
重新审视索引和关键字排名技术:20 年后
已发表: 2022-08-04当将成为 SEO 行业的橡子开始增长时,搜索引擎的索引和排名都纯粹基于关键字。
搜索引擎会将查询中的关键字与其索引中的关键字与出现在网页上的关键字相匹配。
具有最高相关性分数的页面将使用三种最流行的检索技术之一按顺序排列:
- 布尔模型
- 概率模型
- 向量空间模型
向量空间模型成为与搜索引擎最相关的模型。
我将重新审视我在本文中使用的经典模型的基本且有些简单的解释(因为它在搜索引擎组合中仍然相关)。
在此过程中,我们将消除一两个神话——例如网页的“关键字密度”的概念。 让我们一劳永逸地把它放在床上。
关键字:信息科学中最常用的词之一; 对营销人员来说——一个笼罩着的谜团
“什么是关键词?”
你不知道当 SEO 行业兴起时我听到了多少次这个问题。 在我给出一个简单的解释之后,接下来的问题是:“那么,我的关键词是什么,迈克?”
老实说,很难向营销人员解释查询中使用的特定关键字是什么触发了搜索引擎结果中的相应网页。
是的,这几乎肯定会引发另一个问题:“什么是查询,迈克?”
今天,关键字、查询、索引、排名等术语在数字营销词典中很常见。
但是,作为 SEO,我相信了解它们的来源以及为什么以及如何这些术语现在仍然像过去一样适用是非常有用的。
信息检索 (IR) 科学是“人工智能”这一总称下的一个子集。 但 IR 本身也由几个子集组成,包括图书馆和信息科学的子集。
这就是我在 SEO 记忆通道中漫步的第二部分的起点。 (如果你错过了,我的第一个是:我们已经爬网 32 年了:有什么变化?)
这个正在进行的系列文章基于我 20 年前在一本关于 SEO 的书中所写的内容,对这些年来的最新技术进行了观察,并将其与我们今天的情况进行了比较。
书房里的小老太太
因此,在强调了信息检索旗帜下的图书馆学元素之后,让我来谈谈它们适合网络搜索的位置。
看起来,图书馆员主要被认定为小老太太。 多年前,当我采访了新兴的“网络”信息重审 (IR) 领域的几位领先科学家时,确实出现了这种情况。
WebCrawler 的发明者 Brian Pinkerton 以及 Alta Vista 的技术副总裁兼首席科学家 Andrei Broder 以及 Google 的技术总监 Craig Silverstein(尤其是 Google 的第一名员工)都描述了他们在这个新领域的工作是试图让搜索引擎模仿“图书馆里的小老太太”。
图书馆基于索引卡的概念——其最初目的是尝试对世界上所有已知的动物、植物和矿物进行组织和分类。
索引卡构成了整个图书馆系统的支柱,索引了大量不同数量的信息。
除了作者姓名、书名、主题和值得注意的“索引词”(也称为关键字)等,索引卡还会包含书的位置。 因此,过了一会儿,当你向“小老太太图书管理员”询问某本书时,她不仅能直观地指出图书馆的哪个部分,甚至可能指向这本书所在的书架,从而提供个性化的快速检索方法。
然而,当我解释这种类型的索引系统在搜索引擎中的相似性时,就像我多年前所做的那样,我不得不添加一个仍然很重要的警告:
“最大的搜索引擎是以类似于图书馆的方式基于索引的。 在将大部分网络存储在海量索引中之后,他们需要快速返回针对给定关键字或短语的相关文档。 但是网页的变化,在组成、质量和内容方面,甚至比原始数据本身的规模还要大。 整个网络没有统一的结构,在创作风格和内容方面有着巨大的变化,比传统的文本文档集合更广泛、更复杂。 这使得搜索引擎几乎不可能应用图书馆、数据库管理系统和信息检索中使用的严格传统技术。”
不可避免地,关键词和我们为网络写作的方式发生的事情是一个新的交流领域的出现。
正如我在书中解释的那样,HTML 可以被视为一种新的语言类型,在未来的语言研究中也应该这样对待。 超文本文档比“纯文本”文档要多得多。 这更多地表明了特定网页在人类阅读时的含义,以及通过文本挖掘和搜索引擎信息提取对文本进行分析、分类和分类。
有时我仍然听到 SEO 提到搜索引擎“机器阅读”网页,但这个词更多地属于相对较新引入的“结构化数据”系统。
正如我经常要解释的那样,人类阅读网页和搜索引擎文本挖掘和提取“关于”页面的信息与人类阅读网页和搜索引擎“馈送”结构化数据不同。
我发现的最好的具体示例是在插入“机器可读”结构化数据的现代 HTML 网页和现代护照之间进行比较。 看一下护照上的图片页,您会看到一个主要部分,其中包含供人类阅读的图片和文字,而页面底部则有一个单独的部分,专门用于通过滑动或扫描进行机器阅读。
从本质上讲,现代网页的结构有点像现代护照。 有趣的是,20 年前,我用这个小事实引用了人机组合:
“1747 年,法国医生和哲学家 Julien Offroy de la Mettrie 发表了思想史上最具开创性的著作之一。 他将其命名为 L'HOMME MACHINE,最好翻译为“人,一台机器”。 通常,你会听到‘人与机器’这个词,这就是人工智能的根本理念。”
我在上一篇文章中强调了结构化数据的重要性,并希望为您写一些我相信对理解人类阅读和机器阅读之间的平衡非常有帮助的东西。 早在 2002 年,我就以这种方式完全简化了它,以提供基本的合理化:
- 数据:以形式化的方式表示事实或想法,能够通过某些过程进行交流或操纵。
- 信息:人类通过其表示中使用的已知约定赋予数据的含义。
所以:
- 数据与事实和机器有关。
- 信息与意义和人有关。
让我们讨论一下文本的特征,然后我将介绍如何在 SEO 行业中“有点误解”(我们应该说)的东西中将文本表示为数据,称为向量空间模型。
搜索引擎索引中最重要的关键词与最流行的词
听说过齐夫定律吗?
它以哈佛语言学教授 George Kingsley Zipf 的名字命名,它预测了这样一种现象,即在我们写作时,我们会频繁使用熟悉的单词。
齐夫说,他的法则是基于人类行为的主要预测指标:努力减少努力。 因此,齐夫定律几乎适用于任何涉及人类生产的领域。
这意味着我们在自然语言中的排名和频率之间也存在受限关系。
大多数大型文本文档集合具有相似的统计特征。 了解这些统计数据会很有帮助,因为它们会影响用于索引文档的数据结构的有效性和效率。 许多检索模型依赖于它们。
我们写作的方式有一些发生的模式——我们通常会寻找最简单、最短、参与最少、最快的方法。 所以,事实是,我们只是一遍又一遍地使用相同的简单词。
例如,多年前,我从一项实验中发现了一些统计数据,科学家收集了 131MB 的数据(当时是大数据),其中包含 46,500 篇报纸文章(1900 万个术语出现)。
这是前 10 个单词的数据以及它们在该语料库中的使用次数。 你会很快明白这一点,我认为:
词频
该:1130021
547311 的
至 516635
464736
在 390819
和 387703
那 204351
为 199340
是 152483
说 148302
请记住,语料库中包含的所有文章都是由专业记者撰写的。 但是,如果您查看前十个最常用的词,您几乎无法从中做出一个明智的句子。
由于这些常用词在英语中如此频繁地出现,搜索引擎会将它们视为“停用词”而忽略。 如果我们使用的最流行的词不能为自动索引系统提供太多价值,那么哪些词可以?
如前所述,在信息检索(IR)系统领域有很多工作。 由于文本与基于形式逻辑的数据模型(例如关系数据库)的拟合不佳,统计方法已被广泛应用。
因此,与其要求用户能够预测可能出现在感兴趣的文档中的确切单词和单词组合,统计 IR 让用户只需输入可能出现在文档中的一串单词。
然后,系统会考虑这些词在文本集合和单个文档中的出现频率,以确定哪些词可能是最好的相关线索。 根据每个文档包含的单词计算得分,并检索得分最高的文档。
我有幸在 2001 年为这本书进行研究时采访了 IR 领域的一位领先研究人员。当时,Andrei Broder 是 Alta Vista 的首席科学家(现任谷歌杰出工程师),我们正在讨论这个话题关于“术语向量”,我问他是否可以简单地解释一下它们是什么。
他向我解释了,当对索引中的重要性“加权”术语时,他可能会注意到“of”这个词在语料库中出现了数百万次。 他说,这是一个根本没有“分量”的词。 但如果他看到像“血红蛋白”这样的词,这个词在语料库中是一个非常罕见的词,那么这个词就会有一些分量。
在解释索引是如何创建的之前,我想先退后一步,并消除多年来挥之不去的另一个神话。 这就是许多人认为谷歌(和其他搜索引擎)实际上正在下载您的网页并将它们存储在硬盘上的原因。

不,一点也不。 我们已经有一个地方可以做到这一点,它被称为万维网。
是的,Google 会维护页面的“缓存”快照,以便快速检索。 但是,当该页面内容更改时,下次抓取该页面时,缓存的版本也会更改。
这就是为什么您永远无法在 Google 上找到旧网页的副本的原因。 为此,您唯一真正的资源是 Internet 档案(又名 The Wayback Machine)。
事实上,当你的页面被抓取时,它基本上被拆除了。 从文档中解析(提取)文本。
每个文档都有自己的标识符以及位置(URL)的详细信息,“原始数据”被转发到索引器模块。 单词/术语与其出现的相关文档 ID 一起保存。
这是一个非常简单的示例,它使用了我 20 年前创建的两个文档及其包含的文本。
召回指数构建
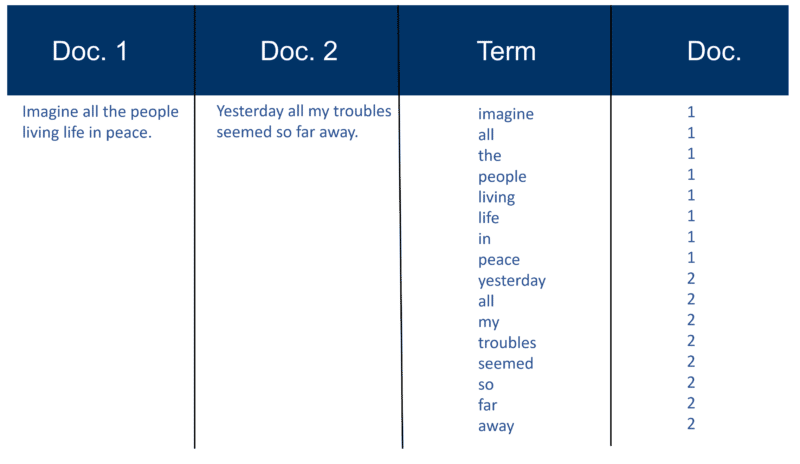
解析完所有文档后,倒排文件按术语排序:
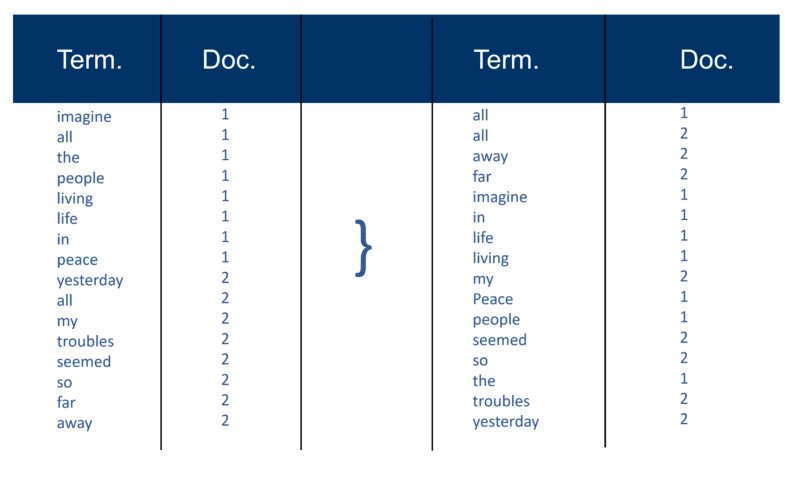
在我的示例中,这在流程开始时看起来相当简单,但是索引的发布(在信息检索术语中称为)一次进入一个文档。 同样,对于数以百万计的文档,您可以想象将其转化为上面简化的大量“术语视图”所需的处理能力,首先是术语,然后是每个术语中的文档。
您会注意到我在多年前提到的“数百万个文档”。 当然,这些天我们已经达到了数十亿(甚至数万亿)。 在我对如何创建索引的基本解释中,我继续说:
每个搜索引擎都会创建自己的自定义词典(或词典——请记住,许多网页不是用英语编写的),其中必须包含爬网后发现的每个新“术语”(想想当使用像 Microsoft Word 这样的文字处理器,您经常可以选择将单词添加到您自己的自定义词典中,即标准英语词典中没有出现的内容)。 一旦搜索引擎有了它的“大”索引,一些术语就会比其他术语更重要。 因此,每个术语都值得拥有自己的权重(值)。 许多权重因子取决于术语本身。 当然,当您考虑它时,这是相当直截了当的,因此对出现次数更多的单词赋予了更大的权重,但是随着该词在整个语料库中的“稀有性”而增加了权重。 索引器还可以为出现在文档中某些位置的单词赋予更多的“权重”。 出现在标题标签 <title> 中的单词非常重要。 <h1> 标题标签中的词或页面上粗体 <b> 中的词可能更相关。 出现在 HTML 页面链接的锚文本中或靠近它们的词当然被视为非常重要。 出现在带有图像的 <alt> 文本标签中的单词以及出现在元标签中的单词都会被记录下来。
除了科学家 Gerard Salton(被认为是现代信息检索之父)撰写的原始文本“现代信息检索”之外,我还有许多其他资源可以验证上述内容。 Brian Pinkerton 和 Michael Maudlin(分别是搜索引擎 WebCrawler 和 Lycos 的发明者)都向我详细介绍了如何使用“经典的 Salton 方法”。 两者都让我意识到了局限性。
不仅如此,拉里佩奇和谢尔盖布林在他们在谷歌原型发布时写的原始论文中强调了同样的内容。 我回到这一点,因为它对帮助消除另一个神话很重要。
但首先,这是我在 2002 年解释“经典索尔顿方法”的方式。请务必注意对“术语权重对”的引用。
一旦搜索引擎创建了“大索引”,索引器模块就会测量文档中单词的“词频”(tf)以获得“词频密度”,然后测量“逆文档频率”(idf)是文档中术语频率的计算; 文件总数; 包含该术语的文档数量。 通过这种进一步的计算,现在可以将每个 Doc 视为 tf x idf 值的向量(直接或间接对应于 Doc 的单词的二进制或数值)。 然后你有一个术语权重对。 您可以将其转置为:文档具有加权的单词列表; 一个词有一个加权的文档列表(一个词权重对)。
向量空间模型
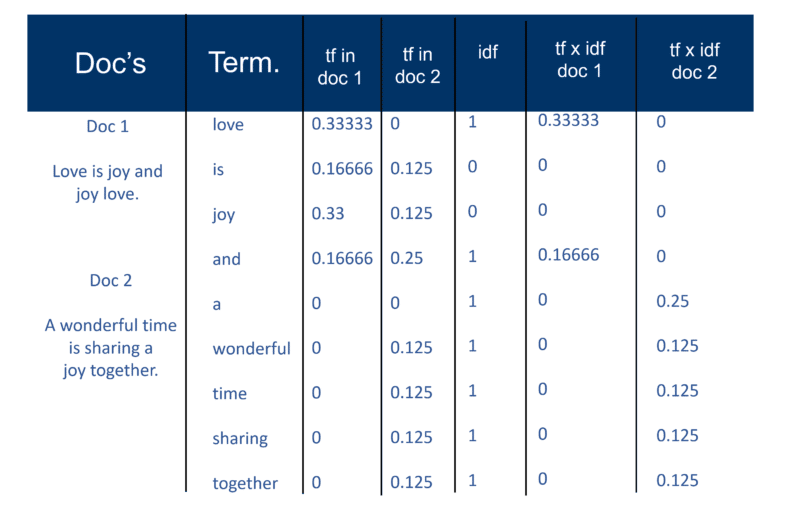
既然 Docs 是每个术语都有一个组件的向量,那么所创建的是所有 Docs 都存在的“向量空间”。 但是,创建这个现在都具有这种规模的 Docs 世界有什么好处呢?
这样,如果 Doc 'd'(例如)是一个向量,那么很容易找到其他喜欢它的人,也很容易找到它附近的向量。
直观地说,您可以确定在向量空间中靠得很近的文档谈论相同的事情。 通过这样做,搜索引擎可以创建单词或文档的聚类并添加各种其他加权方法。
然而,对搜索引擎使用术语向量的主要好处是查询引擎可以将查询本身视为一个非常短的文档。 这样,查询就变成了同一个向量空间中的一个向量,查询引擎可以测量每个 Doc 与它的接近程度。
向量空间模型允许用户在搜索引擎中查询“概念”而不是纯粹的“词汇”搜索。 正如您在此处看到的,即使在 20 年前,概念和主题的概念(而不仅仅是关键字)也非常重要。
好的,让我们解决这个“关键字密度”问题。 “密度”一词确实出现在向量空间模型如何工作的解释中,但仅适用于整个文档语料库的计算,而不是单个页面。 也许正是这一参考使如此多的 SEO 开始在单页上使用关键字密度分析器。
多年来,我还注意到许多发现向量空间模型的 SEO 倾向于尝试应用经典的 tf x idf 术语权重。 但这不太可能奏效,尤其是在谷歌,正如创始人拉里佩奇和谢尔盖布林在他们关于谷歌如何运作的原始论文中所说的那样——他们强调单独应用经典模型时结果质量很差:
“例如,标准向量空间模型试图返回最接近查询的文档,因为查询和文档都是由它们的单词出现定义的向量。 在网络上,这种策略通常会返回非常短的文档,只有查询加上几个单词。”
有许多变体试图绕过向量空间模型的“刚性”。 多年来,随着人工智能和机器学习的进步,计算索引中特定单词和文档的权重的方法有很多变化。
您可能会花费数年时间试图弄清楚任何搜索引擎正在使用哪些公式,更不用说 Google(尽管您可以确定他们没有使用哪个公式,正如我刚刚指出的那样)。 因此,考虑到这一点,它应该消除在创建网页时试图操纵网页的关键字密度是一种浪费努力的神话。
解决丰富问题
第一代搜索引擎严重依赖页面因素进行排名。
但是,您使用纯基于关键字的排名技术(除了我刚从第一天开始提到的关于 Google 的问题)所遇到的问题就是所谓的“丰度问题”,它认为网络每天呈指数级增长,并且包含相同内容的文档呈指数级增长关键字。
这在这张幻灯片上提出了我自 2002 年以来一直在使用的问题:

您可以假设,多年来一直与许多管弦乐队一起编曲和演奏该作品的管弦乐队指挥将是最权威的。 但仅在关键字排名技术上工作,音乐学生很可能成为第一名。
你如何解决这个问题?
好吧,答案是超链接分析(又名反向链接)。
在我的下一部分中,我将解释“权威”这个词是如何进入 IR 和 SEO 词典的。 我还将解释现在称为 EAT 的原始来源以及它的实际基础。
在那之前——保持安全,记住讨论搜索引擎的内部运作是多么快乐!
本文中表达的观点是客座作者的观点,不一定是 Search Engine Land。 工作人员作者在这里列出。