
As origens do EAT: conteúdo da página, análise de hiperlink e dados de uso
Publicados: 2022-09-13Prever o futuro com base no conhecimento do passado é fundamental. Estou sempre atento aos avanços tecnológicos, mas nunca perco a noção do passado.
Conquistas e avanços passados no campo de recuperação de informações (IR) evocam as possibilidades de “onde a seguir” na tecnologia de busca.
Isso me leva ao impacto que isso terá nas técnicas e metodologias de otimização de mecanismos de pesquisa (SEO) no futuro.
Na edição anterior da minha série de SEO “Back to the Future”, técnicas de indexação e classificação de palavras-chave revisitadas: 20 anos depois, concluí mostrando um gráfico que explica algo conhecido como “problema da abundância”. Isso frequentemente impede que técnicas puras de classificação de palavras-chave (na página) coloquem as páginas com mais autoridade no topo dos resultados. Relevante – sim. Mas autoritário?
Para os avaliadores de qualidade do Google, o EAT pode existir há apenas alguns anos. Mas no campo de RI, sempre esteve no centro de como e o que os mecanismos de pesquisa fazem.
Neste artigo, explorarei até onde vão a expertise, a autoridade e a confiabilidade (EAT) e em que elas realmente se baseiam.
'COMER' 20 anos atrás
Ainda há muita ambiguidade na indústria sobre o que “autoridade” realmente significa no sentido de SEO. Como um site/página se torna autoritário?
Talvez olhar como “autoridade” – bem como os termos “especialista” e “confiança” – entrou no léxico de RI e SEO possa lhe dar mais informações.
Aqui está um gráfico que criei em 2002, mas esta versão tem um aprimoramento relevante para unir tudo isso.

Usarei este gráfico clássico de mineração de dados da web, agora apresentando as três letras EAT para ajudar a construir uma melhor compreensão de suas origens.
EAT em si não é um algoritmo, mas:
- Expertise se conecta diretamente ao conteúdo da página .
- A autoridade se conecta diretamente à análise de hiperlink .
- A confiança vem de uma combinação de conteúdo da página e análise de hiperlink, além de dados de acesso do usuário final .
Todos os três aspectos de mineração de dados devem ser combinados em uma meta-pesquisa (ou pesquisa federada) para fornecer as páginas mais confiáveis para satisfazer as necessidades de informação do usuário final. Efetivamente, é uma série de mecanismos de classificação algorítmicos que se reforçam mutuamente.
Como membro profissional de longa data da Association for Computing Machinery, a maior sociedade de computação do mundo, tenho orgulho de pertencer ao grupo de interesse especial para recuperação de informações (SIGIR). Minha principal área de foco dentro desse grupo é a análise de hiperlinks e a ciência dos rankings dos mecanismos de busca.
Para mim, esta é a área mais fascinante de RI e SEO. Como ouvi dizer em muitas conferências ao longo dos anos: “Nem todos os links são iguais. Alguns são infinitamente mais iguais do que outros.”
E esse é um bom ponto de partida para esta próxima leitura épica para os colegas SEO Bravehearts.
A evolução das técnicas de classificação baseadas em texto para algoritmos de classificação baseados em hiperlinks
Vamos abordar rapidamente a razão fundamental pela qual os links são essenciais para todos os mecanismos de pesquisa, não apenas para o Google.
Primeiro, a análise de redes sociais tem uma história distinta. As últimas duas décadas viram um interesse e um fascínio crescentes na comunidade científica pela ideia de redes e teoria de redes. Como uma visão geral básica, isso significa simplesmente um padrão de interconexões entre um conjunto de coisas.
As redes sociais não são um fenômeno novo por empresas como a Meta. Os laços sociais entre amigos são amplamente estudados há muitos anos. Existem redes econômicas, redes de manufatura, redes de mídia e muitas outras redes.
Um experimento no campo que se tornou muito famoso fora da comunidade científica é conhecido como “Seis Graus de Separação”, do qual você deve estar ciente.
A web é uma rede de redes. E em 1998, a estrutura de hiperlinks da web tornou-se de grande interesse para um jovem cientista chamado Jon Kleinberg (agora reconhecido como um dos principais cientistas da computação do mundo) e para alguns estudantes da Universidade de Stanford, incluindo Google Larry Page e Sergey Brin . Durante esse ano, os três produziram dois dos algoritmos de classificação de análise de hiperlinks mais influentes – HITS (ou “Pesquisa de tópico induzida por hiperlink”) e PageRank.
Para ser claro, a web não tem preferência sobre um link ou outro. Um link é um link.
Mas para aqueles na incipiente indústria de SEO em 1998, essa perspectiva mudaria completamente quando Page e Brin, em um artigo que apresentaram em uma conferência na Austrália, fizeram esta declaração:
“Intuitivamente, vale a pena olhar as páginas que são bem citadas em muitos lugares da web.”
E então eles deram uma pista inicial endossando o fato de que eu destaquei que “nem todos os links são iguais” seguindo com isso:
“Além disso, as páginas que talvez tenham apenas uma citação de algo como a página inicial do Yahoo também geralmente valem a pena ser vistas.”
Essa última afirmação mexeu muito comigo e, como praticante, me manteve focado no desenvolvimento de uma abordagem mais elegante para vincular técnicas e práticas de atração ao longo dos anos.
Concluindo esta parte, vou explicar algo sobre minha abordagem (que tem sido um enorme sucesso) que eu sinto que vai mudar, conceitualmente, a maneira como você pensa sobre o que é chamado de “construção de links” e mudar isso para “ construção de reputação”.
As origens da 'autoridade' na busca
Na comunidade de SEO, a palavra “autoridade” é frequentemente usada quando se fala sobre o Google. Mas não é aí que o termo se originou (mais sobre isso depois).
No artigo que os fundadores do Google apresentaram na conferência na Austrália, é notável que, embora estivessem falando sobre um algoritmo de análise de hiperlinks, eles não usaram a palavra “link”, usaram a palavra “citação”. Isso ocorre porque o PageRank é baseado na análise de citações.
Explicando vagamente, essa é a análise da frequência, padrões e gráficos de citações em documentos (também conhecidos como links de um documento para outro). Um objetivo típico seria identificar os documentos mais importantes em uma coleção.
O primeiro exemplo de análise de citações foi o exame de redes de artigos científicos para descobrir as fontes mais confiáveis. Sua ciência abrangente é conhecida como “bibliometria” – que se encaixa na categoria de análise de rede social e teoria de rede, como já mencionei.
Veja como eu transpus isso há 20 anos da maneira mais simples para mostrar como o Google visualizava os dados de links da web.
“Alguns links em páginas da web são simplesmente auxílios de navegação para 'navegar' em um site. Outros links podem fornecer acesso a outras páginas que aumentam o conteúdo da página que os contém. Andrei Broder [Cientista-Chefe Alta Vista] apontou que, um autor de página da web provavelmente criará um link de uma página para outra por causa de sua relevância ou importância: “Sabe, o que é muito interessante na web é o ambiente de hiperlink que carrega muita informação. Diz-lhe: 'Acho que esta página é boa' – porque a maioria das pessoas costuma listar bons recursos. Muito poucas pessoas diriam: 'Essas são as piores páginas que eu já vi' e colocariam links para elas em suas próprias páginas!
Páginas de alta qualidade com informações boas, claras e concisas são mais propensas a ter muitos links apontando para elas. Considerando que as páginas de baixa qualidade terão menos links ou nenhum. A análise de hiperlink pode melhorar significativamente a relevância dos resultados da pesquisa. Todos os principais mecanismos de pesquisa agora empregam algum tipo de algoritmo de análise de links.”

“Usando o princípio de citação/cocitação como usado na bibliometria convencional, os algoritmos de análise de hiperlinks podem fazer uma ou ambas as seguintes suposições básicas:
• Um hiperlink da página 'a' para a página 'b' é uma recomendação da página 'b' pelo autor da página 'a'.
• Se a página 'a' e a página 'b' estiverem conectadas por um hiperlink, elas podem estar no mesmo tópico.
Os algoritmos baseados em hiperlink também usam um gráfico de cocitação não direcionado. A e B estão conectados por uma aresta não direcionada, se e somente se houver uma terceira página C que liga A e B.”
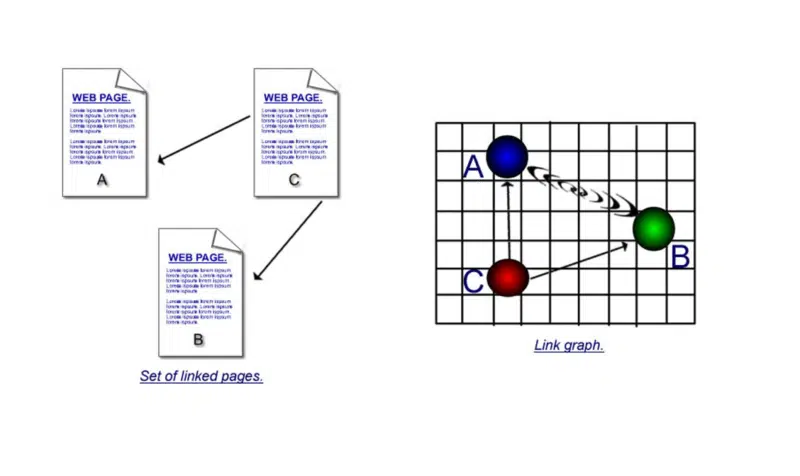
Essa segunda parte tinha uma explicação muito mais longa no livro. Mas como é um pouco confuso, vou dar uma bem simplista aqui.
É importante entender os pontos fortes da citação e da cocitação.
Na primeira ilustração, há links diretos – uma página usando um hiperlink para se conectar a outra. Mas se a página 'c' tem links para 'a' e 'b' e então a página 'd' tem links para 'a' e 'b' e então a página 'e' e assim por diante, o que você pode supor é que, embora a página 'a' e a página 'b' não façam hyperlink diretamente uma para a outra, porque são cocitadas tantas vezes, deve haver alguma conexão entre elas.
Qual seria um exemplo real disso?
Bem, listas para começar. Páginas com os “dez melhores” laptops mais vendidos, os “dez melhores” personalidades esportivas ou estrelas do rock, você pode ver como a cocitação é um grande fator nesses tipos de páginas.
Então, onde esse algoritmo HITS do qual você talvez nunca tenha ouvido falar entra em ação?
Há uma história de que, ao mesmo tempo em que Page e Brin estavam trabalhando em seu algoritmo PageRank, Kleinberg estava analisando resultados nos principais mecanismos de busca da época, incluindo o que mais crescia entre eles, o Alta Vista. Ele achava que todos eles eram muito ruins e produziam resultados muito escassos em termos de quão relevantes eles eram para a consulta.
Ele pesquisou o termo “fabricante automotivo japonês” e não se impressionou ao notar que nenhum dos grandes nomes, como Toyota e Nissan, apareceu em qualquer lugar nos resultados, muito menos onde deveriam estar no topo.
Depois de visitar os sites dos principais fabricantes, ele percebeu uma coisa que todos tinham em comum: nenhum deles tinha as palavras “fabricante automotivo japonês” no texto de qualquer página do site.
Na verdade, ele pesquisou o termo “mecanismo de busca” e nem o Alta Vista apareceu em seus próprios resultados pelo mesmo motivo. Isso fez com que ele começasse e se concentrasse na conectividade das páginas da web para dar uma pista de quão relevantes (e importantes) elas eram para uma determinada consulta.
Então, ele desenvolveu o algoritmo HITS, que pegava as primeiras mil ou mais páginas após uma busca por palavra-chave no Alta Vista e as classificava de acordo com sua interconectividade.
Efetivamente, ele estava usando a estrutura de links para formar uma rede ou “comunidade” em torno do tópico da palavra-chave e, dentro dessa rede, identificar o que ele chamou de “Hubs e Autoridades”.
Foi aí que a palavra “autoridade” entrou no léxico de SEO. O título da tese de Kleinberg era “Fontes autorizadas em um ambiente hiperlinkado”.
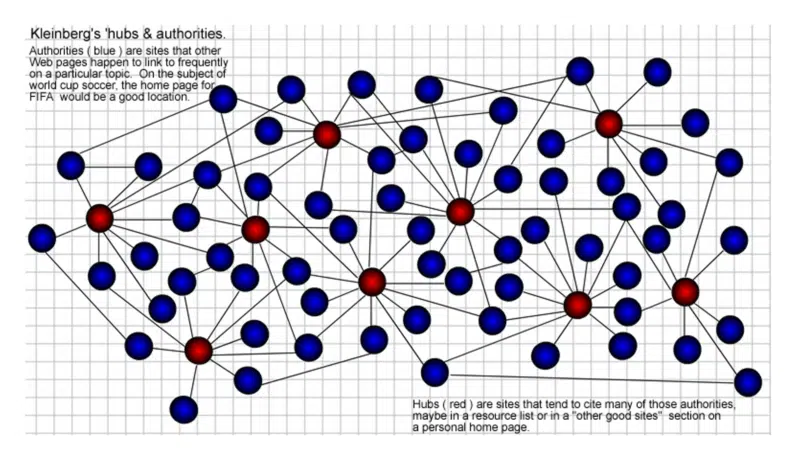
As páginas “Hub” são aquelas com muitos links que conectam a “autoridades” em um determinado tópico. Quanto mais hubs se vinculam a uma determinada autoridade, mais autoridade ela obtém. Isso também se reforça mutuamente. Um bom hub também pode ser uma boa autoridade e vice-versa.
Como de costume, nenhum prêmio para minhas habilidades de criação gráfica todos esses anos atrás, mas foi assim que eu visualizei isso em 2002. Hubs (vermelho) são aqueles que se conectam a muitas “autoridades” (azul) dentro de comunidades da web.

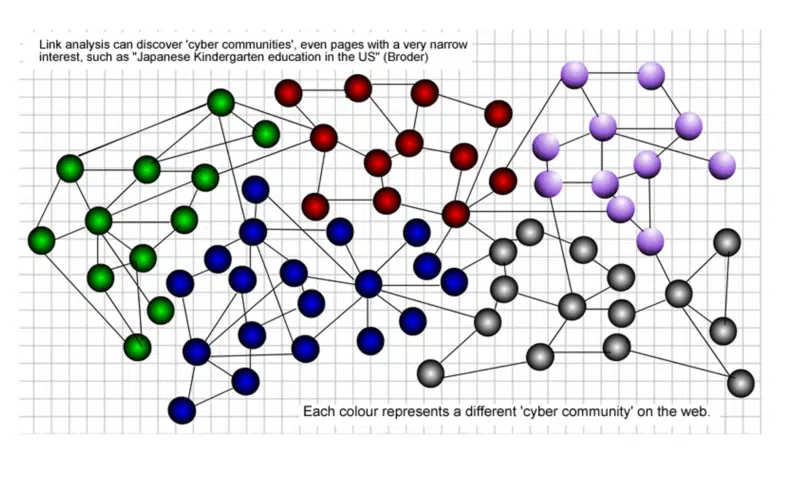
Então, o que é uma “comunidade na web”?
Uma comunidade de dados de página da Web refere-se a um conjunto de páginas da Web que possui suas próprias estruturas lógicas e semânticas.
A comunidade de páginas da Web considera cada página da Web como um objeto inteiro, em vez de dividir a página da Web em partes de informações e revela relações mútuas entre os dados da Web em questão.
É flexível ao refletir a natureza dos dados da web, como dinâmica e heterogeneidade. No gráfico a seguir, cada cor representa uma comunidade diferente na web.
Eu sempre afirmei que links atraídos de dentro de sua própria comunidade na web carregam mais prestígio do que aqueles de fora de sua comunidade.
Expliquei mais sobre a importância de identificar as comunidades desta forma há 20 anos:
“E quanto aos dados de ligação: páginas que apontam (links) para outras páginas podem fornecer uma enorme quantidade de informações sobre estrutura, comunidades e hierarquia (amplamente referidas como “topologia” da web). Ao utilizar esta metodologia os motores de busca podem tentar identificar a estrutura intelectual (topologia) e as redes sociais (comunidades) da web. No entanto, existem muitos problemas com o dimensionamento usando métodos de análise de citação e cocitação para lidar com centenas e centenas de milhões de documentos com bilhões de citações (hiperlinks).
O “ciberespaço” (como na web) já tem suas comunidades e bairros. OK – menos real no sentido de onde você mora e com quem você sai. Mas há uma “sociologia” na web. Amantes da música de diversas culturas e diferentes origens (e fusos horários) não vivem na mesma vizinhança geográfica – mas quando estão ligados uns aos outros na web, eles são muito comunitários. Assim como os amantes da arte e pessoas de todas as esferas da vida que postam suas informações na web e formam essas comunidades ou “vinculam bairros” no “ciberespaço”.
Obtenha a pesquisa diária de newsletters em que os profissionais de marketing confiam.
Consulte os termos.
PageRank vs. HITS: Qual é a diferença?
Existem muitas semelhanças nos algoritmos PageRank e HITS na maneira como analisam a interconectividade das páginas da web para criar um mecanismo de classificação.
Mas há uma diferença significativa também.
O PageRank é um algoritmo de classificação independente de palavras-chave, enquanto o HITS é dependente de palavras-chave.
Com o PageRank, você obtém sua pontuação de autoridade independentemente da comunidade, pois era originalmente uma pontuação global estática.
Enquanto o HITS depende da palavra-chave, o que significa que a pontuação de autoridade é construída em torno da palavra-chave/frase que reúne a comunidade. Leva muito tempo e além do escopo desta parte para entrar em detalhes, então não vou me aprofundar muito aqui.
O algoritmo que introduziu o termo 'especialista'
Este algoritmo Hilltop é extremamente importante, mas recebe menos atenção. E isso porque, nos círculos profissionais, há uma forte crença de que ele foi incorporado aos processos algorítmicos do Google em 2003, quando ocorreu a infame atualização da Flórida.
Um verdadeiro divisor de águas, o algoritmo Hilltop é um derivado muito mais próximo do HITS e foi desenvolvido em 1999 (sim, na mesma época) por Krishna Bharat.
Na época, ele trabalhava para o DEC Systems Research Center, proprietário do mecanismo de busca AltaVista. Seu trabalho de pesquisa foi intitulado "Quando os especialistas concordam: usando especialistas não afiliados para classificar tópicos populares". E é assim que ele descreveu Hilltop.
"Nós propomos um novo esquema de classificação para tópicos populares que coloca as páginas de maior autoridade no tópico de consulta no topo da classificação. Nosso algoritmo opera em um índice especial de "documentos de especialistas". Estes são um subconjunto das páginas na WWW identificados como diretórios de links para fontes não afiliadas sobre tópicos específicos. Os resultados são classificados com base na correspondência entre a consulta e o texto descritivo relevante para hiperlinks em páginas de especialistas que apontam para uma determinada página de resultados."
Sim, foi aqui que o termo "especialista" entrou no léxico de SEO. Observe tanto no título do artigo quanto na descrição do processo que sua página é considerada uma página de especialista quando outros links para ela. Assim, os termos "perito" e "autoridade" podem ser usados de forma intercambiável.
Outra coisa que deve ser observada com cuidado – e é o uso do termo “não afiliado” na descrição do algoritmo. Isso pode dar uma pista de por que muitos comerciantes de afiliados foram tão atingidos com a atualização da Flórida.
Outro que é importante notar é que frequentemente na comunidade de SEO, as pessoas se referem a "sites de autoridade" (ou às vezes "autoridade de domínio" que nem é uma coisa). Mas o fato é que os mecanismos de pesquisa retornam páginas da Web em seus resultados após uma consulta, não sites.
Quanto mais links você atrair de outras páginas "especializadas", mais autoridade você ganha, e mais "prestígio" você pode adicionar a outra página especializada ao criar um link para ela. Essa é a beleza de construir uma "reputação" dentro da comunidade – não simplesmente ser um coletor de links.
Sempre que explico a importância de ser reconhecido como um especialista dentro de uma comunidade da web, como tenho feito nas últimas duas décadas, sei que às vezes as pessoas têm dificuldade em visualizar como seria.
Felizmente, em meu trabalho de pesquisa todos esses anos atrás, encontrei outro algoritmo desenvolvido por dois cientistas japoneses, Masashi Toyoda e Kentarou Fukuchi. A abordagem deles também foi a comunidade da web, mas eles conseguiram produzir seus resultados visualmente.
O exemplo deles foi o que eles usaram quando construíram uma comunidade na web em torno de fabricantes de computadores. Aqui está uma pequena parte da saída que eu levantei para usar nas sessões da conferência para ajudar todos a ter uma ideia mais tangível da noção.
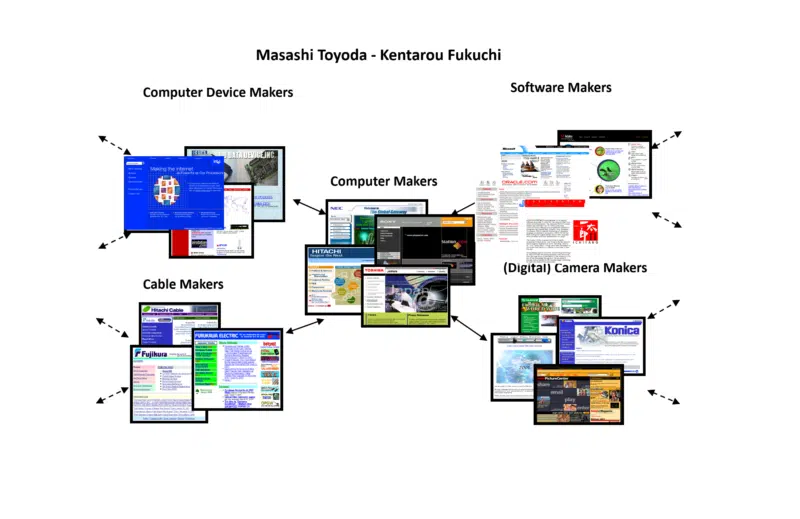
Observe como a comunidade da web inclui não apenas fabricantes de computadores, mas também fabricantes de dispositivos, fabricantes de cabos, fabricantes de software, etc. Isso indica quão ampla e profunda uma comunidade web pode ser (assim como estreita e superficial).
Como surgiu a 'confiança'
Há muito que envolve "expertise" e "autoridade", e nada menos que "confiança".
Mesmo "confiança" se enquadra na área de análise de hiperlinks e na estrutura da web. Muito trabalho foi feito para usar o conteúdo e a conectividade de "páginas de especialistas" confiáveis para descobrir e eliminar spam. Com técnicas de IA e ML, esses padrões de conectividade são muito mais fáceis de identificar e eliminar.
Antigamente havia um algoritmo desenvolvido conhecido como "TrustRank" e era nisso que se baseava. Claro, o teste de "confiança" realmente ocorre com o usuário final.
Os mecanismos de pesquisa se esforçam para eliminar o spam e fornecer resultados que realmente satisfaçam as necessidades de informação dos usuários. Assim, os padrões de acesso do usuário às páginas fornecem uma enorme quantidade de dados sobre quais páginas passam no teste da comunidade da web (conectividade) e, em seguida, aquelas que passam no teste do usuário final (dados de acesso do usuário).
Como mencionei, links de outras páginas da web para suas páginas podem ser vistos como um "voto" para seu conteúdo. Mas e os milhões e milhões de usuários finais que não têm páginas da web para fornecer um link – como eles podem votar?
Eles fazem isso com sua "confiança" clicando em determinados resultados – ou não clicando em outros.
É tudo sobre se os usuários finais estão consumindo seu conteúdo – porque, se não estiverem – qual é o objetivo do Google devolvê-lo nos resultados após uma consulta?
O que 'especialista', 'autoridade' e 'confiança' significam na pesquisa
Para resumir, você não pode se declarar um especialista em suas próprias páginas.
Você pode "reivindicar" ser um especialista ou uma autoridade em um determinado campo ou líder mundial nisso ou naquilo.
Mas filosoficamente, o Google e outros motores de busca estão dizendo: "Quem mais pensa assim?"
Não é o que você diz sobre si mesmo. É o que outras pessoas estão dizendo sobre você (texto âncora do link). É assim que você constrói uma "reputação" em sua comunidade.
Além disso, os avaliadores de qualidade do Google não determinam se seu conteúdo é "especialista" ou se você é uma "autoridade" ou não. Seu trabalho é examinar e determinar se os algoritmos do Google estão fazendo seu trabalho.
Este é um assunto tão fascinante e há muito mais para cobrir. Mas estamos sem tempo e espaço por enquanto.
Da próxima vez, explicarei como os dados estruturados são importantes e estar conectado "semanticamente" em sua comunidade da web.
Até lá, aproveite as cores douradas do outono enquanto entramos em outra temporada com grande expectativa para a próxima leitura épica sobre o funcionamento interno dos mecanismos de busca.
As opiniões expressas neste artigo são do autor convidado e não necessariamente do Search Engine Land. Os autores da equipe estão listados aqui.