
Revisión de las técnicas de indexación y clasificación de palabras clave: 20 años después
Publicado: 2022-08-04Cuando la bellota que se convertiría en la industria del SEO comenzó a crecer, la indexación y la clasificación en los motores de búsqueda se basaban exclusivamente en palabras clave.
El motor de búsqueda haría coincidir las palabras clave de una consulta con las palabras clave de su índice en paralelo con las palabras clave que aparecían en una página web.
Las páginas con la puntuación de relevancia más alta se clasificarían en orden utilizando una de las tres técnicas de recuperación más populares:
- modelo booleano
- modelo probabilístico
- Modelo de espacio vectorial
El modelo de espacio vectorial se convirtió en el más relevante para los motores de búsqueda.
Voy a revisar la explicación básica y algo simple del modelo clásico que usé en el pasado en este artículo (porque sigue siendo relevante en la combinación de motores de búsqueda).
En el camino, disiparemos uno o dos mitos, como la noción de "densidad de palabras clave" de una página web. Dejemos eso en la cama de una vez por todas.
La palabra clave: Una de las palabras más utilizadas en las ciencias de la información; para los especialistas en marketing: un misterio oculto
“¿Qué es una palabra clave?”
No tienes idea de cuántas veces escuché esa pregunta cuando estaba surgiendo la industria del SEO. Y después de dar una breve explicación, la pregunta de seguimiento sería: "Entonces, ¿cuáles son mis palabras clave, Mike?"
Honestamente, fue bastante difícil tratar de explicar a los especialistas en marketing que las palabras clave específicas utilizadas en una consulta fueron las que activaron las páginas web correspondientes en los resultados del motor de búsqueda.
Y sí, eso seguramente generaría otra pregunta: "¿Qué es una consulta, Mike?"
Hoy en día, términos como palabra clave, consulta, índice, clasificación y todos los demás son comunes en el léxico del marketing digital.
Sin embargo, como SEO, creo que es sumamente útil comprender de dónde se extraen y por qué y cómo esos términos todavía se aplican tanto ahora como en el pasado.
La ciencia de la recuperación de información (IR) es un subconjunto bajo el término general "inteligencia artificial". Pero IR en sí mismo también se compone de varios subconjuntos, incluido el de biblioteconomía y ciencias de la información.
Y ese es nuestro punto de partida para esta segunda parte de mi viaje por el camino de la memoria de SEO. (El primero, en caso de que te lo hayas perdido, fue: Hemos rastreado la web durante 32 años: ¿Qué ha cambiado?)
Esta serie continua de artículos se basa en lo que escribí en un libro sobre SEO hace 20 años, haciendo observaciones sobre el estado del arte a lo largo de los años y comparándolo con el lugar donde nos encontramos hoy.
La viejecita de la biblioteca
Entonces, habiendo resaltado que hay elementos de biblioteconomía bajo el título de Recuperación de información, permítanme relacionar dónde encajan en la búsqueda web.
Aparentemente, los bibliotecarios se identifican principalmente como viejecitas. Ciertamente, así pareció cuando entrevisté a varios científicos destacados en el nuevo campo emergente de la recuperación de información (IR) "web" hace tantos años.
Brian Pinkerton, inventor de WebCrawler, junto con Andrei Broder, vicepresidente de tecnología y científico jefe de Alta Vista, el motor de búsqueda número uno antes de Google y, de hecho, Craig Silverstein, director de tecnología de Google (y, en particular, el empleado número uno de Google), todos describieron su trabajo en este nuevo campo como tratar de conseguir un motor de búsqueda para emular a “la viejecita de la biblioteca”.
Las bibliotecas se basan en el concepto de ficha, cuyo propósito original era intentar organizar y clasificar todos los animales, plantas y minerales conocidos en el mundo.
Las fichas formaban la columna vertebral de todo el sistema bibliotecario, indexando grandes y variadas cantidades de información.
Además del nombre del autor, el título del libro, el tema y los "términos de índice" notables (también conocidos como palabras clave), etc., la tarjeta de índice también tendría la ubicación del libro. Y por lo tanto, después de un tiempo, cuando "la viejecita bibliotecaria" le preguntaba sobre un libro en particular, intuitivamente podría señalar no solo la sección de la biblioteca, sino probablemente incluso el estante en el que estaba el libro, brindando una respuesta personalizada. método de recuperación rápida.
Sin embargo, cuando expliqué la similitud de ese tipo de sistema de indexación en los motores de búsqueda como lo hice todos esos años atrás, tuve que agregar una advertencia que aún es importante comprender:
“Los motores de búsqueda más grandes se basan en índices de manera similar a una biblioteca. Habiendo almacenado una gran fracción de la web en índices masivos, necesitan devolver rápidamente documentos relevantes contra una palabra clave o frase determinada. Pero la variación de las páginas web, en términos de composición, calidad y contenido, es incluso mayor que la escala de los propios datos sin procesar. La web en su conjunto no tiene una estructura unificadora, con una enorme variante en el estilo de creación y contenido mucho más amplio y complejo que en las colecciones tradicionales de documentos de texto. Esto hace que sea casi imposible que un motor de búsqueda aplique técnicas estrictamente convencionales utilizadas en bibliotecas, sistemas de gestión de bases de datos y recuperación de información”.
Inevitablemente, lo que ocurrió entonces con las palabras clave y la forma en que escribimos para la web fue el surgimiento de un nuevo campo de comunicación.
Como expliqué en el libro, HTML podría verse como un nuevo género lingüístico y debería ser tratado como tal en futuros estudios lingüísticos. Hay mucho más en un documento de hipertexto que en un documento de "texto plano". Y eso da más indicaciones sobre de qué se trata una página web en particular cuando la leen humanos, así como el texto que se analiza, clasifica y categoriza a través de la minería de texto y la extracción de información por parte de los motores de búsqueda.
A veces todavía escucho que los SEO se refieren a los motores de búsqueda de páginas web de "lectura automática", pero ese término pertenece mucho más a la introducción relativamente reciente de los sistemas de "datos estructurados".
Como todavía tengo que explicar con frecuencia, un ser humano que lee una página web y los motores de búsqueda extraen información "sobre" una página no es lo mismo que los humanos que leen una página web y los motores de búsqueda "alimentan" datos estructurados.
El mejor ejemplo tangible que he encontrado es hacer una comparación entre una página web HTML moderna con datos estructurados "legibles por máquina" insertados y un pasaporte moderno. Eche un vistazo a la página de la imagen en su pasaporte y verá una sección principal con su imagen y texto para que los humanos la lean y una sección separada en la parte inferior de la página, que se creó específicamente para la lectura automática al deslizar o escanear.
Básicamente, una página web moderna está estructurada como un pasaporte moderno. Curiosamente, hace 20 años hice referencia a la combinación hombre/máquina con este pequeño hecho:
“En 1747, el médico y filósofo francés Julien Offroy de la Mettrie publicó una de las obras más importantes de la historia de las ideas. Lo tituló L'HOMME MACHINE, que se traduce mejor como "hombre, una máquina". A menudo, escuchará la frase 'de hombres y máquinas' y esta es la idea fundamental de la inteligencia artificial”.
Enfaticé la importancia de los datos estructurados en mi artículo anterior y espero escribir algo para usted que creo que será de gran ayuda para comprender el equilibrio entre la lectura humana y la lectura automática. Lo simplifiqué totalmente de esta manera en 2002 para proporcionar una racionalización básica:
- Datos: una representación de hechos o ideas de manera formal, capaz de ser comunicada o manipulada por algún proceso.
- Información: el significado que un humano asigna a los datos por medio de las convenciones conocidas utilizadas en su representación.
Por lo tanto:
- Los datos están relacionados con hechos y máquinas.
- La información está relacionada con el significado y los seres humanos.
Hablemos de las características del texto por un minuto y luego cubriré cómo el texto se puede representar como datos en algo "algo incomprendido" (digamos) en la industria de SEO llamado modelo de espacio vectorial.
Las palabras clave más importantes en el índice de un motor de búsqueda frente a las palabras más populares
¿Alguna vez has oído hablar de la Ley de Zipf?
Nombrado en honor al profesor de lingüística de Harvard George Kingsley Zipf, predice el fenómeno de que, mientras escribimos, usamos palabras familiares con mucha frecuencia.
Zipf dijo que su ley se basa en el principal predictor del comportamiento humano: esforzarse por minimizar el esfuerzo. Por lo tanto, la ley de Zipf se aplica a casi cualquier campo relacionado con la producción humana.
Esto significa que también tenemos una relación restringida entre el rango y la frecuencia en el lenguaje natural.
La mayoría de las grandes colecciones de documentos de texto tienen características estadísticas similares. Conocer estas estadísticas es útil porque influyen en la eficacia y la eficiencia de las estructuras de datos utilizadas para indexar documentos. Muchos modelos de recuperación se basan en ellos.
Hay patrones de ocurrencias en la forma en que escribimos: generalmente buscamos el método más fácil, más corto, menos complicado y más rápido posible. Entonces, la verdad es que solo usamos las mismas palabras simples una y otra vez.
Como ejemplo, todos esos años atrás, encontré algunas estadísticas de un experimento en el que los científicos tomaron una colección de 131 MB (que era big data en ese entonces) de 46,500 artículos de periódicos (19 millones de ocurrencias de términos).
Aquí están los datos de las 10 palabras principales y cuántas veces se usaron dentro de este corpus. Entenderás el punto bastante rápido, creo:
Frecuencia de palabras
el: 1130021
de 547311
al 516635
un 464736
en 390819
y 387703
que 204351
para 199340
es 152483
dijo 148302
Recuerde, todos los artículos incluidos en el corpus fueron escritos por periodistas profesionales. Pero si observa las diez palabras más utilizadas, difícilmente podría hacer una sola oración sensata con ellas.
Debido a que estas palabras comunes aparecen con tanta frecuencia en el idioma inglés, los motores de búsqueda las ignorarán como "palabras vacías". Si las palabras más populares que usamos no brindan mucho valor a un sistema de indexación automatizado, ¿qué palabras lo hacen?
Como ya se ha señalado, ha habido mucho trabajo en el campo de los sistemas de recuperación de información (IR). Los enfoques estadísticos se han aplicado ampliamente debido al ajuste deficiente del texto a los modelos de datos basados en lógicas formales (p. ej., bases de datos relacionales).
Entonces, en lugar de requerir que los usuarios puedan anticipar las palabras exactas y las combinaciones de palabras que pueden aparecer en los documentos de interés, el IR estadístico les permite a los usuarios simplemente ingresar una cadena de palabras que es probable que aparezcan en un documento.
Luego, el sistema tiene en cuenta la frecuencia de estas palabras en una colección de texto y en documentos individuales, para determinar qué palabras son probablemente las mejores pistas de relevancia. Se calcula una puntuación para cada documento en función de las palabras que contiene y se recuperan los documentos con la puntuación más alta.

Tuve la suerte de entrevistar a un investigador líder en el campo de IR cuando me investigaba a mí mismo para el libro en 2001. En ese momento, Andrei Broder era científico jefe de Alta Vista (actualmente ingeniero distinguido en Google) y estábamos discutiendo el tema. de “vectores de términos” y le pedí que me diera una explicación sencilla de lo que son.
Me explicó cómo, al “ponderar” los términos por importancia en el índice, puede notar la aparición de la palabra “de” millones de veces en el corpus. Esta es una palabra que no va a tener ningún "peso", dijo. Pero si ve algo como la palabra "hemoglobina", que es una palabra mucho más rara en el corpus, entonces esta tendrá algo de peso.
Quiero dar un paso atrás rápido aquí antes de explicar cómo se crea el índice y disipar otro mito que ha persistido a lo largo de los años. Y ahí es donde mucha gente cree que Google (y otros motores de búsqueda) en realidad están descargando sus páginas web y almacenándolas en un disco duro.
No para nada. Ya tenemos un lugar para hacerlo, se llama World Wide Web.
Sí, Google mantiene una instantánea "en caché" de la página para una recuperación rápida. Pero cuando el contenido de esa página cambia, la próxima vez que se rastrea la página, la versión almacenada en caché también cambia.
Es por eso que nunca puedes encontrar copias de tus páginas web antiguas en Google. Para eso, su único recurso real es Internet Archive (también conocido como The Wayback Machine).
De hecho, cuando se rastrea su página, básicamente se desmantela. El texto se analiza (se extrae) del documento.
Cada documento recibe su propio identificador junto con los detalles de la ubicación (URL) y los "datos sin procesar" se envían al módulo indexador. Las palabras/términos se guardan con el ID del documento asociado en el que aparecieron.
Aquí hay un ejemplo muy simple usando dos Documentos y el texto que contienen que creé hace 20 años.
Construcción del índice de recuperación
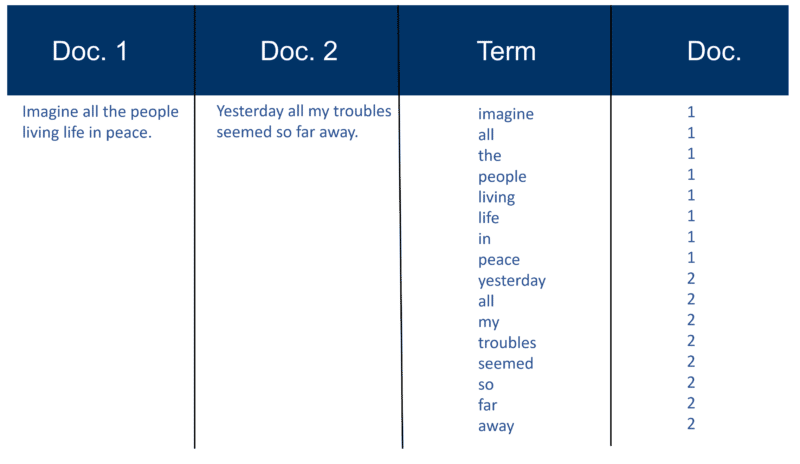
Una vez analizados todos los documentos, el archivo invertido se ordena por términos:
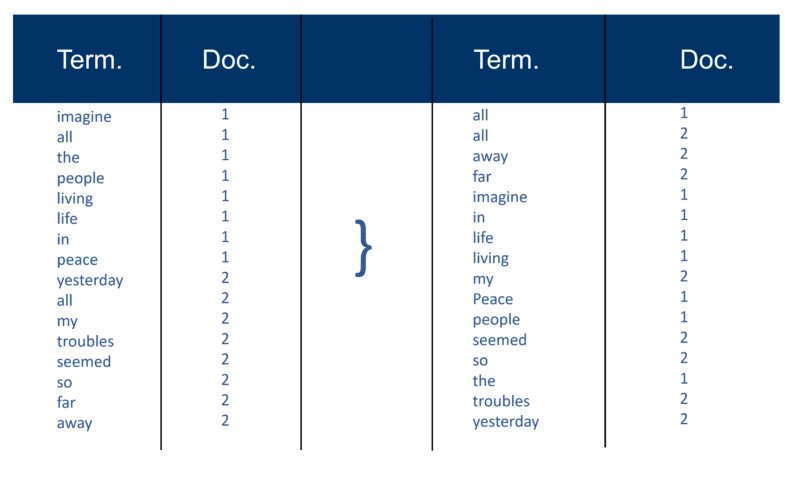
En mi ejemplo, esto parece bastante simple al comienzo del proceso, pero las publicaciones (como se las conoce en términos de recuperación de información) en el índice van en un Doc a la vez. Una vez más, con millones de documentos, puede imaginar la cantidad de potencia de procesamiento requerida para convertir esto en la enorme "visión inteligente de términos" que se simplifica arriba, primero por término y luego por Doc dentro de cada término.
Notarás mi referencia a "millones de documentos" de hace tantos años. Por supuesto, estamos en miles de millones (incluso billones) en estos días. En mi explicación básica de cómo se crea el índice, continué con esto:
Cada motor de búsqueda crea su propio diccionario personalizado (o léxico tal como es; recuerde que muchas páginas web no están escritas en inglés), que debe incluir cada nuevo 'término' descubierto después de un rastreo (piense en la forma en que, al usar un procesador de texto como Microsoft Word, con frecuencia tiene la opción de agregar una palabra a su propio diccionario personalizado, es decir, algo que no ocurre en el diccionario de inglés estándar). Una vez que el motor de búsqueda tenga su índice 'grande', algunos términos serán más importantes que otros. Entonces, cada término merece su propio peso (valor). Gran parte del factor de ponderación depende del término en sí. Por supuesto, esto es bastante sencillo cuando lo piensa, por lo que se le da más peso a una palabra con más ocurrencias, pero este peso luego aumenta por la "rareza" del término en todo el corpus. El indexador también puede dar más 'peso' a las palabras que aparecen en ciertos lugares del Doc. Las palabras que aparecieron en la etiqueta del título <título> son muy importantes. Las palabras que están en las etiquetas de título <h1> o las que están en negrita <b> en la página pueden ser más relevantes. Las palabras que aparecen en el texto de anclaje de los enlaces en las páginas HTML, o cerca de ellas, se consideran muy importantes. Se anotan las palabras que aparecen en las etiquetas de texto <alt> con imágenes, así como las palabras que aparecen en las metaetiquetas.
Además del texto original "Recuperación de información moderna" escrito por el científico Gerard Salton (considerado el padre de la recuperación de información moderna), tuve una serie de otros recursos en el pasado que verificaron lo anterior. Tanto Brian Pinkerton como Michael Maudlin (inventores de los motores de búsqueda WebCrawler y Lycos respectivamente) me brindaron detalles sobre cómo se utilizó “el enfoque clásico de Salton”. Y ambos me hicieron consciente de las limitaciones.
No solo eso, Larry Page y Sergey Brin destacaron lo mismo en el artículo original que escribieron en el lanzamiento del prototipo de Google. Estoy volviendo a esto ya que es importante para ayudar a disipar otro mito.
Pero primero, así es como expliqué el "enfoque clásico de Salton" en 2002. Asegúrese de tener en cuenta la referencia a "un par de pesos de término".
Una vez que el motor de búsqueda ha creado su 'índice grande', el módulo indexador mide la 'frecuencia de término' (tf) de la palabra en un documento para obtener la 'densidad de término' y luego mide la 'frecuencia de documento inversa' (idf) que es un cálculo de la frecuencia de términos en un documento; el número total de documentos; el número de documentos que contienen el término. Con este cálculo adicional, cada Doc ahora se puede ver como un vector de valores tf x idf (valores binarios o numéricos que corresponden directa o indirectamente a las palabras del Doc). Entonces lo que tienes es un par de peso de término. Podría transponer esto como: un documento tiene una lista ponderada de palabras; una palabra tiene una lista ponderada de documentos (un par de pesos de términos).
El modelo de espacio vectorial
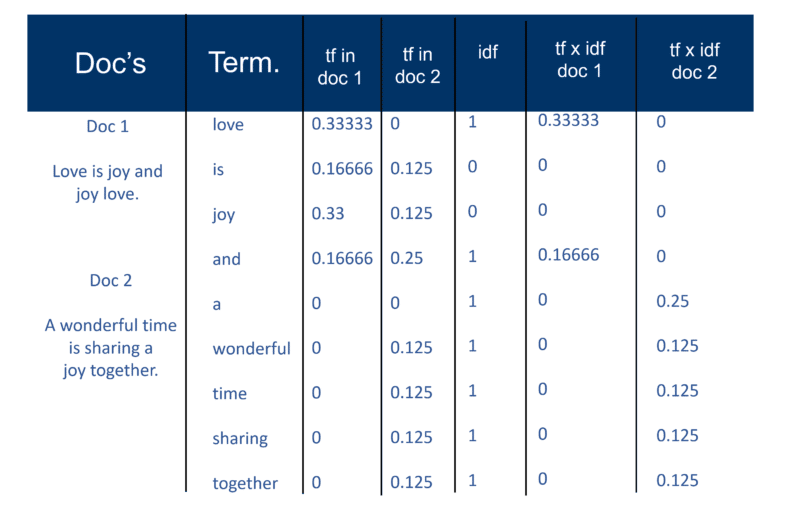
Ahora que los Documentos son vectores con un componente para cada término, lo que se ha creado es un 'espacio vectorial' donde viven todos los Documentos. Pero, ¿cuáles son los beneficios de crear este universo de documentos que ahora tienen todos esta magnitud?
De esta manera, si Doc 'd' (como ejemplo) es un vector, entonces es fácil encontrar otros similares y también encontrar vectores cerca de él.
Intuitivamente, puede determinar que los documentos, que están muy juntos en el espacio vectorial, hablan de las mismas cosas. Al hacer esto, un motor de búsqueda puede crear grupos de palabras o documentos y agregar varios otros métodos de ponderación.
Sin embargo, el principal beneficio de usar vectores de términos para los motores de búsqueda es que el motor de consulta puede considerar una consulta en sí misma como un documento muy breve. De esta forma, la consulta se convierte en un vector en el mismo espacio vectorial y el motor de consultas puede medir la proximidad de cada Doc.
El modelo de espacio vectorial permite al usuario consultar el motor de búsqueda por "conceptos" en lugar de una búsqueda puramente "léxica". Como puede ver aquí, incluso hace 20 años, la noción de conceptos y temas en lugar de solo palabras clave estaba muy en juego.
Bien, abordemos este asunto de la "densidad de palabras clave". La palabra "densidad" aparece en la explicación de cómo funciona el modelo de espacio vectorial, pero solo cuando se aplica al cálculo en todo el corpus de documentos, no en una sola página. Tal vez sea esa referencia la que hizo que tantos SEO comenzaran a usar analizadores de densidad de palabras clave en páginas individuales.
También he notado a lo largo de los años que muchos SEO, que descubren el modelo de espacio vectorial, tienden a intentar aplicar la ponderación clásica de términos tf x idf. Pero es mucho menos probable que funcione, especialmente en Google, como afirmaron los fundadores Larry Page y Sergey Brin en su artículo original sobre cómo funciona Google: enfatizan la mala calidad de los resultados cuando se aplica solo el modelo clásico:
“Por ejemplo, el modelo de espacio vectorial estándar intenta devolver el documento que más se aproxima a la consulta, dado que tanto la consulta como el documento son vectores definidos por su ocurrencia de palabras. En la web, esta estrategia a menudo devuelve documentos muy cortos que son solo la consulta más unas pocas palabras”.
Ha habido muchas variantes para intentar eludir la "rigidez" del modelo de espacio vectorial. Y a lo largo de los años, con los avances en inteligencia artificial y aprendizaje automático, existen muchas variaciones en el enfoque que puede calcular la ponderación de palabras y documentos específicos en el índice.
Podría pasar años tratando de averiguar qué fórmulas está usando cualquier motor de búsqueda, y mucho menos Google (aunque puede estar seguro de cuál no está usando, como acabo de señalar). Entonces, teniendo esto en cuenta, debería disipar el mito de que tratar de manipular la densidad de palabras clave de las páginas web cuando las creas es un esfuerzo algo inútil.
Resolviendo el problema de la abundancia
La primera generación de motores de búsqueda se basó en gran medida en los factores de la página para la clasificación.
Pero el problema que tiene al usar técnicas de clasificación puramente basadas en palabras clave (más allá de lo que acabo de mencionar sobre Google desde el primer día) es algo conocido como "el problema de la abundancia" que considera que la web crece exponencialmente todos los días y el crecimiento exponencial de los documentos que contienen el mismo palabras clave
Y eso plantea la pregunta en esta diapositiva que he estado usando desde 2002:

Puede suponer que el director de orquesta, que ha estado arreglando y tocando la pieza durante muchos años con muchas orquestas, sería el más autorizado. Pero trabajando únicamente en técnicas de clasificación de palabras clave, es muy probable que el estudiante de música sea el resultado número uno.
¿Cómo resuelves ese problema?
Bueno, la respuesta es el análisis de hipervínculos (también conocido como backlinks).
En mi próxima entrega, explicaré cómo la palabra “autoridad” ingresó al léxico IR y SEO. Y también explicaré la fuente original de lo que ahora se conoce como EAT y en qué se basa realmente.
Hasta entonces, manténgase bien, manténgase a salvo y recuerde la alegría que hay al discutir el funcionamiento interno de los motores de búsqueda.
Las opiniones expresadas en este artículo pertenecen al autor invitado y no necesariamente a Search Engine Land. Los autores del personal se enumeran aquí.