
Что такое семантический поиск? (Основы семантического SEO)
Опубликовано: 2022-04-09
Мы все это чувствуем.
SEO сильно изменилось.
То, что работало, когда я только начинал (когда мир был еще черно-белым), теперь работает не так, как раньше.
И по мере развития поисковых систем мы, оптимизаторы, должны развиваться вместе с ними.
Пытаясь найти ответы, я обнаружил семантическое SEO. Хотя первые приложения семантического поиска на самом деле относятся к 2009 году, с годами он набирал обороты, что в конечном итоге привело к революции в том, как работают поисковые системы.
Я обнаружил, что семантический поиск влияет на все основы SEO, включая:
- Исследование ключевых слов
- Цель поиска
- Создание контента
- Архитектура сайта
- Внутренняя перелинковка
- И более
В этом сообщении блога я дам вам обзор семантического поиска. Моя цель — дать вам прочную основу для работы, чтобы, изучая семантические стратегии SEO, вы понимали, почему они работают.
Чтобы сделать этот пост максимально полезным, я постарался сделать его простым и не стал слишком длинным. Я намерен создать последующий контент, который попадет в конкретные стратегии.
Семантический поиск
Итак, все начинается с семантического поиска.
Но что такое семантический поиск?
Семантический поиск описывает, как Google стремится не просто получать результаты путем сопоставления ключевых слов с поисковым запросом, но теперь Google определяет цель и значение запроса, чтобы получить полные результаты, предназначенные для:
- Отвечайте точно, что ищет пользователь
- Получите результаты, которые предсказывают следующий вопрос пользователя еще до того, как он его задаст
Итак, как именно Google это делает?
Ну, чтобы добиться этого, Google и другие поисковые системы с годами изменили способ классификации информации.
Раньше Google сопоставлял поисковый запрос с веб-страницей, используя внутренние и внешние факторы. Это означало сопоставление запроса с ключевыми словами, которые появлялись на видном месте в вашем контенте. Вы знаете, теги заголовков, H1, якорный текст, теги alt и все те основные SEO-оптимизации, о которых вы узнали.
Важно отметить, что в те дни для Google поисковый запрос и контент были не более чем строками символов, что приводило к SEO-стратегиям, ориентированным на ключевые слова.
Это означает, что Google идентифицировал и классифицировал контент, изучив теги заголовков и т. д. После того, как Google классифицировал контент таким образом, Google смог вывести результаты поиска, сопоставив контент с ключевыми словами, найденными в поисковом запросе.
Но в 2012 году Google представил Hummingbird, который произвел революцию в том, как поисковые системы классифицируют информацию. Другими словами, Google отказался от строк и заменил их вещами.
Это означает, что Google теперь хранит информацию о реальных сущностях (или вещах) в базе данных, называемой Графиком знаний. У Google также есть информация о том, как эти объекты связаны друг с другом, и этот сдвиг парадигмы в категоризации информации сильно повлиял на страницы результатов.
Это означает, что поисковый запрос больше не является простой строкой символов. Теперь Google может «понимать», что строка относится к определенному объекту.
Теперь, когда у вас есть общий обзор, мне нужно объяснить:
- Что такое График знаний Google
- Что такое объекты Google
- Как Google понимает отношения между сущностями
Что такое График знаний Google?
График знаний Google — это база данных фактов о сущностях (людях, местах и вещах). Эта база данных позволяет Google отвечать на вопросы о каждой сущности и отображать эти ответы и связанные факты в результатах поиска.
Google собирает эти факты из ряда различных источников, включая:
- Общедоступные источники, такие как Википедия и Всемирная книга фактов ЦРУ.
- Лицензированная информация, такая как спортивные результаты и прогнозы погоды
- Владельцы контента
Однако наличие большого количества информации бесполезно, если она не классифицирована и не структурирована. (Я объясню, как Google структурирует эту информацию позже в этом посте.)
Это позволяет Google отображать два типа информации о данном объекте в результатах поиска.
Сначала Google даст общее резюме по общей теме. Это может быть определение или краткое изложение жизни известного человека.
Во-вторых, понимая взаимосвязь между вещами, Google может предоставлять связанную информацию и соответствующие запросы по теме. Это позволяет пользователю исследовать тему самостоятельно.
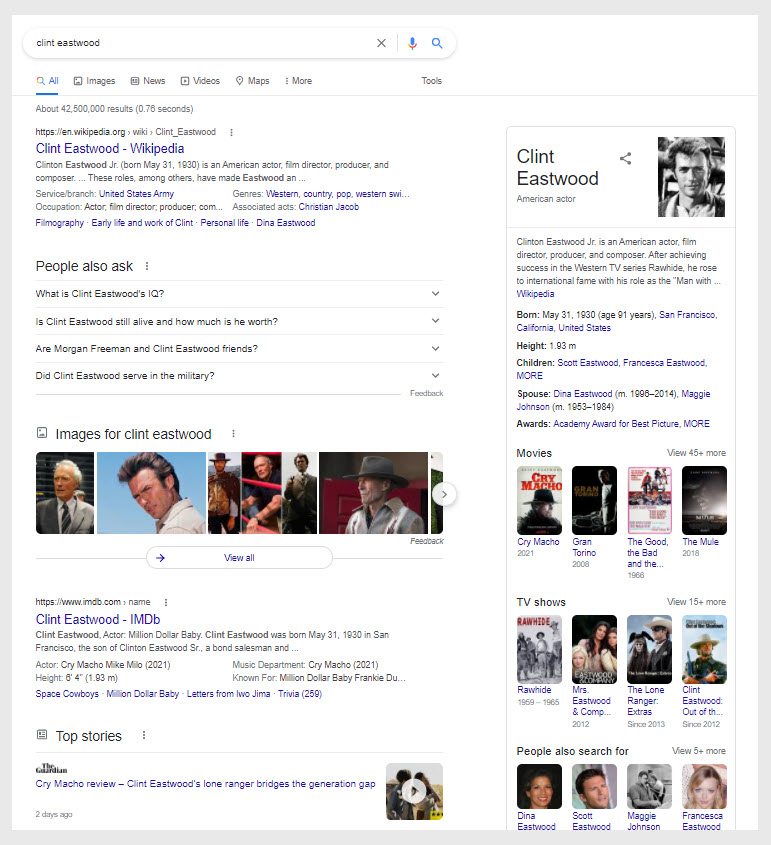
Например, если вы посмотрите на скриншот выше, вы увидите панель знаний в правой части экрана. В верхней части панели знаний указано, кто такой Клинт Иствуд, а также дана основная информация.
Если вы поняли основную информацию и вам немного любопытно продолжить изучение темы, на панели знаний есть список фильмов, в поле «Люди также задают вопросы» представлены часто задаваемые вопросы, а в разделе «Главные новости» представлены текущие новости.
Добавляя все эти параметры, Google предлагает пользователю изучить дополнительную информацию об объекте.
Итак, мы немного изучили Граф знаний, давайте теперь разберемся, что такое сущности.
Что такое объекты Google?
Google определяет сущности как «вещь или концепцию, которая является единственной, уникальной, четко определенной и различимой».
Хотя мы можем представить, что сущность относится к объекту, по определению Google, сущность может также относиться к чему-то абстрактному, например, к концепции. Но для того, чтобы их можно было определить как сущность, они лингвистически представлены существительными. Иными словами, объект — это вещь, которую можно идентифицировать, классифицировать и категоризировать.
Это означает, что даже цвета, чувства или идеи могут быть сущностями.
Теперь, чтобы по-настоящему «понять» эти объекты, Google должен дать им контекст, назначив им атрибуты.
Например, запрос «яблоко» неоднозначен для Google. О каком объекте ищет информацию искатель? Они ищут результаты о фруктах или компании Apple?
Классифицируя один объект как тип фруктов, а другой как бренд, который продает устройства, Google может классифицировать яблоки двумя разными способами и, следовательно, обслуживать два совершенно разных поисковых намерения с двумя разными объектами.
Сеть знаний Google не просто присваивает объектам атрибуты, чтобы определить их как уникальные. Google также использует эти атрибуты, чтобы «понимать», как эти объекты взаимосвязаны. Объекты с похожими атрибутами группируются вместе.
Другими словами, яблоки, апельсины и груши сгруппированы как фрукты.
Кроме того, Google Knowledge Graph также группирует объекты по темам и может понять, что темы существуют в иерархической структуре тем и подтем.
Google называет это тематическим слоем.
Тематический уровень позволяет Google динамически добавлять вкладки подтем в свои панели знаний, превращая поисковый процесс из одного поиска в путешествие, которое потенциально может провести искателя по всей теме.
Так, например, если бы вы искали широкую тему «Вселенная», вы могли бы искать общую информацию. Но как только вы получите то, за чем пришли, вы, возможно, захотите продолжить изучение темы.
Google помогает вам, добавляя подтемы в панель знаний.

Как вы можете видеть на скриншоте выше, Google добавляет расширяемые раскрывающиеся вкладки для подтем:
- Энтропия
- Температура
- Длина
- Центр
Это показывает нам, что Google может не только группировать объекты с помощью общих атрибутов, но также понимает, как они существуют в иерархии тем и подтем.
Если вы хотите глубже понять это, ознакомьтесь с нашим анализом сущностей тематического слоя Google.
Как только мы поймем, что такое сущности, давайте подробнее рассмотрим, как поисковые системы понимают их отношения. Какова анатомия информации в сети знаний Google?
Что ж, это все приводит нас к тройкам.
Что такое тройка?
Тройка относится к отношениям между двумя сущностями. Эти отношения существуют в виде информации в сети знаний, которая структурирована с использованием структуры субъект-предикат-объект.
Проще говоря, субъект и объект являются сущностями. Предикат описывает отношение между этими двумя сущностями.
Так, например, если бы мы посмотрели на предложение «Даррелл любит музыку».
Предложение состоит из:
- Субъект: Даррелл
- Предикат: нравится
- Объект: Музыка
И субъект, и объект в этом примере являются сущностями. Слово «нравится» будет описывать отношения между сущностями.

В дальнейшем объект в нашей тройной «музыке» может быть субъектом в другой тройке.
Таким образом, в предложении «Музыка — это форма искусства» используется сущность «музыка», которая появилась как объект в последнем предложении «Даррелл любит музыку». Однако эта сущность теперь является подлежащим в этом новом предложении.
Связывая сущности таким образом, Google связал вместе три сущности. Сохраняя информацию таким образом, Google связывает буквально миллионы объектов друг с другом.
Поняв эту концепцию, вы получите одну из основ семантического SEO.
Что происходит, когда кто-то ищет в Google?
Итак, мы рассмотрели некоторые основные понятия в понимании семантического поиска. Теперь давайте соберем все воедино и посмотрим, что на самом деле происходит, когда кто-то ищет в Google.
Чтобы понять это, мы должны в основном понять, как Google обрабатывает поисковые запросы, поскольку это первый шаг в Google, выводящий результаты на страницы результатов.
Понимание поисковых запросов
Чтобы поисковая система выдавала полные результаты, точно соответствующие намерениям пользователя, и отправляла пользователя в путь открытий, Google необходимо понимать, что ищет пользователь, когда он вводит запрос в свой браузер.
Чтобы добиться этого, Google должен попытаться понять основное значение запроса пользователя.
Однако добиться этого не так просто. Как люди, мы, как правило, находим много способов сказать одно и то же, и разные формулировки вопроса часто могут иметь несколько разные значения.
Более того, важно понимать, что Google не может понимать язык так, как это может сделать человек. Другими словами, Google (пока) не может понять намерения пользователя по структуре предложения и лингвистике.
Но Google может просматривать свою базу данных сущностей и их взаимосвязей и в основном выяснять, что ищет искатель.
Например, введите эти два разных поиска в Google:
- кто входит в состав Red Hot Chili Peppers
- члены Red Hot Chili Peppers
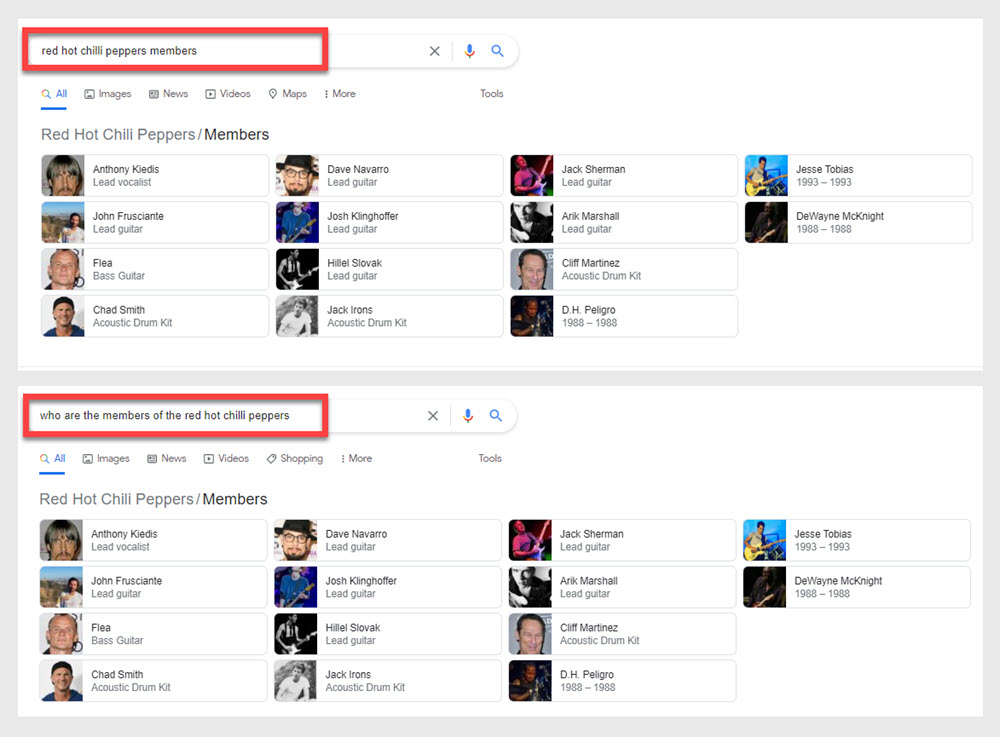
Если вы это сделали, вы заметите, что оба запроса принесли одинаковые результаты, даже если один запрос был сформулирован как вопрос, а другой был только подразумеваемым вопросом. Причина в том, что Google может понять сущность «Red Hot Chilli Peppers». Google также понимает, что с этим объектом связаны другие объекты.
Например, Энтони Кидис тесно связан с Red Hot Chilli Peppers.
Более того, эта связь определяется как «член».
Имея это отношение в своей базе данных, Google обрабатывает два запроса одинаково, даже если один запрос включает слова «кто есть», а другой просто называет сущность Red Hot Chilli Peppers и присоединяет слово «члены».
Пользователь ищет эти тесно связанные объекты, определенные как «члены». Затем Google может предоставить результаты на основе своего «понимания» запроса.
Что происходит, когда Google не «понимает» запрос? Что произойдет, если база данных Google не включает объекты, о которых идет речь, или база данных не понимает связь между объектами?
В подобных случаях Google полагается на такие алгоритмы, как Rank Brain, для имитации семантического понимания.
Rank Brain делает это, используя базу данных похожих запросов, и в основном делает предположения.
Иногда это может привести к множественным поисковым запросам в поисковой выдаче.
=> Ознакомьтесь с нашим руководством о том, как выполнить анализ поисковой выдачи, чтобы понять намерения пользователя.
Почему семантический поиск?
Как побочный момент, все это вызывает вопрос, почему?
Я имею в виду, похоже, что Google изобрел самую сложную библиотеку в мире.
Ответ заключается в том, что благодаря пониманию сущностей и их взаимосвязей Google может обеспечить первоклассный пользовательский интерфейс. Основываясь на данных Google, он может представить тему сверху вниз. Это означает, что когда искатель ищет тему, Google может предоставить информацию, которую искал искатель, а также предсказать, что искатель хочет узнать дальше.
Для этого Google будет отображать тесно связанные намерения пользователей в любой заданной поисковой выдаче. Таким образом, когда у пользователя есть то, что он ищет, у него могут возникнуть новые вопросы. Другими словами, первоначальный вопрос превращается в путешествие, которое приводит к многочисленным поискам.
Если вы хотите увидеть это в действии, ознакомьтесь с записью в нашем блоге: Понимание намерений пользователя (анализ намерений нескольких пользователей)
Семантический поиск в ореховой скорлупе
Надеюсь, что теперь, когда вы увидели этот пост, у вас есть возможность углубиться в некоторые действенные семантические стратегии SEO. Несмотря на то, что я пытался сохранить простой язык, чтобы по-настоящему понять тему, было бы неплохо продолжить чтение. Другими словами, рассматривайте этот пост в блоге как трамплин для дальнейшего расширения ваших знаний.
К счастью, в Интернете есть огромное количество информации, в которую вы можете погрузиться, например, контент, созданный такими людьми, как Билл Славски, Корай Тугберк Губур и Джейсон Барнард, которые разбирают различные аспекты семантического SEO.
Теперь, когда вы понимаете семантический поиск, я уверен, вам интересно, как вы можете использовать его для повышения своего рейтинга и трафика. Первый шаг — понять разницу между ключевыми словами и темами.