
Los orígenes de EAT: contenido de la página, análisis de hipervínculos y datos de uso
Publicado: 2022-09-13Predecir el futuro a partir del conocimiento del pasado es fundamental. Siempre estoy atento a los avances tecnológicos, pero nunca pierdo la pista del pasado.
Los logros y avances pasados en el campo de la recuperación de información (IR) evocan las posibilidades de "dónde seguir" en la tecnología de búsqueda.
Eso me lleva al impacto que tendrá en las técnicas y metodologías de optimización de motores de búsqueda (SEO) en el futuro.
En la entrega anterior de mi serie de SEO "Regreso al futuro", revisé las técnicas de indexación y clasificación de palabras clave: 20 años después, concluí mostrando un gráfico que explica algo conocido como el "problema de la abundancia". Con frecuencia, esto impide que las técnicas puras de clasificación de palabras clave (en la página) coloquen las páginas más autorizadas en la parte superior de los resultados. Relevante, sí. Pero con autoridad?
Para los evaluadores de calidad de Google, es posible que EAT solo haya existido durante algunos años. Pero en el campo de IR, siempre ha estado en el centro de cómo y qué hacen los motores de búsqueda.
En este artículo, exploraré hasta dónde llega la experiencia, la autoridad y la confiabilidad (EAT) y en qué se basan realmente.
'COMER' hace 20 años
Todavía hay bastante ambigüedad en la industria sobre lo que realmente significa "autoridad" en el sentido de SEO. ¿Cómo se vuelve autoritativo un sitio/página?
Tal vez ver cómo la "autoridad", así como los términos "experto" y "confianza", entraron en el léxico de IR y SEO puede brindarle más información.
Aquí hay un gráfico que creé en 2002, pero esta versión tiene una mejora relevante para unir todo esto.

Usaré este gráfico clásico de minería de datos web, que ahora presenta las tres letras EAT para ayudar a comprender mejor sus orígenes.
EAT en sí mismo no es un algoritmo, pero:
- La experiencia se conecta directamente con el contenido de la página .
- Authority se conecta directamente al análisis de hipervínculos .
- La confianza proviene de una combinación de contenido de la página y análisis de hipervínculos, además de datos de acceso del usuario final .
Los tres aspectos de minería de datos deben combinarse en una forma de metabúsqueda (o búsqueda federada) para proporcionar las páginas más autorizadas para satisfacer las necesidades de información del usuario final. Efectivamente, es una serie de mecanismos de clasificación algorítmica convergentes que se refuerzan mutuamente.
Como miembro profesional desde hace mucho tiempo de la Association for Computing Machinery, la sociedad informática más grande del mundo, me enorgullece pertenecer al grupo de interés especial para la recuperación de información (SIGIR). Mi área principal de enfoque dentro de ese grupo es el análisis de hipervínculos y la ciencia de las clasificaciones de los motores de búsqueda.
Para mí, esta es el área más fascinante de IR y SEO. Como se me ha escuchado decir en muchas conferencias a lo largo de los años: “No todos los enlaces son iguales. Algunos son infinitamente más iguales que otros”.
Y ese es un buen punto de partida para esta próxima lectura épica para los compañeros SEO Bravehearts.
La evolución de las técnicas de clasificación basadas en texto a los algoritmos de clasificación basados en hipervínculos
Veamos rápidamente la razón fundamental por la que los enlaces son esenciales para todos los motores de búsqueda, no solo para Google.
Primero, el análisis de redes sociales tiene una historia distinguida. Las últimas dos décadas han visto un gran interés y fascinación en la comunidad científica sobre la idea de las redes y la teoría de redes. Como visión general básica, esto simplemente significa un patrón de interconexiones entre un conjunto de cosas.
Las redes sociales no son un fenómeno nuevo de empresas como Meta. Los lazos sociales entre amigos han sido ampliamente estudiados durante muchos años. Existen redes económicas, redes de fabricación, redes de medios y muchas más redes.
Un experimento en el campo que se hizo muy famoso fuera de la comunidad científica se conoce como "Seis grados de separación", del cual quizás estés al tanto.
La web es una red de redes. Y en 1998, la estructura de hipervínculos de la web se volvió de gran interés para un joven científico llamado Jon Kleinberg (ahora reconocido como uno de los científicos informáticos más importantes del mundo) y para un par de estudiantes de la Universidad de Stanford, incluidos Google Larry Page y Sergey Brin. . Durante ese año, los tres produjeron dos de los algoritmos de clasificación de análisis de hipervínculos más influyentes: HITS (o "Búsqueda de temas inducida por hipervínculos") y PageRank.
Para que quede claro, la web no tiene preferencia sobre un enlace u otro. Un enlace es un enlace.
Pero para aquellos en la incipiente industria de SEO en 1998, esa perspectiva cambiaría por completo cuando Page y Brin, en un documento que presentaron en una conferencia en Australia, hicieron esta declaración:
"Intuitivamente, vale la pena mirar las páginas que están bien citadas en muchos lugares de la web".
Y luego dieron una pista temprana que respalda el hecho de que destaqué que "no todos los enlaces son iguales" al seguir con esto:
"Además, las páginas que quizás solo tengan una cita de algo como la página de inicio de Yahoo también valen la pena mirarlas".
Esa última declaración tocó una fibra sensible en mí y, como practicante, me ha mantenido enfocado en desarrollar un enfoque más elegante para vincular técnicas y prácticas de atracción a lo largo de los años.
Como conclusión de esta entrega, voy a explicar algo sobre mi enfoque (que ha tenido un gran éxito) que creo que cambiará, conceptualmente, la forma en que piensas sobre lo que se conoce como "construcción de enlaces" y lo cambiará a " construcción de reputación”.
Los orígenes de la 'autoridad' en la búsqueda
En la comunidad SEO, la palabra "autoridad" se usa a menudo cuando se habla de Google. Pero ahí no es donde se originó el término (más sobre eso más adelante).
En el documento que los fundadores de Google presentaron en la conferencia en Australia, es notable que, aunque estaban hablando de un algoritmo de análisis de hipervínculos, no usaron la palabra "enlace", sino que usaron la palabra "cita". Esto se debe a que PageRank se basa en el análisis de citas.
Explicado libremente, ese es el análisis de la frecuencia, los patrones y los gráficos de las citas en los documentos (también conocidos como enlaces de un documento a otro). Un objetivo típico sería identificar los documentos más importantes de una colección.
El primer ejemplo de análisis de citas fue el examen de redes de artículos científicos para descubrir las fuentes más autorizadas. Su ciencia general se conoce como "bibliometría", que encaja en la categoría de análisis de redes sociales y teoría de redes, como ya he mencionado.
Así es como transpuse eso hace 20 años de la manera más simple para mostrar cómo Google veía los datos de enlaces web.
“Algunos enlaces en las páginas web son simplemente ayudas de navegación para 'navegar' un sitio. Otros enlaces pueden proporcionar acceso a otras páginas que aumentan el contenido de la página que los contiene. Andrei Broder [Jefe científico de Alta Vista] señaló que es probable que el autor de una página web cree un enlace de una página a otra debido a su relevancia o importancia: "Sabes, lo que es muy interesante sobre la web es el entorno de hipervínculos que lleva mucha información. Te dice: 'Creo que esta página es buena', porque la mayoría de las personas suelen enumerar buenos recursos. ¡Muy pocas personas dirían: 'Esas son las peores páginas que he visto en mi vida' y pondrían enlaces a ellas en sus propias páginas!
Es más probable que las páginas de alta calidad con información buena, clara y concisa tengan muchos enlaces que apuntan a ellas. Mientras que las páginas de baja calidad tendrán menos enlaces o ninguno. El análisis de hipervínculos puede mejorar significativamente la relevancia de los resultados de búsqueda. Todos los principales motores de búsqueda emplean ahora algún tipo de algoritmo de análisis de enlaces”.

“Usando el principio de cita/cocitación como se usa en la bibliometría convencional, los algoritmos de análisis de hipervínculos pueden hacer uno o ambos de estos supuestos básicos:
• Un hipervínculo de la página 'a' a la página 'b' es una recomendación de la página 'b' por parte del autor de la página 'a'.
• Si la página 'a' y la página 'b' están conectadas por un hipervínculo, es posible que traten del mismo tema.
Los algoritmos basados en hipervínculos también utilizan un gráfico de cocitación no dirigido. A y B están conectados por un borde no dirigido, si y solo si hay una tercera página C que enlaza tanto con A como con B”.
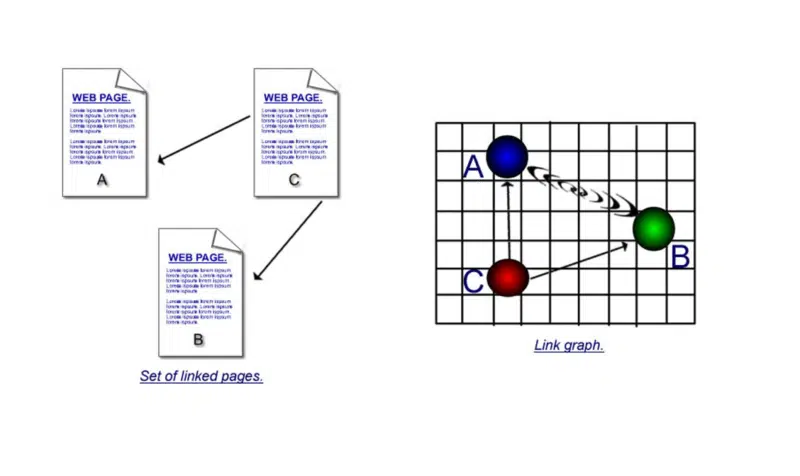
Esa segunda parte tenía una explicación mucho más larga en el libro. Pero como es un poco confuso, daré uno muy simple aquí.
Es importante comprender los puntos fuertes de la citación y la cocitación.
En la primera ilustración, hay enlaces directos: una página que usa un hipervínculo para conectarse a otra. Pero si la página 'c' se vincula a 'a' y 'b' y luego la página 'd' se vincula a 'a' y 'b' y luego a la página 'e' y así sucesivamente, lo que puede suponer es que, aunque la página 'a' y la página 'b' no se vinculan directamente entre sí, debido a que se citan tantas veces, debe haber alguna conexión entre ellas.
¿Cuál sería un ejemplo de la vida real de eso?
Bueno, listas para empezar. Páginas con las "diez mejores" computadoras portátiles más vendidas, las "diez mejores" personalidades deportivas o estrellas de rock, puede ver cómo la cocitación es un factor importante en ese tipo de páginas.
Entonces, ¿dónde entra en juego este algoritmo HITS del que quizás nunca hayas oído hablar?
Hay una historia de que, al mismo tiempo que Page y Brin estaban trabajando en su algoritmo PageRank, Kleinberg estaba analizando los resultados en los principales motores de búsqueda del día, incluido el de más rápido crecimiento entre ellos, Alta Vista. Pensó que todos eran bastante deficientes y produjeron resultados muy escasos en términos de cuán relevantes eran para la consulta.
Buscó el término "fabricante de automóviles japonés" y no se impresionó mucho al notar que ninguno de los nombres más importantes, como Toyota y Nissan, aparecía en los resultados, y mucho menos donde deberían estar en la parte superior.
Después de visitar los sitios web de los principales fabricantes, notó una cosa que todos tenían en común: ninguno de ellos tenía las palabras "fabricante de automóviles japonés" en el texto de las páginas del sitio.
De hecho, buscó el término "motor de búsqueda" e incluso Alta Vista no apareció en sus propios resultados por la misma razón. Esto hizo que comenzara y se centrara en la conectividad de las páginas web para dar una pista de cuán relevantes (e importantes) eran para una consulta determinada.
Entonces, desarrolló el algoritmo HITS, que tomó las primeras mil o más páginas después de una búsqueda de palabras clave en Alta Vista y luego las clasificó según su interconectividad.
Efectivamente, estaba usando la estructura de enlaces para formar una red o "comunidad" en torno al tema de la palabra clave y, dentro de esa red, identificar lo que denominó "Centros y autoridades".
Ahí es donde la palabra "autoridad" entró en el léxico SEO. El título de la tesis de Kleinberg fue "Fuentes autorizadas en un entorno hipervinculado".
Las páginas "hub" son aquellas con muchos enlaces que conectan a "autoridades" sobre un tema determinado. Cuantos más hubs se vinculen con una autoridad dada, más autoridad obtendrá. Esto también se refuerza mutuamente. Un buen hub también puede ser una buena autoridad y viceversa.

Como de costumbre, no hay premios por mis habilidades de creación gráfica hace tantos años, pero así es como lo visualicé en 2002. Los hubs (rojo) son aquellos que se vinculan con muchas "autoridades" (azul) dentro de las comunidades web.
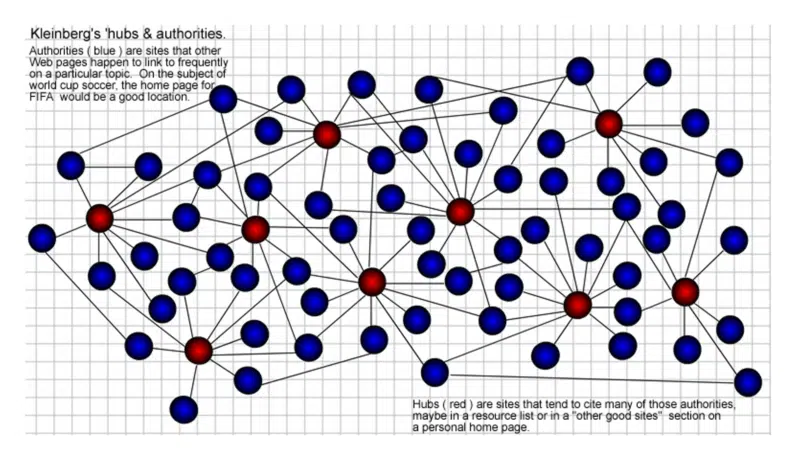
Entonces, ¿qué es una “comunidad web”?
Una comunidad de datos de una página web se refiere a un conjunto de páginas web que tiene sus propias estructuras lógicas y semánticas.
La comunidad de páginas web considera cada página web como un objeto completo en lugar de dividir la página web en piezas de información y revela las relaciones mutuas entre los datos web en cuestión.
Es flexible para reflejar la naturaleza de los datos web, como la dinámica y la heterogeneidad. En el siguiente gráfico, cada color representa una comunidad diferente en la web.
Siempre he sostenido que los enlaces atraídos desde dentro de su propia comunidad web tienen más prestigio que los de fuera de su comunidad.
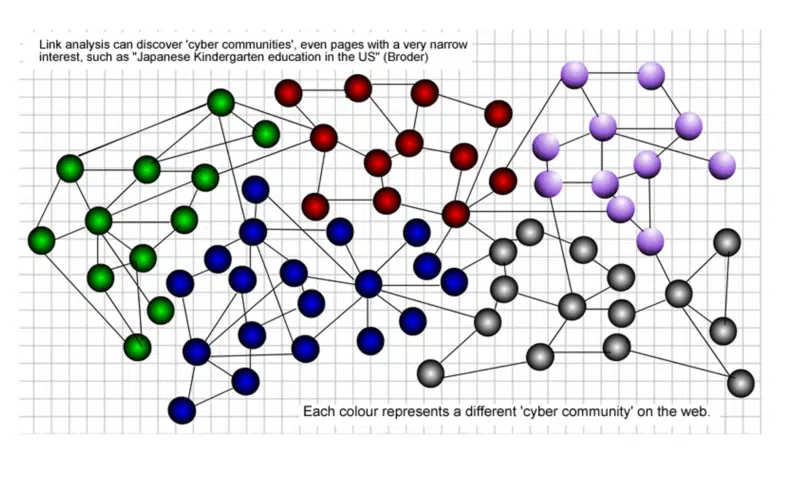
Expliqué más sobre la importancia de identificar comunidades de esta manera hace 20 años:
“Y en cuanto a los datos de vinculación: las páginas que apuntan (vinculan) a otras páginas pueden proporcionar una gran cantidad de información sobre la estructura, las comunidades y la jerarquía (en gran medida denominada “topología” de la web). Mediante el uso de esta metodología, los motores de búsqueda pueden intentar identificar la estructura intelectual (topología) y las redes sociales (comunidades) de la web. Sin embargo, existen muchos problemas con el escalado utilizando métodos de análisis de citas y co-citas para manejar cientos y cientos de millones de documentos con miles de millones de citas (hipervínculos).
El “ciberespacio” (como en la web) ya tiene sus comunidades y barrios. OK, menos real en el sentido de dónde vives y con quién te juntas. Pero hay una "sociología" en la web. Los amantes de la música de diversas culturas y diferentes orígenes (y zonas horarias) no viven en el mismo vecindario geográfico, pero cuando están vinculados entre sí en la web, son una gran comunidad. Al igual que los amantes del arte y las personas de todos los ámbitos de la vida que publican su información en la web y forman estas comunidades o "vecindarios de enlace" en el "ciberespacio".
Obtenga el boletín informativo diario en el que confían los especialistas en marketing.
Ver términos.
PageRank vs. HITS: ¿Cuál es la diferencia?
Hay muchas similitudes en los algoritmos PageRank y HITS en la forma en que analizan la interconectividad de las páginas web para crear un mecanismo de clasificación.
Pero también hay una diferencia significativa.
PageRank es un algoritmo de clasificación independiente de las palabras clave, mientras que HITS depende de las palabras clave.
Con PageRank, obtiene su puntaje de autoridad independientemente de la comunidad, ya que originalmente era un puntaje global estático.
Mientras que HITS depende de la palabra clave, lo que significa que la puntuación de autoridad se basa en la palabra clave/frase que une a la comunidad. Lleva demasiado tiempo y va más allá del alcance de esta entrega entrar en detalles, por lo que no profundizaré demasiado aquí.
El algoritmo que introdujo el término 'experto'
Este algoritmo Hilltop es muy importante pero recibe la menor atención. Y eso se debe a que, en los círculos profesionales, existe una fuerte creencia de que se fusionó con los procesos algorítmicos de Google en 2003 cuando ocurrió la infame actualización de Florida.
Un verdadero cambio de juego, el algoritmo Hilltop es un derivado mucho más cercano de HITS y fue desarrollado en 1999 (sí, casi al mismo tiempo) por Krishna Bharat.
En ese momento, trabajaba para DEC Systems Research Center, que era el propietario del motor de búsqueda AltaVista. Su trabajo de investigación se tituló "Cuando los expertos están de acuerdo: uso de expertos no afiliados para clasificar temas populares". Y así es como describió Hilltop.
"Proponemos un esquema de clasificación novedoso para temas populares que coloca las páginas más autorizadas sobre el tema de consulta en la parte superior de la clasificación. Nuestro algoritmo opera en un índice especial de "documentos de expertos". Estos son un subconjunto de las páginas en la WWW identificados como directorios de enlaces a fuentes no afiliadas sobre temas específicos. Los resultados se clasifican en función de la coincidencia entre la consulta y el texto descriptivo relevante para hipervínculos en páginas de expertos que apuntan a una página de resultados determinada".
Sí, aquí es donde el término "experto" entró en el léxico SEO. Tenga en cuenta que tanto en el título del artículo como en la descripción del proceso, su página se considera una página experta cuando otros enlazan con ella. Por lo tanto, los términos "experto" y "autoridad" pueden usarse indistintamente.
Otra cosa que debe tenerse en cuenta con cuidado es el uso del término "no afiliado" en la descripción del algoritmo. Eso puede dar una pista de por qué muchos comerciantes afiliados se vieron tan afectados por la actualización de Florida.
Otro aspecto importante a tener en cuenta es que, con frecuencia, en la comunidad de SEO, las personas se refieren a "sitios de autoridad" (o, a veces, "autoridad de dominio", que ni siquiera existe). Pero el hecho es que los motores de búsqueda devuelven páginas web en sus resultados después de una consulta, no sitios web.
Cuantos más enlaces atraiga de otras páginas "expertas", más autoridad ganará y más "prestigio" podrá agregar a otra página experta al vincularla. Esta es la belleza de construir una "reputación" dentro de la comunidad, no simplemente ser un recopilador de enlaces.
Cada vez que explico la importancia de ser reconocido como un experto dentro de una comunidad web, como lo he hecho durante las últimas dos décadas, sé que a veces las personas tienen dificultades para visualizar cómo sería eso.
Afortunadamente, en mi trabajo de investigación hace tantos años, encontré otro algoritmo desarrollado por dos científicos japoneses, Masashi Toyoda y Kentarou Fukuchi. Su enfoque también fue la comunidad web, pero pudieron mostrar sus resultados visualmente.
El ejemplo que tomé de ellos fue uno que usaron cuando crearon una comunidad web en torno a los fabricantes de computadoras. Aquí hay una pequeña parte del resultado que tomé para usar en las sesiones de la conferencia para ayudar a todos a tener una idea más tangible de la noción.
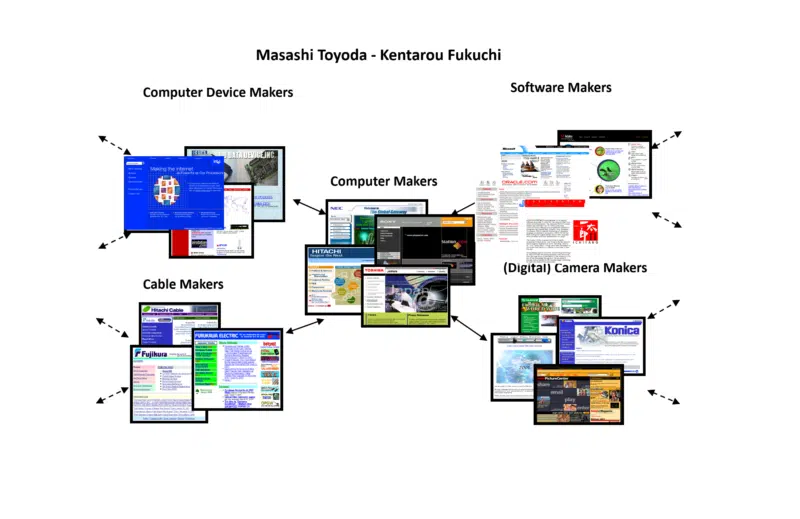
Observe cómo la comunidad web incluye no solo a fabricantes de computadoras, sino también a fabricantes de dispositivos, fabricantes de cables, fabricantes de software, etc. Esto indica qué tan amplia y profunda puede ser una comunidad web (así como estrecha y superficial).
Cómo surgió la 'confianza'
Hay mucho que se incluye en la "experiencia" y la "autoridad", y nada menos que en la "confianza".
Incluso la "confianza" cae en el área del análisis de hipervínculos y la estructura de la web. Se ha trabajado mucho en el uso del contenido y la conectividad de las "páginas de expertos" en las que se confía para descubrir y eliminar el spam. Con las técnicas de IA y ML, esos patrones de conectividad son mucho más fáciles de detectar y eliminar.
En el pasado, se desarrolló un algoritmo conocido como "TrustRank" y en eso se basaba. Por supuesto, la prueba de fuego para la "confianza" realmente ocurre con el usuario final.
Los motores de búsqueda se esfuerzan por eliminar el spam y ofrecer resultados que realmente satisfagan las necesidades de información de los usuarios. Por lo tanto, los patrones de acceso de los usuarios a las páginas proporcionan una gran cantidad de datos sobre qué páginas pasan la prueba de la comunidad web (conectividad) y luego aquellas que pasan la prueba del usuario final (datos de acceso del usuario).
Como mencioné, los enlaces de otras páginas web a sus páginas pueden verse como un "voto" por su contenido. Pero, ¿qué pasa con los millones y millones de usuarios finales que no tienen páginas web para darle un enlace? ¿Cómo pueden votar?
Lo hacen con su "confianza" haciendo clic en ciertos resultados, o no haciendo clic en otros.
Se trata de si los usuarios finales están consumiendo su contenido, porque si no es así, ¿cuál es el punto de que Google lo devuelva en los resultados después de una consulta?
Qué significan 'experto', 'autoridad' y 'confianza' en la búsqueda
Para resumir, no puedes declararte un experto en tus propias páginas.
Puede "pretender" ser un experto o una autoridad en un determinado campo o líder mundial en esto o aquello.
Pero filosóficamente, Google y otros motores de búsqueda dicen: "¿Quién más piensa así?"
No es lo que dices de ti. Es lo que otras personas dicen de ti (texto ancla del enlace). Así es como construyes una "reputación" en tu comunidad.
Además, los evaluadores de calidad de Google no determinan por sí mismos si su contenido es "experto" o si usted es una "autoridad" o no. Su trabajo es examinar y determinar si los algoritmos de Google están haciendo su trabajo.
Este es un tema tan fascinante y hay mucho más que cubrir. Pero estamos fuera de tiempo y espacio por ahora.
La próxima vez, explicaré la importancia de los datos estructurados y de estar conectado "semánticamente" dentro de su comunidad web.
Hasta entonces, disfruta de los colores dorados del otoño mientras nos deslizamos hacia otra temporada con gran expectativa por la próxima lectura épica sobre el funcionamiento interno de los motores de búsqueda.
Las opiniones expresadas en este artículo pertenecen al autor invitado y no necesariamente a Search Engine Land. Los autores del personal se enumeran aquí.