
إعادة النظر في تقنيات تصنيف الكلمات الرئيسية والفهرسة: بعد مرور 20 عامًا
نشرت: 2022-08-04عندما بدأت الجوزة التي ستصبح صناعة تحسين محركات البحث في النمو ، كانت الفهرسة والتصنيف في محركات البحث يعتمدان فقط على الكلمات الرئيسية.
سيطابق محرك البحث الكلمات الرئيسية في استعلام مع الكلمات الرئيسية الموجودة في فهرسه الموازي للكلمات الرئيسية التي تظهر على صفحة ويب.
سيتم ترتيب الصفحات ذات أعلى درجة صلة بالترتيب باستخدام إحدى تقنيات الاسترجاع الثلاثة الأكثر شيوعًا:
- نموذج منطقي
- النموذج الاحتمالي
- نموذج الفضاء المتجه
أصبح نموذج الفضاء المتجه هو الأكثر ملاءمة لمحركات البحث.
سأقوم بإعادة النظر في التفسير الأساسي والبسيط إلى حد ما للنموذج الكلاسيكي الذي استخدمته في اليوم في هذه المقالة (لأنه لا يزال وثيق الصلة بمزيج محرك البحث).
على طول الطريق ، سنبدد أسطورة أو اثنتين - مثل فكرة "كثافة الكلمات الرئيسية" لصفحة الويب. دعونا نضع هذا في الفراش مرة واحدة وإلى الأبد.
الكلمة الرئيسية: واحدة من أكثر الكلمات استخدامًا في علم المعلومات ؛ للمسوقين - لغز يكتنفه
"ما هي الكلمة الرئيسية؟"
ليس لديك أي فكرة عن عدد المرات التي سمعت فيها عن هذا السؤال عندما كانت صناعة تحسين محركات البحث في الظهور. وبعد أن قدمت شرحًا موجزًا ، سيكون سؤال المتابعة: "إذن ، ما هي كلماتي الرئيسية يا مايك؟"
بصراحة ، كان من الصعب جدًا محاولة التوضيح للمسوقين أن الكلمات الرئيسية المحددة المستخدمة في استعلام ما هي التي أدت إلى ظهور صفحات الويب المقابلة في نتائج محرك البحث.
ونعم ، من شبه المؤكد أن هذا سيثير سؤالًا آخر: "ما هو الاستعلام ، مايك؟"
اليوم ، أصبحت مصطلحات مثل الكلمات الرئيسية والاستعلام والفهرس والترتيب وكل الأشياء الباقية شائعة في قاموس التسويق الرقمي.
ومع ذلك ، بصفتي أحد مُحسّنات محرّكات البحث (SEO) ، أعتقد أنه من المفيد جدًا فهم من أين تم استخلاصهم ولماذا وكيف لا تزال هذه الشروط سارية الآن بقدر ما كانت تنطبق في اليوم.
علم استرجاع المعلومات (IR) هو مجموعة فرعية تحت مظلة مصطلح "الذكاء الاصطناعي". لكن IR نفسه يتألف أيضًا من عدة مجموعات فرعية ، بما في ذلك مجموعة علوم المكتبات والمعلومات.
وهذه هي نقطة انطلاقنا لهذا الجزء الثاني من حارة ذاكرة تحسين محركات البحث. (كان أول ما لدي ، في حال فاتتك ، هو: لقد قمنا بالزحف إلى الويب لمدة 32 عامًا: ما الذي تغير؟)
تستند هذه السلسلة المستمرة من المقالات إلى ما كتبته في كتاب عن تحسين محركات البحث قبل 20 عامًا ، وأدليت بملاحظات حول أحدث ما توصلت إليه التكنولوجيا على مر السنين ومقارنتها بما نحن عليه اليوم.
السيدة العجوز الصغيرة في المكتبة
لذلك ، بعد أن سلطت الضوء على أن هناك عناصر من علم المكتبات تحت شعار استرداد المعلومات ، اسمحوا لي أن أتحدث عن المكان المناسب لها في بحث الويب.
على ما يبدو ، يتم تحديد أمناء المكتبات بشكل أساسي على أنهم سيدات عجائز صغيرات. لقد ظهر ذلك بالتأكيد عندما أجريت مقابلات مع العديد من العلماء البارزين في المجال الجديد الناشئ لإعادة محاكمة المعلومات على شبكة الإنترنت (IR) كل تلك السنوات الماضية.
وصف كل من براين بينكرتون ، مخترع WebCrawler ، جنبًا إلى جنب مع Andrei Broder ، نائب رئيس التكنولوجيا وكبير العلماء في Alta Vista ، محرك البحث الأول قبل Google وفي الواقع Craig Silverstein ، مدير التكنولوجيا في Google (وعلى وجه الخصوص ، الموظف الأول في Google) عملهم في هذا المجال الجديد كمحاولة الحصول على محرك بحث لمحاكاة "السيدة العجوز الصغيرة في المكتبة".
تستند المكتبات إلى مفهوم بطاقة الفهرس - والغرض الأصلي منها هو محاولة تنظيم وتصنيف كل حيوان ونبات ومعدن معروف في العالم.
شكلت بطاقات الفهرس العمود الفقري لنظام المكتبة بأكمله ، حيث قامت بفهرسة كميات هائلة ومتنوعة من المعلومات.
بصرف النظر عن اسم المؤلف وعنوان الكتاب والموضوع و "مصطلحات الفهرس" البارزة (الملقب بالكلمات الرئيسية) وما إلى ذلك ، فإن بطاقة الفهرس ستحتوي أيضًا على موقع الكتاب. وبالتالي ، بعد فترة من الوقت عندما سألتها "أمينة مكتبة السيدة العجوز الصغيرة" عن كتاب معين ، ستتمكن بشكل بديهي من الإشارة ليس فقط إلى قسم المكتبة ، ولكن ربما حتى الرف الذي كان الكتاب عليه ، مما يوفر طريقة الاسترجاع السريع.
ومع ذلك ، عندما شرحت تشابه هذا النوع من نظام الفهرسة في محركات البحث كما فعلت كل تلك السنوات الماضية ، كان علي إضافة تحذير لا يزال من المهم فهمه:
"أكبر محركات البحث هي الفهرس الذي يعتمد على طريقة مشابهة لتلك الموجودة في المكتبة. بعد تخزين جزء كبير من الويب في فهارس ضخمة ، يحتاجون بعد ذلك إلى إرجاع المستندات ذات الصلة بسرعة مقابل كلمة رئيسية أو عبارة معينة. لكن تباين صفحات الويب من حيث التكوين والجودة والمحتوى أكبر من حجم البيانات الأولية نفسها. الويب ككل ليس له هيكل موحد ، مع تنوع هائل في أسلوب التأليف والمحتوى أوسع بكثير وأكثر تعقيدًا من المجموعات التقليدية للوثائق النصية. وهذا يجعل من المستحيل تقريبًا على محرك البحث تطبيق التقنيات التقليدية الصارمة المستخدمة في المكتبات وأنظمة إدارة قواعد البيانات واسترجاع المعلومات ".
حتمًا ، ما حدث بعد ذلك بالكلمات الرئيسية والطريقة التي نكتب بها للويب كانت ظهور مجال جديد للاتصال.
كما أوضحت في الكتاب ، يمكن اعتبار HTML نوعًا لغويًا جديدًا ويجب التعامل معه على هذا النحو في الدراسات اللغوية المستقبلية. هناك الكثير في مستند Hypertext أكثر من وجود مستند "نص مسطح". وهذا يعطي إشارة أكثر إلى ما تدور حوله صفحة ويب معينة عندما يتم قراءتها من قبل البشر وكذلك النص الذي يتم تحليله وتصنيفه وتصنيفه من خلال التنقيب عن النص واستخراج المعلومات بواسطة محركات البحث.
أحيانًا ما زلت أسمع مُحسّنات محرّكات البحث تشير إلى صفحات الويب "قراءة الآلة" لمحركات البحث ، ولكن هذا المصطلح ينتمي أكثر إلى المقدمة الحديثة نسبيًا لأنظمة "البيانات المنظمة".
كما لا يزال يتعين علي أن أشرح في كثير من الأحيان ، فإن قراءة الإنسان لصفحة ويب ومحركات البحث عن التنقيب عن المعلومات واستخراج المعلومات "حول" الصفحة لا يعد نفس الشيء مثل قراءة البشر لصفحة ويب ومحركات البحث التي يتم "تغذيتها" ببيانات منظمة.
أفضل مثال ملموس وجدته هو إجراء مقارنة بين صفحة ويب HTML حديثة مع بيانات منظمة مدرجة "قابلة للقراءة آليًا" وجواز سفر حديث. ألقِ نظرة على صفحة الصورة في جواز سفرك وسترى قسمًا رئيسيًا يحتوي على صورتك ونصًا ليقرأه البشر وقسمًا منفصلاً في أسفل الصفحة ، تم إنشاؤه خصيصًا لقراءة الآلة عن طريق التمرير أو المسح.
جوهريًا ، فإن صفحة الويب الحديثة مبنية نوعًا ما مثل جواز السفر الحديث. ومن المثير للاهتمام ، قبل 20 عامًا ، أشرت إلى تركيبة الإنسان / الآلة مع هذه الحقيقة الصغيرة:
في عام 1747 ، نشر الطبيب والفيلسوف الفرنسي جوليان أوفروي دي لا ميتري أحد أكثر الأعمال المؤثرة في تاريخ الأفكار. أطلق عليها اسم L'HOMME MACHINE ، وهو أفضل ما يُترجم على أنه "رجل ، آلة". في كثير من الأحيان ، سوف تسمع عبارة "الرجال والآلات" وهذه هي الفكرة الأساسية للذكاء الاصطناعي. "
لقد أكدت على أهمية البيانات المنظمة في مقالتي السابقة وآمل أن أكتب لك شيئًا أعتقد أنه سيكون مفيدًا للغاية لفهم التوازن بين قراءة البشر وقراءة الآلة. لقد قمت بتبسيطها تمامًا بهذه الطريقة في عام 2002 لتقديم تبرير أساسي:
- البيانات: تمثيل للحقائق أو الأفكار بطريقة رسمية ، يمكن إيصالها أو التلاعب بها من خلال عملية ما.
- المعلومات: المعنى الذي يخصصه الإنسان للبيانات عن طريق الاصطلاحات المعروفة المستخدمة في تمثيلها.
وبالتالي:
- البيانات مرتبطة بالحقائق والآلات.
- المعلومات مرتبطة بالمعنى والبشر.
دعنا نتحدث عن خصائص النص لمدة دقيقة ثم سأغطي كيف يمكن تمثيل النص كبيانات في شيء "أسيء فهمه إلى حد ما" (يجب أن نقول) في صناعة تحسين محركات البحث تسمى نموذج الفضاء المتجه.
الكلمات الرئيسية الأكثر أهمية في فهرس محرك البحث مقابل الكلمات الأكثر شيوعًا
هل سمعت عن قانون زيف؟
سميت على اسم البروفيسور جورج كينجسلي زيف من جامعة هارفارد ، وهي تتنبأ بالظاهرة التي ، ونحن نكتب ، نستخدم كلمات مألوفة عالية التردد.
قال زيف إن قانونه يستند إلى المتنبئ الرئيسي للسلوك البشري: السعي لتقليل الجهد. لذلك ، ينطبق قانون Zipf على أي مجال تقريبًا يتضمن الإنتاج البشري.
هذا يعني أن لدينا أيضًا علاقة مقيدة بين الترتيب والتردد في اللغة الطبيعية.
معظم المجموعات الكبيرة من المستندات النصية لها خصائص إحصائية متشابهة. إن معرفة هذه الإحصائيات مفيد لأنها تؤثر على فعالية وكفاءة هياكل البيانات المستخدمة لفهرسة المستندات. تعتمد العديد من نماذج الاسترجاع عليها.
هناك أنماط من الوقائع في الطريقة التي نكتب بها - نبحث عمومًا عن الطريقة الأسهل والأقصر والأقل مشاركة وأسرع طريقة ممكنة. لذا ، الحقيقة هي أننا نستخدم نفس الكلمات البسيطة مرارًا وتكرارًا.
على سبيل المثال ، كل تلك السنوات الماضية ، صادفت بعض الإحصائيات من تجربة حيث أخذ العلماء مجموعة 131 ميجابايت (كانت بيانات ضخمة في ذلك الوقت) من 46500 مقالة صحفية (19 مليون حدث مصطلح).
فيما يلي البيانات الخاصة بأهم 10 كلمات وعدد مرات استخدامها في هذه المجموعة. ستفهم النقطة بسرعة كبيرة ، على ما أعتقد:
تردد الكلمات
في: 1130021
من 547311
إلى 516635
أ 464736
في 390819
و 387703
أن 204351
لعام 199340
هو 152483
قال 148302
تذكر أن جميع المقالات الواردة في مجموعة المقالات كتبها صحفيون محترفون. ولكن إذا نظرت إلى الكلمات العشر الأكثر استخدامًا ، فبالكاد يمكنك تكوين جملة منطقية منها.
نظرًا لوجود هذه الكلمات الشائعة بشكل متكرر في اللغة الإنجليزية ، ستتجاهلها محركات البحث باعتبارها "كلمات توقف". إذا كانت الكلمات الأكثر شيوعًا التي نستخدمها لا تقدم قيمة كبيرة لنظام الفهرسة الآلي ، فما هي الكلمات التي تفعل ذلك؟
كما لوحظ بالفعل ، كان هناك الكثير من العمل في مجال أنظمة استرجاع المعلومات (IR). تم تطبيق الأساليب الإحصائية على نطاق واسع بسبب عدم ملاءمة النص لنماذج البيانات القائمة على المنطق الرسمي (على سبيل المثال ، قواعد البيانات العلائقية).
لذا فبدلاً من مطالبة المستخدمين بأن يكونوا قادرين على توقع الكلمات الدقيقة ومجموعات الكلمات التي قد تظهر في المستندات ذات الأهمية ، يتيح IR الإحصائي للمستخدمين ببساطة إدخال سلسلة من الكلمات التي من المحتمل أن تظهر في المستند.

ثم يأخذ النظام في الاعتبار تواتر هذه الكلمات في مجموعة من النصوص ، وفي المستندات الفردية ، لتحديد الكلمات التي من المحتمل أن تكون أفضل أدلة ذات صلة. يتم احتساب النتيجة لكل مستند بناءً على الكلمات التي يحتوي عليها ويتم استرداد المستندات ذات الدرجات الأعلى.
لقد كنت محظوظًا بما يكفي لإجراء مقابلة مع باحث رائد في مجال العلاقات الدولية عندما كنت أبحث عن نفسي للكتاب في عام 2001. في ذلك الوقت ، كان أندريه برودر كبير العلماء في Alta Vista (حاليًا مهندس متميز في Google) ، وكنا نناقش هذا الموضوع من "نواقل المصطلح" وسألت عما إذا كان بإمكانه إعطائي شرحًا بسيطًا لما هي عليه.
وأوضح لي كيف أنه عند "ترجيح" مصطلحات الأهمية في الفهرس ، قد يلاحظ حدوث كلمة "من" ملايين المرات في المجموعة. قال إن هذه كلمة لن يكون لها "وزن" على الإطلاق. ولكن إذا رأى شيئًا مثل كلمة "هيموجلوبين" ، وهي كلمة نادرة جدًا في الجسم ، فسيكتسب هذا بعض الوزن.
أريد أن أعود هنا بخطوة سريعة قبل أن أشرح كيفية إنشاء الفهرس ، وأبدد أسطورة أخرى ظلت باقية على مر السنين. وهذا هو المكان الذي يعتقد الكثير من الناس أن Google (ومحركات البحث الأخرى) يقومون بالفعل بتنزيل صفحات الويب الخاصة بك وتخزينها على محرك أقراص ثابت.
لا على الاطلاق. لدينا بالفعل مكان للقيام بذلك ، ويسمى شبكة الويب العالمية.
نعم ، يحتفظ Google بلقطة "مخبأة" للصفحة لاسترجاعها بسرعة. ولكن عندما يتغير محتوى هذه الصفحة ، في المرة التالية التي يتم فيها الزحف إلى الصفحة ، تتغير النسخة المخبأة أيضًا.
لهذا السبب لا يمكنك أبدًا العثور على نسخ من صفحات الويب القديمة الخاصة بك على Google. لذلك ، فإن مورديك الحقيقي الوحيد هو أرشيف الإنترنت (المعروف أيضًا باسم The Wayback Machine).
في الواقع ، عندما يتم الزحف إلى صفحتك ، يتم تفكيكها بشكل أساسي. يتم تحليل النص (مستخرج) من المستند.
يتم إعطاء كل مستند معرفه الخاص جنبًا إلى جنب مع تفاصيل الموقع (عنوان URL) ويتم إعادة توجيه "البيانات الأولية" إلى وحدة المفهرس. يتم حفظ الكلمات / المصطلحات مع معرف المستند المرتبط الذي ظهرت فيه.
إليك مثال بسيط للغاية باستخدام اثنين من المستندات والنص الذي يحتويانه والذي أنشأته قبل 20 عامًا.
أذكر بناء الفهرس
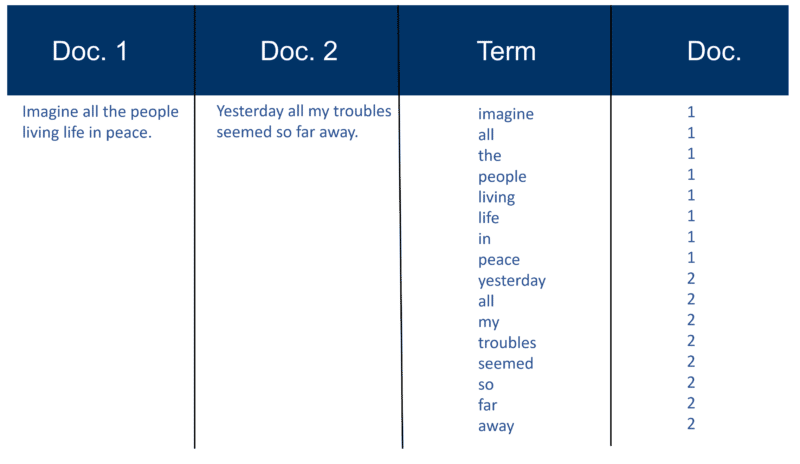
بعد تحليل جميع المستندات ، يتم فرز الملف المقلوب حسب الشروط:
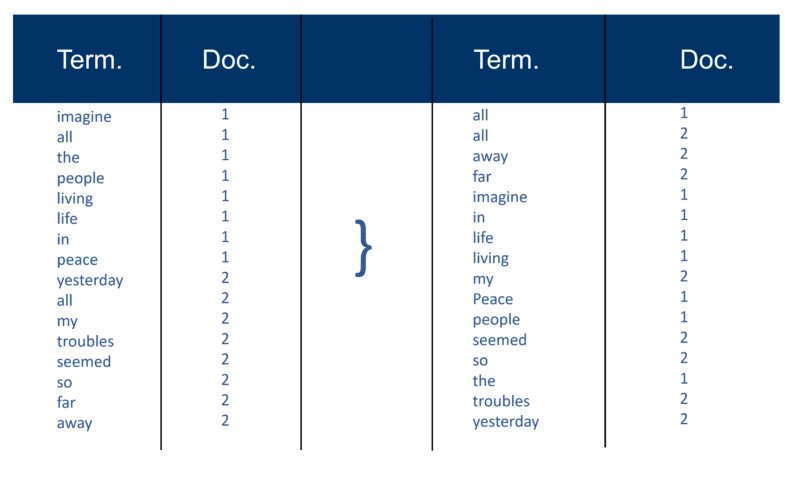
في المثال الخاص بي ، يبدو هذا بسيطًا إلى حد ما في بداية العملية ، لكن الترحيلات (كما تُعرف في مصطلحات استرداد المعلومات) إلى الفهرس يتم إدخالها في مستند واحد في كل مرة. مرة أخرى ، مع الملايين من المستندات ، يمكنك تخيل مقدار قوة المعالجة المطلوبة لتحويل هذا إلى "عرض حكيم للمصطلح" الهائل والذي تم تبسيطه أعلاه ، أولاً حسب المصطلح ثم بواسطة Doc في كل مصطلح.
ستلاحظ إشارتي إلى "ملايين المستندات" من كل تلك السنوات الماضية. بالطبع ، نحن في المليارات (حتى التريليونات) هذه الأيام. في توضيحي الأساسي لكيفية إنشاء الفهرس ، تابعت هذا:
ينشئ كل محرك بحث قاموسه المخصص (أو المعجم كما هو - تذكر أن العديد من صفحات الويب ليست مكتوبة باللغة الإنجليزية) ، والتي يجب أن تتضمن كل "مصطلح" جديد يتم اكتشافه بعد الزحف (فكر في الطريقة التي عند استخدام معالج الكلمات مثل Microsoft Word ، غالبًا ما تحصل على خيار إضافة كلمة إلى قاموسك المخصص ، أي شيء لا يحدث في قاموس اللغة الإنجليزية القياسي). بمجرد أن يحصل محرك البحث على فهرسه "الكبير" ، ستكون بعض المصطلحات أكثر أهمية من غيرها. لذلك ، كل مصطلح يستحق وزنه (القيمة). يعتمد الكثير من عامل الترجيح على المصطلح نفسه. بالطبع ، هذا أمر مباشر إلى حد ما عندما تفكر في الأمر ، لذلك يتم إعطاء وزن أكبر للكلمة ذات التكرارات الأكثر ، ولكن هذا الوزن يزداد بعد ذلك من خلال "ندرة" المصطلح عبر المجموعة بأكملها. يمكن للمفهرس أيضًا إعطاء "وزن" أكبر للكلمات التي تظهر في أماكن معينة في المستند. الكلمات التي ظهرت في علامة العنوان <title> مهمة جدًا. قد تكون الكلمات المكتوبة بعلامات العنوان <h1> أو تلك المكتوبة بخط غامق <b> على الصفحة أكثر صلة بالموضوع. من المؤكد أن الكلمات التي تظهر في نص الرابط للروابط على صفحات HTML ، أو بالقرب منها ، تعتبر مهمة جدًا. يتم تدوين الكلمات التي تظهر في العلامات النصية <alt> مع الصور وكذلك الكلمات التي تظهر في العلامات الوصفية.
بصرف النظر عن النص الأصلي "استرجاع المعلومات الحديثة" الذي كتبه العالم جيرارد سالتون (الذي يُعتبر أبًا لاسترجاع المعلومات الحديثة) ، كان لدي عدد من الموارد الأخرى في اليوم الذي تحقق مما سبق. قدم لي كل من براين بينكرتون ومايكل مودلين (مخترعا محركي البحث WebCrawler و Lycos على التوالي) تفاصيل حول كيفية استخدام "نهج سالتون الكلاسيكي". وكلاهما جعلني أدرك القيود.
ليس ذلك فحسب ، فقد سلط لاري بيدج وسيرجي برين الضوء على نفس الشيء في الورقة الأصلية التي كتبوها عند إطلاق نموذج Google الأولي. سأعود إلى هذا لأنه مهم في المساعدة على تبديد أسطورة أخرى.
لكن أولاً ، إليك كيف شرحت "نهج سالتون الكلاسيكي" في عام 2002. تأكد من ملاحظة الإشارة إلى "زوج الوزن المصطلح".
بمجرد أن ينشئ محرك البحث "الفهرس الكبير" الخاص به ، تقيس وحدة المفهرس "تردد المصطلح" (tf) للكلمة في مستند للحصول على "كثافة المصطلح" ثم يقيس "تردد المستند العكسي" (idf) الذي هو حساب تكرار المصطلحات في المستند ؛ العدد الإجمالي للوثائق ؛ عدد المستندات التي تحتوي على المصطلح. مع هذا الحساب الإضافي ، يمكن الآن عرض كل مستند كمتجه لقيم tf x idf (قيم ثنائية أو رقمية تتوافق بشكل مباشر أو غير مباشر مع كلمات المستند). ما لديك إذن هو زوج وزن مصطلح. يمكنك تحويل هذا إلى: المستند يحتوي على قائمة مرجحة من الكلمات ؛ تحتوي الكلمة على قائمة مرجحة من المستندات (زوج وزن مصطلح).
نموذج الفضاء المتجه
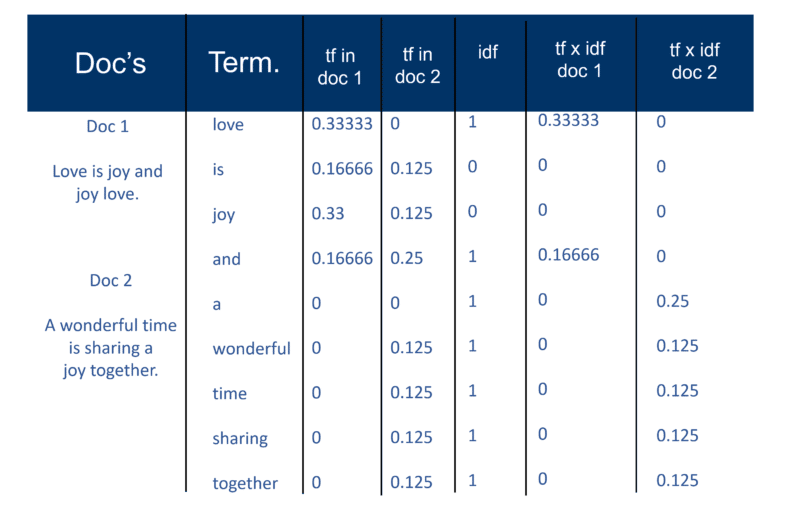
الآن بعد أن أصبحت المستندات عبارة عن متجهات بمكون واحد لكل مصطلح ، فإن ما تم إنشاؤه هو "مساحة متجهة" حيث توجد جميع المستندات. ولكن ما هي فوائد إنشاء هذا الكون من المستندات الذي أصبح له هذا الحجم الآن؟
بهذه الطريقة ، إذا كان Doc 'd' (كمثال) متجهًا ، فمن السهل العثور على الآخرين مثله وأيضًا العثور على متجهات بالقرب منه.
بشكل حدسي ، يمكنك بعد ذلك تحديد أن المستندات ، القريبة من بعضها البعض في مساحة متجهة ، تتحدث عن نفس الأشياء. من خلال القيام بذلك ، يمكن لمحرك البحث إنشاء مجموعات من الكلمات أو المستندات وإضافة العديد من طرق الترجيح الأخرى.
ومع ذلك ، فإن الفائدة الرئيسية لاستخدام متجهات المصطلحات لمحركات البحث هي أن محرك الاستعلام يمكن أن يعتبر الاستعلام نفسه مستندًا قصيرًا جدًا. بهذه الطريقة ، يصبح الاستعلام متجهًا في نفس مساحة المتجه ويمكن لمحرك الاستعلام قياس مدى قرب كل مستند منه.
يتيح نموذج Vector Space للمستخدم الاستعلام في محرك البحث عن "المفاهيم" بدلاً من البحث "المعجمي" البحت. كما ترون هنا ، حتى قبل 20 عامًا ، كانت فكرة المفاهيم والموضوعات بدلاً من الكلمات الرئيسية فقط تلعب دورًا كبيرًا.
حسنًا ، دعنا نتناول موضوع "كثافة الكلمات الرئيسية". تظهر كلمة "كثافة" في شرح كيفية عمل نموذج الفضاء المتجه ، ولكن فقط عندما تنطبق على الحساب عبر مجموعة المستندات بأكملها - وليس على صفحة واحدة. ربما يكون هذا المرجع هو الذي جعل العديد من مُحسّنات محرّكات البحث تبدأ في استخدام أدوات تحليل كثافة الكلمات الرئيسية على صفحات فردية.
لقد لاحظت أيضًا على مر السنين أن العديد من مُحسّنات محرّكات البحث ، الذين اكتشفوا نموذج الفضاء المتجه ، يميلون إلى محاولة تطبيق ترجيح مصطلح tf x idf الكلاسيكي. ولكن من غير المرجح أن ينجح هذا كثيرًا ، لا سيما في Google ، كما ذكر المؤسسان Larry Page و Sergey Brin في ورقتهما الأصلية حول كيفية عمل Google - فقد أكدوا على رداءة جودة النتائج عند تطبيق النموذج الكلاسيكي وحده:
“على سبيل المثال ، يحاول نموذج فضاء المتجه القياسي إرجاع المستند الذي يقارب الاستعلام ، نظرًا لأن كلا من الاستعلام والمستند عبارة عن متجهات يتم تحديدها من خلال تواجد كلمتهم. على الويب ، غالبًا ما تعرض هذه الإستراتيجية مستندات قصيرة جدًا تمثل الاستعلام بالإضافة إلى بضع كلمات ".
كان هناك العديد من المتغيرات لمحاولة الالتفاف على "صلابة" نموذج Vector Space. وعلى مر السنين مع التقدم في الذكاء الاصطناعي والتعلم الآلي ، هناك العديد من الاختلافات في النهج التي يمكن أن تحسب ترجيح كلمات ووثائق معينة في الفهرس.
يمكنك قضاء سنوات في محاولة معرفة الصيغ التي يستخدمها أي محرك بحث ، ناهيك عن Google (على الرغم من أنه يمكنك التأكد من أي منها لا يستخدمه كما أشرت للتو). لذلك ، مع وضع هذا في الاعتبار ، يجب أن يبدد الأسطورة القائلة بأن محاولة التلاعب بكثافة الكلمات الرئيسية لصفحات الويب عند إنشائها هي جهد ضائع إلى حد ما.
حل مشكلة الوفرة
اعتمد الجيل الأول من محركات البحث اعتمادًا كبيرًا على عوامل الصفحة للترتيب.
لكن المشكلة التي تواجهك في استخدام تقنيات التصنيف المعتمدة على الكلمات الرئيسية فقط (بخلاف ما ذكرته للتو عن Google منذ اليوم الأول) هي شيء يُعرف باسم "مشكلة الوفرة" والتي تعتبر أن الويب ينمو بشكل كبير كل يوم والنمو الهائل في المستندات التي تحتوي على نفس الكلمات الدالة.
وهذا يطرح السؤال على هذه الشريحة التي أستخدمها منذ عام 2002:

يمكنك أن تفترض أن قائد الأوركسترا ، الذي كان يرتب ويعزف المقطوعة لسنوات عديدة مع العديد من الأوركسترا ، سيكون الأكثر موثوقية. ولكن من خلال العمل فقط على تقنيات ترتيب الكلمات الرئيسية فقط ، فمن المحتمل أن يكون طالب الموسيقى هو النتيجة الأولى.
كيف تحل هذه المشكلة؟
حسنًا ، الإجابة هي تحليل الارتباط التشعبي (المعروف أيضًا باسم الروابط الخلفية).
في الدفعة التالية ، سأشرح كيف دخلت كلمة "سلطة" في قاموس IR و SEO. وسأشرح أيضًا المصدر الأصلي لما يشار إليه الآن باسم EAT وما الذي يعتمد عليه بالفعل.
حتى ذلك الحين - كن على ما يرام ، ابق آمنًا وتذكر مدى السعادة في مناقشة الأعمال الداخلية لمحركات البحث!
الآراء الواردة في هذا المقال هي آراء المؤلف الضيف وليست بالضرورة آراء محرك البحث. مؤلفو طاقم العمل مدرجون هنا.