
Tehnici de indexare și de clasificare a cuvintelor cheie revizuite: 20 de ani mai târziu
Publicat: 2022-08-04Când ghinda care avea să devină industria SEO a început să crească, indexarea și clasarea la motoarele de căutare s-au bazat ambele exclusiv pe cuvinte cheie.
Motorul de căutare ar potrivi cuvintele cheie dintr-o interogare cu cuvintele cheie din indexul său paralel cu cuvintele cheie care au apărut pe o pagină web.
Paginile cu cel mai mare scor de relevanță vor fi clasate în ordine folosind una dintre cele mai populare trei tehnici de recuperare:
- Model boolean
- Model probabilistic
- Model spațial vectorial
Modelul spațial vectorial a devenit cel mai relevant pentru motoarele de căutare.
Am de gând să revin în acest articol la explicația de bază și oarecum simplă a modelului clasic pe care l-am folosit pe vremuri (pentru că este încă relevant în mixul motoarelor de căutare).
Pe parcurs, vom risipi un mit sau două – cum ar fi noțiunea de „densitate a cuvintelor cheie” a unei pagini web. Să-l punem pe aia în pat o dată pentru totdeauna.
Cuvântul cheie: Unul dintre cele mai utilizate cuvinte în știința informației; pentru marketeri – un mister învăluit
„Ce este un cuvânt cheie?”
Habar nu ai de câte ori am auzit această întrebare când a apărut industria SEO. Și după ce am dat o explicație pe scurt, întrebarea următoare ar fi: „Deci, care sunt cuvintele mele cheie, Mike?”
Sincer, a fost destul de dificil să încerc să le explic agenților de marketing că anumite cuvinte cheie utilizate într-o interogare au fost cele care au declanșat paginile web corespunzătoare în rezultatele motoarelor de căutare.
Și da, asta ar ridica aproape sigur o altă întrebare: „Ce este o întrebare, Mike?”
Astăzi, termeni precum cuvânt cheie, interogare, index, clasare și toate celelalte sunt obișnuiți în lexicul de marketing digital.
Cu toate acestea, în calitate de SEO, cred că este extrem de util să înțelegem de unde sunt extrași și de ce și cum acești termeni se aplică în continuare la fel de mult acum ca atunci.
Știința regăsirii informațiilor (IR) este un subset sub termenul umbrelă „inteligență artificială”. Dar IR în sine este, de asemenea, compus din mai multe subseturi, inclusiv cel al bibliotecologiei și al științei informației.
Și acesta este punctul nostru de plecare pentru această a doua parte a călătoriei mele pe banda de memorie SEO. (Primul meu, în cazul în care ați ratat-o, a fost: Ne-am accesat cu crawlere web timp de 32 de ani: Ce s-a schimbat?)
Această serie de articole în curs de desfășurare se bazează pe ceea ce am scris într-o carte despre SEO acum 20 de ani, făcând observații despre stadiul tehnicii de-a lungul anilor și comparându-l cu locul în care ne aflăm astăzi.
Micuța bătrână din bibliotecă
Așadar, după ce am subliniat că există elemente de biblioteconomie sub bannerul de regăsire a informațiilor, permiteți-mi să vă relatez unde se potrivesc în căutarea pe web.
Aparent, bibliotecarii sunt identificați în principal ca bătrâne mici. Cu siguranță a apărut așa atunci când am intervievat câțiva oameni de știință de seamă în noul domeniu emergent al reluării informațiilor (IR) „web” cu toți acești ani în urmă.
Brian Pinkerton, inventatorul WebCrawler, împreună cu Andrei Broder, vicepreședinte Tehnologie și om de știință șef la Alta Vista, motorul de căutare numărul unu înaintea Google și într-adevăr Craig Silverstein, director de tehnologie la Google (și în special, angajatul Google numărul unu) au descris toate munca lor în acest nou domeniu ca încercarea de a obține un motor de căutare care să imite „bătrâna doamnă din bibliotecă”.
Bibliotecile se bazează pe conceptul de index – al cărui scop inițial a fost să încerce să organizeze și să clasifice fiecare animal, plantă și mineral cunoscut din lume.
Fișele au format coloana vertebrală a întregului sistem de biblioteci, indexând cantități vaste și variate de informații.
În afară de numele autorului, titlul cărții, subiectul și „termenii de index” notabili (alias, cuvinte cheie), etc., fișa de index ar avea și locația cărții. Și, prin urmare, după un timp, „bătrâna bibliotecară”, când ai întrebat-o despre o anumită carte, ar fi putut intuitiv să indice nu doar secțiunea bibliotecii, ci probabil chiar și raftul pe care se afla cartea, oferind o imagine personalizată. metoda de recuperare rapidă.
Cu toate acestea, când am explicat asemănarea acelui tip de sistem de indexare la motoarele de căutare, așa cum am făcut-o cu toți acești ani în urmă, a trebuit să adaug un avertisment care este încă important de înțeles:
„Cele mai mari motoare de căutare sunt bazate pe index într-un mod similar cu cel al unei biblioteci. După ce au stocat o mare parte a internetului în indici masivi, ei trebuie apoi să returneze rapid documentele relevante pentru un anumit cuvânt cheie sau expresie. Dar variația paginilor web, în ceea ce privește compoziția, calitatea și conținutul, este chiar mai mare decât dimensiunea datelor brute în sine. Web-ul în ansamblu nu are o structură unificatoare, cu o variantă enormă în stilul de autor și conținut mult mai amplu și mai complex decât în colecțiile tradiționale de documente text. Acest lucru face aproape imposibil ca un motor de căutare să aplice tehnici strict convenționale utilizate în biblioteci, sisteme de gestionare a bazelor de date și regăsirea informațiilor.”
Inevitabil, ceea ce s-a întâmplat atunci cu cuvintele cheie și felul în care scriem pentru web a fost apariția unui nou domeniu de comunicare.
După cum am explicat în carte, HTML ar putea fi privit ca un nou gen lingvistic și ar trebui tratat ca atare în studiile lingvistice viitoare. Există mult mai mult într-un document hipertext decât într-un document „text plat”. Și asta oferă mai mult o indicație despre ce este o anumită pagină web atunci când este citită de oameni, precum și textul care este analizat, clasificat și clasificat prin extragerea textului și extragerea de informații de către motoarele de căutare.
Uneori încă mai aud SEO referindu-se la paginile web de „citire automată” a motoarelor de căutare, dar acest termen aparține mult mai mult introducerii relativ recente a sistemelor de „date structurate”.
După cum mai trebuie să explic frecvent, un om care citește o pagină web și motoarele de căutare extrage text și extrag informații „despre” o pagină nu este același lucru cu oamenii care citesc o pagină web și motoarele de căutare sunt „alimentate” cu date structurate.
Cel mai bun exemplu tangibil pe care l-am găsit este acela de a face o comparație între o pagină web HTML modernă cu date structurate „citibile de mașină” și un pașaport modern. Aruncați o privire la pagina cu imagini de pe pașaport și veți vedea o secțiune principală cu imaginea și textul dvs. pe care oamenii să le citească și o secțiune separată în partea de jos a paginii, care este creată special pentru citirea automată prin glisare sau scanare.
În esență, o pagină web modernă este structurată ca un pașaport modern. Interesant este că acum 20 de ani am făcut referire la combinația om/mașină cu acest mic factoid:
„În 1747, medicul și filozoful francez Julien Offroy de la Mettrie a publicat una dintre cele mai importante lucrări din istoria ideilor. L-a intitulat L'HOMME MACHINE, care este cel mai bine tradus prin „om, o mașină”. Adesea, veți auzi expresia „a oamenilor și a mașinilor” și aceasta este ideea de bază a inteligenței artificiale.”
Am subliniat importanța datelor structurate în articolul meu anterior și sper să vă scriu ceva care cred că va fi de mare ajutor pentru a înțelege echilibrul dintre citirea oamenilor și citirea automată. Am simplificat-o complet astfel în 2002 pentru a oferi o raționalizare de bază:
- Date: o reprezentare a unor fapte sau idei într-o manieră formală, capabilă să fie comunicată sau manipulată printr-un proces.
- Informație: sensul pe care un om îl atribuie datelor prin intermediul convențiilor cunoscute utilizate în reprezentarea lor.
Prin urmare:
- Datele sunt legate de fapte și mașini.
- Informația este legată de sens și de oameni.
Să vorbim un minut despre caracteristicile textului și apoi voi aborda modul în care textul poate fi reprezentat ca date într-un lucru „oarecum neînțeles” (să spunem) în industria SEO numit model de spațiu vectorial.
Cele mai importante cuvinte cheie dintr-un index de motor de căutare față de cele mai populare cuvinte
Ai auzit vreodată de Legea lui Zipf?
Numit după profesorul de lingvistică de la Harvard George Kingsley Zipf, prezice fenomenul că, pe măsură ce scriem, folosim cuvinte familiare cu frecvență înaltă.
Zipf a spus că legea sa se bazează pe principalul predictor al comportamentului uman: străduința de a minimiza efortul. Prin urmare, legea lui Zipf se aplică aproape oricărui domeniu care implică producția umană.
Aceasta înseamnă că avem și o relație restrânsă între rang și frecvență în limbajul natural.
Majoritatea colecțiilor mari de documente text au caracteristici statistice similare. Cunoașterea acestor statistici este utilă deoarece influențează eficacitatea și eficiența structurilor de date utilizate pentru indexarea documentelor. Multe modele de recuperare se bazează pe ele.
Există modele de apariții în modul în care scriem – în general căutăm cea mai ușoară, mai scurtă, mai puțin implicată, cea mai rapidă metodă posibilă. Deci, adevărul este că folosim mereu aceleași cuvinte simple.
De exemplu, cu toți acești ani în urmă, am dat peste câteva statistici dintr-un experiment în care oamenii de știință au luat o colecție de 131 MB (care era date mari pe atunci) de 46.500 de articole de ziare (19 milioane de apariții pe termen).
Iată datele pentru primele 10 cuvinte și de câte ori au fost folosite în acest corpus. Vei înțelege ideea destul de repede, cred:
Frecvența cuvintelor
cel: 1130021
din 547311
la 516635
un 464736
în 390819
și 387703
că 204351
pentru 199340
este 152483
a spus 148302
Nu uitați, toate articolele incluse în corpus au fost scrise de jurnaliști profesioniști. Dar dacă te uiți la primele zece cuvinte cele mai des folosite, cu greu ai putea face o singură propoziție sensibilă din ele.
Deoarece aceste cuvinte comune apar atât de frecvent în limba engleză, motoarele de căutare le vor ignora ca „cuvinte stop”. Dacă cele mai populare cuvinte pe care le folosim nu oferă prea multă valoare unui sistem de indexare automată, care cuvinte fac?
După cum sa menționat deja, s-a lucrat mult în domeniul sistemelor de regăsire a informațiilor (IR). Abordările statistice au fost aplicate pe scară largă din cauza adaptării slabe a textului la modelele de date bazate pe logici formale (de exemplu, baze de date relaționale).
Deci, în loc să solicite utilizatorilor să poată anticipa cuvintele exacte și combinațiile de cuvinte care pot apărea în documentele de interes, IR-ul statistic le permite utilizatorilor să introducă pur și simplu un șir de cuvinte care ar putea apărea într-un document.
Apoi, sistemul ia în considerare frecvența acestor cuvinte într-o colecție de text și în documente individuale, pentru a determina care cuvinte sunt probabil cele mai bune indicii de relevanță. Se calculează un scor pentru fiecare document pe baza cuvintelor pe care le conține și sunt preluate documentele cu cel mai mare punctaj.
Am fost destul de norocos să intervievez un cercetător de frunte în domeniul IR, când mă cercetam pentru carte, în 2001. La acea vreme, Andrei Broder era om de știință șef la Alta Vista (în prezent Distinguished Engineer la Google) și discutam subiectul de „vectori de termen” și am întrebat dacă îmi poate da o explicație simplă despre ce sunt aceștia.

Mi-a explicat cum, atunci când „ponderează” termenii pentru importanță în index, poate observa apariția cuvântului „de” de milioane de ori în corpus. Acesta este un cuvânt care nu va avea deloc „greutate”, a spus el. Dar dacă vede ceva de genul cuvântului „hemoglobină”, care este un cuvânt mult mai rar în corpus, atunci acesta va primi ceva greutate.
Vreau să fac un pas rapid înapoi aici înainte de a explica cum este creat indexul și de a risipi un alt mit care a persistat de-a lungul anilor. Și acesta este cel în care mulți oameni cred că Google (și alte motoare de căutare) descarcă de fapt paginile tale web și le stochează pe un hard disk.
Nu deloc. Avem deja un loc unde să facem asta, se numește World Wide Web.
Da, Google păstrează un instantaneu „memorizat în cache” a paginii pentru o recuperare rapidă. Dar când conținutul paginii se modifică, data viitoare când pagina este accesată cu crawlere, versiunea stocată în cache se schimbă și.
De aceea, nu puteți găsi niciodată copii ale paginilor dvs. web vechi la Google. Pentru asta, singura ta resursă reală este Arhiva Internet (aka, The Wayback Machine).
De fapt, atunci când pagina dvs. este accesată cu crawlere, este practic demontată. Textul este analizat (extras) din document.
Fiecărui document i se oferă propriul său identificator împreună cu detaliile locației (URL), iar „datele brute” sunt transmise la modulul de indexare. Cuvintele/termenii sunt salvate cu ID-ul documentului asociat în care au apărut.
Iată un exemplu foarte simplu folosind două documente și textul pe care îl conțin pe care l-am creat acum 20 de ani.
Amintiți construcția indexului
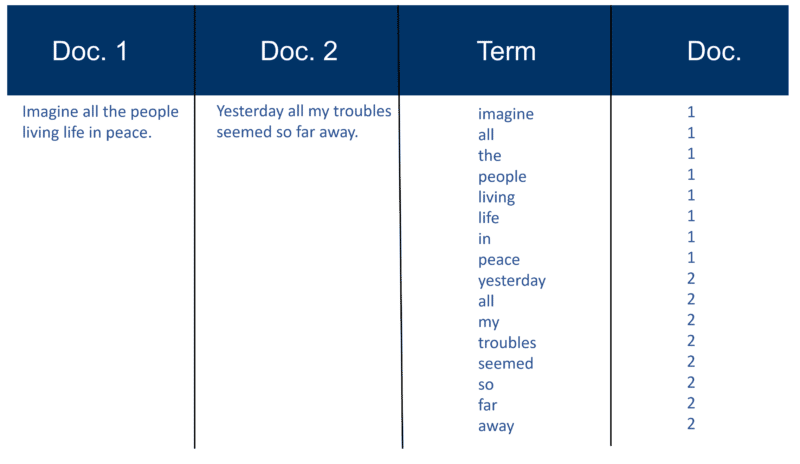
După ce toate documentele au fost analizate, fișierul inversat este sortat după termeni:
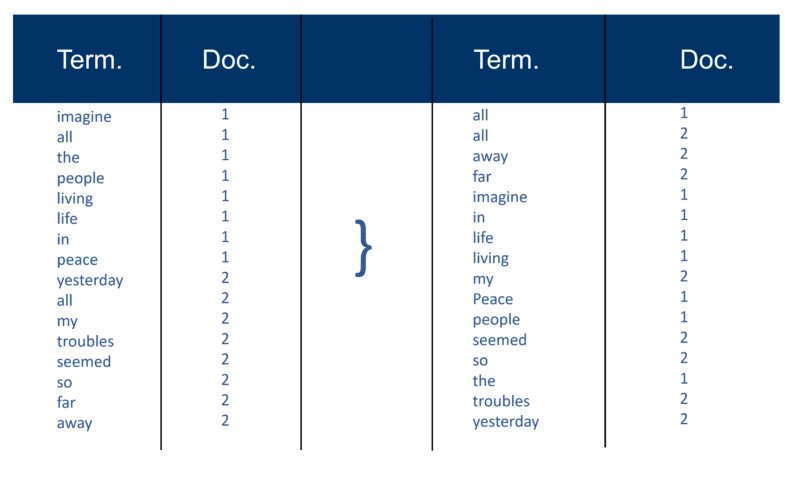
În exemplul meu, acest lucru pare destul de simplu la începutul procesului, dar postările (așa cum sunt cunoscute în termeni de regăsire a informațiilor) către index merg într-un Doc la un moment dat. Din nou, cu milioane de documente, vă puteți imagina cantitatea de putere de procesare necesară pentru a transforma acest lucru în „vizualizarea înțeleaptă a termenilor” masiv, care este simplificată mai sus, mai întâi după termen și apoi de către Doc în fiecare termen.
Veți observa referirea mea la „milioane de documente” din toți acești ani în urmă. Desigur, suntem în miliarde (chiar și trilioane) în aceste zile. În explicația mea de bază despre cum este creat indexul, am continuat cu asta:
Fiecare motor de căutare își creează propriul dicționar personalizat (sau lexic așa cum este – rețineți că multe pagini web nu sunt scrise în limba engleză), care trebuie să includă fiecare „termen” nou descoperit după un acces cu crawlere (gândiți-vă la modul în care, atunci când utilizați un procesor de texte precum Microsoft Word, aveți adesea opțiunea de a adăuga un cuvânt în propriul dicționar personalizat, adică ceva care nu apare în dicționarul standard englez). Odată ce motorul de căutare are indexul său „mare”, unii termeni vor fi mai importanți decât alții. Deci, fiecare termen merită propria sa pondere (valoare). O mare parte din factorul de ponderare depinde de termenul în sine. Desigur, acest lucru este destul de simplu când te gândești la asta, așa că se acordă mai multă greutate unui cuvânt cu mai multe apariții, dar această pondere este apoi mărită de „raritatea” termenului în întregul corpus. Indexatorul poate da, de asemenea, mai multă „pondere” cuvintelor care apar în anumite locuri în Doc. Cuvintele care au apărut în eticheta de titlu <title> sunt foarte importante. Cuvintele care sunt în etichetele de titlu <h1> sau cele care sunt îngroșate <b> pe pagină pot fi mai relevante. Cuvintele care apar în textul de ancorare al linkurilor de pe paginile HTML, sau în apropierea acestora, sunt cu siguranță considerate ca fiind foarte importante. Cuvintele care apar în etichetele de text <alt> cu imagini sunt notate, precum și cuvintele care apar în metaetichetele.
În afară de textul original „Modern Information Retrieval” scris de omul de știință Gerard Salton (considerat ca părintele regăsirii moderne de informații), am avut o serie de alte resurse pe vremea aceea care au verificat cele de mai sus. Atât Brian Pinkerton, cât și Michael Maudlin (inventatorii motoarelor de căutare WebCrawler și respectiv Lycos) mi-au oferit detalii despre cum a fost folosită „abordarea clasică Salton”. Și ambele m-au făcut să conștientizez limitele.
Nu numai că, Larry Page și Sergey Brin au subliniat același lucru în lucrarea originală pe care au scris-o la lansarea prototipului Google. Revin la asta, deoarece este important pentru a ajuta la risipirea unui alt mit.
Dar mai întâi, iată cum am explicat „abordarea clasică Salton” în 2002. Asigurați-vă că rețineți referirea la „o pereche de greutate a termenilor”.
Odată ce motorul de căutare și-a creat „indicele mare”, modulul de indexare măsoară „frecvența termenului” (tf) a cuvântului dintr-un document pentru a obține „densitatea termenilor” și apoi măsoară „frecvența inversă a documentului” (idf) care este un calcul al frecvenței termenilor dintr-un document; numărul total de documente; numărul documentelor care conțin termenul. Cu acest calcul suplimentar, fiecare Doc poate fi acum văzut ca un vector de valori tf x idf (valori binare sau numerice care corespund direct sau indirect cuvintelor din Doc). Ceea ce aveți atunci este o pereche de greutate pe termen. Puteți transpune acest lucru ca: un document are o listă ponderată de cuvinte; un cuvânt are o listă ponderată de documente (o pereche de pondere a termenilor).
Modelul spațial vectorial
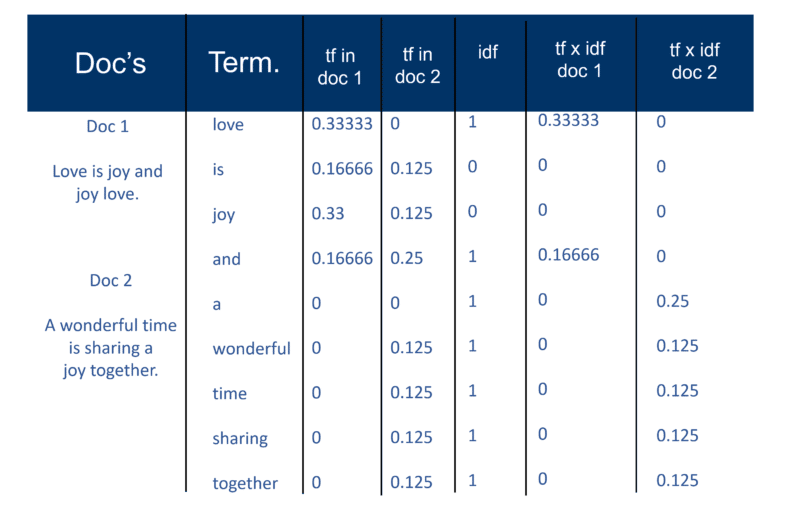
Acum că documentele sunt vectori cu o componentă pentru fiecare termen, ceea ce a fost creat este un „spațiu vectorial” în care locuiesc toți documentele. Dar care sunt beneficiile creării acestui univers de documente care au acum această amploare?
În acest fel, dacă Doc „d” (de exemplu) este un vector, atunci este ușor să găsiți alții ca acesta și, de asemenea, să găsiți vectori în apropierea acestuia.
În mod intuitiv, puteți determina apoi că documentele, care sunt apropiate în spațiul vectorial, vorbesc despre aceleași lucruri. Procedând astfel, un motor de căutare poate crea grupări de cuvinte sau documente și poate adăuga diverse alte metode de ponderare.
Cu toate acestea, principalul avantaj al utilizării vectorilor de termeni pentru motoarele de căutare este că motorul de interogare poate considera o interogare în sine ca fiind un document foarte scurt. În acest fel, interogarea devine un vector în același spațiu vectorial și motorul de interogare poate măsura proximitatea fiecărui document de acesta.
Modelul Vector Space permite utilizatorului să interogheze motorul de căutare pentru „concepte” mai degrabă decât o căutare pură „lexicală”. După cum puteți vedea aici, chiar și în urmă cu 20 de ani noțiunea de concepte și subiecte, spre deosebire de doar cuvinte cheie, era foarte în joc.
OK, să abordăm acest lucru cu „densitatea cuvintelor cheie”. Cuvântul „densitate” apare în explicația modului în care funcționează modelul de spațiu vectorial, dar numai așa cum se aplică calculului pe întreg corpul de documente – nu pe o singură pagină. Poate că acea referință a făcut ca atât de mulți SEO să înceapă să folosească analizatori de densitate a cuvintelor cheie pe pagini individuale.
De asemenea, am observat de-a lungul anilor că mulți SEO, care descoperă modelul spațiului vectorial, tind să încerce să aplice clasica ponderare a termenilor tf x idf. Dar este mult mai puțin probabil să funcționeze, în special la Google, așa cum au afirmat fondatorii Larry Page și Sergey Brin în lucrarea lor originală despre modul în care funcționează Google - ei subliniază calitatea slabă a rezultatelor atunci când aplică doar modelul clasic:
„De exemplu, modelul de spațiu vectorial standard încearcă să returneze documentul care aproximează cel mai mult interogarea, având în vedere că atât interogarea, cât și documentul sunt vectori definiți de apariția cuvântului. Pe web, această strategie returnează adesea documente foarte scurte care sunt doar interogarea plus câteva cuvinte.”
Au existat multe variante pentru a încerca să ocoliți „rigiditatea” modelului spațial vectorial. Și de-a lungul anilor, cu progresele în inteligența artificială și învățarea automată, există multe variații ale abordării care pot calcula ponderea anumitor cuvinte și documente din index.
Ați putea petrece ani de zile încercând să vă dați seama ce formule folosește orice motor de căutare, să nu mai vorbim de Google (deși puteți fi sigur pe care nu o folosesc, așa cum tocmai am subliniat). Deci, ținând cont de acest lucru, ar trebui să risipească mitul că încercarea de a manipula densitatea cuvintelor cheie a paginilor web atunci când le creați este un efort oarecum irosit.
Rezolvarea problemei abundenței
Prima generație de motoare de căutare s-a bazat în mare măsură pe factorii de pe pagină pentru clasare.
Dar problema pe care o întâmpinați folosind tehnici de clasare bazate pe cuvinte cheie (dincolo de ceea ce tocmai am menționat despre Google din prima zi) este ceva cunoscut sub numele de „problema abundenței”, care consideră că web-ul crește exponențial în fiecare zi și creșterea exponențială a documentelor care conțin același lucru. Cuvinte cheie.
Și asta pune întrebarea de pe acest slide pe care îl folosesc din 2002:

Puteți presupune că dirijorul de orchestră, care aranjează și cântă piesa de mulți ani cu multe orchestre, ar fi cel mai autoritar. Dar lucrând doar pe tehnici de clasare a cuvintelor cheie, este la fel de probabil ca studentul de muzică să fie rezultatul numărul unu.
Cum rezolvi acea problemă?
Ei bine, răspunsul este analiza hyperlink-urilor (aka, backlink-uri).
În următoarea mea tranșă, voi explica cum a intrat cuvântul „autoritate” în lexicul IR și SEO. Și voi explica, de asemenea, sursa originală a ceea ce se numește acum EAT și pe ce se bazează de fapt.
Până atunci – fiți bine, fiți în siguranță și amintiți-vă ce bucurie există în a discuta despre funcționarea interioară a motoarelor de căutare!
Opiniile exprimate în acest articol sunt cele ale autorului invitat și nu neapărat Search Engine Land. Autorii personalului sunt enumerați aici.