
Técnicas de indexação e classificação de palavras-chave revisitadas: 20 anos depois
Publicados: 2022-08-04Quando a bolota que se tornaria a indústria de SEO começou a crescer, a indexação e a classificação nos motores de busca eram baseadas puramente em palavras-chave.
O mecanismo de pesquisa corresponderia as palavras-chave em uma consulta às palavras-chave em seu índice, paralelamente às palavras-chave que apareceram em uma página da web.
As páginas com a pontuação de relevância mais alta seriam classificadas em ordem usando uma das três técnicas de recuperação mais populares:
- Modelo booleano
- Modelo probabilístico
- Modelo de espaço vetorial
O modelo de espaço vetorial tornou-se o mais relevante para os motores de busca.
Vou revisitar a explicação básica e um tanto simples do modelo clássico que usei no passado neste artigo (porque ainda é relevante no mix de mecanismos de pesquisa).
Ao longo do caminho, vamos dissipar um mito ou dois – como a noção de “densidade de palavras-chave” de uma página da web. Vamos colocar isso na cama de uma vez por todas.
A palavra-chave: Uma das palavras mais usadas na ciência da informação; para os profissionais de marketing - um mistério encoberto
“O que é uma palavra-chave?”
Você não tem ideia de quantas vezes eu ouvi essa pergunta quando a indústria de SEO estava surgindo. E depois de dar uma explicação resumida, a pergunta de acompanhamento seria: “Então, quais são minhas palavras-chave, Mike?”
Honestamente, foi muito difícil tentar explicar aos profissionais de marketing que palavras-chave específicas usadas em uma consulta eram o que acionava as páginas da Web correspondentes nos resultados dos mecanismos de pesquisa.
E sim, isso quase certamente levantaria outra pergunta: “O que é uma consulta, Mike?”
Hoje, termos como palavra-chave, consulta, índice, classificação e todo o resto são comuns no léxico do marketing digital.
No entanto, como um SEO, acredito que é eminentemente útil entender de onde eles são extraídos e por que e como esses termos ainda se aplicam tanto agora quanto no passado.
A ciência da recuperação da informação (RI) é um subconjunto sob o termo abrangente “inteligência artificial”. Mas a própria RI também é composta por vários subconjuntos, incluindo o de biblioteconomia e ciência da informação.
E esse é o nosso ponto de partida para esta segunda parte do meu passeio pela memória do SEO. (O meu primeiro, caso você tenha perdido, foi: Nós rastreamos a web há 32 anos: O que mudou?)
Esta série contínua de artigos é baseada no que escrevi em um livro sobre SEO há 20 anos, fazendo observações sobre o estado da arte ao longo dos anos e comparando-o com o que estamos hoje.
A velhinha na biblioteca
Assim, tendo destacado que existem elementos da biblioteconomia sob a bandeira da Recuperação da Informação, deixe-me relatar onde eles se encaixam na pesquisa na web.
Aparentemente, os bibliotecários são identificados principalmente como velhinhas. Certamente foi assim quando entrevistei vários cientistas de destaque no novo campo emergente de Reavaliação de Informações (IR) da “web” todos esses anos atrás.
Brian Pinkerton, inventor do WebCrawler, juntamente com Andrei Broder, vice-presidente de tecnologia e cientista-chefe do Alta Vista, o mecanismo de pesquisa número um antes do Google e, de fato, Craig Silverstein, diretor de tecnologia do Google (e notavelmente, o funcionário número um do Google) todos descreveram seu trabalho neste novo campo como tentar fazer com que um mecanismo de busca emule “a velhinha da biblioteca”.
As bibliotecas são baseadas no conceito do cartão de índice – cujo objetivo original era tentar organizar e classificar todos os animais, plantas e minerais conhecidos no mundo.
Os cartões de índice formavam a espinha dorsal de todo o sistema de bibliotecas, indexando vastas e variadas quantidades de informação.
Além do nome do autor, título do livro, assunto e “termos de índice” notáveis (aka, palavras-chave), etc., o cartão de índice também teria a localização do livro. E, portanto, depois de um tempo “a velhinha bibliotecária” quando você perguntava a ela sobre um determinado livro, intuitivamente seria capaz de apontar não apenas para a seção da biblioteca, mas provavelmente até para a estante em que o livro estava, fornecendo um método de recuperação rápida.
No entanto, quando expliquei a semelhança desse tipo de sistema de indexação nos mecanismos de pesquisa, como fiz todos esses anos atrás, tive que adicionar uma ressalva que ainda é importante entender:
“Os maiores mecanismos de busca são baseados em índices de maneira semelhante à de uma biblioteca. Tendo armazenado uma grande fração da web em índices maciços, eles precisam retornar rapidamente documentos relevantes em relação a uma determinada palavra-chave ou frase. Mas a variação das páginas da web, em termos de composição, qualidade e conteúdo, é ainda maior do que a escala dos próprios dados brutos. A web como um todo não tem uma estrutura unificadora, com uma enorme variação no estilo de autoria e conteúdo muito mais amplo e complexo do que nas coleções tradicionais de documentos de texto. Isso torna quase impossível para um mecanismo de busca aplicar técnicas estritamente convencionais usadas em bibliotecas, sistemas de gerenciamento de banco de dados e recuperação de informações”.
Inevitavelmente, o que ocorreu então com as palavras-chave e a forma como escrevemos para a web foi o surgimento de um novo campo de comunicação.
Como expliquei no livro, HTML pode ser visto como um novo gênero linguístico e deve ser tratado como tal em futuros estudos linguísticos. Há muito mais em um documento de hipertexto do que em um documento de “texto simples”. E isso dá mais uma indicação sobre o que é uma determinada página da Web quando está sendo lida por humanos, bem como o texto que está sendo analisado, classificado e categorizado por meio de mineração de texto e extração de informações por mecanismos de pesquisa.
Às vezes ainda ouço SEOs referindo-se a páginas da web de “leitura de máquina” dos mecanismos de busca, mas esse termo pertence muito mais à introdução relativamente recente de sistemas de “dados estruturados”.
Como muitas vezes ainda tenho que explicar, um humano lendo uma página da web e os mecanismos de pesquisa minerando e extraindo informações “sobre” uma página não é a mesma coisa que os humanos lendo uma página da web e os mecanismos de pesquisa sendo “alimentados” com dados estruturados.
O melhor exemplo tangível que encontrei é fazer uma comparação entre uma página web HTML moderna com dados estruturados “legíveis por máquina” inseridos e um passaporte moderno. Dê uma olhada na página da imagem em seu passaporte e você verá uma seção principal com sua imagem e texto para os humanos lerem e uma seção separada na parte inferior da página, que é criada especificamente para leitura automática por deslizamento ou digitalização.
Em essência, uma página da web moderna é estruturada como um passaporte moderno. Curiosamente, 20 anos atrás eu referi a combinação homem/máquina com este pequeno factóide:
“Em 1747, o médico e filósofo francês Julien Offroy de la Mettrie publicou uma das obras mais seminais da história das ideias. Ele intitulou L'HOMME MACHINE, que é melhor traduzido como “homem, uma máquina”. Muitas vezes, você ouvirá a frase 'de homens e máquinas' e essa é a ideia-raiz da inteligência artificial”.
Enfatizei a importância dos dados estruturados em meu artigo anterior e espero escrever algo para você que acredito que será extremamente útil para entender o equilíbrio entre leitura humana e leitura de máquina. Eu simplifiquei totalmente assim em 2002 para fornecer uma racionalização básica:
- Dados: uma representação de fatos ou ideias de forma formalizada, capaz de ser comunicado ou manipulado por algum processo.
- Informação: o significado que um ser humano atribui aos dados por meio das convenções conhecidas utilizadas em sua representação.
Portanto:
- Os dados estão relacionados a fatos e máquinas.
- A informação está relacionada ao significado e aos humanos.
Vamos falar sobre as características do texto por um minuto e depois falarei sobre como o texto pode ser representado como dados em algo “um tanto incompreendido” (digamos) na indústria de SEO chamado modelo de espaço vetorial.
As palavras-chave mais importantes em um índice de mecanismo de pesquisa versus as palavras mais populares
Já ouviu falar da Lei de Zipf?
Nomeado em homenagem ao professor de linguística de Harvard George Kingsley Zipf, ele prevê o fenômeno de que, enquanto escrevemos, usamos palavras familiares com alta frequência.
Zipf disse que sua lei se baseia no principal preditor do comportamento humano: esforçar-se para minimizar o esforço. Portanto, a lei de Zipf se aplica a quase todos os campos que envolvem a produção humana.
Isso significa que também temos uma relação restrita entre classificação e frequência em linguagem natural.
A maioria das grandes coleções de documentos de texto tem características estatísticas semelhantes. Conhecer essas estatísticas é útil porque elas influenciam a eficácia e a eficiência das estruturas de dados usadas para indexar documentos. Muitos modelos de recuperação dependem deles.
Existem padrões de ocorrências na maneira como escrevemos – geralmente procuramos o método mais fácil, mais curto, menos complicado e mais rápido possível. Então, a verdade é que usamos as mesmas palavras simples repetidamente.
Como exemplo, todos esses anos atrás, me deparei com algumas estatísticas de um experimento em que cientistas coletaram uma coleção de 131 MB (que era big data na época) de 46.500 artigos de jornal (19 milhões de ocorrências de termos).
Aqui estão os dados das 10 principais palavras e quantas vezes elas foram usadas neste corpus. Você vai entender o ponto muito rapidamente, eu acho:
Frequência de palavras
o: 1130021
de 547311
para 516635
um 464736
em 390819
e 387703
que 204351
para 199340
é 152483
disse 148302
Lembre-se, todos os artigos incluídos no corpus foram escritos por jornalistas profissionais. Mas se você olhar para as dez palavras mais usadas, dificilmente poderá fazer uma única frase sensata com elas.
Como essas palavras comuns ocorrem com tanta frequência no idioma inglês, os mecanismos de pesquisa as ignorarão como “palavras de parada”. Se as palavras mais populares que usamos não fornecem muito valor a um sistema de indexação automatizado, quais são as palavras?
Como já mencionado, tem havido muito trabalho no campo dos sistemas de recuperação de informação (IR). Abordagens estatísticas têm sido amplamente aplicadas devido ao mau ajuste do texto aos modelos de dados baseados em lógicas formais (por exemplo, bancos de dados relacionais).
Assim, em vez de exigir que os usuários possam antecipar as palavras exatas e as combinações de palavras que podem aparecer em documentos de interesse, a RI estatística permite que os usuários simplesmente insiram uma sequência de palavras que provavelmente aparecerão em um documento.
O sistema leva em consideração a frequência dessas palavras em uma coleção de texto e em documentos individuais para determinar quais palavras provavelmente são as melhores pistas de relevância. Uma pontuação é calculada para cada documento com base nas palavras que ele contém e os documentos com pontuação mais alta são recuperados.

Tive a sorte de entrevistar um pesquisador líder na área de RI quando pesquisava a mim mesmo para o livro em 2001. Naquela época, Andrei Broder era cientista-chefe da Alta Vista (atualmente engenheiro distinto do Google), e estávamos discutindo o assunto de “vetores de termo” e perguntei se ele poderia me dar uma explicação simples do que são.
Ele me explicou como, ao “pesar” termos por importância no índice, ele pode notar a ocorrência da palavra “de” milhões de vezes no corpus. Esta é uma palavra que não terá nenhum “peso”, disse ele. Mas se ele vir algo como a palavra “hemoglobina”, que é uma palavra muito mais rara no corpus, então essa vai ganhar algum peso.
Quero dar um passo atrás aqui antes de explicar como o índice é criado e dissipar outro mito que perdurou ao longo dos anos. E é aí que muitas pessoas acreditam que o Google (e outros mecanismos de busca) estão realmente baixando suas páginas da web e armazenando-as em um disco rígido.
Não, de jeito nenhum. Já temos um lugar para fazer isso, chama-se world wide web.
Sim, o Google mantém um instantâneo “em cache” da página para recuperação rápida. Mas quando o conteúdo dessa página muda, na próxima vez que a página for rastreada, a versão em cache também muda.
É por isso que você nunca consegue encontrar cópias de suas páginas da web antigas no Google. Para isso, seu único recurso real é o Internet Archive (também conhecido como The Wayback Machine).
Na verdade, quando sua página é rastreada, ela é basicamente desmontada. O texto é analisado (extraído) do documento.
Cada documento recebe seu próprio identificador junto com detalhes da localização (URL) e os “dados brutos” são encaminhados para o módulo indexador. As palavras/termos são salvos com o ID do documento associado no qual aparecem.
Aqui está um exemplo muito simples usando dois documentos e o texto que eles contêm que eu criei há 20 anos.
Recuperar a construção do índice
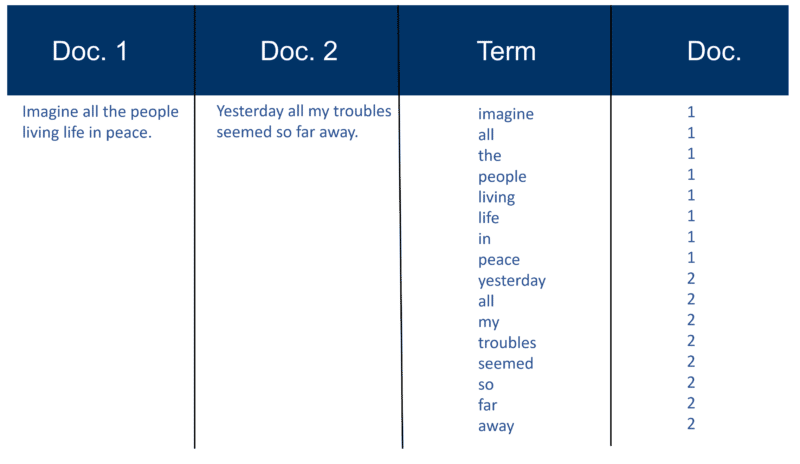
Depois que todos os documentos foram analisados, o arquivo invertido é classificado por termos:
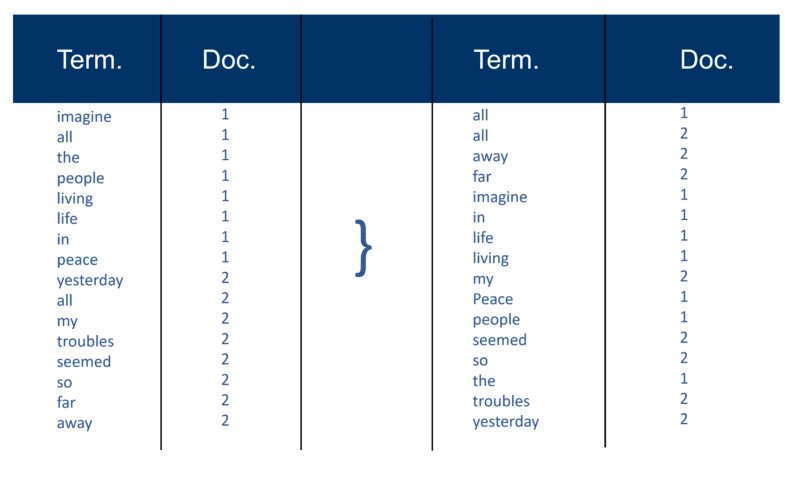
No meu exemplo, isso parece bastante simples no início do processo, mas as postagens (como são conhecidas em termos de recuperação de informações) para o índice vão em um Doc por vez. Novamente, com milhões de Docs, você pode imaginar a quantidade de poder de processamento necessária para transformar isso na enorme 'visão de termos' simplificada acima, primeiro por termo e depois por Doc dentro de cada termo.
Você notará minha referência a “milhões de documentos” de todos aqueles anos atrás. Claro, estamos em bilhões (até trilhões) nos dias de hoje. Na minha explicação básica de como o índice é criado, continuei com isso:
Cada mecanismo de pesquisa cria seu próprio dicionário personalizado (ou léxico como é – lembre-se de que muitas páginas da Web não são escritas em inglês), que deve incluir cada novo 'termo' descoberto após um rastreamento (pense na maneira como, ao usar um processador de texto como o Microsoft Word, você frequentemente tem a opção de adicionar uma palavra ao seu próprio dicionário personalizado, ou seja, algo que não ocorre no dicionário padrão de inglês). Uma vez que o mecanismo de busca tenha seu índice 'grande', alguns termos serão mais importantes que outros. Assim, cada termo merece seu próprio peso (valor). Muito do fator de ponderação depende do próprio termo. Claro, isso é bastante direto quando você pensa sobre isso, então mais peso é dado a uma palavra com mais ocorrências, mas esse peso é aumentado pela 'raridade' do termo em todo o corpus. O indexador também pode dar mais 'peso' às palavras que aparecem em determinados lugares do Doc. As palavras que apareceram na tag de título <title> são muito importantes. Palavras que estão em tags de título <h1> ou aquelas que estão em negrito <b> na página podem ser mais relevantes. As palavras que aparecem no texto âncora de links em páginas HTML, ou próximas a elas, são certamente vistas como muito importantes. Palavras que aparecem em tags de texto <alt> com imagens são anotadas, assim como palavras que aparecem em meta tags.
Além do texto original “Modern Information Retrieval” escrito pelo cientista Gerard Salton (considerado o pai da recuperação de informação moderna), eu tinha vários outros recursos na época que verificaram o que foi dito acima. Tanto Brian Pinkerton quanto Michael Maudlin (inventores dos mecanismos de busca WebCrawler e Lycos, respectivamente) me deram detalhes sobre como “a abordagem clássica de Salton” foi usada. E ambos me alertaram sobre as limitações.
Não só isso, Larry Page e Sergey Brin destacaram o mesmo no artigo original que escreveram no lançamento do protótipo do Google. Estou voltando a isso, pois é importante para ajudar a dissipar outro mito.
Mas primeiro, aqui está como eu expliquei a “abordagem clássica de Salton” em 2002. Certifique-se de observar a referência a “um par de peso de termo”.
Uma vez que o mecanismo de pesquisa tenha criado seu 'grande índice', o módulo indexador mede a 'frequência do termo' (tf) da palavra em um Doc para obter a 'densidade do termo' e, em seguida, mede a 'frequência inversa do documento' (idf) que é um cálculo da frequência de termos em um documento; o número total de documentos; o número de documentos que contêm o termo. Com este cálculo adicional, cada Doc pode agora ser visto como um vetor de valores tf x idf (valores binários ou numéricos correspondentes direta ou indiretamente às palavras do Doc). O que você tem então é um par de peso de termo. Você pode transpor isso como: um documento tem uma lista ponderada de palavras; uma palavra tem uma lista ponderada de documentos (um par de pesos de termos).
O modelo de espaço vetorial
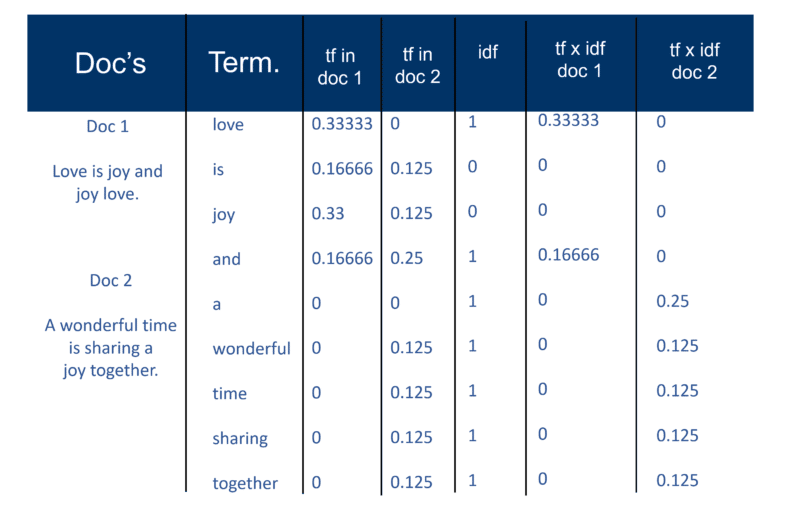
Agora que os Docs são vetores com um componente para cada termo, o que foi criado é um 'espaço vetorial' onde todos os Docs vivem. Mas quais são os benefícios de criar esse universo de Docs que agora tem essa magnitude?
Desta forma, se Doc 'd' (como exemplo) é um vetor então é fácil encontrar outros como ele e também encontrar vetores próximos a ele.
Intuitivamente, você pode determinar que documentos, que estão próximos no espaço vetorial, falam sobre as mesmas coisas. Ao fazer isso, um mecanismo de pesquisa pode criar agrupamentos de palavras ou documentos e adicionar vários outros métodos de ponderação.
No entanto, o principal benefício de usar vetores de termos para mecanismos de pesquisa é que o mecanismo de consulta pode considerar uma consulta em si como um documento muito curto. Dessa forma, a consulta se torna um vetor no mesmo espaço vetorial e o mecanismo de consulta pode medir a proximidade de cada Doc a ele.
O modelo de espaço vetorial permite que o usuário consulte o mecanismo de pesquisa por “conceitos” em vez de uma pesquisa “lexical” pura. Como você pode ver aqui, mesmo 20 anos atrás, a noção de conceitos e tópicos em vez de apenas palavras-chave estava muito em jogo.
OK, vamos lidar com essa coisa de “densidade de palavras-chave”. A palavra “densidade” aparece na explicação de como o modelo de espaço vetorial funciona, mas apenas quando se aplica ao cálculo em todo o corpus de documentos – não em uma única página. Talvez seja essa referência que fez tantos SEOs começarem a usar analisadores de densidade de palavras-chave em páginas únicas.
Também notei ao longo dos anos que muitos SEOs, que descobrem o modelo de espaço vetorial, tendem a tentar aplicar a ponderação clássica de termos tf x idf. Mas é muito menos provável que isso funcione, principalmente no Google, como os fundadores Larry Page e Sergey Brin afirmaram em seu artigo original sobre como o Google funciona – eles enfatizam a baixa qualidade dos resultados ao aplicar apenas o modelo clássico:
“Por exemplo, o modelo de espaço vetorial padrão tenta retornar o documento que mais se aproxima da consulta, dado que tanto a consulta quanto o documento são vetores definidos por sua ocorrência de palavra. Na web, essa estratégia geralmente retorna documentos muito curtos que são apenas a consulta mais algumas palavras.”
Tem havido muitas variantes para tentar contornar a 'rigidez' do Modelo de Espaço Vetorial. E ao longo dos anos com os avanços em inteligência artificial e aprendizado de máquina, existem muitas variações na abordagem que pode calcular o peso de palavras e documentos específicos no índice.
Você pode passar anos tentando descobrir quais fórmulas qualquer mecanismo de pesquisa está usando, muito menos o Google (embora possa ter certeza de qual eles não estão usando, como acabei de apontar). Portanto, tendo isso em mente, isso deve dissipar o mito de que tentar manipular a densidade de palavras-chave das páginas da Web ao criá-las é um esforço um pouco desperdiçado.
Resolvendo o problema da abundância
A primeira geração de mecanismos de busca dependia fortemente de fatores na página para classificação.
Mas o problema que você tem ao usar técnicas de classificação puramente baseadas em palavras-chave (além do que acabei de mencionar sobre o Google desde o primeiro dia) é algo conhecido como “o problema da abundância”, que considera a web crescendo exponencialmente a cada dia e o crescimento exponencial de documentos contendo o mesmo palavras-chave.
E isso coloca a questão neste slide que tenho usado desde 2002:

Você pode supor que o maestro da orquestra, que vem organizando e tocando a peça há muitos anos com muitas orquestras, seria o mais autoritário. Mas trabalhando apenas com técnicas de classificação de palavras-chave, é muito provável que o estudante de música seja o resultado número um.
Como você resolve esse problema?
Bem, a resposta é a análise de hiperlinks (também conhecido como backlinks).
Na minha próxima parte, explicarei como a palavra “autoridade” entrou no léxico de RI e SEO. E também explicarei a fonte original do que agora é chamado de EAT e em que realmente se baseia.
Até lá – fique bem, fique seguro e lembre-se da alegria que existe em discutir o funcionamento interno dos mecanismos de busca!
As opiniões expressas neste artigo são do autor convidado e não necessariamente do Search Engine Land. Os autores da equipe estão listados aqui.