
Tecniche di indicizzazione e ranking delle parole chiave rivisitate: 20 anni dopo
Pubblicato: 2022-08-04Quando la ghianda che sarebbe diventata l'industria SEO ha iniziato a crescere, l'indicizzazione e il posizionamento sui motori di ricerca erano entrambi basati esclusivamente su parole chiave.
Il motore di ricerca abbinerebbe le parole chiave in una query alle parole chiave nel suo indice parallelamente alle parole chiave che sono apparse su una pagina web.
Le pagine con il punteggio di pertinenza più alto verrebbero classificate in ordine utilizzando una delle tre tecniche di recupero più popolari:
- Modello booleano
- Modello probabilistico
- Modello spaziale vettoriale
Il modello dello spazio vettoriale è diventato il più rilevante per i motori di ricerca.
In questo articolo rivisiterò la spiegazione di base e in qualche modo semplice del modello classico che usavo in passato (perché è ancora rilevante nel mix dei motori di ricerca).
Lungo la strada, sfatiamo un mito o due, come il concetto di "densità delle parole chiave" di una pagina web. Mettiamolo a letto una volta per tutte.
La parola chiave: una delle parole più usate nella scienza dell'informazione; per gli esperti di marketing: un mistero avvolto
"Cos'è una parola chiave?"
Non hai idea di quante volte ho sentito quella domanda quando stava emergendo l'industria SEO. E dopo aver fornito una breve spiegazione, la domanda successiva sarebbe stata: "Allora, quali sono le mie parole chiave, Mike?"
Onestamente, è stato piuttosto difficile spiegare ai professionisti del marketing che le parole chiave specifiche utilizzate in una query erano ciò che attivava le pagine Web corrispondenti nei risultati dei motori di ricerca.
E sì, questo solleverebbe quasi sicuramente un'altra domanda: "Che cosa è una domanda, Mike?"
Oggi termini come parola chiave, query, indice, ranking e tutto il resto sono all'ordine del giorno nel lessico del marketing digitale.
Tuttavia, come SEO, credo che sia estremamente utile capire da dove vengono tratti e perché e come quei termini si applicano ancora oggi come lo erano una volta.
La scienza del recupero delle informazioni (IR) è un sottoinsieme del termine generico "intelligenza artificiale". Ma la stessa IR comprende anche diversi sottoinsiemi, tra cui quello delle biblioteche e delle scienze dell'informazione.
E questo è il nostro punto di partenza per questa seconda parte del mio viaggio nella memoria SEO. (Il mio primo, nel caso ve lo foste perso, è stato: Abbiamo scansionato il Web per 32 anni: cosa è cambiato?)
Questa serie in corso di articoli si basa su ciò che ho scritto in un libro sulla SEO 20 anni fa, facendo osservazioni sullo stato dell'arte nel corso degli anni e confrontandolo con quello in cui siamo oggi.
La vecchietta in biblioteca
Quindi, dopo aver evidenziato che ci sono elementi di biblioteconomia sotto il banner di Information Retrieval, permettetemi di riferire dove si inseriscono nella ricerca sul web.
Apparentemente, i bibliotecari sono principalmente identificati come vecchiette. Certamente è apparso in questo modo quando ho intervistato diversi scienziati di spicco nel nuovo campo emergente del "web" Information Retrial (IR) tutti quegli anni fa.
Brian Pinkerton, inventore di WebCrawler, insieme ad Andrei Broder, Vice President Technology e Chief Scientist di Alta Vista, il motore di ricerca numero uno prima di Google e in effetti Craig Silverstein, Director of Technology di Google (e in particolare, il dipendente di Google numero uno) hanno tutti descritto il loro lavoro in questo nuovo campo come cercare di ottenere un motore di ricerca per emulare "la vecchietta in biblioteca".
Le biblioteche si basano sul concetto di scheda, il cui scopo originale era quello di tentare di organizzare e classificare ogni animale, pianta e minerale conosciuto nel mondo.
Le schede indice costituivano la spina dorsale dell'intero sistema bibliotecario, indicizzando quantità vaste e variegate di informazioni.
A parte il nome dell'autore, il titolo del libro, l'argomento e i "termini dell'indice" notevoli (ovvero parole chiave), ecc., la scheda indice avrebbe anche la posizione del libro. E quindi, dopo un po' "la vecchietta bibliotecaria" quando le chiedevi di un libro in particolare, sarebbe intuitivamente in grado di indicare non solo la sezione della biblioteca, ma probabilmente anche lo scaffale su cui si trovava il libro, fornendo un metodo di recupero rapido.
Tuttavia, quando ho spiegato la somiglianza di quel tipo di sistema di indicizzazione sui motori di ricerca come ho fatto tutti quegli anni fa, ho dovuto aggiungere un avvertimento che è ancora importante comprendere:
“I motori di ricerca più grandi sono basati su indici in modo simile a quello di una biblioteca. Avendo archiviato gran parte del Web in enormi indici, devono quindi restituire rapidamente documenti pertinenti rispetto a una determinata parola chiave o frase. Ma la variazione delle pagine web, in termini di composizione, qualità e contenuto, è persino maggiore della scala dei dati grezzi stessi. Il web nel suo insieme non ha una struttura unificante, con un'enorme variante nello stile di authoring e nei contenuti molto più ampia e complessa rispetto alle tradizionali raccolte di documenti di testo. Ciò rende quasi impossibile per un motore di ricerca applicare tecniche strettamente convenzionali utilizzate nelle biblioteche, nei sistemi di gestione dei database e nel recupero delle informazioni".
Inevitabilmente, quello che poi è successo con le parole chiave e il modo in cui scriviamo per il web è stato l'emergere di un nuovo campo di comunicazione.
Come ho spiegato nel libro, l'HTML potrebbe essere visto come un nuovo genere linguistico e dovrebbe essere trattato come tale nei futuri studi linguistici. C'è molto di più in un documento Hypertext rispetto a un documento di "testo piatto". E questo fornisce più di un'indicazione di cosa tratta una particolare pagina Web quando viene letta da esseri umani, nonché del testo analizzato, classificato e classificato attraverso l'estrazione di testo e l'estrazione di informazioni dai motori di ricerca.
A volte sento ancora i SEO riferirsi alle pagine web di “lettura automatica” dei motori di ricerca, ma quel termine appartiene molto di più all'introduzione relativamente recente dei sistemi di “dati strutturati”.
Come spesso devo ancora spiegare, un essere umano che legge una pagina Web e che i motori di ricerca estraggono un testo ed estraggono informazioni "su" una pagina non è la stessa cosa di un essere umano che legge una pagina Web e che i motori di ricerca vengono "alimentati" con dati strutturati.
Il miglior esempio tangibile che ho trovato è quello di fare un confronto tra una moderna pagina Web HTML con inseriti dati strutturati "leggibili dalla macchina" e un passaporto moderno. Dai un'occhiata alla pagina delle immagini sul tuo passaporto e vedrai una sezione principale con la tua foto e il tuo testo che possono essere letti dagli umani e una sezione separata nella parte inferiore della pagina, creata appositamente per la lettura automatica tramite scorrimento o scansione.
In sostanza, una pagina web moderna è strutturata come un passaporto moderno. È interessante notare che 20 anni fa ho fatto riferimento alla combinazione uomo/macchina con questo piccolo fattoide:
“Nel 1747 il medico e filosofo francese Julien Offroy de la Mettrie pubblicò una delle opere più seminali nella storia delle idee. Lo intitolò L'HOMME MACHINE, che è meglio tradotto come "uomo, una macchina". Spesso sentirai la frase "di uomini e macchine" e questa è l'idea alla base dell'intelligenza artificiale".
Ho sottolineato l'importanza dei dati strutturati nel mio precedente articolo e spero di scrivere qualcosa per te che credo sarà estremamente utile per comprendere l'equilibrio tra la lettura umana e la lettura automatica. L'ho completamente semplificato in questo modo nel 2002 per fornire una razionalizzazione di base:
- Dati: una rappresentazione di fatti o idee in maniera formalizzata, suscettibile di essere comunicata o manipolata da qualche processo.
- Informazione: il significato che un essere umano attribuisce ai dati attraverso le convenzioni note utilizzate nella sua rappresentazione.
Perciò:
- I dati sono legati a fatti e macchine.
- Le informazioni sono legate al significato e agli esseri umani.
Parliamo delle caratteristiche del testo per un minuto e poi tratterò come il testo può essere rappresentato come dati in qualcosa di "un po' frainteso" (dovremo dire) nel settore SEO chiamato modello dello spazio vettoriale.
Le parole chiave più importanti in un indice di un motore di ricerca rispetto alle parole più popolari
Mai sentito parlare della legge di Zipf?
Prende il nome dal professore di linguistica di Harvard George Kingsley Zipf, predice il fenomeno che, mentre scriviamo, usiamo parole familiari con alta frequenza.
Zipf ha affermato che la sua legge si basa sul principale predittore del comportamento umano: cercare di ridurre al minimo lo sforzo. Pertanto, la legge di Zipf si applica a quasi tutti i campi che coinvolgono la produzione umana.
Ciò significa che abbiamo anche una relazione vincolata tra rango e frequenza nel linguaggio naturale.
La maggior parte delle grandi raccolte di documenti di testo hanno caratteristiche statistiche simili. Conoscere queste statistiche è utile perché influenzano l'efficacia e l'efficienza delle strutture di dati utilizzate per indicizzare i documenti. Molti modelli di recupero si basano su di essi.
Ci sono schemi di occorrenze nel modo in cui scriviamo: generalmente cerchiamo il metodo più semplice, più breve, meno coinvolto e più veloce possibile. Quindi, la verità è che usiamo sempre le stesse semplici parole.
Ad esempio, tutti quegli anni fa, mi sono imbattuto in alcune statistiche di un esperimento in cui gli scienziati hanno raccolto una raccolta di 131 MB (all'epoca erano big data) di 46.500 articoli di giornale (19 milioni di occorrenze di termini).
Ecco i dati per le prime 10 parole e quante volte sono state utilizzate all'interno di questo corpus. Otterrai il punto abbastanza rapidamente, penso:
Frequenza delle parole
il: 1130021
di 547311
a 516635
un 464736
nel 390819
e 387703
quel 204351
per 199340
è 152483
detto 148302
Ricorda, tutti gli articoli inclusi nel corpus sono stati scritti da giornalisti professionisti. Ma se guardi le prime dieci parole usate più di frequente, difficilmente potresti ricavarne una sola frase sensata.
Poiché queste parole comuni ricorrono così frequentemente nella lingua inglese, i motori di ricerca le ignoreranno come "parole di arresto". Se le parole più popolari che usiamo non forniscono molto valore a un sistema di indicizzazione automatizzato, quali parole lo fanno?
Come già notato, c'è stato molto lavoro nel campo dei sistemi di recupero delle informazioni (IR). Gli approcci statistici sono stati ampiamente applicati a causa dello scarso adattamento del testo ai modelli di dati basati su logiche formali (ad es. database relazionali).
Quindi, anziché richiedere che gli utenti siano in grado di anticipare le parole esatte e le combinazioni di parole che possono apparire nei documenti di interesse, l'IR statistico consente agli utenti di inserire semplicemente una stringa di parole che è probabile che compaiano in un documento.
Il sistema tiene quindi conto della frequenza di queste parole in una raccolta di testo e in singoli documenti per determinare quali parole potrebbero essere i migliori indizi di pertinenza. Viene calcolato un punteggio per ogni documento in base alle parole che contiene e vengono recuperati i documenti con il punteggio più alto.

Ho avuto la fortuna di intervistare un ricercatore di spicco nel campo dell'IR durante la ricerca per il libro nel 2001. A quel tempo, Andrei Broder era capo scienziato presso Alta Vista (attualmente Distinguished Engineer presso Google) e stavamo discutendo l'argomento di “termine vettori” e gli ho chiesto se poteva darmi una semplice spiegazione di cosa sono.
Mi ha spiegato come, quando "pondera" i termini per importanza nell'indice, può notare la presenza della parola "di" milioni di volte nel corpus. Questa è una parola che non avrà alcun "peso", ha detto. Ma se vede qualcosa come la parola "emoglobina", che è una parola molto più rara nel corpus, allora questa prenderà peso.
Voglio fare un rapido passo indietro qui prima di spiegare come viene creato l'indice e sfatare un altro mito che è rimasto nel corso degli anni. Ed è quello in cui molte persone credono che Google (e altri motori di ricerca) stiano effettivamente scaricando le tue pagine web e memorizzandole su un disco rigido.
No, per niente. Abbiamo già un posto per farlo, si chiama World Wide Web.
Sì, Google conserva un'istantanea "memorizzata nella cache" della pagina per un rapido recupero. Ma quando il contenuto della pagina cambia, alla successiva scansione della pagina cambia anche la versione memorizzata nella cache.
Ecco perché su Google non puoi mai trovare copie delle tue vecchie pagine web. Per questo, la tua unica vera risorsa è Internet Archive (aka, The Wayback Machine).
In effetti, quando la tua pagina viene scansionata, viene sostanzialmente smantellata. Il testo viene analizzato (estratto) dal documento.
A ogni documento viene assegnato il proprio identificatore insieme ai dettagli della posizione (URL) e i "dati grezzi" vengono inoltrati al modulo indicizzatore. Le parole/termini vengono salvati con l'ID documento associato in cui sono apparsi.
Ecco un esempio molto semplice usando due documenti e il testo che contengono che ho creato 20 anni fa.
Richiama la costruzione dell'indice
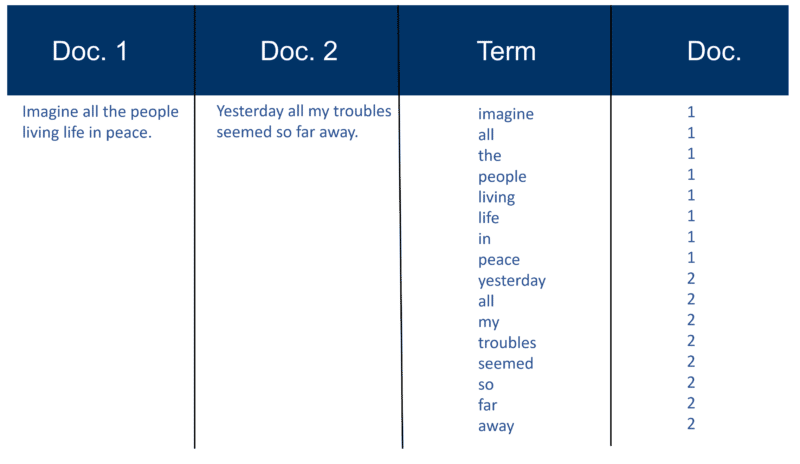
Dopo che tutti i documenti sono stati analizzati, il file invertito viene ordinato per termini:
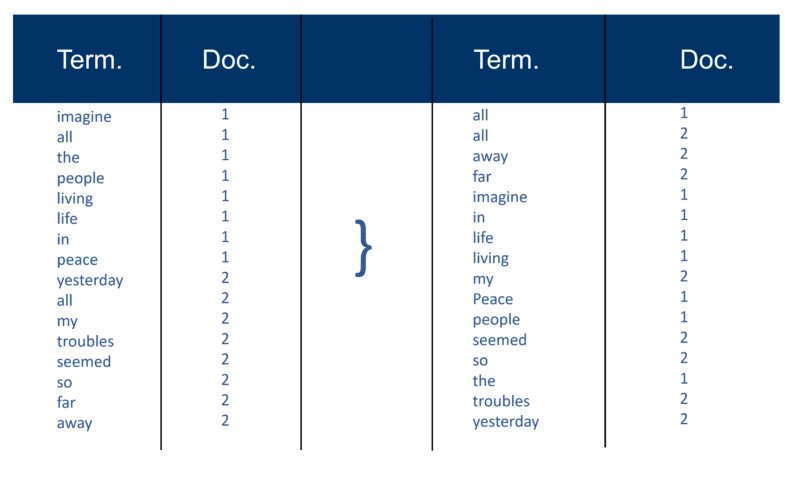
Nel mio esempio sembra abbastanza semplice all'inizio del processo, ma i post (come sono conosciuti in termini di recupero delle informazioni) nell'indice vanno in un documento alla volta. Ancora una volta, con milioni di documenti, puoi immaginare la quantità di potenza di elaborazione richiesta per trasformarlo nell'enorme "visione saggia dei termini" che è semplificata sopra, prima per termine e poi per Doc all'interno di ogni termine.
Noterai il mio riferimento a "milioni di documenti" di tutti quegli anni fa. Naturalmente, siamo in miliardi (anche trilioni) in questi giorni. Nella mia spiegazione di base di come viene creato l'indice, ho continuato con questo:
Ogni motore di ricerca crea il proprio dizionario personalizzato (o lessico così com'è - ricorda che molte pagine web non sono scritte in inglese), che deve includere ogni nuovo "termine" scoperto dopo una scansione (pensa al modo in cui, quando si utilizza un word processor come Microsoft Word, hai spesso la possibilità di aggiungere una parola al tuo dizionario personalizzato, cioè qualcosa che non compare nel dizionario inglese standard). Una volta che il motore di ricerca ha il suo indice "grande", alcuni termini saranno più importanti di altri. Quindi, ogni termine merita il proprio peso (valore). Gran parte del fattore di ponderazione dipende dal termine stesso. Naturalmente, questo è abbastanza semplice se ci pensi, quindi viene dato più peso a una parola con più occorrenze, ma questo peso viene poi aumentato dalla "rarità" del termine nell'intero corpus. L'indicizzatore può anche dare più 'peso' alle parole che appaiono in determinati punti del documento. Le parole che sono apparse nel tag title <title> sono molto importanti. Le parole che si trovano nei tag del titolo <h1> o quelle che sono in grassetto <b> nella pagina potrebbero essere più pertinenti. Le parole che compaiono nell'anchor text dei link nelle pagine HTML, o vicino ad esse, sono sicuramente considerate molto importanti. Vengono annotate le parole che appaiono nei tag di testo <alt> con immagini, così come le parole che appaiono nei meta tag.
A parte il testo originale "Modern Information Retrieval" scritto dallo scienziato Gerard Salton (considerato il padre del moderno recupero delle informazioni), in passato avevo una serie di altre risorse che verificavano quanto sopra. Sia Brian Pinkerton che Michael Maudlin (inventori rispettivamente dei motori di ricerca WebCrawler e Lycos) mi hanno fornito dettagli su come "l'approccio classico di Salton" è stato utilizzato. Ed entrambi mi hanno reso consapevole dei limiti.
Non solo, Larry Page e Sergey Brin hanno evidenziato lo stesso nel documento originale che hanno scritto al lancio del prototipo di Google. Tornerò su questo perché è importante per aiutare a sfatare un altro mito.
Ma prima, ecco come ho spiegato il "classico approccio Salton" nel 2002. Assicurati di notare il riferimento a "una coppia di pesi a termine".
Una volta che il motore di ricerca ha creato il suo "grande indice", il modulo indicizzatore misura la "frequenza del termine" (tf) della parola in un documento per ottenere la "densità del termine" e quindi misura la "frequenza inversa del documento" (idf) che è un calcolo della frequenza dei termini in un documento; il numero totale di documenti; il numero di documenti che contengono il termine. Con questo ulteriore calcolo, ogni Doc può ora essere visto come un vettore di valori tf x idf (valori binari o numerici corrispondenti direttamente o indirettamente alle parole del Doc). Quello che hai quindi è una coppia di pesi a termine. Potresti trasporre questo come: un documento ha un elenco ponderato di parole; una parola ha un elenco ponderato di documenti (una coppia di pesi di termini).
Il modello spaziale vettoriale
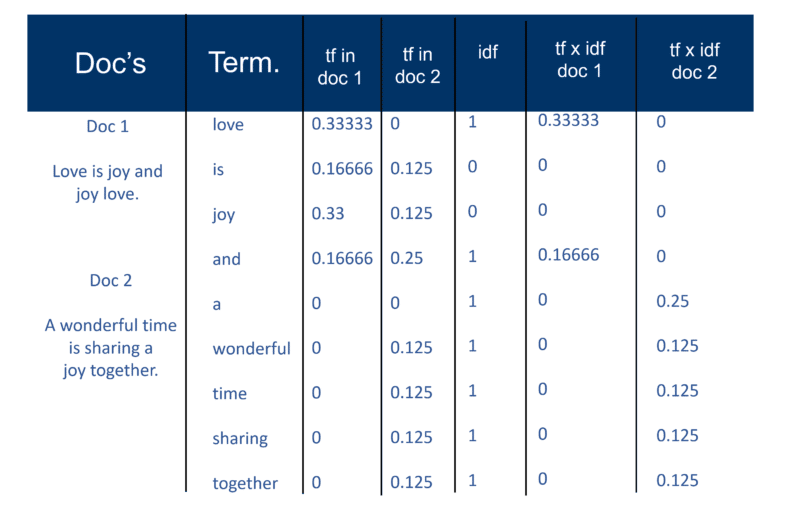
Ora che i documenti sono vettori con una componente per ogni termine, ciò che è stato creato è uno "spazio vettoriale" in cui vivono tutti i documenti. Ma quali sono i vantaggi della creazione di questo universo di Docs che ora ha tutti questa portata?
In questo modo, se Doc 'd' (ad esempio) è un vettore, è facile trovarne altri simili e anche trovare vettori vicino ad esso.
Intuitivamente, puoi quindi determinare che i documenti, che sono vicini tra loro nello spazio vettoriale, parlano delle stesse cose. In questo modo un motore di ricerca può quindi creare raggruppamenti di parole o documenti e aggiungere vari altri metodi di ponderazione.
Tuttavia, il principale vantaggio dell'utilizzo di vettori di termini per i motori di ricerca è che il motore di query può considerare una query stessa come un documento molto breve. In questo modo, la query diventa un vettore nello stesso spazio vettoriale e il motore di query può misurare la vicinanza di ciascun Doc ad esso.
Il Vector Space Model consente all'utente di interrogare il motore di ricerca per "concetti" piuttosto che per una pura ricerca "lessicale". Come puoi vedere qui, anche 20 anni fa la nozione di concetti e argomenti in contrapposizione alle semplici parole chiave era molto in gioco.
OK, affrontiamo questa cosa della "densità delle parole chiave". La parola "densità" appare nella spiegazione di come funziona il modello spaziale vettoriale, ma solo quando si applica al calcolo sull'intero corpus di documenti, non su una singola pagina. Forse è quel riferimento che ha fatto sì che così tanti SEO iniziassero a utilizzare gli analizzatori di densità delle parole chiave su singole pagine.
Ho anche notato nel corso degli anni che molti SEO, che scoprono il modello dello spazio vettoriale, tendono a provare ad applicare la classica ponderazione dei termini tf x idf. Ma è molto meno probabile che funzioni, in particolare su Google, come hanno affermato i fondatori Larry Page e Sergey Brin nel loro articolo originale su come funziona Google: sottolineano la scarsa qualità dei risultati quando si applica il modello classico da solo:
“Ad esempio, il modello di spazio vettoriale standard cerca di restituire il documento che si avvicina di più alla query, dato che sia la query che il documento sono vettori definiti dalla loro occorrenza di parole. Sul web, questa strategia restituisce spesso documenti molto brevi che sono solo la query più poche parole”.
Ci sono state molte varianti per tentare di aggirare la "rigidità" del modello spaziale vettoriale. E nel corso degli anni, con i progressi dell'intelligenza artificiale e dell'apprendimento automatico, sono state apportate molte variazioni all'approccio in grado di calcolare la ponderazione di parole e documenti specifici nell'indice.
Potresti passare anni a cercare di capire quali formule sta usando qualsiasi motore di ricerca, per non parlare di Google (anche se puoi essere sicuro di quale non stanno usando come ho appena sottolineato). Quindi, tenendo presente questo, dovrebbe sfatare il mito secondo cui cercare di manipolare la densità delle parole chiave delle pagine Web quando le crei è uno sforzo alquanto sprecato.
Risolvere il problema dell'abbondanza
La prima generazione di motori di ricerca faceva molto affidamento sui fattori sulla pagina per il posizionamento.
Ma il problema che hai usando tecniche di ranking puramente basate su parole chiave (al di là di ciò che ho appena menzionato su Google dal primo giorno) è qualcosa noto come "problema dell'abbondanza" che considera il web in crescita esponenziale ogni giorno e la crescita esponenziale di documenti che contengono lo stesso parole chiave.
E questo pone la domanda su questa diapositiva che uso dal 2002:

Si può presumere che il direttore d'orchestra, che da molti anni arrangia e suona il pezzo con molte orchestre, sarebbe il più autorevole. Ma lavorando esclusivamente sulle tecniche di ranking delle parole chiave, è altrettanto probabile che lo studente di musica possa essere il risultato numero uno.
Come risolvi quel problema?
Bene, la risposta è l'analisi dei collegamenti ipertestuali (aka backlink).
Nella mia prossima puntata, spiegherò come la parola "autorità" è entrata nel lessico IR e SEO. E spiegherò anche la fonte originale di ciò che ora viene chiamato EAT e su cosa si basa effettivamente.
Fino ad allora - stai bene, stai al sicuro e ricorda che gioia c'è nel discutere il funzionamento interno dei motori di ricerca!
Le opinioni espresse in questo articolo sono quelle dell'autore ospite e non necessariamente di Search Engine Land. Gli autori dello staff sono elencati qui.