
Новый взгляд на методы индексирования и ранжирования ключевых слов: 20 лет спустя
Опубликовано: 2022-08-04Когда желудь, который впоследствии стал индустрией SEO, начал расти, индексация и ранжирование в поисковых системах основывались исключительно на ключевых словах.
Поисковая система будет сопоставлять ключевые слова в запросе с ключевыми словами в своем индексе параллельно с ключевыми словами, которые появляются на веб-странице.
Страницы с наивысшим показателем релевантности будут ранжироваться по порядку с использованием одного из трех самых популярных методов поиска:
- Булева модель
- Вероятностная модель
- Векторная космическая модель
Модель векторного пространства стала наиболее актуальной для поисковых систем.
Я собираюсь вернуться к основному и несколько простому объяснению классической модели, которую я использовал в свое время в этой статье (потому что она все еще актуальна для поисковых систем).
Попутно мы развеем один или два мифа, например, о «плотности ключевых слов» на веб-странице. Давайте уложим его в постель раз и навсегда.
Ключевое слово: одно из наиболее часто используемых слов в информатике; для маркетологов – покрытая тайной
«Что такое ключевое слово?»
Вы не представляете, сколько раз я слышал этот вопрос, когда зарождалась индустрия SEO. И после того, как я дал краткое объяснение, последовал следующий вопрос: «Итак, какие у меня ключевые слова, Майк?»
Честно говоря, было довольно сложно объяснить маркетологам, что определенные ключевые слова, использованные в запросе, вызывали соответствующие веб-страницы в результатах поиска.
И да, это почти наверняка вызовет еще один вопрос: «Что за вопрос, Майк?»
Сегодня такие термины, как ключевое слово, запрос, индекс, ранжирование и все остальные, широко распространены в лексиконе цифрового маркетинга.
Тем не менее, как специалист по поисковой оптимизации, я считаю чрезвычайно полезным понимать, откуда они взяты, почему и как эти термины по-прежнему применяются так же часто, как и раньше.
Наука информационного поиска (IR) является частью общего термина «искусственный интеллект». Но сами ИО также состоят из нескольких подмножеств, в том числе библиотечного и информационного.
И это наша отправная точка для второй части моего блуждания по переулку воспоминаний о SEO. (Моим первым, если вы пропустили, было: Мы сканировали Интернет 32 года: что изменилось?)
Эта продолжающаяся серия статей основана на том, что я написал в книге о SEO 20 лет назад, делая наблюдения о состоянии дел за эти годы и сравнивая их с тем, что мы имеем сегодня.
Маленькая старушка в библиотеке
Итак, подчеркнув, что под лозунгом информационного поиска есть элементы библиотечного дела, позвольте мне рассказать, где они вписываются в веб-поиск.
По-видимому, библиотекарей в основном идентифицируют как маленьких старушек. Это определенно выглядело так, когда я брал интервью у нескольких ведущих ученых в зарождающейся новой области «сетевого» повторного просмотра информации (IR) много лет назад.
Брайан Пинкертон, изобретатель WebCrawler, вместе с Андреем Бродером, вице-президентом по технологиям и главным научным сотрудником Alta Vista, поисковой системы номер один перед Google, и Крейгом Сильверстайном, директором по технологиям Google (и, что особенно важно, сотрудником Google номер один) — все они описали их работа в этой новой области как попытка заставить поисковую систему подражать «маленькой старушке в библиотеке».
Библиотеки основаны на концепции каталожных карточек, первоначальной целью которых была попытка систематизировать и классифицировать все известные в мире животные, растения и минералы.
Каталожные карточки составляли основу всей библиотечной системы, индексируя огромные и разнообразные объемы информации.
Помимо имени автора, названия книги, предмета и известных «указательных терминов» (также известных как ключевые слова) и т. д., на карточке также будет указано местонахождение книги. И поэтому через какое-то время «маленькая старушка-библиотекарь», когда вы спрашиваете ее о той или иной книге, интуитивно сможет указать не просто на отдел библиотеки, но, возможно, даже на полку, на которой стоит книга, предоставив персонифицированную информацию. метод быстрого поиска.
Однако, когда я объяснял сходство этого типа системы индексации в поисковых системах, как я это делал много лет назад, мне пришлось добавить оговорку, которую все еще важно усвоить:
«Крупнейшие поисковые системы основаны на индексах так же, как библиотеки. Сохранив большую часть Интернета в массивных индексах, им необходимо быстро вернуть релевантные документы по заданному ключевому слову или фразе. Но разнообразие веб-страниц с точки зрения состава, качества и содержания даже больше, чем масштаб самих необработанных данных. Сеть в целом не имеет единой структуры, с огромным разнообразием стилей написания и контента, гораздо более широким и сложным, чем в традиционных коллекциях текстовых документов. Это делает почти невозможным для поисковой системы применение строго традиционных методов, используемых в библиотеках, системах управления базами данных и поиске информации».
То, что затем произошло с ключевыми словами и тем, как мы пишем для Интернета, неизбежно стало появлением новой области коммуникации.
Как я объяснил в книге, HTML можно рассматривать как новый лингвистический жанр, и его следует рассматривать как таковой в будущих лингвистических исследованиях. Гипертекстовый документ — это гораздо больше, чем обычный текстовый документ. И это дает больше указаний на то, о чем конкретная веб-страница, когда ее читают люди, а также текст анализируется, классифицируется и классифицируется с помощью анализа текста и извлечения информации поисковыми системами.
Иногда я до сих пор слышу, как оптимизаторы называют поисковые системы «машинным чтением» веб-страниц, но этот термин гораздо больше относится к относительно недавнему внедрению систем «структурированных данных».
Как мне все еще часто приходится объяснять, человек, читающий веб-страницу, и поисковые системы извлекают текст и извлекают информацию «о» странице — это не то же самое, что люди, читающие веб-страницу, и поисковые системы «скармливают» структурированные данные.
Лучший осязаемый пример, который я нашел, — это сравнение современной веб-страницы HTML со вставленными «машиночитаемыми» структурированными данными и современным паспортом. Взгляните на страницу с изображением в вашем паспорте, и вы увидите один основной раздел с вашим изображением и текстом для чтения людьми и отдельный раздел в нижней части страницы, который создан специально для машинного чтения путем пролистывания или сканирования.
По сути, современная веб-страница устроена примерно так же, как современный паспорт. Интересно, что 20 лет назад я упомянул сочетание человек/машина с этим небольшим фактом:
«В 1747 году французский врач и философ Жюльен Оффруа де ла Меттри опубликовал одну из самых плодотворных работ в истории идей. Он назвал его L'HOMME MACHINE, что лучше всего переводится как «человек, машина». Часто вы будете слышать фразу «о людях и машинах», и это основная идея искусственного интеллекта».
Я подчеркивал важность структурированных данных в своей предыдущей статье и надеюсь написать для вас кое-что, что, по моему мнению, будет очень полезно для понимания баланса между чтением людей и машинным чтением. Я полностью упростил это еще в 2002 году, чтобы дать базовое объяснение:
- Данные: представление фактов или идей в формализованной форме, способное передаваться или манипулироваться каким-либо процессом.
- Информация: значение, которое человек приписывает данным посредством известных соглашений, используемых при их представлении.
Следовательно:
- Данные связаны с фактами и машинами.
- Информация связана со значением и людьми.
Давайте минутку поговорим о характеристиках текста, а затем я объясню, как текст может быть представлен в виде данных в чем-то «несколько неправильно понятом» (скажем так) в SEO-индустрии, называемом моделью векторного пространства.
Самые важные ключевые слова в индексе поисковой системы по сравнению с самыми популярными словами
Вы когда-нибудь слышали о законе Ципфа?
Названный в честь профессора гарвардской лингвистики Джорджа Кингсли Ципфа, он предсказывает явление, когда мы пишем, часто используя знакомые слова.
Ципф сказал, что его закон основан на главном предсказателе человеческого поведения: стремлении минимизировать усилия. Следовательно, закон Ципфа применим практически к любой области, связанной с человеческим производством.
Это означает, что у нас также есть ограниченная связь между рангом и частотой в естественном языке.
Большинство больших коллекций текстовых документов имеют схожие статистические характеристики. Знание этих статистических данных полезно, поскольку они влияют на эффективность и эффективность структур данных, используемых для индексации документов. Многие модели поиска полагаются на них.
В том, как мы пишем, есть закономерности — обычно мы ищем самый простой, самый короткий, наименее сложный и самый быстрый из возможных способов. Итак, правда в том, что мы просто используем одни и те же простые слова снова и снова.
Например, много лет назад я наткнулся на статистику эксперимента, в ходе которого ученые взяли 131-мегабайтную коллекцию (тогда это были большие данные) из 46 500 газетных статей (19 миллионов терминов).
Вот данные для первых 10 слов и сколько раз они использовались в этом корпусе. Я думаю, вы довольно быстро поймете суть:
Частота слов
номер: 1130021
из 547311
до 516635
464736
в 390819
и 387703
что 204351
на 199340
это 152483
сказал 148302
Помните, что все статьи, вошедшие в корпус, написаны профессиональными журналистами. Но если вы посмотрите на десятку наиболее часто употребляемых слов, вы вряд ли сможете составить из них хоть одно осмысленное предложение.
Поскольку эти распространенные слова так часто встречаются в английском языке, поисковые системы будут игнорировать их как «стоп-слова». Если самые популярные слова, которые мы используем, не представляют особой ценности для автоматизированной системы индексации, то какие слова принесут пользу?
Как уже отмечалось, в области информационно-поисковых (ИК) систем проделана большая работа. Статистические подходы широко применялись из-за плохого соответствия текста моделям данных, основанным на формальной логике (например, реляционным базам данных).
Таким образом, вместо того, чтобы требовать, чтобы пользователи могли предугадывать точные слова и сочетания слов, которые могут появиться в интересующих документах, статистический IR позволяет пользователям просто вводить строку слов, которые могут появиться в документе.
Затем система учитывает частоту этих слов в наборе текстов и в отдельных документах, чтобы определить, какие слова могут быть лучшими ключами к релевантности. Оценка рассчитывается для каждого документа на основе содержащихся в нем слов, и извлекаются документы с наивысшей оценкой.
Мне посчастливилось взять интервью у ведущего исследователя в области IR, когда я проводил исследования для книги еще в 2001 году. В то время Андрей Бродер был главным научным сотрудником Alta Vista (в настоящее время заслуженным инженером Google), и мы обсуждали эту тему. «термин-векторов», и я спросил, может ли он дать мне простое объяснение того, что они собой представляют.

Он объяснил мне, как при «взвешивании» терминов по важности в указателе он может отметить появление слова «из» в корпусе миллионы раз. По его словам, это слово вообще не будет иметь «веса». Но если он увидит что-то вроде слова «гемоглобин», которое встречается в корпусе гораздо реже, то это слово получит некоторый вес.
Я хочу сделать небольшой шаг назад, прежде чем объясню, как создается индекс, и развею еще один миф, существующий годами. И это тот случай, когда многие люди считают, что Google (и другие поисковые системы) на самом деле загружают ваши веб-страницы и сохраняют их на жестком диске.
Нет, совсем нет. У нас уже есть место для этого, оно называется всемирная паутина.
Да, Google поддерживает «кэшированный» снимок страницы для быстрого поиска. Но когда содержимое этой страницы изменяется, при следующем сканировании страницы кэшированная версия также меняется.
Вот почему вы никогда не сможете найти копии своих старых веб-страниц в Google. Для этого ваш единственный реальный ресурс — Интернет-архив (также известный как The Wayback Machine).
На самом деле, когда ваша страница сканируется, она в основном демонтирована. Текст анализируется (извлекается) из документа.
Каждому документу присваивается собственный идентификатор вместе с информацией о местоположении (URL), а «необработанные данные» пересылаются в модуль индексатора. Слова/термины сохраняются с соответствующим идентификатором документа, в котором они появились.
Вот очень простой пример использования двух документов и содержащегося в них текста, который я создал 20 лет назад.
Вспомнить построение индекса
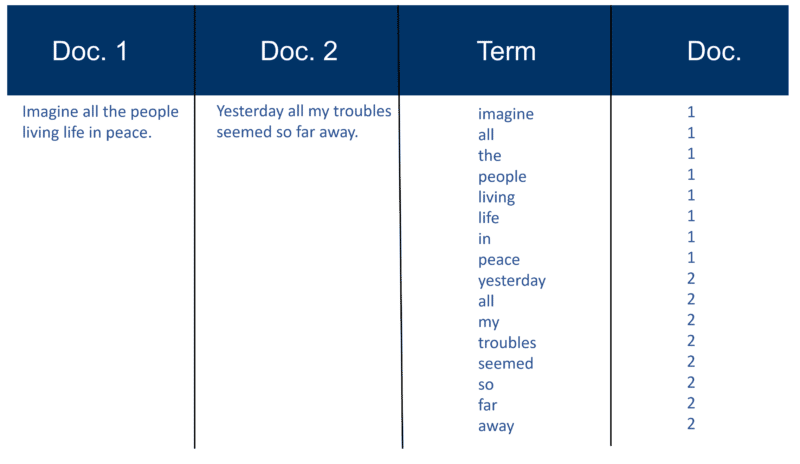
После разбора всех документов инвертированный файл сортируется по терминам:
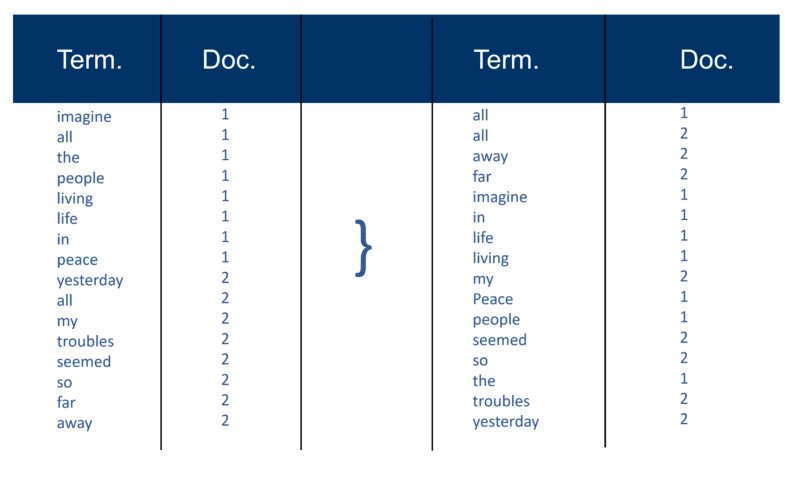
В моем примере это выглядит довольно просто в начале процесса, но проводки (как они называются в терминах информационного поиска) в индекс идут в одном документе за раз. Опять же, с миллионами документов вы можете себе представить, сколько вычислительной мощности требуется, чтобы превратить это в массивное «представление по терминам», которое упрощено выше, сначала по терминам, а затем по документам в каждом термине.
Вы обратите внимание на мою ссылку на «миллионы документов» за все эти годы. Конечно, сегодня у нас миллиарды (даже триллионы). В моем основном объяснении того, как создается индекс, я продолжил это:
Каждая поисковая система создает свой собственный словарь (или лексикон, как он есть — помните, что многие веб-страницы написаны не на английском языке), который должен включать каждый новый «термин», обнаруженный после сканирования (подумайте о том, как при использовании текстовом процессоре, таком как Microsoft Word, вы часто получаете возможность добавить слово в свой собственный словарь, то есть то, чего нет в стандартном словаре английского языка). Как только у поисковой системы появится «большой» индекс, некоторые термины станут более важными, чем другие. Итак, каждый термин заслуживает своего веса (значения). Весовой коэффициент во многом зависит от самого термина. Конечно, это довольно просто, если подумать, поэтому больший вес придается слову с большим количеством вхождений, но затем этот вес увеличивается за счет «редкости» термина во всем корпусе. Индексатор также может придавать больший «вес» словам, которые появляются в определенных местах документа. Слова, которые появляются в теге заголовка <title>, очень важны. Слова, которые находятся в тегах заголовков <h1> или те, которые выделены полужирным шрифтом <b> на странице, могут быть более релевантными. Слова, которые появляются в якорном тексте ссылок на HTML-страницах или рядом с ними, безусловно, считаются очень важными. Слова, которые появляются в текстовых тегах <alt> с изображениями, отмечаются так же, как и слова, которые появляются в метатегах.
Помимо оригинального текста «Современный поиск информации», написанного ученым Джерардом Салтоном (считающимся отцом современного поиска информации), у меня в свое время был ряд других ресурсов, которые подтвердили вышеизложенное. И Брайан Пинкертон, и Майкл Модлин (создатели поисковых систем WebCrawler и Lycos соответственно) подробно рассказали мне, как использовался «классический подход Солтона». И оба заставили меня осознать ограничения.
Мало того, Ларри Пейдж и Сергей Брин подчеркнули то же самое в оригинальной статье, которую они написали при запуске прототипа Google. Я возвращаюсь к этому, поскольку это важно для того, чтобы помочь развеять еще один миф.
Но сначала, вот как я объяснил «классический подход Солтона» еще в 2002 году. Обязательно обратите внимание на ссылку на «пару весов терминов».
После того, как поисковая система создала свой «большой индекс», модуль индексатора измеряет «частоту терминов» (tf) слова в документе, чтобы получить «плотность терминов», а затем измеряет «обратную частоту документа» (idf), которая вычисление частотности терминов в документе; общее количество документов; количество документов, содержащих термин. С помощью этого дальнейшего расчета каждый документ теперь можно рассматривать как вектор значений tf x idf (двоичные или числовые значения, прямо или косвенно соответствующие словам документа). То, что вы тогда имеете, является парой веса термина. Вы можете транспонировать это как: документ имеет взвешенный список слов; слово имеет взвешенный список документов (пара весов терминов).
Модель векторного пространства
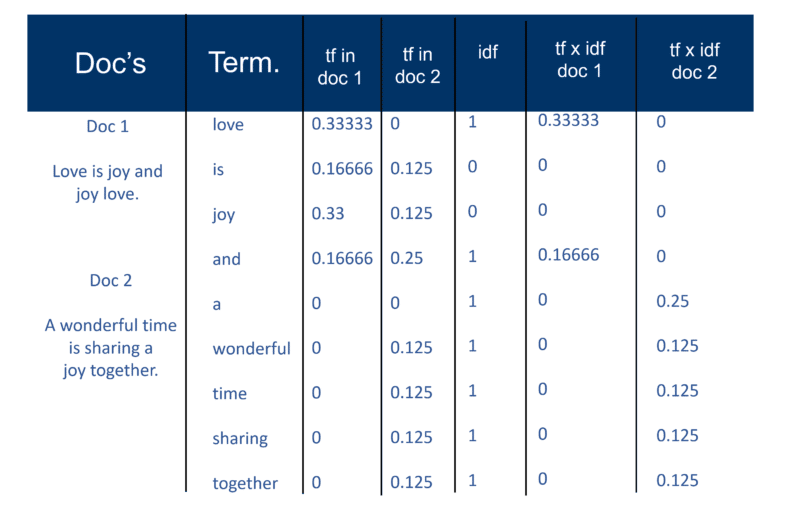
Теперь, когда Документы представляют собой векторы с одним компонентом для каждого термина, было создано «векторное пространство», в котором живут все Документы. Но каковы преимущества создания этой вселенной Документов, которые теперь имеют такой масштаб?
Таким образом, если Doc 'd' (в качестве примера) является вектором, то легко найти другие подобные ему, а также найти векторы рядом с ним.
Интуитивно вы можете определить, что документы, расположенные близко друг к другу в векторном пространстве, говорят об одном и том же. Делая это, поисковая система может создавать кластеры слов или документов и добавлять различные другие методы взвешивания.
Однако основным преимуществом использования векторов терминов для поисковых систем является то, что механизм запросов может рассматривать сам запрос как очень короткий документ. Таким образом, запрос становится вектором в том же векторном пространстве, и механизм запросов может измерить близость к нему каждого документа.
Модель векторного пространства позволяет пользователю запрашивать у поисковой системы «понятия», а не чистый «лексический» поиск. Как вы можете видеть здесь, даже 20 лет назад понятие концепций и тем, а не просто ключевых слов, было очень популярным.
Хорошо, давайте разберемся с проблемой «плотности ключевых слов». Слово «плотность» появляется в объяснении того, как работает модель векторного пространства, но только в том смысле, что оно применяется к расчету по всему корпусу документов, а не по отдельной странице. Возможно, именно эта ссылка заставила многих SEO-специалистов начать использовать анализаторы плотности ключевых слов на отдельных страницах.
С годами я также заметил, что многие SEO-специалисты, открывшие для себя модель векторного пространства, стремятся применить классическое взвешивание терминов tf x idf. Но это гораздо менее вероятно, особенно в Google, как заявили основатели Ларри Пейдж и Сергей Брин в своей оригинальной статье о том, как работает Google, — они подчеркивают низкое качество результатов при применении одной лишь классической модели:
«Например, стандартная модель векторного пространства пытается вернуть документ, который наиболее точно соответствует запросу, учитывая, что и запрос, и документ являются векторами, определяемыми их вхождением слова. В Интернете эта стратегия часто возвращает очень короткие документы, состоящие только из запроса и нескольких слов».
Было много вариантов, чтобы попытаться обойти «жесткость» модели векторного пространства. И за годы с достижениями в области искусственного интеллекта и машинного обучения появилось множество вариантов подхода, который может вычислять вес определенных слов и документов в индексе.
Вы можете потратить годы, пытаясь понять, какие формулы использует любая поисковая система, не говоря уже о Google (хотя вы можете быть уверены, какую из них они не используют, как я только что указал). Таким образом, имея это в виду, это должно развеять миф о том, что попытка манипулировать плотностью ключевых слов веб-страниц при их создании является несколько напрасной тратой усилий.
Решение проблемы изобилия
Первое поколение поисковых систем в значительной степени полагалось на внутренние факторы для ранжирования.
Но проблема, с которой вы сталкиваетесь при использовании чисто методов ранжирования на основе ключевых слов (помимо того, что я только что упомянул о Google с самого первого дня), — это нечто, известное как «проблема изобилия», которая предполагает экспоненциальный рост сети каждый день и экспоненциальный рост документов, содержащих одно и то же. ключевые слова.
И это ставит вопрос на этом слайде, который я использую с 2002 года:

Можно предположить, что самым авторитетным был бы дирижер оркестра, который много лет аранжировал и исполнял произведение со многими оркестрами. Но работая исключительно над методами ранжирования ключевых слов, столь же вероятно, что студент-музыкант может быть результатом номер один.
Как вы решаете эту проблему?
Что ж, ответ — анализ гиперссылок (также известных как обратные ссылки).
В следующем выпуске я объясню, как слово «авторитет» вошло в лексикон IR и SEO. И я также объясню первоисточник того, что сейчас называется EAT, и на чем он фактически основан.
А пока — будьте здоровы, берегите себя и помните, какое удовольствие доставляет обсуждение внутренней работы поисковых систем!
Мнения, выраженные в этой статье, принадлежат приглашенному автору, а не обязательно поисковой системе. Штатные авторы перечислены здесь.