
Przegląd technik indeksowania i rankingu słów kluczowych: 20 lat później
Opublikowany: 2022-08-04Kiedy żołądź, który stał się branżą SEO, zaczął się rozwijać, indeksowanie i ranking w wyszukiwarkach opierały się wyłącznie na słowach kluczowych.
Wyszukiwarka dopasuje słowa kluczowe w zapytaniu do słów kluczowych w swoim indeksie równolegle do słów kluczowych pojawiających się na stronie internetowej.
Strony o najwyższym wyniku trafności zostałyby uszeregowane według jednej z trzech najpopularniejszych technik wyszukiwania:
- Model logiczny
- Model probabilistyczny
- Model przestrzeni wektorowej
Model przestrzeni wektorowej stał się najbardziej odpowiedni dla wyszukiwarek.
Zamierzam wrócić do podstawowego i nieco prostego wyjaśnienia klasycznego modelu, którego używałem w tym artykule (ponieważ nadal jest aktualny w zestawie wyszukiwarek).
Po drodze rozwiejemy jeden lub dwa mit – na przykład pojęcie „gęstości słów kluczowych” na stronie internetowej. Połóżmy go do łóżka raz na zawsze.
Słowo kluczowe: jedno z najczęściej używanych słów w informatyce; dla marketerów – tajemnicza tajemnica
„Co to jest słowo kluczowe?”
Nie masz pojęcia, ile razy słyszałem to pytanie, gdy pojawiała się branża SEO. A po tym, jak podałbym skrótowe wyjaśnienie, następne pytanie brzmiałoby: „Więc, jakie są moje słowa kluczowe, Mike?”
Szczerze mówiąc, dość trudno było wyjaśnić marketerom, że konkretne słowa kluczowe użyte w zapytaniu spowodowały wyświetlenie odpowiednich stron internetowych w wynikach wyszukiwania.
I tak, prawie na pewno wywołałoby to kolejne pytanie: „Co to jest zapytanie, Mike?”
Obecnie terminy takie jak słowo kluczowe, zapytanie, indeks, ranking i cała reszta są powszechne w leksykonie marketingu cyfrowego.
Jednak jako SEO uważam, że niezwykle przydatne jest zrozumienie, skąd pochodzą, dlaczego i w jaki sposób te terminy nadal mają zastosowanie, tak samo jak kiedyś.
Nauka o wyszukiwaniu informacji (IR) jest podzbiorem pod wspólnym terminem „sztuczna inteligencja”. Ale sama IR składa się również z kilku podzbiorów, w tym bibliotekoznawstwa i informatyki.
I to jest nasz punkt wyjścia do tej drugiej części mojej wędrówki po pasie pamięci SEO. (Moim pierwszym, na wypadek gdybyś to przegapił, było: indeksowaliśmy sieć od 32 lat: co się zmieniło?)
Ta ciągła seria artykułów opiera się na tym, co napisałem w książce o SEO 20 lat temu, dokonując obserwacji na temat stanu techniki na przestrzeni lat i porównując go z tym, gdzie jesteśmy dzisiaj.
Mała starsza pani w bibliotece?
Po zwróceniu uwagi na to, że pod hasłem Pozyskiwanie informacji znajdują się elementy bibliotekoznawstwa, pozwólcie, że odniosę się do ich miejsca w wyszukiwarce internetowej.
Pozornie bibliotekarki są identyfikowane głównie jako małe starsze panie. Z pewnością wyglądało to w ten sposób, kiedy przeprowadziłem wywiady z kilkoma czołowymi naukowcami w wyłaniającej się nowej dziedzinie „sieciowego” pobierania informacji (IR) wiele lat temu.
Brian Pinkerton, wynalazca WebCrawler, wraz z Andrei Broderem, wiceprezesem ds. technologii i głównym naukowcem w Alta Vista, wyszukiwarce numer jeden przed Google i rzeczywiście Craig Silverstein, dyrektor ds. technologii w Google (a zwłaszcza pracownik numer jeden w Google) opisali to wszystko. ich praca w tej nowej dziedzinie jako próba nakłonienia wyszukiwarki do naśladowania „małej staruszki w bibliotece”.
Biblioteki opierają się na koncepcji karty indeksowej, której pierwotnym celem była próba uporządkowania i sklasyfikowania każdego znanego na świecie zwierzęcia, rośliny i minerału.
Karty indeksowe stanowiły podstawę całego systemu bibliotecznego, indeksując ogromne i zróżnicowane ilości informacji.
Poza nazwiskiem autora, tytułem książki, tematyką i godnymi uwagi „pojęciami indeksowymi” (czyli słowami kluczowymi) itp., karta indeksowa zawierałaby również lokalizację książki. I dlatego po chwili „starsza bibliotekarka”, gdy zapytasz ją o konkretną książkę, intuicyjnie będzie w stanie wskazać nie tylko sekcję biblioteki, ale prawdopodobnie nawet półkę, na której książka się znajdowała, zapewniając spersonalizowaną metoda szybkiego pobierania.
Jednak kiedy wyjaśniłem podobieństwo tego typu systemu indeksowania w wyszukiwarkach, tak jak robiłem to przez te wszystkie lata, musiałem dodać zastrzeżenie, które nadal jest ważne do zrozumienia:
„Największe wyszukiwarki są indeksowane w podobny sposób jak w bibliotece. Mając dużą część sieci w ogromnych indeksach, muszą szybko zwrócić odpowiednie dokumenty na dane słowo kluczowe lub frazę. Jednak zróżnicowanie stron internetowych pod względem składu, jakości i treści jest nawet większe niż skala samych surowych danych. Sieć jako całość nie ma jednoczącej struktury, z ogromnym wariantem stylu tworzenia i treści znacznie szerszym i bardziej złożonym niż w tradycyjnych zbiorach dokumentów tekstowych. To sprawia, że wyszukiwarka jest prawie niemożliwa do zastosowania ściśle konwencjonalnych technik stosowanych w bibliotekach, systemach zarządzania bazami danych i wyszukiwaniu informacji”.
Nieuchronnie to, co wtedy wydarzyło się ze słowami kluczowymi i sposobem, w jaki piszemy dla sieci, było pojawieniem się nowej dziedziny komunikacji.
Jak wyjaśniłem w książce, HTML może być postrzegany jako nowy gatunek językowy i tak powinien być traktowany w przyszłych badaniach językoznawczych. Dokument hipertekstowy to znacznie więcej niż dokument „płaski tekst”. Daje to więcej informacji na temat tego, o czym jest dana strona internetowa, gdy jest ona czytana przez ludzi, a także tekstu, który jest analizowany, klasyfikowany i kategoryzowany poprzez eksplorację tekstu i wyodrębnianie informacji przez wyszukiwarki.
Czasami wciąż słyszę, jak SEO odnosi się do stron internetowych „odczytu maszynowego” wyszukiwarek, ale termin ten należy znacznie bardziej do stosunkowo niedawnego wprowadzenia systemów „danych strukturalnych”.
Jak często wciąż muszę wyjaśniać, człowiek czytający stronę internetową i wyszukiwarki tekstowe i wydobywające informacje „o” stronie to nie to samo, co człowiek czytający stronę internetową i wyszukiwarki „karmione” ustrukturyzowanymi danymi.
Najlepszym namacalnym przykładem, jaki znalazłem, jest porównanie nowoczesnej strony internetowej HTML z wstawionymi ustrukturyzowanymi danymi „do odczytu maszynowego” z nowoczesnym paszportem. Spójrz na stronę ze zdjęciem w paszporcie, a zobaczysz jedną główną sekcję ze zdjęciem i tekstem, którą ludzie mogą przeczytać, oraz oddzielną sekcję u dołu strony, która jest stworzona specjalnie do odczytu maszynowego przez przeciągnięcie lub skanowanie.
Zasadniczo współczesna strona internetowa ma strukturę podobną do nowoczesnego paszportu. Co ciekawe, 20 lat temu odniosłem się do kombinacji człowiek/maszyna z tym małym faktoidem:
„W 1747 francuski lekarz i filozof Julien Offroy de la Mettrie opublikował jedno z najbardziej przełomowych dzieł w historii idei. Zatytułował ją L'HOMME MACHINE, co najlepiej przetłumaczyć jako „człowiek, maszyna”. Często usłyszysz frazę „ludzi i maszyn” i jest to podstawowa idea sztucznej inteligencji”.
W poprzednim artykule podkreśliłem znaczenie uporządkowanych danych i mam nadzieję, że napiszę dla Ciebie coś, co moim zdaniem będzie niezwykle pomocne w zrozumieniu równowagi między czytaniem przez ludzi a czytaniem maszynowym. Całkowicie uprościłem to w 2002 roku, aby zapewnić podstawową racjonalizację:
- Dane: przedstawienie faktów lub pomysłów w sposób sformalizowany, które mogą być przekazywane lub manipulowane przez jakiś proces.
- Informacja: znaczenie, jakie człowiek przypisuje danym za pomocą znanych konwencji stosowanych w ich reprezentacji.
W związku z tym:
- Dane są powiązane z faktami i maszynami.
- Informacja jest związana ze znaczeniem i ludźmi.
Porozmawiajmy przez chwilę o cechach tekstu, a potem omówię, jak tekst może być reprezentowany jako dane w czymś „nieco źle zrozumianym” (powiedzmy) w branży SEO, zwanym modelem przestrzeni wektorowej.
Najważniejsze słowa kluczowe w indeksie wyszukiwarki a najpopularniejsze słowa
Słyszałeś kiedyś o prawie Zipfa?
Nazwany na cześć profesora lingwistyki z Harvardu George'a Kingsleya Zipfa, przewiduje zjawisko polegające na tym, że podczas pisania używamy znanych słów z dużą częstotliwością.
Zipf powiedział, że jego prawo opiera się na głównym predykatorze ludzkiego zachowania: dążeniu do zminimalizowania wysiłku. Dlatego prawo Zipfa ma zastosowanie do prawie każdej dziedziny związanej z produkcją ludzką.
Oznacza to, że mamy również ograniczony związek między rangą a częstotliwością w języku naturalnym.
Większość dużych zbiorów dokumentów tekstowych ma podobne cechy statystyczne. Znajomość tych statystyk jest pomocna, ponieważ wpływają one na skuteczność i wydajność struktur danych wykorzystywanych do indeksowania dokumentów. Wiele modeli wyszukiwania opiera się na nich.
W sposobie, w jaki piszemy, istnieją wzorce zdarzeń – zazwyczaj szukamy najłatwiejszej, najkrótszej, najmniej zaangażowanej, najszybszej możliwej metody. Tak więc prawda jest taka, że po prostu używamy tych samych prostych słów w kółko.
Jako przykład, przez te wszystkie lata, natknąłem się na statystyki z eksperymentu, w którym naukowcy zebrali 131 MB kolekcji (wtedy były to duże zbiory danych) 46 500 artykułów prasowych (19 milionów terminów).
Oto dane dla 10 najpopularniejszych słów i ile razy zostały użyte w tym korpusie. Dość szybko zrozumiesz, jak sądzę:
Częstotliwość słów
numer: 1130021
z 547311
do 516635
464736
w 390819
i 387703
że 204351
za rok 199340
jest 152483
powiedział 148302
Pamiętaj, że wszystkie artykuły zawarte w korpusie zostały napisane przez profesjonalnych dziennikarzy. Ale jeśli spojrzysz na dziesięć najczęściej używanych słów, nie możesz z nich zrobić ani jednego sensownego zdania.
Ponieważ te popularne słowa występują tak często w języku angielskim, wyszukiwarki zignorują je jako „słowa stop”. Jeśli najpopularniejsze słowa, których używamy, nie przynoszą dużej wartości automatycznemu systemowi indeksowania, które słowa mają?
Jak już wspomniano, wykonano wiele prac w dziedzinie systemów wyszukiwania informacji (IR). Podejścia statystyczne są szeroko stosowane ze względu na słabe dopasowanie tekstu do modeli danych opartych na logice formalnej (np. relacyjne bazy danych).
Dlatego zamiast wymagać, aby użytkownicy byli w stanie dokładnie przewidzieć słowa i kombinacje słów, które mogą pojawić się w interesujących dokumentach, statystyczna IR pozwala użytkownikom po prostu wprowadzić ciąg słów, które prawdopodobnie pojawią się w dokumencie.
Następnie system bierze pod uwagę częstotliwość występowania tych słów w zbiorze tekstów oraz w poszczególnych dokumentach, aby określić, które słowa mogą być najlepszymi wskazówkami dotyczącymi trafności. Punktacja jest obliczana dla każdego dokumentu na podstawie zawartych w nim słów i pobierane są dokumenty o najwyższej punktacji.

Miałem szczęście przeprowadzić wywiad z czołowym naukowcem w dziedzinie IR, kiedy przygotowywałem się do tej książki w 2001 roku. W tym czasie Andrei Broder był głównym naukowcem w Alta Vista (obecnie Distinguished Engineer w Google) i dyskutowaliśmy na ten temat „wektorów terminów” i zapytałem, czy mógłby mi w prosty sposób wyjaśnić, czym one są.
Wyjaśnił mi, jak podczas „ważenia” terminów pod względem ważności w indeksie może zauważyć wystąpienie słowa „z” miliony razy w korpusie. To słowo, które w ogóle nie będzie miało „wagi”, powiedział. Ale jeśli zobaczy coś w rodzaju słowa „hemoglobina”, które jest znacznie rzadszym słowem w korpusie, to ten nabierze wagi.
Chciałbym zrobić tu szybki krok wstecz, zanim wyjaśnię, jak tworzony jest indeks, i rozwiewam kolejny mit, który utrzymywał się przez lata. I to jest ten, w którym wiele osób uważa, że Google (i inne wyszukiwarki) faktycznie pobierają Twoje strony internetowe i przechowują je na dysku twardym.
Nie, wcale nie. Mamy już miejsce, w którym można to zrobić, nazywa się to World Wide Web.
Tak, Google przechowuje „z pamięci podręcznej” migawkę strony w celu szybkiego pobrania. Ale gdy zawartość strony ulegnie zmianie, przy następnym indeksowaniu strony zmieni się również wersja w pamięci podręcznej.
Dlatego w Google nigdy nie znajdziesz kopii swoich starych stron internetowych. W tym celu Twoim jedynym prawdziwym zasobem jest Internet Archive (aka The Wayback Machine).
W rzeczywistości, gdy twoja strona jest indeksowana, jest w zasadzie demontowana. Tekst jest analizowany (wyodrębniany) z dokumentu.
Każdy dokument otrzymuje własny identyfikator wraz ze szczegółami lokalizacji (URL), a „dane surowe” są przekazywane do modułu indeksatora. Słowa/terminy są zapisywane z powiązanym identyfikatorem dokumentu, w którym się pojawiły.
Oto bardzo prosty przykład wykorzystujący dwa dokumenty i zawarty w nich tekst, który stworzyłem 20 lat temu.
Przypomnij konstrukcję indeksu
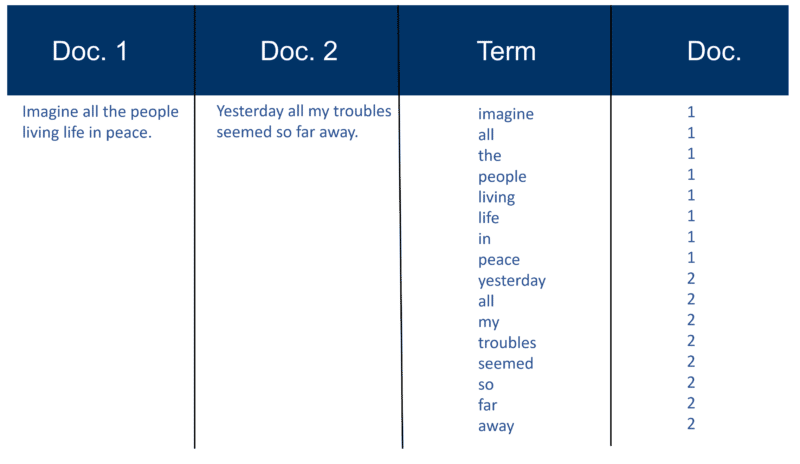
Po przeanalizowaniu wszystkich dokumentów odwrócony plik jest sortowany według terminów:
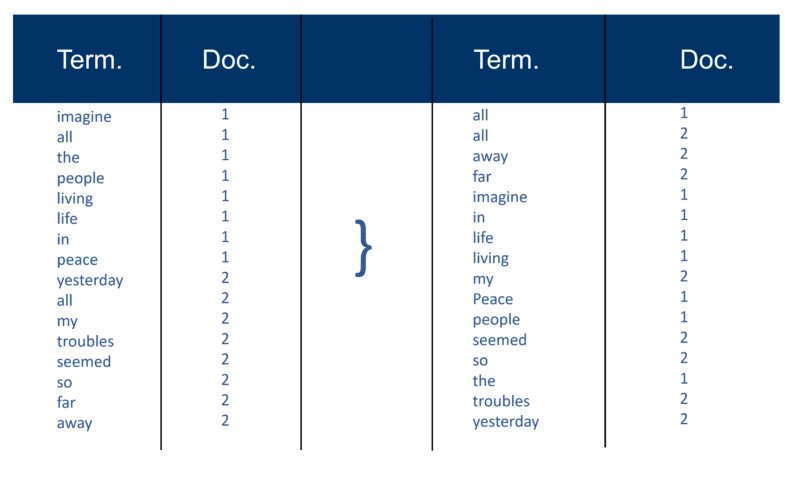
W moim przykładzie wygląda to dość prosto na początku procesu, ale księgowania (jak są one znane w terminach wyszukiwania informacji) do indeksu idą w jednym dokumencie na raz. Znowu, mając miliony dokumentów, możesz sobie wyobrazić ilość mocy obliczeniowej wymaganej do przekształcenia tego w ogromny „mądry pogląd na terminy”, który jest uproszczony powyżej, najpierw według terminów, a następnie dokumentów w ramach każdego terminu.
Zwróć uwagę na moje odniesienie do „milionów dokumentów” sprzed lat. Oczywiście w dzisiejszych czasach jesteśmy w miliardach (nawet bilionach). W moim podstawowym wyjaśnieniu, jak tworzony jest indeks, kontynuowałem to:
Każda wyszukiwarka tworzy swój własny słownik (lub leksykon, jak to jest – pamiętaj, że wiele stron internetowych nie jest napisanych w języku angielskim), który musi zawierać każdy nowy „termin” wykryty po przeszukaniu (pomyśl o sposobie, w jaki podczas korzystania z edytor tekstu, taki jak Microsoft Word, często masz możliwość dodania słowa do własnego słownika niestandardowego, czyli czegoś, co nie występuje w standardowym słowniku angielskim). Gdy wyszukiwarka ma swój „duży” indeks, niektóre terminy będą ważniejsze niż inne. Tak więc każdy termin zasługuje na swoją wagę (wartość). Wiele czynników ważenia zależy od samego terminu. Oczywiście, gdy się nad tym zastanowić, jest to dość proste, więc większą wagę przypisuje się słowu, które ma więcej wystąpień, ale waga ta jest następnie zwiększana przez „rzadkość” terminu w całym korpusie. Indeksator może również nadać większą wagę słowom, które pojawiają się w określonych miejscach w dokumencie. Bardzo ważne są słowa, które pojawiły się w tytule tagu <title>. Słowa znajdujące się w tagach <h1> nagłówka lub pogrubione <b> na stronie mogą być bardziej odpowiednie. Słowa, które pojawiają się w tekście kotwicy linków na stronach HTML lub w ich pobliżu są z pewnością postrzegane jako bardzo ważne. Słowa, które pojawiają się w znacznikach tekstowych <alt> z obrazkami, są odnotowywane, a także słowa, które pojawiają się w znacznikach meta.
Poza oryginalnym tekstem „Modern Information Retrieval” napisanym przez naukowca Gerarda Saltona (uważanego za ojca nowoczesnego wyszukiwania informacji) miałem w tamtych czasach szereg innych źródeł, które weryfikowały powyższe. Zarówno Brian Pinkerton, jak i Michael Maudlin (odpowiednio wynalazcy wyszukiwarek WebCrawler i Lycos) przekazali mi szczegółowe informacje na temat tego, w jaki sposób wykorzystano „klasyczne podejście Saltona”. I oba uświadomiły mi ograniczenia.
Co więcej, Larry Page i Sergey Brin podkreślili to samo w oryginalnym artykule, który napisali podczas uruchamiania prototypu Google. Wracam do tego, ponieważ jest to ważne w rozwianiu kolejnego mitu.
Ale najpierw, oto jak wyjaśniłem „klasyczne podejście Saltona” w 2002 roku. Pamiętaj, aby zauważyć odniesienie do „pary wagowej”.
Gdy wyszukiwarka utworzy swój „duży indeks”, moduł indeksujący mierzy „częstotliwość terminów” (tf) słowa w dokumencie, aby uzyskać „gęstość terminów”, a następnie mierzy „odwrotną częstotliwość dokumentu” (idf), która to obliczenie częstotliwości terminów w dokumencie; łączna liczba dokumentów; liczba dokumentów zawierających termin. Dzięki tym dalszym obliczeniom każdy Doc może być teraz oglądany jako wektor wartości tf x idf (wartości binarne lub liczbowe odpowiadające bezpośrednio lub pośrednio słowom Doc). To, co masz wtedy, to para wag terminowych. Można to przetransponować w następujący sposób: dokument zawiera ważoną listę słów; słowo ma ważoną listę dokumentów (para wag terminów).
Model przestrzeni wektorowej
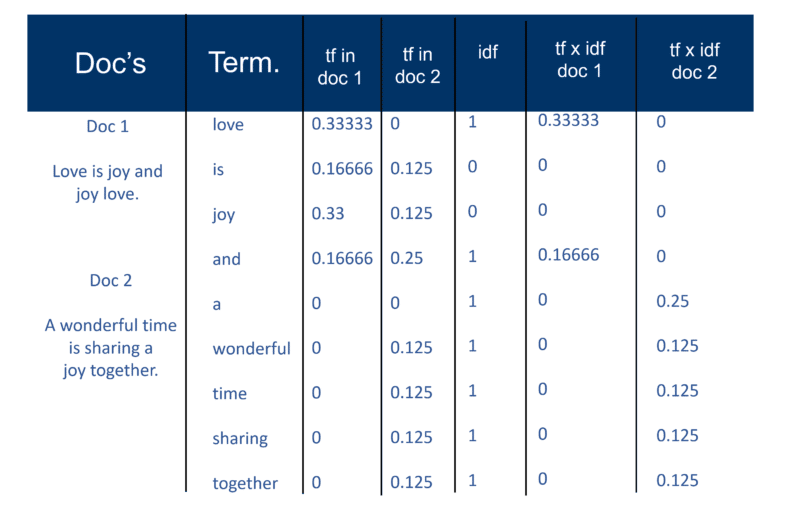
Teraz, gdy Dokumenty są wektorami z jednym składnikiem dla każdego terminu, stworzono „przestrzeń wektorów”, w której żyją wszystkie Dokumenty. Ale jakie są korzyści z tworzenia tego wszechświata Dokumentów, które teraz mają taką skalę?
W ten sposób, jeśli Doc 'd' (jako przykład) jest wektorem, łatwo jest znaleźć inne podobne do niego, a także znaleźć wektory w jego pobliżu.
Intuicyjnie można wtedy określić, że dokumenty znajdujące się blisko siebie w przestrzeni wektorowej mówią o tych samych rzeczach. W ten sposób wyszukiwarka może następnie utworzyć klastry słów lub dokumentów i dodać różne inne metody ważenia.
Jednak główną zaletą korzystania z wektorów terminów w wyszukiwarkach jest to, że mechanizm zapytań może traktować samo zapytanie jako bardzo krótki dokument. W ten sposób zapytanie staje się wektorem w tej samej przestrzeni wektorowej, a silnik zapytań może mierzyć bliskość każdego dokumentu.
Model przestrzeni wektorowej umożliwia użytkownikowi wyszukiwanie w wyszukiwarce „pojęć”, a nie tylko wyszukiwanie „leksykalne”. Jak widać, jeszcze 20 lat temu pojęcie pojęć i tematów, a nie tylko słów kluczowych, było bardzo popularne.
OK, zajmijmy się tą kwestią „gęstości słów kluczowych”. Słowo „gęstość” pojawia się w wyjaśnieniu, jak działa model przestrzeni wektorowej, ale tylko w odniesieniu do obliczeń w całym zbiorze dokumentów – a nie na pojedynczej stronie. Być może to właśnie to odniesienie sprawiło, że tak wielu SEO zaczęło używać analizatorów gęstości słów kluczowych na pojedynczych stronach.
Przez lata zauważyłem również, że wielu SEO, którzy odkrywają model przestrzeni wektorowej, stara się stosować klasyczne ważenie terminów tf x idf. Ale jest to znacznie mniej prawdopodobne, szczególnie w Google, jak stwierdzili założyciele Larry Page i Sergey Brin w swoim oryginalnym artykule o tym, jak działa Google – podkreślają słabą jakość wyników przy zastosowaniu samego klasycznego modelu:
„Na przykład standardowy model przestrzeni wektorowej próbuje zwrócić dokument, który jest najbardziej zbliżony do zapytania, biorąc pod uwagę, że zarówno zapytanie, jak i dokument są wektorami zdefiniowanymi przez wystąpienie słowa. W Internecie strategia ta często zwraca bardzo krótkie dokumenty, które zawierają tylko zapytanie i kilka słów”.
Istniało wiele wariantów prób obejścia „sztywności” modelu przestrzeni wektorowej. Przez lata postępów w sztucznej inteligencji i uczeniu maszynowym pojawiło się wiele odmian tego podejścia, które pozwala obliczyć wagę określonych słów i dokumentów w indeksie.
Możesz spędzić lata próbując dowiedzieć się, jakich formuł używa każda wyszukiwarka, nie mówiąc już o Google (chociaż możesz być pewien, którego nie używają, jak właśnie wspomniałem). Mając to na uwadze, powinno to rozwiać mit, że próba manipulowania gęstością słów kluczowych stron internetowych podczas ich tworzenia jest nieco zmarnowanym wysiłkiem.
Rozwiązanie problemu dostatku
Pierwsza generacja wyszukiwarek opierała się w dużej mierze na czynnikach na stronie w celu uzyskania rankingu.
Ale problem, który masz, używając wyłącznie technik rankingowych opartych na słowach kluczowych (poza tym, o czym właśnie wspomniałem o Google od pierwszego dnia) jest czymś znanym jako „problem obfitości”, który polega na tym, że sieć rośnie wykładniczo każdego dnia i wykładniczy wzrost w dokumentach zawierających to samo słowa kluczowe.
I to nasuwa pytanie na tym slajdzie, z którego korzystam od 2002 roku:

Można przypuszczać, że najbardziej autorytatywny byłby dyrygent orkiestry, który od wielu lat aranżuje i gra ten utwór z wieloma orkiestrami. Ale pracując wyłącznie nad technikami rankingu słów kluczowych, jest równie prawdopodobne, że student muzyki może być wynikiem numer jeden.
Jak rozwiązujesz ten problem?
Cóż, odpowiedzią jest analiza hiperłączy (czyli backlinków).
W kolejnej części wyjaśnię, w jaki sposób słowo „autorytet” weszło do leksykonu IR i SEO. Wyjaśnię również pierwotne źródło tego, co jest teraz określane jako EAT i na czym tak naprawdę się opiera.
Do tego czasu – bądź zdrowy, bądź bezpieczny i pamiętaj, jaka radość sprawia dyskusja na temat wewnętrznego funkcjonowania wyszukiwarek!
Opinie wyrażone w tym artykule są opiniami gościa i niekoniecznie Search Engine Land. Lista autorów personelu znajduje się tutaj.