
EAT の起源: ページ コンテンツ、ハイパーリンク分析、使用データ
公開: 2022-09-13過去の知識に基づいて未来を予測することは基本です。 私は常に技術の進歩に目を光らせていますが、過去を決して忘れません。
情報検索(IR)分野におけるこれまでの実績とブレークスルーは、検索技術の「次はどこへ」の可能性を想起させます。
それは、将来の検索エンジン最適化 (SEO) の手法と方法論にどのような影響を与えるかということです。
私の SEO「バック トゥ ザ フューチャー」シリーズの前回の記事では、インデックス作成とキーワード ランキングの手法を再検討しました。20 年後、私は「豊富な問題」として知られるものを説明する図を示して締めくくりました。 これにより、純粋なキーワード ランキング手法 (ページ上) では、より権威のあるページを結果の上部に配置できなくなることがよくあります。 関連 – はい。 しかし権威?
Google の品質評価者にとって、EAT はほんの数年しか存在しなかったかもしれません。 しかし、IR の分野では、検索エンジンがどのように、また何を行うかの中核を常に占めてきました。
この記事では、専門知識、信頼性、および信頼性 (EAT) がどこまでさかのぼり、実際に何に基づいているかを探ります。
「食べる」 20年前
SEO の意味での「権威性」が実際に何を意味するのかについて、業界にはまだかなり曖昧な点があります。 サイト/ページはどのようにして信頼できるようになりますか?
おそらく、「権威」、および「専門家」や「信頼」という用語がどのように IR と SEO の用語集に登場したかを見ると、より多くの洞察が得られるでしょう。
これは私が 2002 年に作成したグラフィックですが、このバージョンには、これらすべてを結び付ける関連する拡張機能があります。

ここでは、この古典的な Web データ マイニング グラフィックを使用します。現在は EAT の 3 文字を特徴としており、その起源をよりよく理解するのに役立ちます。
EAT 自体はアルゴリズムではありませんが、
- 専門知識は、ページ コンテンツに直接つながります。
- 権限は、ハイパーリンク分析に直接接続します。
- 信頼は、ページ コンテンツとハイパーリンク分析、およびエンドユーザー アクセス データの組み合わせから生まれます。
エンド ユーザーの情報ニーズを満たす最も信頼できるページを提供するには、データ マイニングの 3 つの側面すべてをメタ検索 (または連合検索) 方式で組み合わせる必要があります。 事実上、これは相互に補強し合う一連の収束アルゴリズム ランキング メカニズムです。
世界最大のコンピューティング ソサイエティである Association for Computing Machinery の長年の専門メンバーとして、情報検索の特別利益団体 (SIGIR) に所属していることを誇りに思います。 そのグループ内で私の主な焦点は、ハイパーリンク分析と検索エンジン ランキングの科学です。
私にとって、これは IR と SEO の最も魅力的な分野です。 何年にもわたって多くの会議で私が言っているのを聞いてきました。 あるものは他のものより無限に平等です。」
これは、仲間の SEO Bravehearts にとって、次の壮大な記事の良い出発点です。
テキストベースのランキング手法からハイパーリンクベースのランキングアルゴリズムへの進化
Google だけでなく、すべての検索エンジンにとってリンクが不可欠であるという基本的な理由を簡単に説明しましょう。
まず、ソーシャル ネットワーク分析には顕著な歴史があります。 過去 20 年間、ネットワークとネットワーク理論の概念に対する科学界の関心と魅力が大きく発展してきました。 基本的な概要として、これは単純に一連のものの間の相互接続のパターンを意味します。
ソーシャル ネットワークは、Meta のような企業による新しい現象ではありません。 友人間の社会的絆は、長年にわたって広く研究されてきました。 経済ネットワーク、製造ネットワーク、メディア ネットワーク、その他多くのネットワークが存在します。
科学界の外で非常に有名になったこの分野での 1 つの実験は、「6 つの分離度」として知られています。
ウェブはネットワークのネットワークです。 そして 1998 年、ウェブのハイパーリンク構造は、ジョン・クラインバーグという若い科学者 (現在は世界をリードするコンピューター科学者の 1 人として認められている) と、Google のラリー ペイジやセルゲイ ブリンを含むスタンフォード大学の数人の学生にとって大きな関心を持つようになりました。 . その年、3 人は最も影響力のあるハイパーリンク分析ランキング アルゴリズムの 2 つ、HITS (または「ハイパーリンク誘導トピック検索」) と PageRank を作成しました。
明確にするために言うと、ウェブにはリンクが優先されるわけではありません。 リンクはリンクです。
しかし、1998 年の初期の SEO 業界の人々にとって、その見方は完全に変わりました。Page と Brin が、オーストラリアでの会議で発表した論文の中で次のような声明を出したときです。
「直感的に、ウェブ上の多くの場所からよく引用されているページは一見の価値があります。」
そして、彼らは、私が強調した「すべてのリンクが等しいわけではない」という事実を支持する初期の手がかりを、次のようにフォローアップして与えました。
「また、Yahoo のホームページなどからおそらく 1 つしか引用されていないページも、一般的に見る価値があります。」
この最後の言葉は、私にとって非常に心に響く言葉であり、施術者として、長年にわたってアトラクションのテクニックと実践を結び付けるためのより洗練されたアプローチを開発することに集中してきました.
この記事の最後に、「リンク ビルディング」と呼ばれるものについての考え方を概念的に変え、それを「評判の構築。」
検索における「権威」の起源
SEO コミュニティでは、Google について話すときに「権限」という言葉がよく使われます。 しかし、それはこの用語が生まれた場所ではありません (これについては後で詳しく説明します)。
オーストラリアで開催された会議で Google の創設者が発表した論文では、彼らがハイパーリンク分析アルゴリズムについて話していたにもかかわらず、「リンク」という言葉を使用せず、「引用」という言葉を使用していたことは注目に値します。 これは、PageRank が引用分析に基づいているためです。
大雑把に説明すると、これはドキュメント内の引用の頻度、パターン、およびグラフ (つまり、あるドキュメントから別のドキュメントへのリンク) の分析です。 典型的な目的は、コレクション内の最も重要なドキュメントを特定することです。
引用分析の最も初期の例は、最も信頼できる情報源を発見するための科学論文のネットワークの調査でした。 その包括的な科学は「ビブリオメトリクス」として知られています。これは、既に触れたように、ソーシャル ネットワーク分析とネットワーク理論のカテゴリに当てはまります。
これは、Google が Web リンケージ データをどのように見ていたかを示すために、20 年前にそれを最も簡単な方法で置き換えた方法です。
「ウェブページのリンクの中には、サイトを「ブラウズ」するためのナビゲーション補助に過ぎないものがあります。 他のリンクは、それらを含むページのコンテンツを補強する他のページへのアクセスを提供する場合があります。 Andrei Broder [Alta Vista チーフ サイエンティスト] は、ウェブ ページの作成者は、その関連性または重要性のために、あるページから別のページへのリンクを作成する可能性が高いと指摘しました。多くの情報。 「このページは良いと思います」というメッセージが表示されます。これは、ほとんどの人が通常、優れたリソースをリストしているためです。 「これまで見た中で最悪のページだ」と言って、自分のページにリンクを貼っている人はほとんどいません。
良質で明確かつ簡潔な情報を含む高品質のページには、そのページへのリンクが多く含まれる可能性が高くなります。 一方、品質の低いページにはリンクが少ないか、まったくありません。 ハイパーリンク分析により、検索結果の関連性が大幅に向上します。 現在、主要な検索エンジンはすべて、ある種のリンク分析アルゴリズムを採用しています。」

「従来の計量文献学で使用されている引用/共引用の原則を使用して、ハイパーリンク分析アルゴリズムは、これらの基本的な仮定のいずれかまたは両方を作成できます。
• ページ「a」からページ「b」へのハイパーリンクは、ページ「a」の作成者によるページ「b」の推奨です。
• ページ 'a' とページ 'b' がハイパーリンクで接続されている場合、それらは同じトピックに関するものである可能性があります。
ハイパーリンク ベースのアルゴリズムも、無向共引用グラフを使用します。 A と B は、A と B の両方にリンクする 3 番目のページ C が存在する場合にのみ、無向エッジで接続されます。」
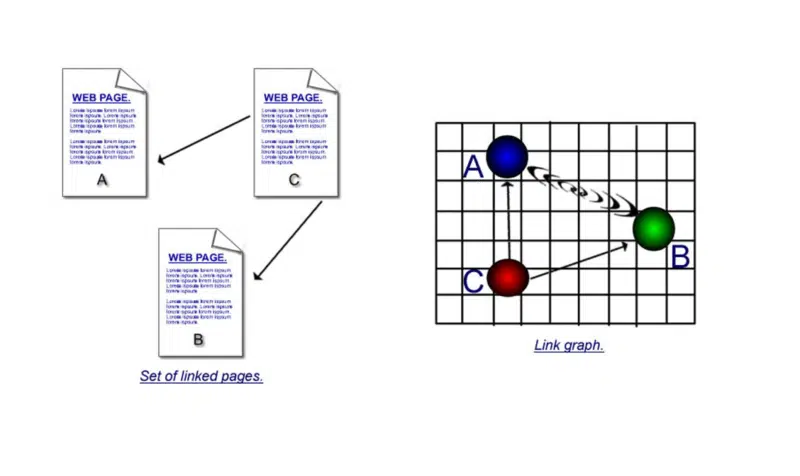
その 2 番目の部分には、本の中でより長い説明がありました。 しかし、少しややこしいので、ここでは非常に単純化したものを示します。
引用と共引用の両方の長所を理解することが重要です。
最初の図には、直接リンクがあります。あるページはハイパーリンクを使用して別のページに接続しています。 しかし、ページ 'c' が 'a' と 'b' にリンクし、次にページ 'd' が 'a' と 'b' にリンクし、次にページ 'e' などにリンクしている場合、次のように仮定できます。ページ「a」とページ「b」は相互に直接ハイパーリンクしていませんが、何度も共引用されているため、それらの間に何らかの関連があるはずです。
その実際の例は何でしょうか?
さて、まずはリストです。 「トップ 10」のベストセラー ラップトップ、「トップ 10」のスポーツ パーソナリティ、またはロック スターのページでは、これらのタイプのページで共引用がいかに大きな要因であるかがわかります。
では、聞いたことがないかもしれないこの HITS アルゴリズムはどこで機能するのでしょうか?
ペイジとブリンが PageRank アルゴリズムに取り組んでいたのと同時に、クラインバーグはその日のトップ検索エンジンの結果を分析していたという話があります。 彼は、それらはすべて非常に貧弱であり、クエリとの関連性に関して非常に貧弱な結果しか得られなかったと考えていました。
彼は「日本の自動車メーカー」という用語を検索しましたが、トヨタや日産などの主要な名前が検索結果のどこにも表示されず、ましてや上位に表示されないことに非常に感銘を受けませんでした。
主要なメーカーのウェブサイトを訪れた後、彼は共通点が 1 つあることに気付きました。それは、サイトのページのテキストに「日本の自動車メーカー」という単語が含まれていないことです。
実際、彼は「検索エンジン」という用語を検索しましたが、Alta Vista でさえ、まったく同じ理由で、独自の検索結果に表示されませんでした。 これにより、彼は Web ページの接続性に注目し、特定のクエリとの関連性 (および重要性) に関する手がかりを得ることができました。
そこで彼は HITS アルゴリズムを開発しました。このアルゴリズムは、Alta Vista でキーワード検索を行った後、上位 1,000 ページ以上を取得し、それらの相互接続性に従ってランク付けしました。
事実上、彼はリンク構造を使用して、キーワード トピックの周りにネットワークまたは「コミュニティ」を形成し、そのネットワーク内で、彼が「ハブと権威」と名付けたものを特定していました。
そこで、「権威」という言葉が SEO 用語集に登場しました。 クラインバーグの論文のタイトルは、「ハイパーリンク環境における信頼できる情報源」でした。
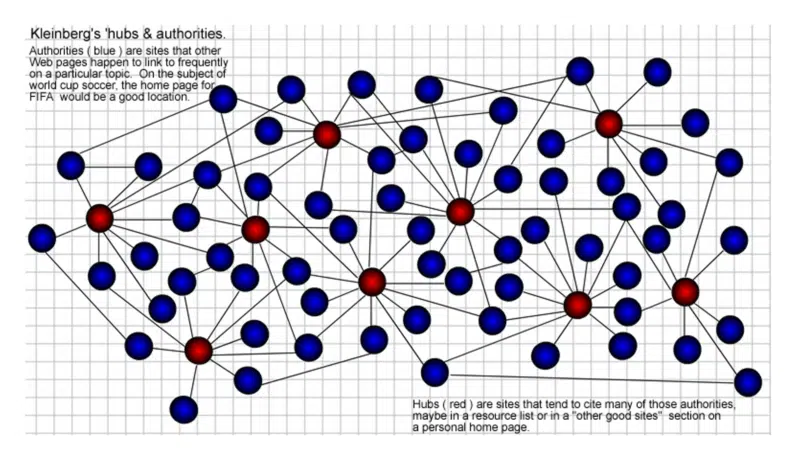
「ハブ」ページは、特定のトピックに関する「権威」につながるリンクが多数あるページです。 特定の機関にリンクするハブが多いほど、より多くの機関が取得します。 これも相互補強です。 良いハブは良いオーソリティにもなり得ますし、その逆も成り立ちます。
いつものように、何年も前の私のグラフィック作成スキルに対する賞はありませんでしたが、これは 2002 年にそれを視覚化した方法です。ハブ (赤) は、Web コミュニティ内の多くの「権限」 (青) にリンクするものです。
では、「Web コミュニティ」とは何でしょうか。
Web ページ データ コミュニティは、独自の論理構造と意味構造を持つ一連の Web ページを指します。

Web ページ コミュニティは、Web ページを情報に分割するのではなく、各 Web ページを全体オブジェクトと見なし、関連する Web データ間の相互関係を明らかにします。
ダイナミクスや異質性など、Web データの性質を柔軟に反映できます。 次の図では、各色が Web 上のさまざまなコミュニティを表しています。
私は常に、自分の Web コミュニティ内から集められたリンクは、コミュニティ外からのリンクよりも威信が高いと主張してきました。
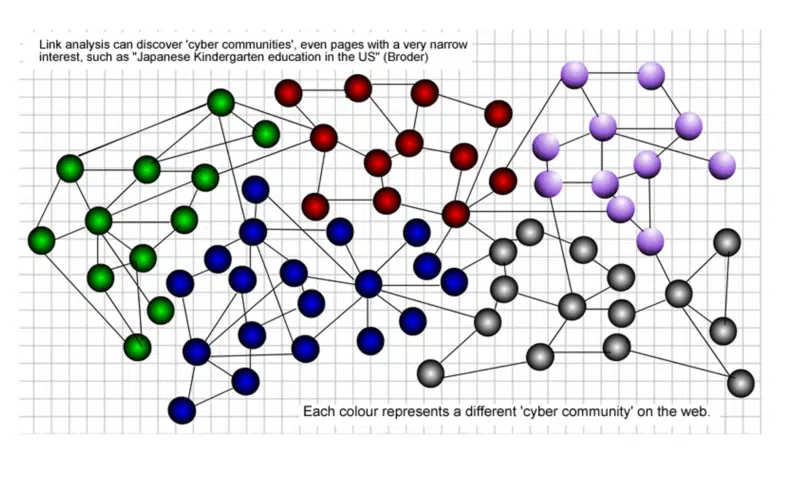
この方法でコミュニティを識別することの重要性について、私は 20 年前に詳しく説明しました。
「リンク データについては、他のページを指す (リンクする) ページは、構造、コミュニティ、および階層 (主に Web の「トポロジ」と呼ばれる) に関する膨大な量の情報を提供できます。 この方法論を使用することにより、検索エンジンは、Web の知的構造 (トポロジー) とソーシャル ネットワーク (コミュニティ) を識別しようとすることができます。 ただし、引用および共引用分析の方法を使用して、数十億の引用 (ハイパーリンク) を含む何億ものドキュメントを処理するスケーリングには、多くの問題があります。
「サイバースペース」(ウェブの場合)には、すでにコミュニティと近隣地域があります。 OK – どこに住んでいて、誰と一緒にいるかという意味では現実味がありません。 しかし、ウェブには「社会学」があります。 さまざまな文化やさまざまな背景 (およびタイム ゾーン) の音楽愛好家は、地理的に同じ地域に住んでいるわけではありません。 芸術愛好家やあらゆる分野の人々がウェブに情報を投稿し、これらのコミュニティを形成したり、「サイバースペース」で「近所をリンクしたりする」のと同じです。」
検索マーケティング担当者が頼りにしている毎日のニュースレターを入手してください。
条件を参照してください。
PageRank と HITS: 違いは何ですか?
PageRank アルゴリズムと HITS アルゴリズムには、Web ページの相互接続性を分析してランキング メカニズムを作成する方法に多くの類似点があります。
しかし、大きな違いもあります。
PageRank はキーワードに依存しないランキング アルゴリズムですが、HITS はキーワードに依存します。
PageRank を使用すると、元は静的なグローバル スコアであるため、コミュニティに関係なくオーソリティ スコアを取得できます。
HITS はキーワードに依存しますが、オーソリティ スコアは、コミュニティをまとめるキーワード/フレーズを中心に構築されます。 詳しく説明するには時間がかかりすぎて、今回の記事の範囲を超えているため、ここでは深くは触れません。
「エキスパート」という用語を導入したアルゴリズム
このヒルトップ アルゴリズムは非常に重要ですが、あまり注目されていません。 それは、専門家の間では、2003 年に悪名高いフロリダ アップデートが発生したときに、Google のアルゴリズム プロセスに統合されたという強い信念があるからです。
真のゲームチェンジャーであるヒルトップ アルゴリズムは、HITS の派生物であり、クリシュナ バーラトによって 1999 年に (そうです、まったく同じ時期に) 開発されました。
当時、彼は AltaVista 検索エンジンの所有者である DEC Systems Research Center に勤務していました。 彼の研究論文のタイトルは、「専門家が同意する場合: 所属していない専門家を使用して人気のあるトピックをランク付けする」です。 そして、これが彼がヒルトップを説明した方法です。
「私たちは、クエリトピックで最も信頼できるページをランキングの上位に配置する、人気のあるトピックの新しいランキング方式を提案します。私たちのアルゴリズムは、「専門家のドキュメント」の特別なインデックスで動作します。これらは、WWW 上のページのサブセットです。特定のトピックに関する非関連ソースへのリンクのディレクトリとして識別されます. 結果は、特定の結果ページを指す専門家ページのハイパーリンクのクエリと関連する説明テキストとの一致に基づいてランク付けされます."
はい、ここで「専門家」という用語が SEO 用語集に登場しました。 論文のタイトルとプロセスの説明の両方に注目してください。あなたのページは、他の人がリンクしたときにエキスパート ページと見なされます。 したがって、「専門家」と「権威」という用語は同じ意味で使用できます。
注意すべきもう 1 つの点は、アルゴリズムの説明で「非関連」という用語が使用されていることです。 これは、なぜ多くのアフィリエイト マーケターがフロリダの更新でひどく打撃を受けたのかについての手がかりを与えるかもしれません.
注意すべきもう 1 つの重要な点は、SEO コミュニティでは、人々が頻繁に「オーソリティ サイト」(または時には「ドメイン オーソリティ」でさえない) を参照することです。 しかし、実際には、検索エンジンは、Web サイトではなく、クエリの結果として Web ページを返します。
他の「専門家」ページから多くのリンクを集めるほど、より多くの権限を獲得し、リンクすることで別の専門家ページに追加できる「名声」が高まります。 これは、単にリンク コレクターになるだけでなく、コミュニティ内で「評判」を築くことの利点です。
私が過去 20 年間そうしてきたように、ウェブ コミュニティ内で専門家として認められることの重要性を説明するときはいつでも、人々がそれがどのように見えるかを想像するのが難しい場合があることを知っています。
幸運なことに、何年も前の私の研究で、2 人の日本人科学者、豊田正志と福地健太郎によって開発された別のアルゴリズムに出会いました。 彼らのアプローチも Web コミュニティでしたが、結果を視覚的にアウトプットすることができました。
私が取り上げた彼らの例は、彼らがコンピュータ メーカーを中心に Web コミュニティを構築したときに使用したものです。 これは、会議セッションで使用するために私が持ち上げた出力のごく一部であり、誰もが概念のより具体的なアイデアを得るのに役立ちます.
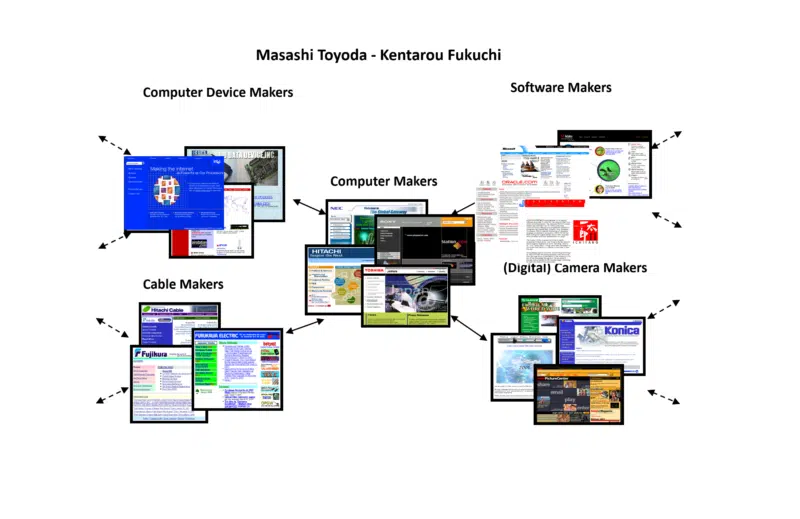
Web コミュニティには、コンピュータ メーカーだけでなく、デバイス メーカー、ケーブル メーカー、ソフトウェア メーカーなどが含まれていることに注意してください。これは、Web コミュニティがどれほど広くて深いか (狭くて浅いか) を示しています。
「信頼」はどのようにして生まれたのか
「専門性」と「権威性」には多くの要素があり、それは「信頼」にも当てはまります。
「信頼」でさえ、ハイパーリンク分析と Web の構造の領域に分類されます。 スパムを発見して除去する信頼できる「エキスパート ページ」のコンテンツと接続性を使用するために、多くの作業が行われました。 AI と ML の手法を使用すると、これらの接続パターンを見つけて排除するのがはるかに簡単になります。
昔、「TrustRank」として知られるアルゴリズムが開発され、それが基になっていました。 もちろん、「信頼」の酸テストは実際にエンド ユーザーに対して行われます。
検索エンジンは、スパムを排除し、ユーザーの情報ニーズを真に満たす結果を提供するよう努めています。 そのため、ページへのユーザー アクセス パターンは、Web コミュニティ テスト (接続性) に合格したページと、エンド ユーザー テストに合格したページ (ユーザー アクセス データ) に関する膨大な量のデータを提供します。
前述したように、他の Web ページからあなたのページへのリンクは、あなたのコンテンツに対する "投票" と見なすことができます。 しかし、リンクを提供するための Web ページを持っていない何百万ものエンド ユーザーはどうでしょうか。彼らはどうやって投票できるのでしょうか?
彼らは、特定の結果をクリックするか、他の結果をクリックしないことで、「信頼」を持ってそれを行います。
エンド ユーザーがあなたのコンテンツを消費しているかどうかがすべてです。もし消費していなければ、Google がクエリに続く結果でそれを返すことに何の意味があるのでしょうか?
検索における「専門家」、「権威」、「信頼」の意味
要約すると、自分のページで自分が専門家であると宣言することはできません。
あなたは、特定の分野の専門家または権威である、または世界をリードするこれまたはあれであると「主張」することができます。
しかし哲学的には、Google や他の検索エンジンはこう言っています。
それはあなたがあなた自身について言うことではありません。 それは、他の人があなたについて言っていることです (リンク アンカー テキスト)。 それがあなたのコミュニティで「評判」を築く方法です。
さらに、Google の品質評価者は、あなたのコンテンツが「専門家」であるか、または「権威」であるかを判断していません。 彼らの仕事は、Google のアルゴリズムが機能しているかどうかを調べて判断することです。
これは非常に魅力的なテーマであり、カバーすべきことは他にもたくさんあります。 しかし、今のところ時間とスペースがありません。
次回は、構造化データがいかに重要であり、Web コミュニティ内で「意味的に」接続されることがいかに重要であるかを説明します。
それまでは、秋の黄金色を楽しみながら、検索エンジンの内部動作に関する次の叙事詩を大いに期待して、別の季節に滑り込みましょう。
この記事で表明された意見はゲスト著者のものであり、必ずしも Search Engine Land ではありません。 スタッフの著者はここにリストされています。