
¿Qué es la búsqueda semántica? (Conceptos básicos de SEO semántico)
Publicado: 2022-04-09
Todos lo sentimos.
El SEO ha cambiado drásticamente.
Lo que solía funcionar cuando comencé (cuando el mundo todavía era en blanco y negro), ya no funciona como antes.
Y, a medida que evolucionan los motores de búsqueda, los SEO tenemos que evolucionar con ellos.
Al tratar de encontrar respuestas, descubrí el SEO semántico. Aunque las primeras aplicaciones de la búsqueda semántica en realidad se remontan a 2009, se ha acelerado a lo largo de los años y finalmente ha creado una revolución en el funcionamiento de los motores de búsqueda.
Descubrí que la búsqueda semántica influye en todos los conceptos básicos de SEO, incluidos:
- Investigación de palabras clave
- Intención de búsqueda
- Creación de contenido
- Arquitectura del sitio
- Enlace interno
- Y más
En esta publicación de blog, le daré una descripción general de la búsqueda semántica. Mi objetivo es brindarle una base sólida con la que trabajar para que cuando aprenda estrategias de SEO semántico comprenda por qué funcionan.
Para que esta publicación sea lo más útil posible, he intentado mantener el lenguaje simple y he evitado que la publicación sea demasiado larga. Tengo la intención de crear contenido de seguimiento que entrará en las estrategias específicas.
Búsqueda semántica
Así que todo comienza con la búsqueda semántica.
Pero, ¿qué es la búsqueda semántica?
La búsqueda semántica describe cómo Google tiene como objetivo no solo brindar resultados haciendo coincidir las palabras clave con la consulta de búsqueda, sino que ahora Google determina la intención y el significado de la consulta para brindar resultados completos diseñados para:
- Responda exactamente lo que el usuario está buscando
- Trae resultados que predicen la próxima pregunta del usuario incluso antes de que la haga.
Entonces, ¿cómo exactamente Google hace eso?
Bueno, para lograr esto, Google y otros motores de búsqueda a lo largo de los años han cambiado la forma en que clasifican la información.
En los viejos tiempos, Google hacía coincidir una consulta de búsqueda con una página web mediante el uso de factores dentro y fuera de la página. Esto significaba hacer coincidir la consulta con las palabras clave que aparecían en lugares destacados de su contenido. Ya sabes, etiquetas de título, H1, texto de anclaje, etiquetas alternativas y todas esas optimizaciones básicas de SEO que aprendiste.
Es importante tener en cuenta que para Google, la consulta de búsqueda y el contenido en esos días no eran más que cadenas de caracteres que resultaron en estrategias de SEO centradas en palabras clave.
Esto significa que Google identificó y clasificó el contenido al examinar las etiquetas de título, etc. Una vez que Google clasificó el contenido de esta manera, Google pudo generar resultados de búsqueda haciendo coincidir el contenido con las palabras clave encontradas en la consulta de búsqueda.
Pero en 2012, Google presentó Hummingbird, que supuso una revolución en la forma en que los motores de búsqueda clasifican la información. En otras palabras, Google se alejó de las cadenas y las reemplazó con cosas.
Esto significa que Google ahora está almacenando información sobre entidades (o cosas) del mundo real en una base de datos llamada Knowledge Graph. Google también tiene información sobre cómo estas entidades se relacionan entre sí y este cambio de paradigma en la categorización de la información ha dado forma dramática a las páginas de resultados.
Esto significa que una consulta de búsqueda ya no es una mera cadena de caracteres. Google ahora puede "entender" que la cadena se refiere a una entidad específica.
Ahora que tiene una descripción general básica, necesito explicar:
- Qué es el gráfico de conocimiento de Google
- Qué son las entidades de Google
- Cómo entiende Google las relaciones entre entidades
¿Qué es el gráfico de conocimiento de Google?
Knowledge Graph de Google es una base de datos de hechos sobre entidades (personas, lugares y cosas). Esta base de datos le permite a Google responder preguntas sobre cada entidad y mostrar estas respuestas y datos relacionados en los resultados de búsqueda.
Google recopila estos datos de varias fuentes diferentes, entre ellas:
- Fuentes públicas como Wikipedia y el World Factbook de la CIA
- Información autorizada, como resultados deportivos y previsiones meteorológicas
- Propietarios de contenido
Sin embargo, tener grandes cantidades de información no es útil a menos que esté categorizada y estructurada. (Explicaré cómo Google estructura esta información más adelante en esta publicación).
Esto permite que Google presente dos tipos de información sobre una entidad determinada en los resultados de búsqueda.
En primer lugar Google dará un resumen general del tema general. Esto podría ser una definición o un breve resumen de la vida de una persona famosa.
En segundo lugar, al comprender la relación entre las cosas, Google puede presentar información relacionada y consultas relacionadas sobre el tema. Esto permite al usuario explorar el tema por su cuenta.
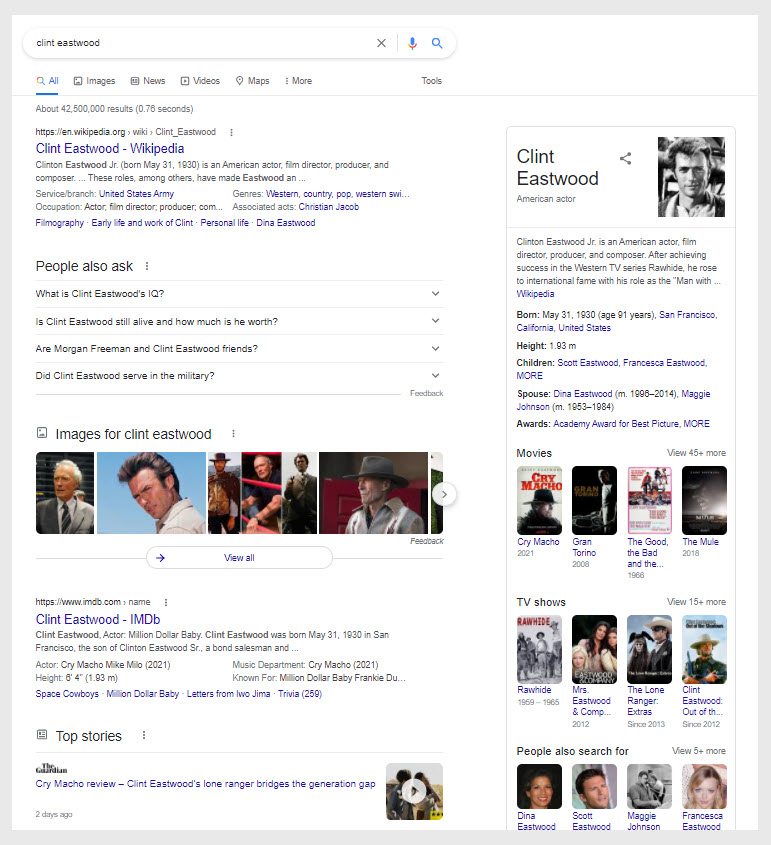
Por ejemplo, si observa la captura de pantalla anterior, verá un panel de conocimiento en el lado derecho de la pantalla. La parte superior del Panel de conocimiento define quién es Clint Eastwood al mismo tiempo que brinda información básica.
Si ha entendido la información básica y tiene un poco de curiosidad por explorar el tema más a fondo, el Panel de conocimientos presenta una lista de películas, el cuadro La gente también pregunta presenta las preguntas más frecuentes y la función Historias destacadas presenta noticias actuales.
Al agregar todas estas opciones, Google está solicitando al usuario que explore más información sobre la entidad.
Bien, hemos explorado un poco el Gráfico de conocimiento, ahora entendamos qué son las entidades.
¿Qué son las entidades de Google?
Google define las entidades como "una cosa o un concepto que es singular, único, bien definido y distinguible".
Aunque podríamos imaginar que una entidad se refiere a un objeto, según la definición de Google, una entidad también podría referirse a algo abstracto como un concepto. Pero, para definirse como una entidad, se representan lingüísticamente mediante sustantivos. Dicho de otra manera, una entidad es una cosa que se puede identificar, clasificar y categorizar.
Esto significa que incluso los colores, los sentimientos o las ideas pueden ser entidades.
Ahora, para 'comprender' verdaderamente estas entidades, Google tiene que darles contexto asignándoles atributos.
Por ejemplo, una consulta para 'manzana' es ambigua para Google. ¿Sobre qué entidad busca información el buscador? ¿Están buscando resultados sobre la fruta o Apple sobre la empresa?
Al categorizar una entidad como un tipo de fruta y otra como una marca que vende dispositivos, Google puede categorizar las manzanas de dos maneras diferentes y, por lo tanto, atender dos intenciones de búsqueda completamente diferentes con dos entidades diferentes.
Knowledge Graph de Google no solo asigna atributos a las entidades para definirlas como únicas. Google también utiliza estos atributos para "comprender" cómo se interconectan estas entidades. Las entidades con atributos similares se agrupan.
En otras palabras, las manzanas, las naranjas y las peras se agrupan como frutas.
Además de eso, Knowledge Graph de Google también agrupa entidades en temas y es capaz de comprender que los temas existen en una estructura jerárquica de temas y subtemas.
Google llama a esto la capa de tema.
La capa de temas le permite a Google agregar dinámicamente pestañas de subtemas a sus Paneles de conocimiento transformando la experiencia de búsqueda de una sola búsqueda en un viaje que potencialmente puede llevar a un buscador a través de un tema completo.
Entonces, por ejemplo, si tuviera que buscar el tema amplio 'el universo', podría estar buscando información general. Pero, una vez que obtenga lo que buscaba, es posible que desee explorar más el tema.
Google lo ayuda agregando subtemas al Panel de conocimiento.

Como puede ver en la captura de pantalla anterior, Google agrega pestañas desplegables expandibles para los subtemas:
- entropía
- Temperatura
- Largo
- Centro
Esto nos muestra que Google no solo puede agrupar entidades a través de atributos compartidos, sino que también comprende cómo existen en una jerarquía de temas y subtemas.
Si desea comprender esto más a fondo, consulte nuestro análisis de entidades de la capa de temas de Google.
Una vez que comprendamos qué son las entidades, echemos un vistazo más profundo a cómo los motores de búsqueda entienden sus relaciones. ¿Cuál es la anatomía de la información en el Knowledge Graph de Google?
Bueno, todo esto nos lleva a triples.
¿Qué es un triple?
Un triple se refiere a la relación entre dos entidades. Estas relaciones existen como información en el gráfico de conocimiento que se estructura utilizando una estructura sujeto-predicado-objeto.
En pocas palabras, el sujeto y el objeto son entidades. El predicado describe la relación entre estas dos entidades.
Entonces, por ejemplo, si tuviéramos que mirar la oración 'A Darrell le gusta la música'.
La oración se compone de:
- Un sujeto: Darrell
- Predicado: Me gusta
- Objeto: Música
Tanto el sujeto como el objeto en este ejemplo son entidades. La palabra 'me gusta' describiría la relación entre las entidades.

Llevando esto más lejos, el objeto en nuestra triple 'música' podría ser el sujeto en un triple diferente.
Entonces, la oración 'La música es una forma de arte' usa la entidad 'música' que apareció como objeto en la última oración 'A Darrell le gusta la música'. Sin embargo, esa entidad ahora es un sujeto en esta nueva oración.
Al interconectar entidades de esta manera, Google ha vinculado tres entidades. Al almacenar información de esta manera, Google vincula literalmente millones de entidades entre sí.
Al entender este concepto tienes una de las bases del SEO semántico.
¿Qué sucede cuando alguien busca en Google?
Así que hemos cubierto algunos conceptos básicos para comprender la búsqueda semántica. Ahora pongamos todo junto mirando lo que realmente sucede cuando alguien busca en Google.
Para entender esto, básicamente tenemos que entender cómo Google trata las consultas de búsqueda, ya que ese es el primer paso para que Google lleve los resultados a las páginas de resultados.
Comprender las consultas de búsqueda
Para que un motor de búsqueda brinde resultados completos que coincidan estrechamente con la intención del usuario y lo lleven a un viaje de descubrimiento, Google debe comprender qué está buscando el usuario cuando escribe una consulta en su navegador.
Para lograr esto, Google tiene que intentar comprender el significado subyacente de la consulta del buscador.
Esto no es tan fácil de lograr, sin embargo. Como personas, tendemos a encontrar muchas maneras de decir lo mismo, y formular una pregunta de diferentes maneras a menudo puede crear significados ligeramente diferentes.
Además, es importante entender que Google no puede entender el lenguaje de la misma manera que lo hace un ser humano. En otras palabras, Google no puede (todavía) comprender la intención del usuario a partir de la estructura de la oración y la lingüística.
Pero, Google puede mirar su base de datos de entidades y sus relaciones y básicamente descubrir qué está buscando un buscador.
Por ejemplo, escriba estas dos búsquedas diferentes en Google:
- quienes son los integrantes de los red hot chili peppers
- miembros de red hot chili peppers
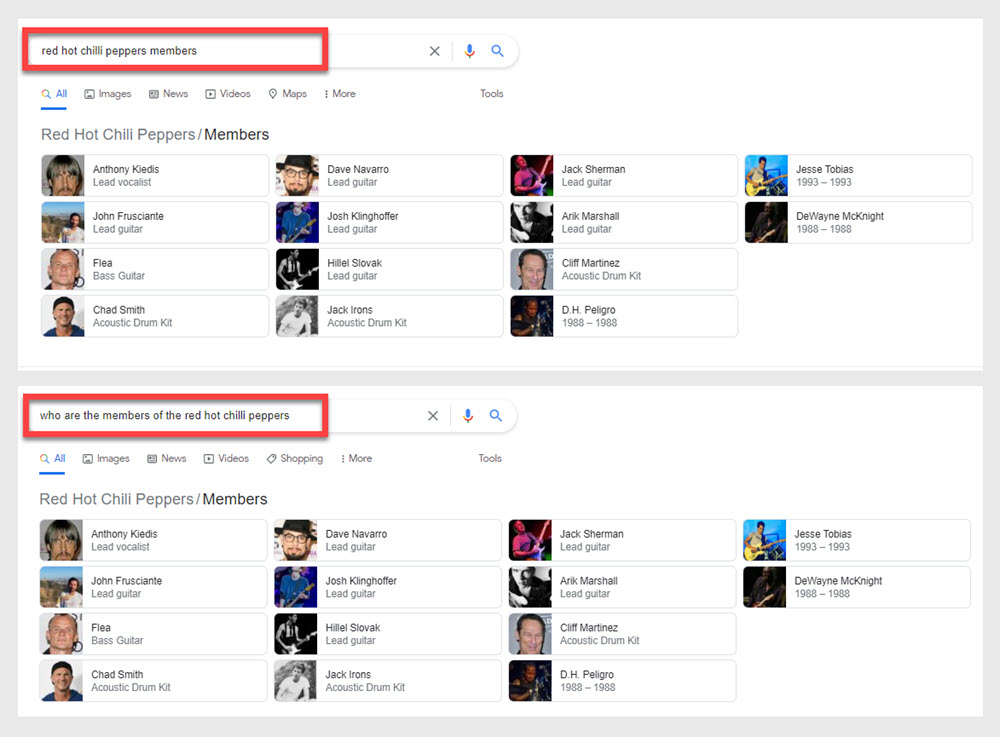
Si lo hizo, notará que ambas consultas generaron resultados similares, incluso si una consulta se formuló como una pregunta, mientras que la otra fue solo una pregunta implícita. La razón es que Google puede entender la entidad 'Red Hot Chilli Peppers'. Google también entiende que esta entidad tiene otras entidades asociadas.
La entidad Anthony Kiedis, por ejemplo, está estrechamente relacionada con la entidad Red Hot Chilli Peppers.
Además, esa relación se define como un 'miembro'.
Al tener esta relación en su base de datos, Google trata las dos consultas de la misma manera incluso si una consulta incluye las palabras 'quiénes son' mientras que la otra simplemente nombra a la entidad Red Hot Chilli Peppers y adjunta la palabra miembros.
El usuario está buscando estas entidades estrechamente relacionadas definidas como 'miembros'. Google puede entonces traer resultados basados en su 'comprensión' de la consulta.
Ahora, ¿qué sucede cuando Google no 'entiende' la consulta? ¿Qué sucede si la base de datos de Google no incluye las entidades sobre las que se realiza la consulta o si la base de datos no comprende la conexión entre las entidades?
En casos como este, Google se basa en algoritmos como Rank Brain para imitar la comprensión semántica.
Rank Brain hace esto mediante el uso de una base de datos de consultas similares y básicamente hace una conjetura.
Esto a veces puede resultar en múltiples intentos de búsqueda en un SERP.
=> Consulte nuestra guía sobre cómo realizar un análisis SERP para comprender la intención del usuario.
¿Por qué búsqueda semántica?
Como punto adicional, todo esto plantea la pregunta, ¿por qué?
Quiero decir que parece que Google ha inventado la biblioteca más sofisticada del mundo.
La respuesta es que, al comprender las entidades y sus relaciones, Google puede brindar una experiencia de usuario estelar. Según los datos de Google, puede presentar un tema de arriba hacia abajo. Esto significa que cuando un buscador busca un tema, Google puede proporcionar información que el buscador estaba buscando, así como predecir lo que el buscador quiere saber a continuación.
Para hacer esto, Google presentará intenciones de usuario estrechamente relacionadas en cualquier SERP dado. De esta forma, una vez que el usuario tiene lo que busca, pueden surgir nuevas preguntas en su mente. En otras palabras, la pregunta original se convierte en un viaje de descubrimiento, lo que resulta en muchas búsquedas.
Si desea ver esto en acción, consulte nuestra publicación de blog: Comprensión de la intención del usuario (Análisis de múltiples intenciones de usuario)
Búsqueda semántica en pocas palabras
Con suerte, ahora que ha visto esta publicación, está en una buena posición para profundizar en algunas estrategias de SEO semántico procesables. Aunque he intentado mantener el lenguaje simple para comprender realmente el tema, es una buena idea seguir leyendo. En otras palabras, trate esta publicación de blog como un trampolín para desarrollar aún más su conocimiento.
Afortunadamente, hay una gran cantidad de información en línea en la que puedes hincarle el diente, como el contenido creado por personas como Bill Slawski, Koray Tugberk GUBUR y Jason Barnard, quienes analizan diferentes aspectos del SEO semántico.
Ahora que comprende la búsqueda semántica, estoy seguro de que se pregunta cómo puede usarla para aumentar su clasificación y tráfico. El primer paso es comprender la diferencia entre palabras clave y temas.