
Asal usul EAT: Konten halaman, analisis hyperlink, dan data penggunaan
Diterbitkan: 2022-09-13Memprediksi masa depan berdasarkan pengetahuan tentang masa lalu adalah fundamental. Saya selalu memperhatikan kemajuan teknologi tetapi tidak pernah melupakan masa lalu.
Pencapaian dan terobosan masa lalu di bidang pencarian informasi (IR) memunculkan kemungkinan "di mana untuk selanjutnya" dalam teknologi pencarian.
Itu kemudian membawa saya pada apa dampaknya pada teknik dan metodologi optimasi mesin pencari (SEO) di masa depan.
Dalam angsuran sebelumnya dari seri "Kembali ke Masa Depan" SEO saya, Teknik pengindeksan dan peringkat kata kunci ditinjau kembali: 20 tahun kemudian, saya menyimpulkan dengan menunjukkan grafik yang menjelaskan sesuatu yang dikenal sebagai "masalah kelimpahan." Ini sering mencegah teknik peringkat kata kunci murni (di halaman) dari menempatkan halaman yang lebih otoritatif di bagian atas hasil. Relevan - ya. Tapi berwibawa?
Untuk penilai kualitas Google, EAT mungkin hanya ada selama beberapa tahun. Namun di bidang IR, selalu menjadi inti dari bagaimana dan apa yang dilakukan mesin pencari.
Dalam artikel ini, saya akan mengeksplorasi sejauh mana keahlian, otoritas, dan kepercayaan (EAT) berjalan dan apa yang sebenarnya menjadi dasar mereka.
'MAKAN' 20 tahun yang lalu
Masih ada cukup banyak ambiguitas dalam industri tentang apa arti sebenarnya dari "otoritas" dalam arti SEO. Bagaimana sebuah situs/halaman menjadi otoritatif?
Mungkin melihat bagaimana “otoritas” – serta istilah “ahli” dan “kepercayaan” – masuk ke dalam kamus IR dan SEO dapat memberi Anda lebih banyak wawasan.
Berikut adalah grafik yang saya buat pada tahun 2002, tetapi versi ini memiliki peningkatan yang relevan untuk menyatukan semua ini.

Saya akan menggunakan grafik penambangan data web klasik ini, sekarang menampilkan tiga huruf EAT untuk membantu membangun pemahaman yang lebih baik tentang asal-usulnya.
EAT itu sendiri bukanlah sebuah algoritma, tetapi:
- Keahlian terhubung langsung ke konten halaman .
- Otoritas terhubung langsung ke analisis hyperlink .
- Kepercayaan berasal dari kombinasi konten halaman dan analisis hyperlink, ditambah data akses pengguna akhir .
Ketiga aspek penambangan data harus digabungkan dalam pencarian meta (atau pencarian gabungan) untuk menyediakan halaman yang paling otoritatif untuk memenuhi kebutuhan informasi pengguna akhir. Secara efektif, ini adalah serangkaian mekanisme peringkat algoritmik yang saling memperkuat.
Sebagai anggota profesional lama dari Association for Computing Machinery, masyarakat komputasi terbesar di dunia, saya bangga menjadi bagian dari kelompok minat khusus untuk pencarian informasi (SIGIR). Area fokus utama saya dalam grup itu adalah analisis hyperlink dan ilmu tentang peringkat mesin pencari.
Bagi saya, ini adalah area IR dan SEO yang paling menarik. Seperti yang pernah saya dengar di banyak konferensi selama bertahun-tahun: “Tidak semua tautan sama. Beberapa jauh lebih setara daripada yang lain. ”
Dan itu adalah titik awal yang baik untuk membaca epik berikutnya untuk sesama SEO Bravehearts.
Evolusi dari teknik peringkat berbasis teks ke algoritma peringkat berbasis hyperlink
Mari kita bahas alasan mendasar bahwa tautan penting untuk semua mesin telusur, bukan hanya untuk Google.
Pertama, analisis jaringan sosial memiliki sejarah tersendiri. Dua dekade terakhir telah melihat minat dan daya tarik yang sangat berkembang dalam komunitas ilmiah pada gagasan jaringan dan teori jaringan. Sebagai gambaran dasar, ini berarti pola interkoneksi antara satu set hal.
Jejaring sosial bukanlah fenomena baru oleh perusahaan seperti Meta. Ikatan sosial di antara teman-teman telah dipelajari secara luas selama bertahun-tahun. Jaringan ekonomi, jaringan manufaktur, jaringan media, dan banyak lagi jaringan yang ada.
Salah satu eksperimen di bidang yang menjadi sangat terkenal di luar komunitas ilmiah dikenal sebagai "Enam Derajat Pemisahan", yang mungkin Anda ketahui.
Web adalah jaringan dari jaringan. Dan pada tahun 1998, struktur hyperlink web menjadi sangat menarik bagi seorang ilmuwan muda bernama Jon Kleinberg (sekarang diakui sebagai salah satu ilmuwan komputer terkemuka di dunia) dan beberapa mahasiswa dari Universitas Stanford, termasuk Google Larry Page dan Sergey Brin . Selama tahun itu, ketiganya menghasilkan dua algoritma peringkat analisis hyperlink yang paling berpengaruh – HITS (atau “Pencarian Topik yang Diinduksi Hyperlink”) dan PageRank.
Agar jelas, web tidak memiliki preferensi atas satu tautan atau lainnya. Tautan adalah tautan.
Tetapi bagi mereka yang baru lahir di industri SEO pada tahun 1998, perspektif itu akan berubah sepenuhnya ketika Page dan Brin, dalam makalah yang mereka presentasikan pada sebuah konferensi di Australia, membuat pernyataan ini:
“Secara intuitif, halaman yang dikutip dengan baik dari banyak tempat di web layak untuk dilihat.”
Dan kemudian mereka memberikan petunjuk awal yang mendukung fakta yang saya soroti bahwa “tidak semua tautan sama” dengan menindaklanjuti ini:
“Juga, halaman yang mungkin hanya memiliki satu kutipan dari sesuatu seperti halaman beranda Yahoo juga umumnya layak untuk dilihat.”
Pernyataan terakhir itu benar-benar menyentuh hati saya dan, sebagai seorang praktisi, telah membuat saya tetap fokus pada pengembangan pendekatan yang lebih elegan untuk menghubungkan teknik dan praktik atraksi selama bertahun-tahun.
Sebagai penutup dari angsuran ini, saya akan menjelaskan sesuatu tentang pendekatan saya (yang telah sangat sukses) yang saya rasa akan mengubah, secara konseptual, cara Anda berpikir tentang apa yang disebut sebagai "membangun tautan" dan mengubahnya menjadi " membangun reputasi.”
Asal usul 'otoritas' dalam pencarian
Dalam komunitas SEO, kata "otoritas" sering digunakan ketika berbicara tentang Google. Tapi bukan dari situ istilah itu berasal (lebih lanjut nanti).
Dalam makalah yang dipresentasikan oleh para pendiri Google pada konferensi di Australia, perlu dicatat bahwa meskipun mereka berbicara tentang algoritma analisis hyperlink, mereka tidak menggunakan kata "tautan", mereka menggunakan kata "kutipan". Ini karena PageRank didasarkan pada analisis kutipan.
Secara gamblang dijelaskan, itulah analisis frekuensi, pola, dan grafik kutipan dalam dokumen (alias tautan dari satu dokumen ke dokumen lainnya). Tujuan tipikal adalah untuk mengidentifikasi dokumen paling penting dalam koleksi.
Contoh paling awal dari analisis kutipan adalah pemeriksaan jaringan makalah ilmiah untuk menemukan sumber yang paling otoritatif. Ilmu menyeluruhnya dikenal sebagai "bibliometrik" – yang cocok dengan analisis jaringan sosial dan kategori teori jaringan seperti yang telah saya singgung sebelumnya.
Inilah cara saya mengubahnya 20 tahun yang lalu dengan cara paling sederhana untuk menunjukkan bagaimana Google melihat data tautan web.
“Beberapa tautan di halaman web hanyalah alat bantu navigasi untuk 'menjelajahi' sebuah situs. Tautan lain dapat memberikan akses ke halaman lain yang menambah konten halaman yang memuatnya. Andrei Broder [Chief Scientist Alta Vista] menunjukkan bahwa, seorang penulis halaman web cenderung membuat link dari satu halaman ke halaman lain karena relevansi atau pentingnya: “Anda tahu, apa yang sangat menarik tentang web adalah lingkungan hyperlink yang membawa Banyak informasi. Ini memberi tahu Anda: 'Saya pikir halaman ini bagus' – karena kebanyakan orang biasanya mencantumkan sumber daya yang bagus. Sangat sedikit orang yang akan berkata: 'Itu adalah halaman terburuk yang pernah saya lihat' dan memasang tautan ke halaman tersebut di halaman mereka sendiri!
Halaman berkualitas tinggi dengan informasi yang baik, jelas, dan ringkas lebih cenderung memiliki banyak tautan yang mengarah ke sana. Sedangkan halaman berkualitas rendah akan memiliki lebih sedikit tautan atau tidak ada sama sekali. Analisis hyperlink dapat secara signifikan meningkatkan relevansi hasil pencarian. Semua mesin pencari utama sekarang menggunakan beberapa jenis algoritma analisis tautan.”

“Menggunakan prinsip kutipan/ko-sitasi seperti yang digunakan dalam bibliometrik konvensional, algoritma analisis hyperlink dapat membuat salah satu atau kedua asumsi dasar ini:
• Sebuah hyperlink dari halaman 'a' ke halaman 'b' adalah rekomendasi dari halaman 'b' oleh penulis halaman 'a.'
• Jika halaman 'a' dan halaman 'b' dihubungkan oleh hyperlink, maka mereka mungkin berada pada topik yang sama.
Algoritma berbasis hyperlink juga menggunakan grafik co-citation tidak berarah. A dan B dihubungkan oleh sisi tak berarah, jika dan hanya jika ada halaman ketiga C yang menghubungkan keduanya ke A dan B.”
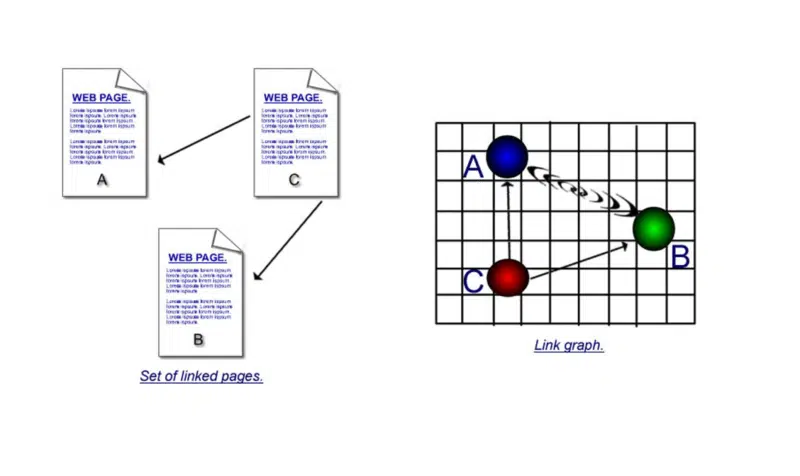
Bagian kedua itu memiliki penjelasan yang lebih panjang di dalam buku. Tetapi karena agak membingungkan, saya akan memberikan yang sangat sederhana di sini.
Penting untuk memahami kekuatan kutipan dan ko-sitasi.
Pada ilustrasi pertama, ada tautan langsung – satu halaman menggunakan hyperlink untuk terhubung ke yang lain. Tetapi jika halaman 'c' terhubung ke 'a' dan 'b' dan kemudian halaman 'd' terhubung ke 'a' dan 'b' dan kemudian halaman 'e' dan seterusnya dan seterusnya, yang dapat Anda asumsikan adalah, meskipun halaman 'a' dan halaman 'b' tidak saling hyperlink secara langsung, karena mereka dikutip berkali-kali, pasti ada hubungan di antara mereka.
Apa contoh kehidupan nyata dari itu?
Nah, daftar untuk memulai. Halaman dengan laptop terlaris “sepuluh besar”, tokoh olahraga “sepuluh besar”, atau bintang rock, Anda dapat melihat bagaimana kutipan bersama merupakan faktor besar dalam jenis halaman tersebut.
Jadi di mana algoritma HITS yang mungkin belum pernah Anda dengar ini ikut bermain?
Ada cerita bahwa pada saat yang sama Page dan Brin mengerjakan algoritma PageRank mereka, Kleinberg menganalisis hasil di mesin pencari teratas hari itu, termasuk yang paling cepat berkembang di antara mereka, Alta Vista. Dia berpikir bahwa mereka semua sangat buruk dan menghasilkan hasil yang sangat sedikit dalam hal seberapa relevan mereka dengan kueri.
Dia mencari istilah "produsen otomotif Jepang" dan sangat tidak terkesan karena tidak ada nama besar seperti Toyota dan Nissan yang muncul di hasil, apalagi di posisi teratas.
Setelah mengunjungi situs web produsen besar, dia melihat satu kesamaan yang mereka semua miliki: Tak satu pun dari mereka memiliki kata-kata "produsen otomotif Jepang" dalam teks di halaman situs mana pun.
Bahkan, dia mencari istilah "mesin pencari", dan bahkan Alta Vista tidak muncul di hasil pencariannya sendiri karena alasan yang sama. Hal ini menyebabkan dia untuk memulai dan fokus pada konektivitas halaman web untuk memberikan petunjuk tentang seberapa relevan (dan penting) mereka dengan kueri yang diberikan.
Jadi, dia mengembangkan algoritma HITS, yang mengambil ribuan halaman teratas atau lebih setelah pencarian kata kunci di Alta Vista dan kemudian memberi peringkat berdasarkan interkonektivitasnya.
Secara efektif, dia menggunakan struktur tautan untuk membentuk jaringan atau "komunitas" di sekitar topik kata kunci dan, di dalam jaringan itu, mengidentifikasi apa yang dia beri nama "Hub dan Otoritas."
Di situlah kata "otoritas" masuk ke dalam leksikon SEO. Judul tesis Kleinberg adalah "Sumber Resmi dalam Lingkungan Hyperlink."
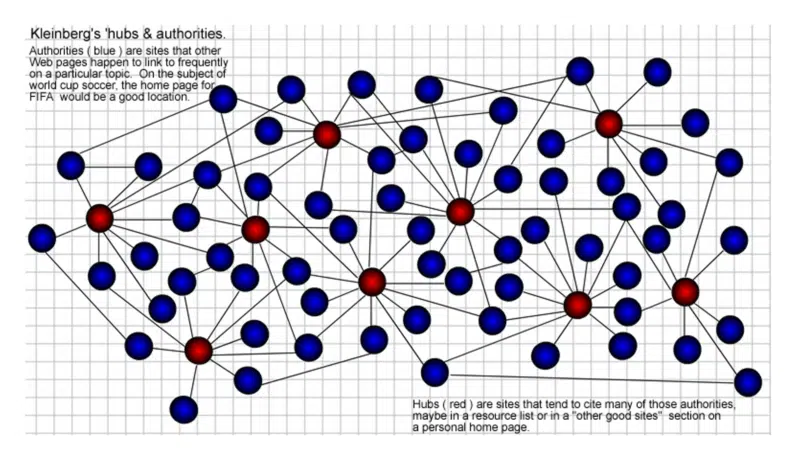
Halaman "Hub" adalah halaman dengan banyak tautan yang terhubung ke "otoritas" pada topik tertentu. Semakin banyak hub yang menautkan ke otoritas tertentu, semakin banyak otoritas yang didapatnya. Ini juga saling menguatkan. Hub yang baik juga bisa menjadi otoritas yang baik dan sebaliknya.

Seperti biasa, tidak ada hadiah untuk keterampilan membuat grafis saya bertahun-tahun yang lalu, tetapi ini adalah bagaimana saya memvisualisasikannya pada tahun 2002. Hub (merah) adalah yang menghubungkan ke banyak "otoritas" (biru) di dalam komunitas web.
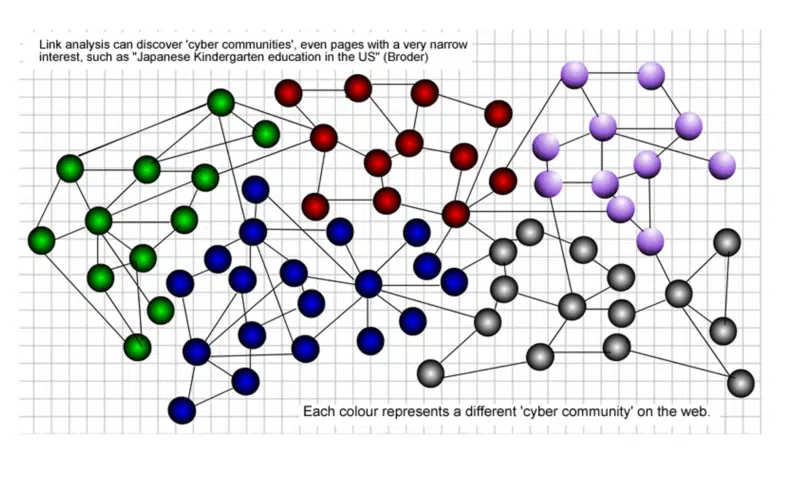
Jadi, apa itu "komunitas web"?
Komunitas data halaman web mengacu pada sekumpulan halaman web yang memiliki struktur logis dan semantiknya sendiri.
Komunitas halaman web menganggap setiap halaman web sebagai objek keseluruhan daripada memecah halaman web menjadi potongan-potongan informasi dan mengungkapkan hubungan timbal balik di antara data web yang bersangkutan.
Ini fleksibel dalam mencerminkan sifat data web, seperti dinamika dan heterogenitas. Dalam grafik berikut, setiap warna mewakili komunitas yang berbeda di web.
Saya selalu menyatakan bahwa tautan yang ditarik dari dalam komunitas web Anda sendiri memiliki prestise yang lebih tinggi daripada tautan yang berasal dari luar komunitas Anda.
Saya menjelaskan lebih lanjut tentang pentingnya mengidentifikasi komunitas dengan cara ini 20 tahun yang lalu:
“Dan untuk data linkage: halaman yang menunjuk (menghubungkan) ke halaman lain dapat memberikan sejumlah besar informasi tentang struktur, komunitas, dan hierarki (sebagian besar disebut sebagai “topologi” web). Dengan menggunakan metodologi ini mesin pencari dapat mencoba untuk mengidentifikasi struktur intelektual (topologi) dan jaringan sosial (komunitas) dari web. Namun, ada banyak masalah dengan penskalaan menggunakan metode kutipan dan analisis ko-sitasi untuk menangani ratusan dan ratusan juta dokumen dengan miliaran kutipan (hyperlink).
“Cyberspace” (seperti di web) sudah memiliki komunitas dan lingkungannya. OK – kurang nyata dalam arti di mana Anda tinggal dan dengan siapa Anda bergaul. Tapi ada "sosiologi" ke web. Pecinta musik dari beragam budaya dan latar belakang (dan zona waktu) yang berbeda tidak tinggal di lingkungan geografis yang sama – tetapi ketika mereka terhubung satu sama lain di web, mereka menjadi komunitas yang sangat besar. Sama seperti pecinta seni dan orang-orang dari setiap lapisan masyarakat yang memposting informasi mereka ke web dan membentuk komunitas ini atau “link environment” di “cyberspace.””
Dapatkan pemasar pencarian buletin harian yang diandalkan.
Lihat istilah.
PageRank vs. HITS: Apa bedanya?
Ada banyak kesamaan dalam algoritma PageRank dan HITS dalam cara mereka menganalisis interkonektivitas halaman web untuk membuat mekanisme peringkat.
Tapi ada perbedaan yang signifikan juga.
PageRank adalah algoritma peringkat kata kunci-independen, sedangkan HITS tergantung kata kunci.
Dengan PageRank, Anda mendapatkan skor otoritas Anda terlepas dari komunitas karena awalnya skor global statis.
Sedangkan HITS bergantung pada kata kunci, artinya skor otoritas dibangun di sekitar kata kunci/frasa yang menyatukan komunitas. Dibutuhkan terlalu lama dan di luar cakupan angsuran ini untuk masuk ke detail, jadi saya tidak akan pergi terlalu dalam di sini.
Algoritma yang memperkenalkan istilah 'ahli'
Algoritma Hilltop ini sangat penting tetapi mendapat perhatian paling sedikit. Dan itu karena, di kalangan profesional, ada keyakinan kuat bahwa itu digabungkan ke dalam proses algoritme Google pada tahun 2003 ketika pembaruan Florida yang terkenal terjadi.
Sebuah game-changer nyata, algoritma Hilltop adalah turunan lebih dekat dari HITS dan dikembangkan pada tahun 1999 (ya, semua sekitar waktu yang sama) oleh Krishna Bharat.
Saat itu, dia bekerja untuk DEC Systems Research Center, yang merupakan pemilik mesin pencari AltaVista. Makalah penelitiannya berjudul, "Ketika Para Ahli Setuju: Menggunakan Pakar Non-Afiliasi untuk Memberi Peringkat Topik Populer." Dan begitulah dia menggambarkan Hilltop.
"Kami mengusulkan skema peringkat baru untuk topik populer yang menempatkan halaman paling otoritatif pada topik kueri di peringkat teratas. Algoritme kami beroperasi pada indeks khusus "dokumen ahli." Ini adalah bagian dari halaman di WWW diidentifikasi sebagai direktori tautan ke sumber non-afiliasi pada topik tertentu. Hasil diberi peringkat berdasarkan kecocokan antara kueri dan teks deskriptif yang relevan untuk hyperlink pada halaman pakar yang mengarah ke halaman hasil tertentu."
Ya, di sinilah istilah "ahli" masuk ke dalam leksikon SEO. Perhatikan baik dalam judul makalah dan deskripsi proses halaman Anda dianggap sebagai halaman ahli ketika orang lain menautkannya. Jadi, istilah "ahli" dan "otoritas" dapat digunakan secara bergantian.
Satu hal lagi yang harus diperhatikan dengan hati-hati – dan itulah penggunaan istilah "non-afiliasi" dalam deskripsi algoritme. Itu mungkin memberi petunjuk mengapa banyak pemasar afiliasi sangat terpukul dengan pembaruan Florida.
Hal lain yang penting untuk diperhatikan adalah bahwa sering kali di komunitas SEO, orang merujuk ke "situs otoritas" (atau terkadang "otoritas domain" yang bahkan bukan apa-apa). Tetapi kenyataannya, mesin pencari mengembalikan halaman web dalam hasil mereka mengikuti permintaan, bukan situs web.
Semakin banyak tautan yang Anda tarik dari halaman "pakar" lainnya, semakin banyak otoritas yang Anda peroleh, dan semakin banyak "prestise" yang dapat Anda tambahkan ke halaman pakar lain dengan menautkannya. Inilah indahnya membangun "reputasi" di tengah masyarakat – bukan sekadar menjadi link collector.
Setiap kali saya menjelaskan pentingnya diakui sebagai ahli dalam komunitas web, seperti yang saya lakukan selama dua dekade terakhir, saya tahu bahwa terkadang orang mengalami kesulitan memvisualisasikan seperti apa bentuknya.
Untungnya, dalam penelitian saya bertahun-tahun yang lalu, saya menemukan algoritma lain yang dikembangkan oleh dua ilmuwan Jepang, Masashi Toyoda dan Kentarou Fukuchi. Pendekatan mereka adalah komunitas web juga, tetapi mereka mampu menampilkan hasil mereka secara visual.
Contoh yang saya ambil dari mereka adalah salah satu yang mereka gunakan ketika mereka membangun komunitas web di sekitar produsen komputer. Inilah sebagian kecil dari hasil yang saya angkat untuk digunakan pada sesi konferensi untuk membantu semua orang mendapatkan gagasan yang lebih nyata tentang gagasan tersebut.
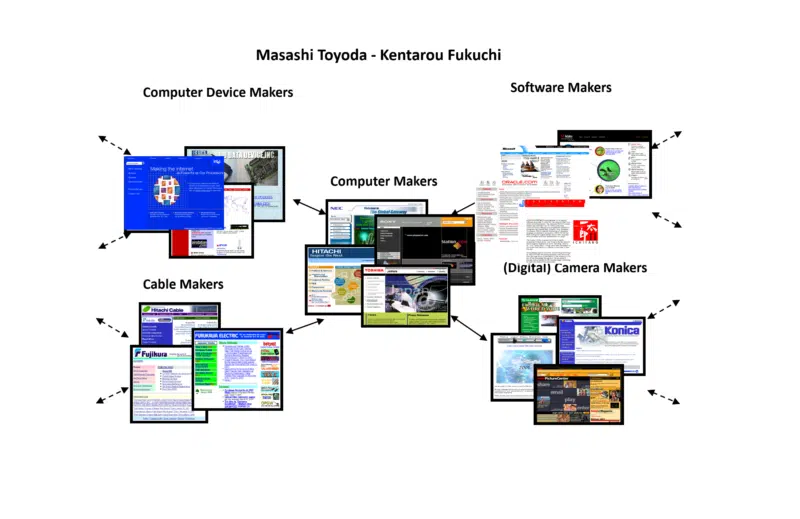
Perhatikan bagaimana komunitas web tidak hanya mencakup produsen komputer tetapi juga pembuat perangkat, pembuat kabel, pembuat perangkat lunak, dll. Ini menunjukkan seberapa luas dan dalam komunitas web dapat (serta sempit dan dangkal).
Bagaimana 'kepercayaan' muncul
Ada banyak hal yang masuk ke dalam "keahlian" dan "kewibawaan," dan tidak kurang yang masuk ke "kepercayaan."
Bahkan "kepercayaan" termasuk dalam area analisis hyperlink dan struktur web. Banyak pekerjaan telah dilakukan untuk menggunakan konten dan konektivitas "halaman ahli" yang dipercaya untuk menemukan dan menyingkirkan spam. Dengan teknik AI dan ML, pola konektivitas tersebut jauh lebih mudah dikenali dan dihilangkan.
Kembali pada hari ada algoritma yang dikembangkan yang dikenal sebagai "TrustRank" dan itulah yang menjadi dasarnya. Tentu saja, ujian asam untuk "kepercayaan" benar-benar terjadi pada pengguna akhir.
Mesin pencari berusaha untuk menyingkirkan spam dan memberikan hasil yang benar-benar memuaskan kebutuhan informasi pengguna. Jadi, pola akses pengguna ke halaman menyediakan sejumlah besar data di halaman mana yang lulus uji komunitas web (konektivitas) dan yang lulus uji pengguna akhir (data akses pengguna).
Seperti yang telah saya sebutkan, tautan dari halaman web lain ke halaman Anda dapat dilihat sebagai "suara" untuk konten Anda. Tapi bagaimana dengan jutaan dan jutaan pengguna akhir yang tidak memiliki halaman web untuk memberi Anda tautan – bagaimana mereka bisa memilih?
Mereka melakukannya dengan "kepercayaan" mereka dengan mengklik hasil tertentu – atau tidak mengklik yang lain.
Ini semua tentang apakah pengguna akhir mengonsumsi konten Anda – karena jika tidak – apa gunanya Google mengembalikannya dalam hasil setelah kueri?
Apa arti 'ahli', 'otoritas', dan 'kepercayaan' dalam penelusuran
Untuk meringkas, Anda tidak bisa menyatakan diri Anda seorang ahli di halaman Anda sendiri.
Anda dapat "mengklaim" menjadi ahli atau otoritas di bidang tertentu atau terkemuka dunia ini atau itu.
Tapi secara filosofis, Google dan mesin pencari lainnya berkata: "Siapa lagi yang berpikir begitu?"
Bukan apa yang Anda katakan tentang diri Anda. Itulah yang dikatakan orang lain tentang Anda (teks jangkar tautan). Begitulah cara Anda membangun "reputasi" di komunitas Anda.
Selain itu, penilai kualitas Google tidak dengan sendirinya menentukan apakah konten Anda "ahli" atau Anda adalah "otoritas" atau bukan. Tugas mereka adalah memeriksa dan menentukan apakah algoritma Google melakukan tugasnya.
Ini adalah subjek yang sangat menarik dan masih banyak lagi yang harus dibahas. Tapi kita kehabisan waktu dan ruang untuk saat ini.
Lain kali, saya akan menjelaskan betapa pentingnya data terstruktur dan "secara semantik" terhubung dalam komunitas web Anda.
Sampai saat itu, nikmati warna keemasan musim gugur saat kita meluncur ke musim lain dengan antisipasi besar untuk membaca epik berikutnya tentang cara kerja mesin pencari.
Pendapat yang diungkapkan dalam artikel ini adalah dari penulis tamu dan belum tentu Search Engine Land. Penulis staf tercantum di sini.