ่มคำเตือนที่ยังคงเป็นสิ่งสำคัญที่ต้องเข้าใจ:
“เสิร์ชเอ็นจิ้นที่ใหญ่ที่สุดคือดัชนีที่อิงตามลักษณะที่คล้ายกับของห้องสมุด เมื่อจัดเก็บเว็บจำนวนมากไว้ในดัชนีจำนวนมาก พวกเขาจำเป็นต้องส่งคืนเอกสารที่เกี่ยวข้องอย่างรวดเร็วโดยเทียบกับคำหลักหรือวลีที่ระบุ แต่ความผันแปรของหน้าเว็บในแง่ขององค์ประกอบ คุณภาพ และเนื้อหา นั้นยิ่งใหญ่กว่าขนาดของข้อมูลดิบเสียอีก เว็บโดยรวมไม่มีโครงสร้างที่เป็นหนึ่งเดียว โดยรูปแบบต่างๆ มากมายในรูปแบบของการเขียนและเนื้อหาที่กว้างและซับซ้อนกว่าในคอลเล็กชันเอกสารข้อความแบบดั้งเดิม ซึ่งทำให้แทบเป็นไปไม่ได้เลยที่เสิร์ชเอ็นจิ้นจะใช้เทคนิคแบบเดิมที่ใช้ในห้องสมุด ระบบการจัดการฐานข้อมูล และการดึงข้อมูลอย่างเข้มงวด”
อย่างหลีกเลี่ยงไม่ได้ สิ่งที่เกิดขึ้นกับคำหลักและวิธีที่เราเขียนสำหรับเว็บคือการเกิดขึ้นของสาขาการสื่อสารใหม่
ตามที่ฉันอธิบายไว้ในหนังสือ HTML อาจถูกมองว่าเป็นประเภทภาษาใหม่และควรได้รับการปฏิบัติเช่นนี้ในการศึกษาภาษาศาสตร์ในอนาคต เอกสารไฮเปอร์เท็กซ์มีอะไรมากกว่าที่จะมีในเอกสาร "ข้อความธรรมดา" และนั่นให้ข้อบ่งชี้มากขึ้นว่าหน้าเว็บหนึ่งๆ นั้นเกี่ยวกับอะไรเมื่อมนุษย์อ่านมัน เช่นเดียวกับข้อความที่ถูกวิเคราะห์ จำแนก และจัดหมวดหมู่ผ่านการทำเหมืองข้อความและการดึงข้อมูลโดยเสิร์ชเอ็นจิ้น
บางครั้งฉันยังได้ยิน SEO ที่อ้างถึงหน้าเว็บ "เครื่องอ่าน" ของเครื่องมือค้นหา แต่คำนั้นเป็นมากกว่าการแนะนำระบบ "ข้อมูลที่มีโครงสร้าง" ที่ค่อนข้างใหม่
อย่างที่ฉันยังต้องอธิบายอยู่บ่อยๆ มนุษย์ที่อ่านหน้าเว็บและเครื่องมือค้นหาข้อความและดึงข้อมูล "เกี่ยวกับ" หน้านั้นไม่ใช่สิ่งเดียวกับที่มนุษย์อ่านหน้าเว็บและเครื่องมือค้นหาที่ถูก "ป้อน" ข้อมูลที่มีโครงสร้าง
ตัวอย่างที่จับต้องได้ที่ดีที่สุดที่ฉันพบคือการเปรียบเทียบระหว่างหน้าเว็บ HTML สมัยใหม่ที่มีข้อมูลที่มีโครงสร้างที่ "เครื่องอ่านได้" แทรกและหนังสือเดินทางสมัยใหม่ ดูหน้ารูปภาพบนหนังสือเดินทางของคุณ แล้วคุณจะเห็นส่วนหลักหนึ่งส่วนที่มีรูปภาพและข้อความสำหรับให้มนุษย์อ่าน และส่วนแยกต่างหากที่ด้านล่างของหน้า ซึ่งสร้างขึ้นสำหรับการอ่านด้วยเครื่องโดยเฉพาะโดยการปัดหรือสแกน
แก่นสาร หน้าเว็บสมัยใหม่มีโครงสร้างแบบเดียวกับหนังสือเดินทางสมัยใหม่ น่าสนใจเมื่อ 20 ปีที่แล้ว ฉันได้อ้างอิงการรวม man/machine กับ factoid เล็กน้อยนี้:
“ในปี ค.ศ. 1747 แพทย์และนักปรัชญาชาวฝรั่งเศสชื่อ Julien Offroy de la Metrie ได้ตีพิมพ์ผลงานชิ้นสำคัญชิ้นหนึ่งในประวัติศาสตร์ของความคิด เขาให้ชื่อว่า L'HOMME MACHINE ซึ่งแปลว่า "มนุษย์ เครื่องจักร" ได้ดีที่สุด บ่อยครั้ง คุณจะได้ยินวลี 'ของมนุษย์และเครื่องจักร' และนี่คือแนวคิดหลักของปัญญาประดิษฐ์”
ฉันได้เน้นย้ำถึงความสำคัญของข้อมูลที่มีโครงสร้างในบทความที่แล้ว และหวังว่าจะเขียนบางอย่างให้คุณ ซึ่งฉันเชื่อว่าจะเป็นประโยชน์อย่างมากในการทำความเข้าใจความสมดุลระหว่างการอ่านของมนุษย์และการอ่านด้วยเครื่อง ฉันได้ทำให้มันง่ายขึ้นโดยสิ้นเชิงในปี 2002 เพื่อให้เหตุผลพื้นฐาน:
- ข้อมูล: การแสดงข้อเท็จจริงหรือความคิดในลักษณะที่เป็นทางการ ซึ่งสามารถสื่อสารหรือจัดการโดยกระบวนการบางอย่างได้
- ข้อมูล: ความหมายที่มนุษย์กำหนดให้กับข้อมูลโดยใช้อนุสัญญาที่รู้จักซึ่งใช้ในการเป็นตัวแทนของข้อมูล
ดังนั้น:
- ข้อมูลเกี่ยวข้องกับข้อเท็จจริงและเครื่องจักร
- ข้อมูลเกี่ยวข้องกับความหมายและมนุษย์
มาพูดถึงลักษณะของข้อความกันสักครู่แล้วฉันจะอธิบายว่าข้อความสามารถแสดงเป็นข้อมูลได้อย่างไรในสิ่งที่ "เข้าใจผิดบ้าง" (เราจะพูด) ในอุตสาหกรรม SEO ที่เรียกว่า vector space model
คำหลักที่สำคัญที่สุดในดัชนีเครื่องมือค้นหาเทียบกับคำที่นิยมมากที่สุด
เคยได้ยินกฎของ Zipf หรือไม่?
ตั้งชื่อตามศาสตราจารย์ด้านภาษาศาสตร์ของฮาร์วาร์ด จอร์จ คิงสลีย์ ซิปฟ์ โดยทำนายปรากฏการณ์ที่เมื่อเราเขียน เราใช้คำที่คุ้นเคยซึ่งมีความถี่สูง
Zipf กล่าวว่ากฎหมายของเขามีพื้นฐานมาจากตัวทำนายหลักของพฤติกรรมมนุษย์: พยายามลดความพยายามให้น้อยที่สุด ดังนั้น กฎหมายของ Zipf จึงมีผลบังคับใช้กับเกือบทุกสาขาที่เกี่ยวข้องกับการผลิตของมนุษย์
ซึ่งหมายความว่าเรายังมีความสัมพันธ์ที่จำกัดระหว่างอันดับและความถี่ในภาษาธรรมชาติ
เอกสารข้อความขนาดใหญ่ส่วนใหญ่มีลักษณะทางสถิติที่คล้ายคลึงกัน ความรู้เกี่ยวกับสถิติเหล่านี้มีประโยชน์เนื่องจากมีอิทธิพลต่อประสิทธิภาพและประสิทธิภาพของโครงสร้างข้อมูลที่ใช้ในการจัดทำดัชนีเอกสาร โมเดลการดึงข้อมูลจำนวนมากพึ่งพาพวกเขา
มีรูปแบบของเหตุการณ์ที่เกิดขึ้นในวิธีที่เราเขียน โดยทั่วไปเราจะมองหาวิธีที่ง่ายที่สุด สั้นที่สุด เกี่ยวข้องน้อยที่สุด และเร็วที่สุดเท่าที่จะเป็นไปได้ ความจริงก็คือ เราแค่ใช้คำง่ายๆ เดิมๆ ซ้ำแล้วซ้ำเล่า
ตัวอย่างเช่น เมื่อหลายปีก่อน ฉันพบสถิติบางอย่างจากการทดลองที่นักวิทยาศาสตร์เก็บคอลเล็กชัน 131MB (ซึ่งเป็นข้อมูลขนาดใหญ่ในตอนนั้น) จากบทความในหนังสือพิมพ์ 46,500 บทความ (19 ล้านครั้ง)
นี่คือข้อมูลสำหรับคำ 10 อันดับแรกและจำนวนคำที่ใช้ในคลังข้อมูลนี้ คุณจะได้รับประเด็นอย่างรวดเร็ว ฉันคิดว่า:
ความถี่ของคำ
ที่: 1130021
จาก 547311
ถึง 516635
464736
ใน 390819
และ 387703
ว่า 204351
สำหรับปี 199340
คือ 152483
กล่าว 148302
โปรดจำไว้ว่า บทความทั้งหมดที่รวมอยู่ในคลังบทความเขียนขึ้นโดยนักข่าวมืออาชีพ แต่ถ้าคุณดูคำที่ใช้บ่อยที่สุดสิบอันดับแรก คุณแทบจะไม่สามารถสร้างประโยคที่สมเหตุสมผลได้แม้แต่ประโยคเดียว
เนื่องจากคำทั่วไปเหล่านี้เกิดขึ้นบ่อยครั้งในภาษาอังกฤษ เครื่องมือค้นหาจะเพิกเฉยต่อคำเหล่านี้ว่าเป็น "คำหยุด" หากคำที่นิยมใช้กันมากที่สุดไม่ได้ให้คุณค่ากับระบบการจัดทำดัชนีอัตโนมัติ คำไหนทำ?
ดังที่ได้กล่าวไปแล้ว มีงานมากมายในด้านระบบการดึงข้อมูล (IR) มีการใช้วิธีการทางสถิติอย่างกว้างขวางเนื่องจากรูปแบบข้อความกับแบบจำลองข้อมูลไม่เหมาะสมตามตรรกะที่เป็นทางการ (เช่น ฐานข้อมูลเชิงสัมพันธ์)
ดังนั้น แทนที่จะกำหนดให้ผู้ใช้ต้องคาดการณ์คำที่ถูกต้องและการรวมกันของคำที่อาจปรากฏในเอกสารที่น่าสนใจ IR ทางสถิติช่วยให้ผู้ใช้ป้อนสตริงของคำที่มีแนวโน้มว่าจะปรากฏในเอกสารได้
จากนั้นระบบจะพิจารณาความถี่ของคำเหล่านี้ในชุดข้อความ และในเอกสารแต่ละฉบับ เพื่อกำหนดว่าคำใดน่าจะเป็นเบาะแสของความเกี่ยวข้องที่ดีที่สุด คะแนนจะถูกคำนวณสำหรับเอกสารแต่ละฉบับตามคำที่อยู่ในนั้นและจะดึงเอกสารคะแนนสูงสุดออกมา
ฉันโชคดีที่ได้สัมภาษณ์นักวิจัยชั้นนำในด้าน IR เมื่อค้นคว้าตัวเองสำหรับหนังสือเล่มนี้ในปี 2544 ในเวลานั้น Andrei Broder เป็นหัวหน้านักวิทยาศาสตร์ของ Alta Vista (ปัจจุบันเป็นวิศวกรที่โดดเด่นของ Google) และเรากำลังคุยกันถึงหัวข้อ ของ "เวกเตอร์เทอม" และฉันถามว่าเขาช่วยอธิบายง่ายๆ ได้ไหมว่ามันคืออะไร

เขาอธิบายให้ฉันฟังว่า เมื่อคำว่า "การถ่วงน้ำหนัก" หมายถึงความสำคัญในดัชนี เขาอาจสังเกตเห็นคำว่า "ของ" หลายล้านครั้งในคลังข้อมูล นี่เป็นคำที่จะไม่มี "น้ำหนัก" เลย เขากล่าว แต่ถ้าเขาเห็นบางอย่างเช่นคำว่า "เฮโมโกลบิน" ซึ่งเป็นคำที่หายากกว่ามากในคลังข้อมูล คำนี้ก็จะมีน้ำหนักเพิ่มขึ้น
ฉันต้องการย้อนเวลากลับไปที่นี่ ก่อนที่ฉันจะอธิบายว่าดัชนีถูกสร้างขึ้นมาอย่างไร และปัดเป่าตำนานอื่นที่ยังคงอยู่ในช่วงหลายปีที่ผ่านมา และนั่นคือสิ่งที่หลายคนเชื่อว่า Google (และเครื่องมือค้นหาอื่นๆ) กำลังดาวน์โหลดหน้าเว็บของคุณและจัดเก็บไว้ในฮาร์ดไดรฟ์
ไม่เลย เรามีสถานที่ที่จะทำอย่างนั้นอยู่แล้ว เรียกว่าเวิลด์ไวด์เว็บ
ใช่ Google จะเก็บสแนปชอต "แคช" ของหน้าไว้เพื่อให้สามารถดึงข้อมูลได้อย่างรวดเร็ว แต่เมื่อเนื้อหาของหน้านั้นเปลี่ยนแปลง ครั้งต่อไปที่มีการรวบรวมข้อมูลหน้า เวอร์ชันแคชก็จะเปลี่ยนไปเช่นกัน
นั่นเป็นเหตุผลที่คุณไม่สามารถหาสำเนาของหน้าเว็บเก่าของคุณที่ Google ได้ สำหรับสิ่งนั้น ทรัพยากรจริงเพียงอย่างเดียวของคุณคือ Internet Archive (หรือที่รู้จักว่า The Wayback Machine)
อันที่จริง เมื่อหน้าเว็บของคุณถูกรวบรวมข้อมูล หน้าเว็บของคุณจะถูกรื้อถอนโดยพื้นฐาน ข้อความถูกแยกวิเคราะห์ (แยก) จากเอกสาร
เอกสารแต่ละฉบับจะได้รับตัวระบุของตนเองพร้อมกับรายละเอียดของตำแหน่ง (URL) และ "ข้อมูลดิบ" จะถูกส่งต่อไปยังโมดูลตัวทำดัชนี คำ/ข้อกำหนดจะถูกบันทึกด้วย ID เอกสารที่เกี่ยวข้องซึ่งปรากฏ
นี่เป็นตัวอย่างง่ายๆ โดยใช้เอกสารสองชุดและข้อความในเอกสารที่ฉันสร้างเมื่อ 20 ปีที่แล้ว
เรียกคืนการสร้างดัชนี
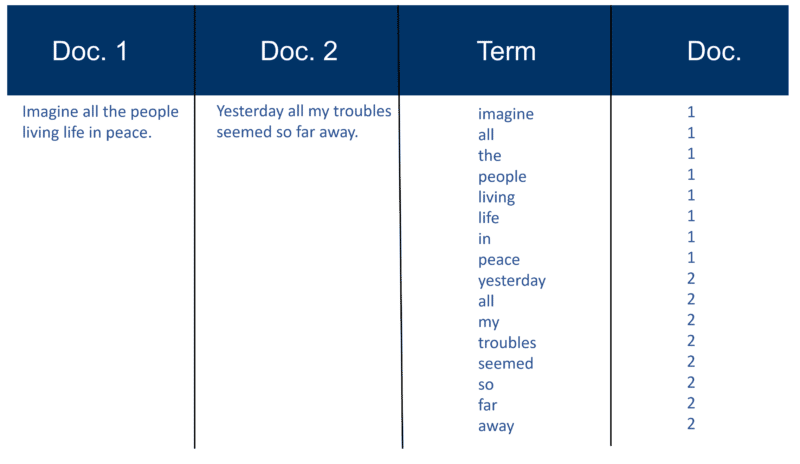
หลังจากแยกวิเคราะห์เอกสารทั้งหมดแล้ว ไฟล์กลับด้านจะถูกจัดเรียงตามเงื่อนไข:
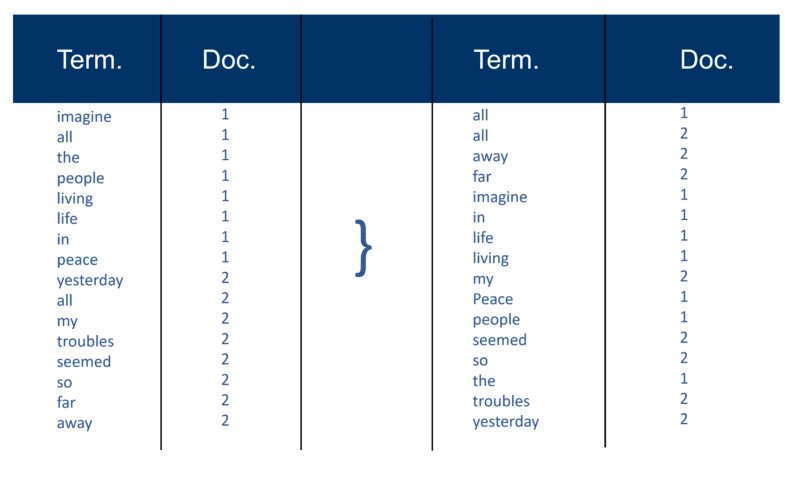
ในตัวอย่างของฉัน สิ่งนี้ดูค่อนข้างง่ายในช่วงเริ่มต้นของกระบวนการ แต่การโพสต์ (ดังที่ทราบในเงื่อนไขการดึงข้อมูล) ไปยังดัชนีจะไปในเอกสารทีละรายการ อีกครั้ง ด้วยเอกสารนับล้าน คุณสามารถจินตนาการถึงจำนวนพลังในการประมวลผลที่จำเป็นในการเปลี่ยนสิ่งนี้ให้เป็น 'มุมมองที่ชาญฉลาดเกี่ยวกับคำศัพท์' ขนาดใหญ่ ซึ่งถูกทำให้เรียบง่ายขึ้นด้านบน ขั้นแรกทีละเทอม แล้วตามด้วย Doc ภายในแต่ละเทอม
คุณจะสังเกตเห็นการอ้างอิงถึง "ล้านเอกสาร" ของฉันเมื่อหลายปีก่อน แน่นอนว่าทุกวันนี้เราอยู่ในพันล้าน (ถึงล้านล้าน) ในคำอธิบายพื้นฐานเกี่ยวกับวิธีการสร้างดัชนี ฉันได้ดำเนินการต่อไป:
เสิร์ชเอ็นจิ้นแต่ละเครื่องจะสร้างพจนานุกรมที่กำหนดเองขึ้นมาเอง (หรือพจนานุกรมตามที่เป็นอยู่ – จำไว้ว่าหน้าเว็บจำนวนมากไม่ได้เขียนเป็นภาษาอังกฤษ) ซึ่งจะต้องมี 'คำศัพท์' ใหม่ทุกคำที่ค้นพบหลังจากการรวบรวมข้อมูล (ลองคิดดูว่าเมื่อใช้ โปรแกรมประมวลผลคำ เช่น Microsoft Word คุณมักจะได้รับตัวเลือกในการเพิ่มคำลงในพจนานุกรมที่คุณกำหนดเอง เช่น สิ่งที่ไม่มีในพจนานุกรมภาษาอังกฤษมาตรฐาน) เมื่อเครื่องมือค้นหามีดัชนี 'ใหญ่' คำบางคำจะมีความสำคัญมากกว่าคำอื่นๆ ดังนั้นแต่ละเทอมจึงควรมีน้ำหนัก (ค่า) ของตัวเอง ปัจจัยการให้น้ำหนักจำนวนมากขึ้นอยู่กับคำศัพท์นั้นเอง แน่นอนว่าสิ่งนี้ค่อนข้างตรงไปตรงมาเมื่อคุณคิดถึงมัน ดังนั้นน้ำหนักที่มากขึ้นจะถูกมอบให้กับคำที่มีจำนวนเหตุการณ์มากขึ้น แต่น้ำหนักนี้จะเพิ่มขึ้นตาม 'ความหายาก' ของคำศัพท์ทั่วทั้งคลังข้อมูล ตัวทำดัชนียังสามารถให้ 'น้ำหนัก' มากขึ้นกับคำที่ปรากฏในบางตำแหน่งในเอกสารได้ คำที่ปรากฏในแท็กชื่อ <title> มีความสำคัญมาก คำที่อยู่ในแท็กพาดหัว <h1> หรือคำที่เป็นตัวหนา <b> บนหน้าอาจมีความเกี่ยวข้องมากกว่า คำที่ปรากฏใน anchor text ของลิงก์ในหน้า HTML หรือใกล้เคียงนั้นถือว่าสำคัญมาก คำที่ปรากฏในแท็กข้อความ <alt> พร้อมรูปภาพจะถูกบันทึกไว้ เช่นเดียวกับคำที่ปรากฏในเมตาแท็ก
นอกเหนือจากข้อความต้นฉบับ "Modern Information Retrieval" ที่เขียนโดยนักวิทยาศาสตร์ Gerard Salton (ถือได้ว่าเป็นบิดาแห่งการดึงข้อมูลสมัยใหม่) ฉันมีแหล่งข้อมูลอื่นอีกจำนวนหนึ่งในวันที่ตรวจสอบข้างต้น ทั้ง Brian Pinkerton และ Michael Maudlin (ผู้ประดิษฐ์เครื่องมือค้นหา WebCrawler และ Lycos ตามลำดับ) ได้ให้รายละเอียดเกี่ยวกับวิธีการใช้ "แนวทาง Salton แบบคลาสสิก" และทั้งสองทำให้ฉันตระหนักถึงข้อจำกัด
ไม่เพียงเท่านั้น Larry Page และ Sergey Brin ยังเน้นย้ำถึงสิ่งเดียวกันในเอกสารต้นฉบับที่พวกเขาเขียนเมื่อเปิดตัวต้นแบบของ Google ฉันกลับมาที่เรื่องนี้เพราะมันเป็นสิ่งสำคัญในการช่วยปัดเป่าตำนานอื่น
แต่ก่อนอื่น นี่คือวิธีที่ฉันอธิบาย "แนวทาง Salton แบบคลาสสิก" ในปี 2545 อย่าลืมสังเกตการอ้างอิงถึง "คู่น้ำหนักระยะ"
เมื่อเสิร์ชเอ็นจิ้นได้สร้าง 'ดัชนีขนาดใหญ่' แล้ว โมดูลตัวทำดัชนีจะวัด 'ความถี่ของคำ' (tf) ของคำในเอกสารเพื่อรับ 'ความหนาแน่นของคำ' จากนั้นจึงวัด 'ความถี่ของเอกสารผกผัน' (idf) ซึ่ง คือการคำนวณความถี่ของเงื่อนไขในเอกสาร จำนวนเอกสารทั้งหมด จำนวนเอกสารที่มีเงื่อนไข ด้วยการคำนวณเพิ่มเติมนี้ ขณะนี้เอกสารแต่ละฉบับสามารถดูเป็นเวกเตอร์ของค่า tf x idf (ค่าไบนารีหรือตัวเลขที่สัมพันธ์กันโดยตรงหรือโดยอ้อมกับคำในเอกสาร) สิ่งที่คุณมีคือคู่น้ำหนักระยะ คุณสามารถสลับเป็น: เอกสารมีรายการคำที่ถ่วงน้ำหนัก คำมีรายการเอกสารถ่วงน้ำหนัก (คู่น้ำหนักคำ)
แบบจำลองอวกาศเวกเตอร์
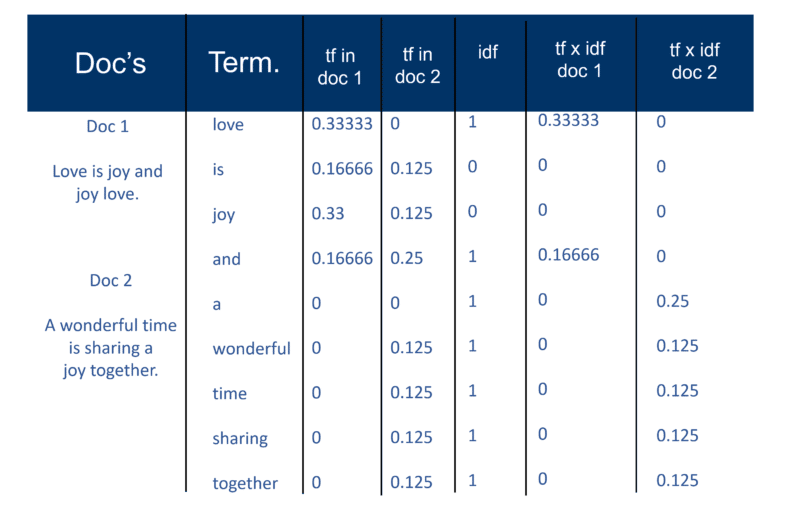
ขณะนี้เอกสารเป็นเวกเตอร์ที่มีองค์ประกอบเดียวสำหรับแต่ละคำ สิ่งที่สร้างขึ้นคือ 'เวคเตอร์สเปซ' ที่ซึ่งเอกสารทั้งหมดอาศัยอยู่ แต่อะไรคือประโยชน์ของการสร้างจักรวาลของ Docs ซึ่งตอนนี้ล้วนมีขนาดเท่านี้?
ด้วยวิธีนี้ หาก Doc 'd' (ตัวอย่าง) เป็นเวกเตอร์ ก็จะง่ายต่อการค้นหาสิ่งอื่นๆ ที่คล้ายกัน และยังสามารถค้นหาเวกเตอร์ที่อยู่ใกล้ๆ ได้อีกด้วย
จากสัญชาตญาณ คุณสามารถระบุได้ว่าเอกสารซึ่งอยู่ใกล้กันในปริภูมิเวกเตอร์ พูดถึงสิ่งเดียวกัน การทำเช่นนี้ เครื่องมือค้นหาจะสามารถสร้างคลัสเตอร์ของคำหรือเอกสาร และเพิ่มวิธีการชั่งน้ำหนักอื่นๆ ได้
อย่างไรก็ตาม ประโยชน์หลักของการใช้เวกเตอร์คำสำหรับเครื่องมือค้นหาคือ เครื่องมือค้นหาสามารถถือว่าข้อความค้นหานั้นเป็นเอกสารที่สั้นมาก ด้วยวิธีนี้ การสืบค้นข้อมูลจะกลายเป็นเวกเตอร์ในพื้นที่เวกเตอร์เดียวกัน และเครื่องมือสืบค้นข้อมูลสามารถวัดความใกล้ชิดของเอกสารแต่ละรายการ
Vector Space Model อนุญาตให้ผู้ใช้ค้นหาเครื่องมือค้นหาสำหรับ "แนวคิด" มากกว่าการค้นหา "คำศัพท์" ล้วนๆ ดังที่คุณเห็นในที่นี้ แม้กระทั่งเมื่อ 20 ปีที่แล้ว แนวคิดเกี่ยวกับแนวคิดและหัวข้อต่างจากการใช้คีย์เวิร์ดเพียงอย่างเดียวก็มีบทบาทอย่างมาก
ตกลง มาจัดการเรื่อง "ความหนาแน่นของคำหลัก" กัน คำว่า "ความหนาแน่น" ปรากฏในคำอธิบายว่าโมเดลพื้นที่เวกเตอร์ทำงานอย่างไร แต่เมื่อใช้กับการคำนวณทั่วทั้งคลังเอกสารเท่านั้น ไม่ใช่ในหน้าเดียว บางทีการอ้างอิงที่ทำให้ SEO จำนวนมากเริ่มใช้ตัววิเคราะห์ความหนาแน่นของคำหลักในหน้าเดียว
ฉันยังสังเกตเห็นในช่วงหลายปีที่ผ่านมาว่า SEO จำนวนมากซึ่งค้นพบโมเดลเวคเตอร์สเปซมักจะลองใช้การถ่วงน้ำหนักแบบคลาสสิก tf x idf แต่นั่นมีโอกาสน้อยกว่ามาก โดยเฉพาะอย่างยิ่งที่ Google ตามที่ผู้ก่อตั้ง Larry Page และ Sergey Brin ระบุไว้ในเอกสารต้นฉบับเกี่ยวกับวิธีการทำงานของ Google พวกเขาเน้นย้ำถึงคุณภาพของผลลัพธ์ที่ไม่ดีเมื่อใช้โมเดลคลาสสิกเพียงอย่างเดียว:
“ตัวอย่างเช่น โมเดลพื้นที่เวกเตอร์มาตรฐานพยายามส่งคืนเอกสารที่ใกล้เคียงกับการสืบค้นมากที่สุด เนื่องจากทั้งข้อความค้นหาและเอกสารเป็นเวกเตอร์ที่กำหนดโดยการเกิดคำ บนเว็บ กลยุทธ์นี้มักจะส่งคืนเอกสารสั้นๆ ที่เป็นเพียงข้อความค้นหาพร้อมคำไม่กี่คำ”
มีหลายรูปแบบที่พยายามหลีกเลี่ยง 'ความแข็งแกร่ง' ของ Vector Space Model และตลอดหลายปีที่ผ่านมาด้วยความก้าวหน้าของปัญญาประดิษฐ์และแมชชีนเลิร์นนิง มีแนวทางที่หลากหลายซึ่งสามารถคำนวณน้ำหนักของคำและเอกสารเฉพาะในดัชนีได้
คุณอาจใช้เวลาหลายปีในการพยายามค้นหาว่าเสิร์ชเอ็นจิ้นใดใช้สูตรใด นับประสา Google (แม้ว่าคุณจะแน่ใจได้ว่าพวกเขาไม่ได้ใช้สูตรใดดังที่ฉันได้กล่าวไปแล้ว) ดังนั้น เมื่อคำนึงถึงสิ่งนี้ มันควรขจัดตำนานที่พยายามจัดการความหนาแน่นของคำหลักของหน้าเว็บเมื่อคุณสร้างมัน เป็นความพยายามที่สูญเปล่าไปบ้าง
แก้ปัญหาความอุดมสมบูรณ์
เครื่องมือค้นหารุ่นแรกอาศัยปัจจัยในหน้าสำหรับการจัดอันดับเป็นอย่างมาก
แต่ปัญหาที่คุณใช้เทคนิคการจัดอันดับตามคำหลักล้วนๆ (นอกเหนือจากที่ฉันเพิ่งพูดถึงเกี่ยวกับ Google ตั้งแต่วันแรก) เป็นสิ่งที่เรียกว่า "ปัญหาความอุดมสมบูรณ์" ซึ่งถือว่าเว็บเติบโตแบบทวีคูณทุกวันและการเติบโตแบบทวีคูณในเอกสารที่มีเนื้อหาเหมือนกัน คีย์เวิร์ด
และนั่นทำให้เกิดคำถามในสไลด์นี้ซึ่งฉันใช้มาตั้งแต่ปี 2002:

คุณสามารถสรุปได้ว่าวาทยกรของวงออร์เคสตราซึ่งจัดการและเล่นบทนี้มาหลายปีกับวงออเคสตราจำนวนมากจะเป็นผู้มีอำนาจมากที่สุด แต่การทำงานเฉพาะกับเทคนิคการจัดอันดับคำหลักเท่านั้น ก็มีโอกาสที่นักศึกษาดนตรีจะเป็นผลลัพธ์อันดับหนึ่ง
คุณจะแก้ปัญหานั้นอย่างไร?
คำตอบคือการวิเคราะห์ไฮเปอร์ลิงก์ (หรือที่รู้จักว่าลิงก์ย้อนกลับ)
ในงวดหน้า ฉันจะอธิบายว่าคำว่า "ผู้มีอำนาจ" ป้อนคำศัพท์ IR และ SEO อย่างไร และฉันยังจะอธิบายแหล่งที่มาดั้งเดิมของสิ่งที่เรียกว่า EAT และสิ่งที่อ้างอิงตามจริงด้วย
ก่อนหน้านั้น – สบายดี อยู่อย่างปลอดภัย และจดจำความสุขที่มีในการพูดคุยเกี่ยวกับการทำงานภายในของเครื่องมือค้นหา!
ความคิดเห็นที่แสดงในบทความนี้เป็นความคิดเห็นของผู้เขียนรับเชิญและไม่จำเป็นต้องเป็น Search Engine Land ผู้เขียนพนักงานอยู่ที่นี่