
Qu'est-ce que la recherche sémantique ? (Bases du SEO sémantique)
Publié: 2022-04-09
Nous le ressentons tous.
Le référencement a radicalement changé.
Ce qui fonctionnait quand j'ai commencé (quand le monde était encore en noir et blanc), ne fonctionne plus comme avant.
Et, à mesure que les moteurs de recherche évoluent, nous, les référenceurs, devons évoluer avec eux.
En essayant de trouver des réponses, j'ai découvert le référencement sémantique. Bien que les premières applications de la recherche sémantique remontent en fait à 2009, elle s'est accélérée au fil des ans, créant finalement une révolution dans le fonctionnement des moteurs de recherche.
J'ai découvert que la recherche sémantique influence toutes les bases du référencement, notamment :
- Recherche de mots clés
- Intention de recherche
- Création de contenu
- Architecture du site
- Maillage interne
- Et plus
Dans cet article de blog, je vais vous donner un aperçu de la recherche sémantique. Mon objectif est de vous donner une base solide sur laquelle travailler afin que, lorsque vous apprendrez les stratégies de référencement sémantique, vous compreniez pourquoi elles fonctionnent.
Afin de rendre ce message aussi utile que possible, j'ai essayé de garder un langage simple et j'ai évité de rendre le message trop long. J'ai l'intention de créer un contenu de suivi qui entrera dans les stratégies spécifiques.
Recherche sémantique
Tout commence donc par une recherche sémantique.
Mais qu'est-ce que la recherche sémantique ?
La recherche sémantique décrit comment Google vise non seulement à apporter des résultats en faisant correspondre des mots-clés à la requête de recherche, mais maintenant Google détermine l'intention et la signification de la requête afin d'apporter des résultats complets conçus pour :
- Répondez exactement à ce que l'utilisateur recherche
- Apportez des résultats qui prédisent la prochaine question de l'utilisateur avant même qu'il ne la pose
Alors, comment Google fait-il exactement cela ?
Eh bien, pour y parvenir, Google et d'autres moteurs de recherche au fil des ans ont changé leur façon de catégoriser les informations.
Auparavant, Google associait une requête de recherche à une page Web en utilisant des facteurs sur la page et hors page. Cela signifiait faire correspondre la requête aux mots clés qui apparaissaient à des endroits bien en vue dans votre contenu. Vous savez, les balises de titre, les H1, le texte d'ancrage, les balises alt et toutes ces optimisations SEO de base que vous avez apprises.
Il est important de noter que pour Google, la requête de recherche et le contenu n'étaient à l'époque que des chaînes de caractères qui aboutissaient à des stratégies de référencement axées sur les mots clés.
Cela signifie que Google a identifié et classé le contenu en examinant les balises de titre, etc. Une fois que Google a classé le contenu de cette façon, Google a pu apporter des résultats de recherche en faisant correspondre le contenu aux mots-clés trouvés dans la requête de recherche.
Mais en 2012, Google a introduit Hummingbird, une révolution dans la manière dont les moteurs de recherche classent les informations. En d'autres termes, Google s'est éloigné des chaînes et les a remplacées par des choses.
Cela signifie que Google stocke désormais des informations sur des entités (ou des choses) du monde réel dans une base de données appelée Knowledge Graph. Google dispose également d'informations sur la manière dont ces entités sont liées les unes aux autres et ce changement de paradigme dans la catégorisation des informations a considérablement façonné les pages de résultats.
Cela signifie qu'une requête de recherche n'est plus une simple chaîne de caractères. Google peut désormais "comprendre" que la chaîne fait référence à une entité spécifique.
Maintenant que vous avez un aperçu de base, je dois vous expliquer :
- Qu'est-ce que le Google Knowledge Graph ?
- Quelles sont les entités Google ?
- Comment Google comprend les relations entre les entités
Qu'est-ce que le Knowledge Graph de Google ?
Le Knowledge Graph de Google est une base de données de faits sur des entités (personnes, lieux et objets). Cette base de données permet à Google de répondre aux questions sur chaque entité et d'afficher ces réponses et les faits connexes dans les résultats de recherche.
Google compile ces faits à partir d'un certain nombre de sources différentes, notamment :
- Sources publiques telles que Wikipedia et le CIA World Factbook
- Informations sous licence telles que les résultats sportifs et les prévisions météorologiques
- Propriétaires de contenu
Cependant, avoir des quantités massives d'informations n'est pas utile à moins qu'elles ne soient catégorisées et structurées. (J'expliquerai comment Google structure ces informations plus loin dans cet article.)
Cela permet à Google de présenter deux types d'informations sur une entité donnée dans les résultats de recherche.
Tout d'abord, Google donnera un résumé général du sujet général. Il peut s'agir d'une définition ou d'un bref résumé de la vie d'une personne célèbre.
Deuxièmement, en comprenant la relation entre les choses, Google est en mesure de présenter des informations connexes et des requêtes connexes sur le sujet. Cela permet à l'utilisateur d'explorer le sujet par lui-même.
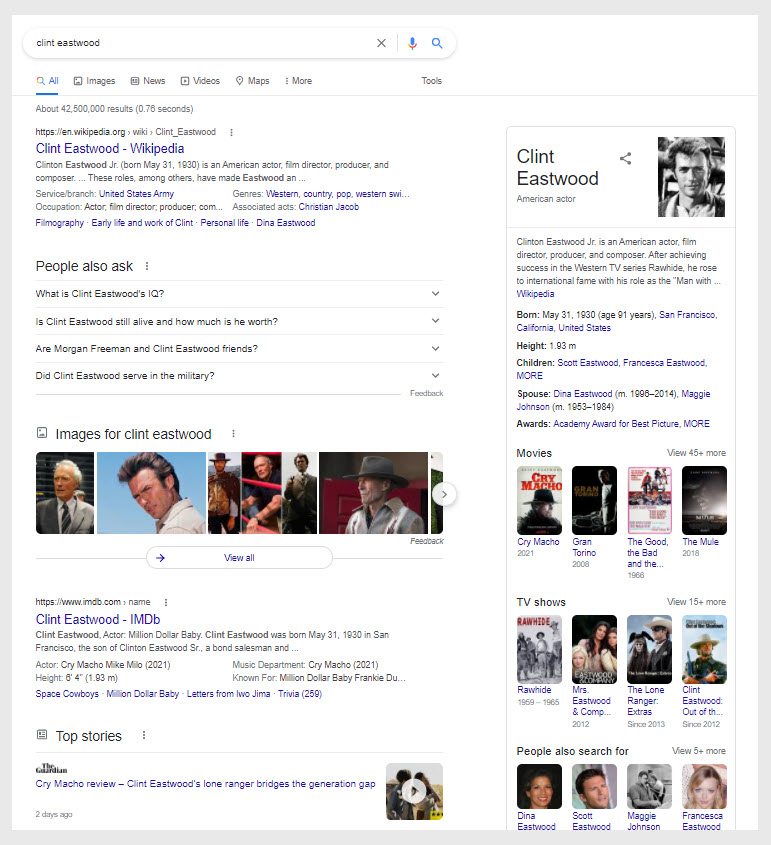
Par exemple, si vous regardez la capture d'écran ci-dessus, vous verrez un panneau de connaissances sur le côté droit de l'écran. Le haut du panneau de connaissances définit qui est Clint Eastwood tout en donnant des informations de base.
Si vous avez compris les informations de base et que vous êtes un peu curieux d'approfondir le sujet, le panneau de connaissances présente une liste de films, la boîte Les gens demandent aussi des questions fréquemment posées et la fonction Top Stories présente les actualités actuelles.
En ajoutant toutes ces options, Google invite l'utilisateur à explorer plus d'informations sur l'entité.
Bon, nous avons un peu exploré le Knowledge Graph, comprenons maintenant ce que sont les entités.
Que sont les entités Google ?
Google définit les entités comme « une chose ou un concept singulier, unique, bien défini et distinctif ».
Bien que nous puissions imaginer qu'une entité se réfère à un objet, selon la définition de Google, une entité pourrait tout aussi bien se référer à quelque chose d'abstrait comme un concept. Mais, pour être définis comme une entité, ils sont représentés linguistiquement par des noms. Autrement dit, une entité est une chose qui peut être identifiée, classée et catégorisée.
Cela signifie que même les couleurs, les sentiments ou les idées peuvent être des entités.
Maintenant, pour vraiment "comprendre" ces entités, Google doit leur donner un contexte en leur attribuant des attributs.
Par exemple, une requête pour "pomme" est ambiguë pour Google. Sur quelle entité le chercheur recherche-t-il des informations ? Cherchent-ils des résultats sur le fruit ou Apple sur l'entreprise ?
En catégorisant une entité comme un type de fruit et une autre comme une marque qui vend des appareils, Google est en mesure de catégoriser les pommes de deux manières différentes et donc de servir deux intentions de recherche complètement différentes avec deux entités différentes.
Le Knowledge Graph de Google ne se contente pas d'attribuer des attributs aux entités pour les définir comme uniques. Google utilise également ces attributs pour "comprendre" comment ces entités sont interconnectées. Les entités avec des attributs similaires sont regroupées.
En d'autres termes, les pommes, les oranges et les poires sont toutes regroupées en tant que fruits.
En plus de cela, le Knowledge Graph de Google regroupe également les entités en sujets et est capable de comprendre que les sujets existent dans une structure hiérarchique de sujets et de sous-sujets.
Google appelle cela la couche thématique.
La couche de sujets permet à Google d'ajouter dynamiquement des onglets de sous-sujets à ses panneaux de connaissances, transformant l'expérience de recherche d'une recherche unique en un voyage qui peut potentiellement emmener un chercheur à travers un sujet entier.
Ainsi, par exemple, si vous deviez rechercher le vaste sujet "l'univers", vous pourriez rechercher des informations générales. Mais, une fois que vous aurez compris ce pour quoi vous êtes venu, vous voudrez peut-être approfondir le sujet.
Google vous aide en ajoutant des sous-sujets au Knowledge Panel.

Comme vous pouvez le voir dans la capture d'écran ci-dessus, Google ajoute des onglets déroulants extensibles pour les sous-thèmes :
- Entropie
- Température
- Longueur
- Centre
Cela nous montre que Google est capable non seulement de regrouper des entités via des attributs partagés, mais également de comprendre comment elles existent dans une hiérarchie de sujets et de sous-sujets.
Si vous souhaitez mieux comprendre cela, consultez notre analyse d'entité de la couche thématique de Google.
Une fois que nous comprenons ce que sont les entités, examinons plus en détail comment les moteurs de recherche comprennent leurs relations. Quelle est l'anatomie des informations dans le Knowledge Graph de Google ?
Eh bien, tout cela nous amène à des triplets.
Qu'est-ce qu'un triplé ?
Un triple fait référence à la relation entre deux entités. Ces relations existent sous forme d'informations dans le Knowledge Graph qui est structuré à l'aide d'une structure sujet-prédicat-objet.
En termes simples, le sujet et l'objet sont des entités. Le prédicat décrit la relation entre ces deux entités.
Ainsi, par exemple, si nous devions regarder la phrase « Darrell aime la musique ».
La phrase est composée de :
- Un sujet : Darrell
- Prédicat : J'aime
- Objet : Musique
Le sujet et l'objet dans cet exemple sont des entités. Le mot "j'aime" décrirait la relation entre les entités.

En allant plus loin, l'objet de notre triple « musique » pourrait être le sujet d'un triplet différent.
Ainsi, la phrase « La musique est une forme d'art » utilise l'entité « musique » qui est apparue comme objet dans la dernière phrase « Darrell aime la musique ». Cependant, cette entité est maintenant un sujet dans cette nouvelle phrase.
En interconnectant les entités de cette manière, Google a lié trois entités ensemble. En stockant les informations de cette manière, Google relie littéralement des millions d'entités les unes aux autres.
En comprenant ce concept, vous avez l'un des fondements du référencement sémantique.
Que se passe-t-il lorsque quelqu'un effectue une recherche sur Google ?
Nous avons donc couvert quelques concepts de base pour comprendre la recherche sémantique. Maintenant, rassemblons tout en examinant ce qui se passe réellement lorsque quelqu'un effectue une recherche sur Google.
Pour comprendre cela, nous devons essentiellement comprendre comment Google traite les requêtes de recherche, car c'est la première étape pour que Google apporte des résultats aux pages de résultats.
Comprendre les requêtes de recherche
Pour qu'un moteur de recherche fournisse des résultats complets qui correspondent étroitement à l'intention de l'utilisateur et emmène l'utilisateur dans un voyage de découverte, Google doit comprendre ce que l'utilisateur recherche lorsqu'il tape une requête dans son navigateur.
Pour y parvenir, Google doit tenter de comprendre le sens sous-jacent de la requête du chercheur.
Ce n'est pas si facile à réaliser, cependant. En tant que personnes, nous avons tendance à trouver de nombreuses façons de dire la même chose, et formuler une question de différentes manières peut souvent créer des significations légèrement différentes.
De plus, il est important de comprendre que Google n'est pas capable de comprendre le langage comme un humain le peut. En d'autres termes, Google ne peut pas (encore) comprendre l'intention de l'utilisateur à partir de la structure des phrases et de la linguistique.
Mais, Google est capable d'examiner sa base de données d'entités et leurs relations et de comprendre essentiellement ce qu'un chercheur recherche.
Par exemple, tapez ces deux recherches différentes dans Google :
- qui sont les membres des red hot chili peppers
- membres des piments rouges
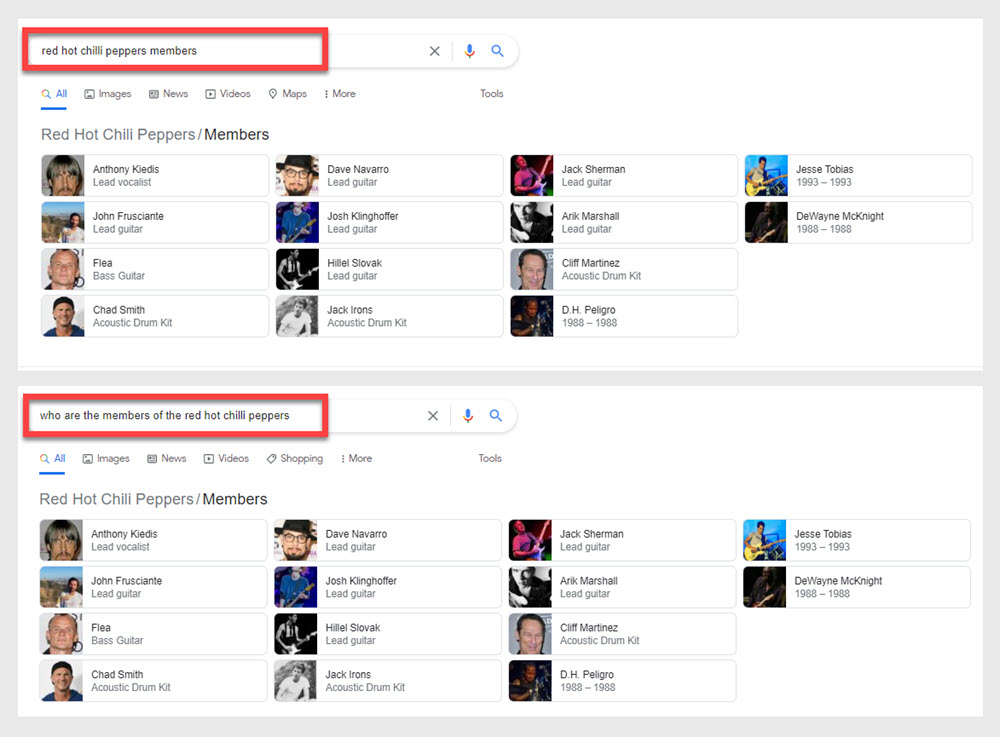
Si vous l'avez fait, vous remarquerez que les deux requêtes ont donné des résultats similaires même si une requête était formulée comme une question tandis que l'autre n'était qu'une question implicite. La raison en est que Google est capable de comprendre l'entité "Red Hot Chilli Peppers". Google comprend également que cette entité est associée à d'autres entités.
L'entité Anthony Kiedis, par exemple, est étroitement liée à l'entité Red Hot Chilli Peppers.
De plus, cette relation est définie comme un « membre ».
Ayant cette relation dans sa base de données, Google traite les deux requêtes de la même manière même si une requête inclut les mots "qui sont" tandis que l'autre nomme simplement l'entité Red Hot Chilli Peppers et attache le mot membres.
L'utilisateur recherche ces entités étroitement liées définies comme des « membres ». Google peut alors apporter des résultats basés sur sa "compréhension" de la requête.
Maintenant, que se passe-t-il lorsque Google ne "comprend" pas la requête ? Que se passe-t-il si la base de données de Google n'inclut pas les entités sur lesquelles porte la requête ou si la base de données ne comprend pas la connexion entre les entités ?
Dans des cas comme celui-ci, Google s'appuie sur des algorithmes comme Rank Brain pour imiter la compréhension sémantique.
Rank Brain le fait en utilisant une base de données de requêtes similaires et fait essentiellement une supposition.
Cela peut parfois entraîner plusieurs intentions de recherche sur une SERP.
=> Consultez notre guide sur la façon d'effectuer une analyse SERP pour comprendre l'intention de l'utilisateur.
Pourquoi la recherche sémantique ?
En passant, tout cela soulève la question, pourquoi?
Je veux dire, on dirait que Google a inventé la bibliothèque la plus sophistiquée au monde.
La réponse est qu'en comprenant les entités et leurs relations, Google est en mesure de fournir une expérience utilisateur exceptionnelle. Basé sur les données de Google, il est capable de présenter un sujet de haut en bas. Cela signifie que lorsqu'un chercheur recherche un sujet, Google est en mesure de fournir les informations que le chercheur recherchait et de prédire ce que le chercheur veut savoir ensuite.
Pour ce faire, Google présentera des intentions d'utilisateur étroitement liées dans n'importe quel SERP donné. De cette façon, une fois que l'utilisateur a trouvé ce qu'il recherche, de nouvelles questions peuvent surgir dans son esprit. En d'autres termes, la question initiale se transforme en un voyage de découverte, entraînant de nombreuses recherches.
Si vous voulez voir cela en action, consultez notre article de blog : Comprendre l'intention de l'utilisateur (analyser plusieurs intentions d'utilisateur)
Recherche sémantique dans une coquille de noix
J'espère que, maintenant que vous avez vu cet article, vous êtes bien placé pour vous plonger dans des stratégies de référencement sémantique exploitables. Bien que j'aie essayé de garder un langage simple pour vraiment comprendre le sujet, c'est une bonne idée de continuer à lire. En d'autres termes, considérez cet article de blog comme un tremplin pour approfondir vos connaissances.
Heureusement, il existe une mine d'informations en ligne dans lesquelles vous pouvez vous enfoncer, comme le contenu créé par des personnes comme Bill Slawski, Koray Tugberk GUBUR et Jason Barnard qui décomposent différents aspects du référencement sémantique.
Maintenant que vous comprenez la recherche sémantique, je suis sûr que vous vous demandez comment vous pouvez l'utiliser pour augmenter votre classement et votre trafic. La première étape consiste à comprendre la différence entre les mots-clés et les sujets.