
Originile EAT: conținutul paginii, analiza hyperlink și date de utilizare
Publicat: 2022-09-13Prezicerea viitorului pe baza cunoașterii trecutului este fundamentală. Sunt mereu cu ochii pe progresele tehnologice, dar nu pierd niciodată evidența trecutului.
Realizările și descoperirile anterioare în domeniul regăsirii informațiilor (IR) evocă posibilitățile de „unde urmează” în tehnologia de căutare.
Acest lucru mă duce apoi la impactul pe care îl va avea asupra tehnicilor și metodologiilor de optimizare a motoarelor de căutare (SEO) în viitor.
În versiunea anterioară a seriei mele SEO „Înapoi în viitor”, Tehnicile de indexare și de clasificare a cuvintelor cheie au fost revizuite: 20 de ani mai târziu, am încheiat arătând un grafic care explică ceva cunoscut sub numele de „problema abundenței”. Acest lucru împiedică frecvent tehnicile pure de clasificare a cuvintelor cheie (pe pagină) să plaseze paginile mai autorizate în partea de sus a rezultatelor. Relevant - da. Dar autoritar?
Pentru evaluatorii de calitate Google, este posibil ca EAT să fi existat doar de câțiva ani. Dar în domeniul IR, acesta a fost întotdeauna în centrul modului și a ceea ce fac motoarele de căutare.
În acest articol, voi explora cât de departe se află expertiza, autoritatea și încrederea (EAT) și pe ce se bazează de fapt.
„MANAT” acum 20 de ani
Există încă destul de multă ambiguitate în industrie cu privire la ceea ce înseamnă de fapt „autoritatea” în sensul SEO. Cum devine un site/pagină autorizat?
Poate că dacă priviți modul în care „autoritatea” – precum și termenii „expert” și „încredere” – au intrat în lexicul IR și SEO vă poate oferi mai multe informații.
Iată un grafic pe care l-am creat în 2002, dar această versiune are o îmbunătățire relevantă pentru a lega toate acestea.

Voi folosi această grafică clasică de extragere a datelor web, prezentând acum cele trei litere EAT pentru a ajuta la o mai bună înțelegere a originilor sale.
EAT în sine nu este un algoritm, ci:
- Expertiza se conectează direct la conținutul paginii .
- Autoritatea se conectează direct la analiza hyperlink .
- Încrederea provine dintr-o combinație de analiză a conținutului paginii și hyperlink, plus datele de acces ale utilizatorilor finali .
Toate cele trei aspecte ale extragerii de date trebuie să fie combinate într-o manieră de meta-căutare (sau căutare federată) pentru a oferi cele mai autorizate pagini pentru a satisface nevoile de informații ale utilizatorului final. Efectiv, este o serie de mecanisme de clasare algoritmice convergente care se consolidează reciproc.
În calitate de membru profesionist de lungă durată al Asociației pentru Mașini de Calcul, cea mai mare societate de calcul din lume, sunt mândru că aparțin grupului de interes special pentru regăsirea informațiilor (SIGIR). Principalul meu domeniu de interes în cadrul acelui grup este analiza hyperlink-urilor și știința ierarhizării motoarelor de căutare.
Pentru mine, aceasta este cea mai fascinantă zonă a IR și SEO. După cum am fost auzit să spun la multe conferințe de-a lungul anilor: „Nu toate legăturile sunt egale. Unii sunt infinit mai egali decât alții.”
Și acesta este un bun punct de plecare pentru următoarea lectură epică pentru colegii SEO Bravehearts.
Evoluția de la tehnici de clasare bazate pe text la algoritmi de clasare bazați pe hyperlink
Să acoperim rapid motivul fundamental pentru care linkurile sunt esențiale pentru toate motoarele de căutare, nu doar pentru Google.
În primul rând, analiza rețelelor sociale are o istorie deosebită. Ultimele două decenii s-au înregistrat în comunitatea științifică un interes și o fascinație în creștere uriașă pentru ideea rețelelor și a teoriei rețelelor. Ca o privire de ansamblu de bază, aceasta înseamnă pur și simplu un model de interconexiuni între un set de lucruri.
Rețelele sociale nu sunt un fenomen nou pentru companii precum Meta. Legăturile sociale dintre prieteni au fost studiate pe larg de mulți ani. Există rețele economice, rețele de producție, rețele media și multe alte rețele.
Un experiment în domeniu care a devenit foarte faimos în afara comunității științifice este cunoscut sub numele de „Șase grade de separare”, de care s-ar putea să știți.
Web-ul este o rețea de rețele. Și în 1998, structura hyperlink a web-ului a devenit de mare interes pentru un tânăr om de știință numit Jon Kleinberg (acum recunoscut drept unul dintre cei mai importanți informaticieni din lume) și pentru câțiva studenți de la Universitatea Stanford, inclusiv Google Larry Page și Sergey Brin . În acel an, cei trei au produs doi dintre cei mai influenți algoritmi de clasificare pentru analiza hyperlinkului – HITS (sau „Căutare de subiecte induse de hiperlinkuri”) și PageRank.
Pentru a fi clar, web-ul nu are preferințe față de un link sau altul. Un link este un link.
Dar pentru cei din industria SEO în curs de dezvoltare în 1998, această perspectivă s-ar schimba complet atunci când Page și Brin, într-o lucrare pe care au prezentat-o la o conferință din Australia, au făcut această declarație:
„În mod intuitiv, paginile care sunt bine citate din multe locuri de pe web merită văzute.”
Și apoi au dat un indiciu timpuriu, susținând faptul că am subliniat că „nu toate legăturile sunt egale”, continuând cu asta:
„De asemenea, paginile care au poate doar o citare de la ceva de genul paginii de pornire Yahoo merită, în general, să le vezi.”
Această ultimă afirmație mi-a lovit o coardă reală și, în calitate de practicant, m-a ținut concentrat pe dezvoltarea unei abordări mai elegante de a lega tehnicile și practicile de atracție de-a lungul anilor.
În încheierea acestei tranșe, voi explica ceva despre abordarea mea (care a avut un succes enorm) despre care cred că va schimba, din punct de vedere conceptual, modul în care vă gândiți la ceea ce se numește „link building” și îl va schimba în „ construirea reputației.”
Originile „autorității” în căutare
În comunitatea SEO, cuvântul „autoritate” este adesea folosit când vorbim despre Google. Dar nu de aici a provenit termenul (mai multe despre asta mai târziu).
În lucrarea pe care fondatorii Google au prezentat-o la conferința din Australia, este de remarcat faptul că, deși vorbeau despre un algoritm de analiză a hyperlink-urilor, ei nu au folosit cuvântul „link”, ci au folosit cuvântul „citare”. Acest lucru se datorează faptului că PageRank se bazează pe analiza citărilor.
Explicată vag, aceasta este analiza frecvenței, modelelor și graficelor citărilor din documente (alias, link-uri de la un document la altul). Un obiectiv tipic ar fi identificarea celor mai importante documente dintr-o colecție.
Cel mai timpuriu exemplu de analiză a citărilor a fost examinarea rețelelor de lucrări științifice pentru a descoperi sursele cele mai autorizate. Știința sa globală este cunoscută sub numele de „bibliometrie” – care se încadrează în categoria analizei rețelelor sociale și teoriei rețelelor, așa cum am atins deja.
Iată cum am transpus asta acum 20 de ani, în cel mai simplu mod absolut, pentru a arăta cum a văzut Google datele de conectare web.
„Unele link-uri de pe paginile web sunt pur și simplu ajutoare de navigare pentru a „naviga” un site. Alte link-uri pot oferi acces la alte pagini care sporesc conținutul paginii care le conține. Andrei Broder [Omul de știință șef Alta Vista] a subliniat că, un autor de pagină web este probabil să creeze un link de la o pagină la alta din cauza relevanței sau importanței sale: „Știți, ceea ce este foarte interesant la web este mediul de hyperlink care poartă o mulțime de informații. Vă spune: „Cred că această pagină este bună” – pentru că majoritatea oamenilor listează de obicei resurse bune. Foarte puțini oameni ar spune: „Acelea sunt cele mai proaste pagini pe care le-am văzut vreodată” și ar pune link-uri către ele pe propriile pagini!
Paginile de înaltă calitate cu informații bune, clare și concise au mai multe șanse să aibă multe link-uri care să trimită către ele. În timp ce paginile de calitate scăzută vor avea mai puține link-uri sau deloc. Analiza hyperlink poate îmbunătăți semnificativ relevanța rezultatelor căutării. Toate motoarele de căutare majore folosesc acum un anumit tip de algoritmi de analiză a linkurilor.”

„Folosind principiul citare/co-citare așa cum este utilizat în bibliometria convențională, algoritmii de analiză a hyperlinkurilor pot face una sau ambele dintre aceste ipoteze de bază:
• Un hyperlink de la pagina „a” la pagina „b” este o recomandare a paginii „b” de către autorul paginii „a”.
• Dacă pagina „a” și pagina „b” sunt conectate printr-un hyperlink, atunci acestea pot fi pe același subiect.
Algoritmii bazați pe hyperlink folosesc, de asemenea, un grafic de co-citare nedirecționată. A și B sunt conectate printr-o margine nedirecționată, dacă și numai dacă există o a treia pagină C care leagă atât la A, cât și la B.”
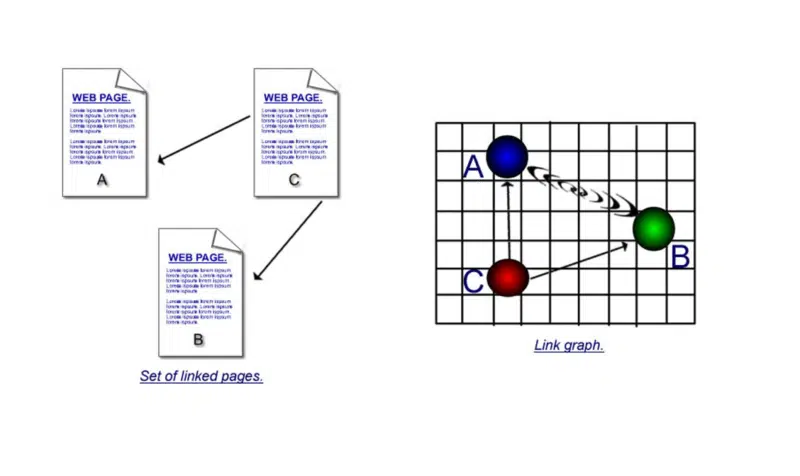
A doua parte a avut o explicație mult mai lungă în carte. Dar, deoarece este puțin confuz, voi da aici unul cu adevărat simplist.
Este important să înțelegeți punctele forte atât ale citării, cât și ale co-citării.
În prima ilustrație, există legături directe – o pagină care folosește un hyperlink pentru a se conecta la alta. Dar dacă pagina „c” se leagă la „a” și „b”, apoi pagina „d” se leagă la „a” și „b”, apoi pagina „e” și așa mai departe, ceea ce puteți presupune este că, deși pagina „a” și pagina „b” nu fac direct hyperlink între ele, deoarece sunt co-citate de atâtea ori, trebuie să existe o anumită legătură între ele.
Care ar fi un exemplu în viața reală în acest sens?
Ei bine, liste pentru început. Paginile cu cele mai bine vândute laptopuri din „top zece”, personalități sportive din „top zece” sau vedete rock, puteți vedea cum co-citarea este un factor important în aceste tipuri de pagini.
Deci, unde intră în joc acest algoritm HITS despre care poate nu ați auzit niciodată?
Există o poveste că, în același timp, Page și Brin lucrau la algoritmul lor PageRank, Kleinberg analiza rezultatele la principalele motoare de căutare ale zilei, inclusiv cea cu cea mai rapidă creștere dintre ele, Alta Vista. El s-a gândit că toate erau destul de sărace și au produs rezultate foarte slabe în ceea ce privește cât de relevante au fost pentru interogare.
El a căutat termenul „producător japonez de automobile” și a fost foarte neimpresionat să observe că niciunul dintre numele majore precum Toyota și Nissan nu a apărut nicăieri în rezultate, cu atât mai puțin unde ar trebui să fie în top.
După ce a vizitat site-urile marilor producători, a observat un lucru pe care toți aveau în comun: niciunul dintre ei nu avea cuvintele „producător japonez de automobile” în textul de pe paginile site-ului.
De fapt, el a căutat termenul „motor de căutare” și nici măcar Alta Vista nu a apărut în propriile rezultate din același motiv. Acest lucru l-a determinat să înceapă și să se concentreze asupra conectivității paginilor web pentru a oferi un indiciu despre cât de relevante (și importante) erau acestea pentru o anumită interogare.
Așadar, a dezvoltat algoritmul HITS, care a luat primele mii sau mai multe pagini în urma unei căutări de cuvinte cheie la Alta Vista și apoi le-a clasat în funcție de interconectivitate.
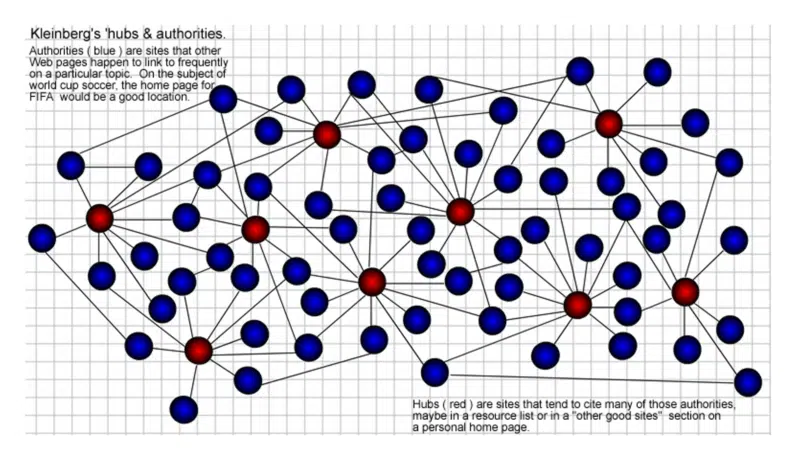
Efectiv, el folosea structura de legături pentru a forma o rețea sau „comunitate” în jurul subiectului de cuvinte cheie și, în cadrul acelei rețele, a identifica ceea ce a numit „centri și autorități”.
Acolo a intrat cuvântul „autoritate” în lexicul SEO. Titlul tezei lui Kleinberg a fost „Surse autorizate într-un mediu hiperlinkat”.
Paginile „hub” sunt cele cu multe link-uri care se conectează la „autorități” pe un anumit subiect. Cu cât sunt mai multe hub-uri care se conectează la o anumită autoritate, cu atât aceasta primește mai multă autoritate. Acest lucru se întărește reciproc. Un hub bun poate fi, de asemenea, o autoritate bună și invers.

Ca de obicei, nu există premii pentru abilitățile mele de creare grafică cu toți acești ani în urmă, dar așa am vizualizat-o în 2002. Hub-urile (roșu) sunt cele care fac legătura cu multe „autorități” (albastru) din comunitățile web.
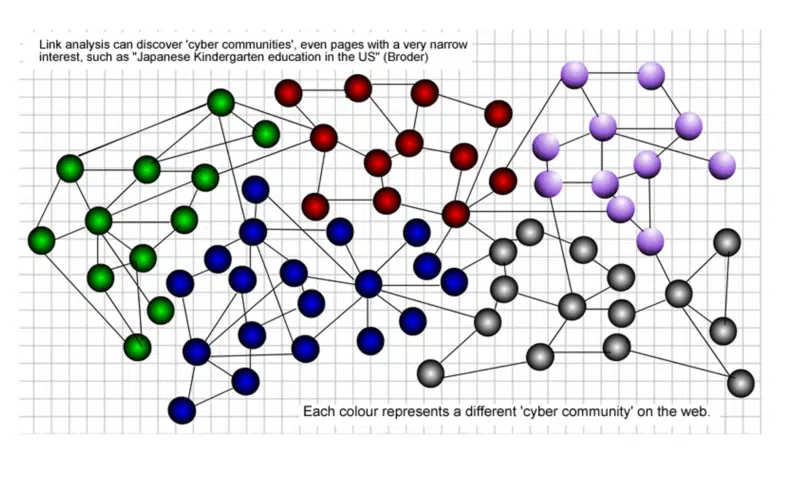
Deci, ce este o „comunitate web” atunci?
O comunitate de date de pagini web se referă la un set de pagini web care are propriile sale structuri logice și semantice.
Comunitatea paginilor web consideră fiecare pagină web ca un obiect întreg, mai degrabă decât defalcarea paginii web în bucăți de informații și dezvăluie relații reciproce între datele web în cauză.
Este flexibil în reflectarea naturii datelor web, cum ar fi dinamica și eterogenitatea. În graficul următor, fiecare culoare reprezintă o comunitate diferită de pe web.
Întotdeauna am susținut că linkurile atrase din propria comunitate web au mai mult prestigiu decât cele din afara comunității tale.
Am explicat mai multe despre importanța identificării comunităților în acest fel acum 20 de ani:
„Și în ceea ce privește datele legate de legături: paginile care indică (legături) către alte pagini pot furniza o cantitate masivă de informații despre structură, comunități și ierarhie (denumită în mare parte „topologia”) web. Folosind această metodologie, motoarele de căutare pot încerca să identifice structura intelectuală (topologia) și rețelele sociale (comunitățile) web. Cu toate acestea, există multe probleme legate de scalarea utilizării metodelor de analiză a citării și co-citării pentru a trata sute și sute de milioane de documente cu miliarde de citări (hyperlink-uri).
„Cyberspace” (ca și în web) are deja comunitățile și cartierele sale. OK – mai puțin real în sensul unde locuiești și cu cine stai. Dar există o „sociologie” pentru web. Iubitorii de muzică din diverse culturi și medii (și fusuri orare) diferite nu locuiesc în același cartier geografic – dar atunci când sunt legați unul de celălalt pe web, sunt o comunitate foarte mare. La fel ca iubitorii de artă și oamenii din toate categoriile sociale care își postează informațiile pe web și formează aceste comunități sau „conectează cartiere” în „spațiul cibernetic”.
Obțineți buletinele informative zilnice pe care se bazează marketerii.
Vezi termenii.
PageRank vs. HITS: Care este diferența?
Există multe asemănări în ambele algoritmi PageRank și HITS în modul în care analizează interconectivitatea paginilor web pentru a crea un mecanism de clasare.
Dar există și o diferență semnificativă.
PageRank este un algoritm de clasare independent de cuvinte cheie, în timp ce HITS este dependent de cuvinte cheie.
Cu PageRank, obțineți scorul de autoritate indiferent de comunitate, deoarece inițial era un scor global static.
În timp ce HITS depinde de cuvinte cheie, ceea ce înseamnă că scorul de autoritate este construit în jurul cuvântului cheie/expresiei care reunește comunitatea. Este nevoie de prea mult timp și dincolo de scopul acestei tranșe pentru a intra în detalii, așa că nu voi intra prea adânc aici.
Algoritmul care a introdus termenul „expert”
Acest algoritm Hilltop este extrem de important, dar primește cea mai mică atenție. Și asta pentru că, în cercurile profesionale, există o credință puternică că a fost fuzionat în procesele algoritmice ale Google în 2003, când a avut loc infama actualizare din Florida.
Un adevărat schimbător de joc, algoritmul Hilltop este un derivat mult mai apropiat al HITS și a fost dezvoltat în 1999 (da, cam în același timp) de Krishna Bharat.
La acea vreme, el lucra pentru DEC Systems Research Center, care era proprietarul motorului de căutare AltaVista. Lucrarea sa de cercetare a fost intitulată „Când experții sunt de acord: utilizarea experților neafiliați pentru a clasifica subiectele populare”. Și așa a descris Hilltop.
„Propunem o nouă schemă de clasare pentru subiectele populare, care plasează cele mai autorizate pagini cu privire la subiectul de interogare în fruntea clasamentului. Algoritmul nostru operează pe un index special de „documente de experți”. Acestea sunt un subset al paginilor de pe WWW identificate ca directoare de link-uri către surse neafiliate pe anumite subiecte. Rezultatele sunt clasificate în funcție de potrivirea dintre interogare și textul descriptiv relevant pentru hyperlinkurile de pe paginile de experți care indică o anumită pagină de rezultate."
Da, aici a intrat termenul „expert” în lexicul SEO. Observați atât în titlul lucrării, cât și în descrierea procesului, pagina dvs. este considerată a fi o pagină de expert atunci când alții link la ea. Deci, termenii „expert” și „autoritate” pot fi folosiți interschimbabil.
Un alt lucru care ar trebui notat cu atenție – și acesta este utilizarea termenului „neafiliat” în descrierea algoritmului. Acest lucru poate oferi un indiciu de ce mulți agenți de marketing afiliați au fost loviți atât de rău de actualizarea Florida.
Un alt lucru important de remarcat este faptul că, în mod frecvent, în comunitatea SEO, oamenii se referă la „site-uri de autoritate” (sau uneori la „autoritate de domeniu”, ceea ce nici măcar nu este un lucru). Dar adevărul este că motoarele de căutare returnează pagini web în rezultatele lor în urma unei interogări, nu site-uri web.
Cu cât atrageți mai multe link-uri din alte pagini de „expert”, cu atât câștigați mai multă autoritate și cu atât mai mult „prestigiu” puteți adăuga la o altă pagină de experți prin link-ul către aceasta. Aceasta este frumusețea construirii unei „reputații” în cadrul comunității – nu a fi pur și simplu un colector de linkuri.
Ori de câte ori explic importanța de a fi recunoscut ca expert în cadrul unei comunități web, așa cum am făcut-o în ultimele două decenii, știu că uneori oamenii au dificultăți să vizualizeze cum ar arăta.
Din fericire, în munca mea de cercetare în urmă cu toți acești ani, am dat peste un alt algoritm dezvoltat de doi oameni de știință japonezi, Masashi Toyoda și Kentarou Fukuchi. Abordarea lor a fost și comunitatea web, dar au reușit să își prezinte rezultatele vizual.
Exemplul pe care l-am luat al lor a fost unul pe care l-au folosit atunci când au creat o comunitate web în jurul producătorilor de computere. Iată o mică parte din rezultatul pe care l-am ridicat pentru a-l folosi la sesiunile de conferință pentru a ajuta toată lumea să își facă o idee mai tangibilă a noțiunii.
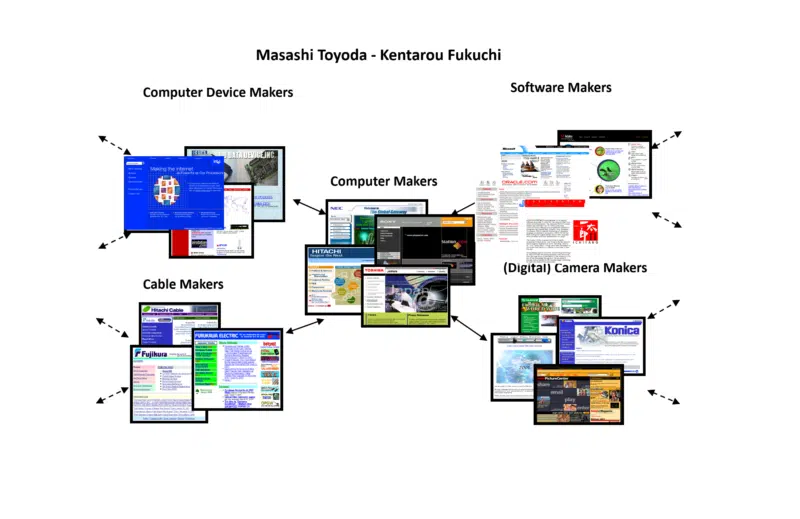
Observați cum comunitatea web include nu doar producători de computere, ci și producători de dispozitive, producători de cabluri, producători de software etc. Acest lucru indică cât de largă și de adâncă poate fi o comunitate web (precum îngustă și superficială).
Cum a apărut „încrederea”.
Există multe lucruri care se referă la „expertiză” și „autoritate”, și nu mai puțin care intră în „încredere”.
Chiar și „încrederea” se încadrează în zona analizei hyperlink și a structurii web-ului. S-a depus multă muncă în utilizarea conținutului și a conectivității „paginilor de experți” care sunt de încredere pentru a descoperi și a elimina spamul. Cu tehnicile AI și ML, aceste modele de conectivitate sunt mult mai ușor de identificat și eliminat.
Pe vremuri exista un algoritm dezvoltat cunoscut sub numele de „TrustRank” și pe asta se baza. Desigur, testul acid pentru „încredere” are loc cu adevărat cu utilizatorul final.
Motoarele de căutare se străduiesc să elimine spam-ul și să ofere rezultate care satisfac cu adevărat nevoile de informații ale utilizatorilor. Deci, modelele de acces ale utilizatorilor la pagini oferă o cantitate imensă de date pe care paginile trec testul comunității web (conectivitate) și apoi cele care trec testul utilizatorului final (date de acces utilizator).
După cum am menționat, linkurile din alte pagini web către paginile dvs. pot fi văzute ca un „vot” pentru conținutul dvs. Dar cum rămâne cu milioanele și milioanele de utilizatori finali care nu au pagini web pentru a vă oferi un link – cum pot vota?
O fac cu „încrederea” lor făcând clic pe anumite rezultate – sau nu făcând clic pe altele.
Totul este dacă utilizatorii finali vă consumă conținutul – pentru că, dacă nu sunt, ce rost are Google să îl returneze în rezultate în urma unei interogări?
Ce înseamnă „expert”, „autoritate” și „încredere” în căutare
Pentru a rezuma, nu ajungi să te declari expert pe propriile tale pagini.
Puteți „pretinde” că sunteți un expert sau o autoritate într-un anumit domeniu sau liderul lumii cu asta sau cutare.
Dar din punct de vedere filozofic, Google și alte motoare de căutare spun: „Cine altcineva crede așa?”
Nu este ceea ce spui despre tine. Este ceea ce spun alții despre tine (link anchor text). Așa îți construiești o „reputație” în comunitatea ta.
Mai mult, evaluatorii de calitate de la Google nu determină ei înșiși dacă conținutul tău este „expert” sau dacă ești o „autoritate” sau nu. Sarcina lor este să examineze și să determine dacă algoritmii Google își fac treaba.
Acesta este un subiect atât de fascinant și mai sunt multe de acoperit. Dar nu avem timp și spațiu pentru moment.
Data viitoare, voi explica cât de importante sunt datele structurate și să fii conectat „semantic” în cadrul comunității tale web.
Până atunci, bucurați-vă de culorile aurii ale toamnei în timp ce alunecăm într-un alt sezon cu mare așteptare pentru următoarea lectură epică despre funcționarea interioară a motoarelor de căutare.
Opiniile exprimate în acest articol sunt cele ale autorului invitat și nu neapărat Search Engine Land. Autorii personalului sunt enumerați aici.