
Początki EAT: zawartość strony, analiza hiperłączy i dane dotyczące użytkowania
Opublikowany: 2022-09-13Przewidywanie przyszłości w oparciu o wiedzę o przeszłości ma fundamentalne znaczenie. Zawsze bacznie obserwuję postęp technologiczny, ale nigdy nie tracę z przeszłości śladu.
Dotychczasowe osiągnięcia i przełomy w dziedzinie wyszukiwania informacji (IR) stwarzają możliwości „dokąd dalej” w technologii wyszukiwania.
To prowadzi mnie do tego, jaki wpływ będzie to miało na techniki i metodologie optymalizacji wyszukiwarek (SEO) w przyszłości.
W poprzedniej części mojej serii SEO „Powrót do przyszłości” ponownie omówiłem techniki indeksowania i rankingu słów kluczowych: 20 lat później zakończyłem, pokazując grafikę, która wyjaśnia coś znanego jako „problem z obfitością”. Często uniemożliwia to zwykłym technikom rankingowania słów kluczowych (na stronie) umieszczanie bardziej autorytatywnych stron na górze wyników. Trafne – tak. Ale autorytatywny?
Dla osób oceniających jakość Google, EAT może istnieć dopiero od kilku lat. Ale w dziedzinie IR zawsze była w centrum tego, jak i co robią wyszukiwarki.
W tym artykule zbadam, jak daleko sięga wiedza specjalistyczna, autorytatywność i wiarygodność (EAT) i na czym tak naprawdę się opierają.
„JEŚĆ” 20 lat temu
W branży wciąż jest sporo niejasności co do tego, co tak naprawdę oznacza „autorytatywność” w sensie SEO. W jaki sposób witryna/strona staje się autorytatywna?
Być może spojrzenie na to, jak „autorytet” – a także terminy „ekspert” i „zaufanie” – pojawiły się w leksykonie IR i SEO, może dać ci więcej wglądu.
Oto grafika, którą stworzyłem w 2002 roku, ale ta wersja ma odpowiednie ulepszenie, które łączy to wszystko razem.

Wykorzystam tę klasyczną grafikę do eksploracji danych internetowych, która teraz zawiera trzy litery EAT, aby pomóc w lepszym zrozumieniu jej pochodzenia.
EAT sam w sobie nie jest algorytmem, ale:
- Doświadczenie łączy się bezpośrednio z zawartością strony .
- Urząd łączy się bezpośrednio z analizą hiperłączy .
- Zaufanie wynika z połączenia zawartości strony i analizy hiperłączy oraz danych dostępowych użytkowników końcowych .
Wszystkie trzy aspekty eksploracji danych muszą być połączone w sposób metawyszukiwania (lub wyszukiwania sfederowanego), aby zapewnić najbardziej wiarygodne strony spełniające potrzeby informacyjne użytkownika końcowego. W rzeczywistości jest to wzajemnie wzmacniająca się seria zbieżnych algorytmicznych mechanizmów rankingowych.
Jako wieloletni zawodowy członek Association for Computing Machinery, największego na świecie stowarzyszenia komputerowego, jestem dumny, że należę do specjalnej grupy interesu ds. wyszukiwania informacji (SIGIR). Moim głównym obszarem zainteresowania w tej grupie jest analiza hiperłączy i nauka o rankingach wyszukiwarek.
Dla mnie to najbardziej fascynujący obszar IR i SEO. Jak już słyszałem na wielu konferencjach na przestrzeni lat: „Nie wszystkie powiązania są równe. Niektóre są nieskończenie bardziej równe niż inne.”
To dobry punkt wyjścia do kolejnej epickiej lektury dla innych SEO Bravehearts.
Ewolucja od tekstowych technik rankingowych do algorytmów rankingowych opartych na hiperłączach
Omówmy szybko podstawowy powód, dla którego linki są niezbędne dla wszystkich wyszukiwarek, nie tylko dla Google.
Po pierwsze, analiza sieci społecznościowych ma wybitną historię. Ostatnie dwie dekady przyniosły ogromny rozwój zainteresowania i fascynacji społeczności naukowej ideą sieci i teorią sieci. W podstawowym przeglądzie oznacza to po prostu wzorzec połączeń między zbiorem rzeczy.
Sieci społecznościowe nie są nowym zjawiskiem firm takich jak Meta. Więzi społeczne wśród przyjaciół są szeroko badane od wielu lat. Istnieją sieci gospodarcze, sieci produkcyjne, sieci medialne i wiele innych sieci.
Jeden z eksperymentów w tej dziedzinie, który stał się bardzo sławny poza społecznością naukową, znany jest jako „Sześć stopni oddalenia”, o którym możesz być świadomy.
Sieć to sieć sieci. W 1998 roku struktura hiperłączy w sieci zainteresowała młodego naukowca Jona Kleinberga (obecnie uznawanego za jednego z czołowych informatyków na świecie) oraz kilku studentów ze Stanford University, w tym Google Larry Page i Sergey Brin. . W ciągu tego roku ta trójka stworzyła dwa najbardziej wpływowe algorytmy rankingu analizy hiperłączy – HITS (lub „Wyszukiwanie tematów wywołane przez hiperłącza”) i PageRank.
Żeby było jasne, sieć nie ma pierwszeństwa w stosunku do tego czy innego linku. Link to link.
Ale dla tych z rodzącej się branży SEO w 1998, ta perspektywa zmieniłaby się całkowicie, gdy Page i Brin w artykule, który przedstawili na konferencji w Australii, wydali następujące oświadczenie:
„Intuicyjnie warto obejrzeć strony, które są dobrze cytowane z wielu miejsc w sieci”.
A potem podali wczesną wskazówkę, potwierdzając fakt, że podkreśliłem, że „nie wszystkie linki są równe”, kontynuując to:
„Ponadto strony, które mają być może tylko jeden cytat z czegoś takiego jak strona główna Yahoo, są również ogólnie warte obejrzenia”.
To ostatnie stwierdzenie uderzyło we mnie prawdziwą strunę i przez lata, jako praktykującego, skupiłem się na rozwijaniu bardziej eleganckiego podejścia do łączenia technik i praktyk przyciągania.
Na zakończenie tej części wyjaśnię coś o moim podejściu (które odniosło ogromny sukces), które moim zdaniem zmieni koncepcyjnie sposób, w jaki myślisz o tym, co określa się jako „budowanie linków” i zmienisz to na „ budowanie reputacji.”
Początki „autorytetu” w wyszukiwaniu
W społeczności SEO słowo „autorytet” jest często używane, gdy mówi się o Google. Ale nie od tego pochodzi termin (więcej o tym później).
W artykule, który założyciele Google zaprezentowali na konferencji w Australii, warto zauważyć, że chociaż mówili o algorytmie analizy hiperłączy, nie użyli słowa „link”, ale użyli słowa „cytowanie”. Dzieje się tak, ponieważ PageRank opiera się na analizie cytowań.
Luźno wyjaśniony, jest to analiza częstotliwości, wzorców i wykresów cytowań w dokumentach (czyli linków z jednego dokumentu do drugiego). Typowym celem byłoby zidentyfikowanie najważniejszych dokumentów w kolekcji.
Najwcześniejszym przykładem analizy cytowań było badanie sieci artykułów naukowych w celu odkrycia najbardziej autorytatywnych źródeł. Jej nadrzędna nauka znana jest jako „bibliometria” – która pasuje do kategorii analizy sieci społecznych i teorii sieci, o czym już wspomniałem.
Oto jak przetransponowałem to 20 lat temu w absolutnie najprostszy sposób, aby pokazać, jak Google przeglądał dane o linkach internetowych.
„Niektóre linki na stronach internetowych to po prostu pomoc w nawigacji do 'przeglądania' witryny. Inne linki mogą zapewniać dostęp do innych stron, które rozszerzają zawartość strony zawierającej je. Andrei Broder [Główny Naukowiec Alta Vista] zwrócił uwagę, że autor strony internetowej prawdopodobnie utworzy link z jednej strony do drugiej ze względu na jej znaczenie lub znaczenie: „Wiesz, bardzo interesujące w sieci jest środowisko hiperłączy, które przenosi dużo informacji. Mówi ci: „Uważam, że ta strona jest dobra” – ponieważ większość ludzi zwykle wymienia dobre zasoby. Bardzo niewiele osób powiedziałoby: „To są najgorsze strony, jakie kiedykolwiek widziałem” i umieściłoby linki do nich na własnych stronach!
Strony wysokiej jakości z dobrymi, jasnymi i zwięzłymi informacjami częściej zawierają wiele linków do nich kierujących. Natomiast strony niskiej jakości będą miały mniej linków lub wcale. Analiza hiperłączy może znacznie poprawić trafność wyników wyszukiwania. Wszystkie główne wyszukiwarki wykorzystują teraz pewien rodzaj algorytmów analizy linków”.

„Korzystając z zasady cytowania/kocytowania stosowanej w konwencjonalnej bibliometrii, algorytmy analizy hiperłączy mogą przyjąć jedno lub oba z tych podstawowych założeń:
• Hiperłącze ze strony „a” do strony „b” to rekomendacja strony „b” przez autora strony „a”.
• Jeśli strona „a” i strona „b” są połączone hiperłączem, mogą dotyczyć tego samego tematu.
Algorytmy oparte na hiperłączach wykorzystują również nieskierowany wykres współcytowania. A i B są połączone nieskierowaną krawędzią, wtedy i tylko wtedy, gdy istnieje trzecia strona C, która łączy zarówno z A, jak i B.”
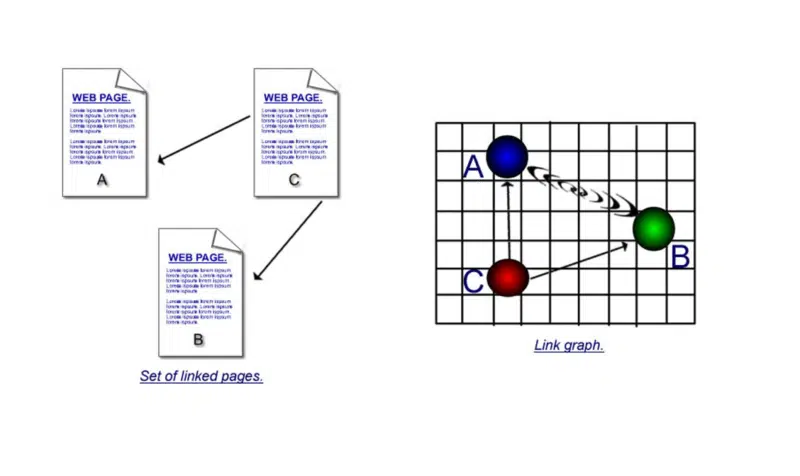
Ta druga część miała znacznie dłuższe wyjaśnienie w książce. Ale ponieważ jest to trochę zagmatwane, podam tutaj bardzo uproszczony.
Ważne jest, aby zrozumieć mocne strony cytowania i współcytowania.
Na pierwszej ilustracji znajdują się bezpośrednie linki – jedna strona używa hiperłącza do łączenia się z drugą. Ale jeśli strona „c” łączy się z „a” i „b”, a następnie strona „d” łączy się z „a” i „b”, a następnie ze stroną „e” itd. itd., możesz założyć, że: chociaż strona „a” i strona „b” nie prowadzą do siebie bezpośrednio hiperłączy, ponieważ są one cytowane tak wiele razy, musi istnieć między nimi jakiś związek.
Jaki byłby tego przykład z życia?
Cóż, listy na początek. Strony z „dziesięciu” najlepiej sprzedających się laptopów, „dziesięć najlepszych” osobowości sportowych lub gwiazdy rocka, możesz zobaczyć, jak współcytowanie jest ważnym czynnikiem w tego typu stronach.
Więc gdzie w grę wchodzi ten algorytm HITS, o którym być może nigdy nie słyszałeś?
Jest taka historia, że w tym samym czasie Page i Brin pracowali nad swoim algorytmem PageRank, Kleinberg analizował wyniki w najlepszych wyszukiwarkach tamtych czasów, w tym najszybciej rozwijającej się wśród nich, Alta Vista. Uważał, że wszystkie były dość słabe i dawały bardzo skromne wyniki pod względem tego, jak trafne były dla zapytania.
Szukał terminu „japoński producent samochodów” i nie zrobił na nim wrażenia, gdy zauważył, że żadna z głównych nazw, takich jak Toyota i Nissan, nie pojawiła się nigdzie w wynikach, nie mówiąc już o tym, gdzie powinny znajdować się na szczycie.
Po odwiedzeniu stron internetowych głównych producentów zauważył jedną wspólną cechę: żaden z nich nie zawierał w tekście na żadnej stronie słowa „japoński producent samochodów”.
W rzeczywistości szukał terminu „wyszukiwarka” i nawet Alta Vista nie pojawiła się we własnych wynikach z tego samego powodu. To spowodowało, że zaczął i skoncentrował się na łączności stron internetowych, aby dać wskazówkę, jak istotne (i ważne) są one dla danego zapytania.
Opracował więc algorytm HITS, który po wyszukaniu słów kluczowych w Alta Vista pobierał tysiąc lub więcej najlepszych stron, a następnie klasyfikował je według ich wzajemnych połączeń.
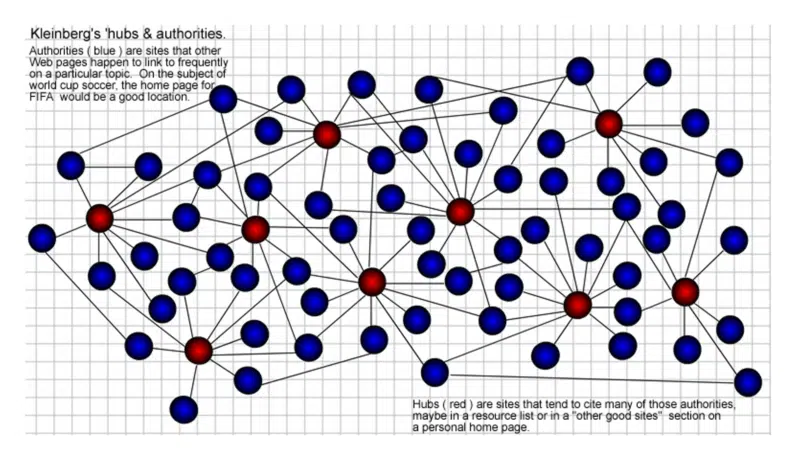
Skutecznie wykorzystywał strukturę linków, aby utworzyć sieć lub „społeczność” wokół tematu słów kluczowych i, w ramach tej sieci, zidentyfikować to, co nazwał „Centrami i władzami”.
Właśnie tam słowo „autorytet” weszło do leksykonu SEO. Tytuł pracy Kleinberga brzmiał „Autorytatywne źródła w środowisku hiperlinkowym”.
Strony „Hub” to te, które zawierają wiele linków prowadzących do „autorytetów” na dany temat. Im więcej hubów łączy się z danym organem, tym więcej autorytetu otrzymuje. To również wzajemnie się wzmacnia. Dobry hub może być również dobrym autorytetem i vice versa.

Jak zwykle żadnych nagród za moje umiejętności graficzne sprzed lat, ale tak to sobie wyobraziłem w 2002 roku. Huby (czerwone) to te, które prowadzą do wielu „autorytetów” (niebieskie) w społecznościach internetowych.
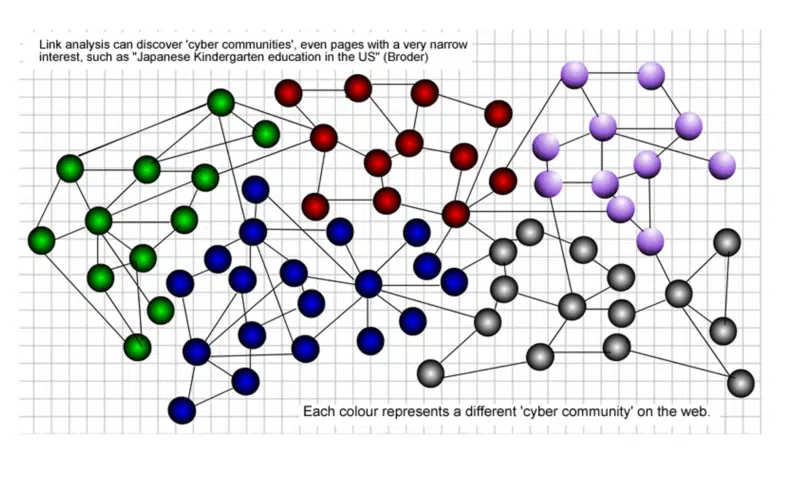
Czym zatem jest „społeczność internetowa”?
Społeczność danych stron internetowych odnosi się do zestawu stron internetowych, które mają własne struktury logiczne i semantyczne.
Społeczność stron internetowych traktuje każdą stronę internetową jako cały obiekt, zamiast dzielić ją na fragmenty informacji i ujawnia wzajemne relacje między odpowiednimi danymi sieciowymi.
Elastycznie odzwierciedla naturę danych internetowych, taką jak dynamika i heterogeniczność. Na poniższej grafice każdy kolor reprezentuje inną społeczność w sieci.
Zawsze twierdziłem, że linki przyciągane z Twojej własnej społeczności internetowej mają większy prestiż niż te spoza Twojej społeczności.
Wyjaśniłem więcej o znaczeniu identyfikacji społeczności w ten sposób 20 lat temu:
„A co do danych o linkach: strony wskazujące (linkujące) do innych stron mogą dostarczać ogromnej ilości informacji o strukturze, społecznościach i hierarchii (określanej głównie jako „topologia” sieci). Korzystając z tej metodologii, wyszukiwarki mogą próbować zidentyfikować strukturę intelektualną (topologię) i sieci społecznościowe (społeczności) sieci. Istnieje jednak wiele problemów ze skalowaniem za pomocą metod analizy cytowań i kocytacji, aby poradzić sobie z setkami i setkami milionów dokumentów z miliardami cytowań (hiperłącza).
„Cyberprzestrzeń” (podobnie jak w sieci) ma już swoje społeczności i sąsiedztwo. OK – mniej realne w sensie tego, gdzie mieszkasz i z kim spędzasz czas. Ale w sieci jest „socjologia”. Miłośnicy muzyki z różnych kultur i różnych środowisk (i stref czasowych) nie mieszkają w tym samym sąsiedztwie geograficznym – ale kiedy są ze sobą połączeni w sieci, są bardzo społecznością. Tak samo jak miłośnicy sztuki i ludzie z różnych środowisk, którzy publikują swoje informacje w sieci i tworzą te społeczności lub „łączą dzielnice” w „cyberprzestrzeni”.
Otrzymuj codzienne newslettery, na których polegają marketerzy.
Zobacz warunki.
PageRank vs. HITS: Jaka jest różnica?
Istnieje wiele podobieństw zarówno w algorytmach PageRank, jak i HITS w sposobie, w jaki analizują one wzajemne połączenia stron internetowych w celu stworzenia mechanizmu rankingu.
Ale jest też znacząca różnica.
PageRank jest algorytmem rankingu niezależnym od słów kluczowych, podczas gdy HITS jest zależny od słów kluczowych.
Dzięki PageRank otrzymujesz swój autorytet niezależnie od społeczności, ponieważ pierwotnie był to statyczny globalny wynik.
Podczas gdy HITS jest zależny od słów kluczowych, co oznacza, że punktacja autorytetu jest budowana wokół słowa kluczowego/frazy, która łączy społeczność. Wchodzenie w szczegóły zajmuje zbyt dużo czasu i wykracza poza ramy tej części, więc nie będę się tutaj zagłębiał.
Algorytm, który wprowadził termin „ekspert”
Ten algorytm Hilltop jest niezwykle ważny, ale zwraca najmniej uwagi. A to dlatego, że w kręgach zawodowych panuje silne przekonanie, że został on włączony do algorytmicznych procesów Google w 2003 roku, kiedy miała miejsce niesławna aktualizacja Florydy.
Prawdziwy zmieniacz gry, algorytm Hilltop jest znacznie bliższą pochodną HITS i został opracowany w 1999 roku (tak, mniej więcej w tym samym czasie) przez Krishnę Bharat.
W tym czasie pracował dla DEC Systems Research Center, będącego właścicielem wyszukiwarki AltaVista. Jego artykuł badawczy był zatytułowany „Kiedy eksperci się zgadzają: Korzystanie z ekspertów niezrzeszonych w rankingu popularnych tematów”. I tak opisał Hilltop.
„Proponujemy nowatorski schemat rankingowy dla popularnych tematów, który umieszcza najbardziej autorytatywne strony na temat zapytania na szczycie rankingu. Nasz algorytm operuje na specjalnym indeksie „dokumentów eksperckich”. Stanowią one podzbiór stron w sieci WWW identyfikowane jako katalogi linków do niepowiązanych źródeł na określone tematy. Wyniki są klasyfikowane na podstawie dopasowania między zapytaniem a odpowiednim tekstem opisu dla hiperłączy na stronach eksperckich wskazujących na daną stronę wyników”.
Tak, tutaj termin „ekspert” pojawił się w leksykonie SEO. Zwróć uwagę zarówno w tytule artykułu, jak i opisie procesu, w którym Twoja strona jest uznawana za stronę ekspercką, gdy inni linkują do niej. Tak więc terminy „ekspert” i „autorytet” mogą być używane zamiennie.
Jeszcze jedna rzecz, na którą należy zwrócić szczególną uwagę – to użycie w opisie algorytmu określenia „niestowarzyszony”. To może dać wskazówkę, dlaczego wielu marketingowców afiliacyjnych zostało tak mocno dotkniętych aktualizacją na Florydzie.
Innym, o czym warto pamiętać, jest to, że często w społeczności SEO ludzie odnoszą się do „witryny autorytetu” (lub czasami „autorytetu domeny”, co nawet nie jest rzeczą). Ale faktem jest, że wyszukiwarki zwracają strony internetowe w swoich wynikach po zapytaniu, a nie strony internetowe.
Im więcej linków przyciągasz z innych „eksperckich” stron, tym więcej zyskujesz autorytetu i tym większy „prestiż” możesz dodać do innej strony eksperckiej, umieszczając do niej link. Na tym polega piękno budowania „reputacji” w społeczności – nie tylko bycia kolekcjonerem linków.
Ilekroć wyjaśniam znaczenie bycia rozpoznawanym jako ekspert w społeczności internetowej, tak jak robiłem to przez ostatnie dwie dekady, wiem, że czasami ludzie mają trudności z wizualizacją, jak by to wyglądało.
Na szczęście w mojej pracy badawczej wiele lat temu natknąłem się na inny algorytm opracowany przez dwóch japońskich naukowców, Masashi Toyoda i Kentarou Fukuchi. Ich podejściem była również społeczność internetowa, ale byli w stanie przedstawić swoje wyniki wizualnie.
Przykładem, który wziąłem od nich, był ten, którego użyli, kiedy zbudowali społeczność internetową wokół producentów komputerów. Oto niewielka część wyników, które zebrałem do wykorzystania podczas sesji konferencyjnych, aby pomóc wszystkim uzyskać bardziej namacalne pojęcie o tym pojęciu.
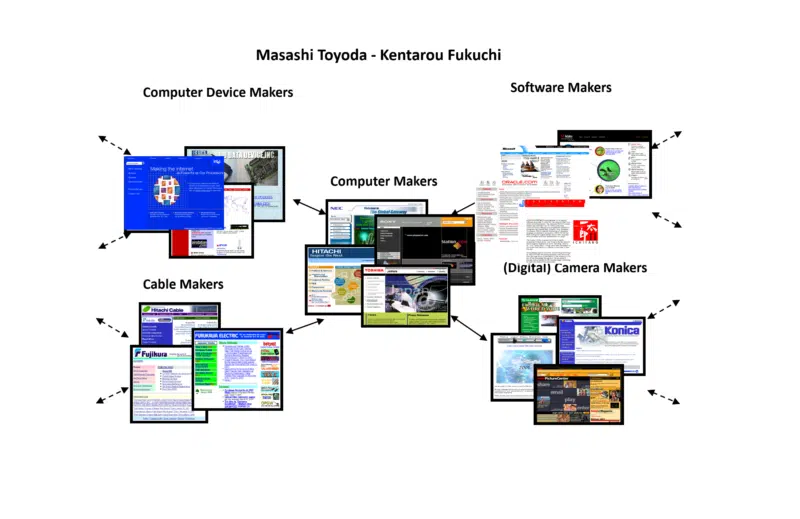
Zauważ, że społeczność internetowa obejmuje nie tylko producentów komputerów, ale także producentów urządzeń, producentów kabli, twórców oprogramowania itp. Wskazuje to, jak szeroka i głęboka może być społeczność internetowa (a także wąska i płytka).
Jak powstało „zaufanie”
Jest wiele rzeczy związanych z „ekspertyzacją” i „autorytatywnością”, a nie mniej z „zaufaniem”.
Nawet „zaufanie” wpada w obszar analizy hiperłączy i struktury sieci. Dużo pracy włożono w wykorzystanie treści i połączeń „stron eksperckich”, które są zaufane w wykrywaniu i usuwaniu spamu. Dzięki technikom AI i ML te wzorce łączności są znacznie łatwiejsze do wykrycia i wyeliminowania.
Kiedyś opracowano algorytm znany jako "TrustRank" i na tym się opierał. Oczywiście test na „zaufanie” naprawdę występuje u użytkownika końcowego.
Wyszukiwarki starają się wyeliminować spam i dostarczać wyniki, które naprawdę zaspokajają potrzeby informacyjne użytkowników. Tak więc wzorce dostępu użytkowników do stron dostarczają ogromnej ilości danych, które strony przechodzą test społeczności internetowej (łączność), a następnie te, które przechodzą test użytkownika końcowego (dane dostępowe użytkownika).
Jak już wspomniałem, linki z innych stron internetowych do Twoich stron mogą być postrzegane jako „głos” na Twoją treść. Ale co z milionami użytkowników końcowych, którzy nie mają stron internetowych, na których można by umieścić link – jak mogą głosować?
Robią to z „zaufaniem”, klikając określone wyniki – lub nie klikając na inne.
Chodzi o to, czy użytkownicy końcowi konsumują Twoje treści – bo jeśli tak nie jest – po co Google zwraca je w wynikach po zapytaniu?
Co oznaczają słowa „ekspert”, „autorytet” i „zaufanie” w wyszukiwarce
Podsumowując, nie możesz ogłosić się ekspertem na własnych stronach.
Możesz twierdzić, że jesteś ekspertem lub autorytetem w określonej dziedzinie lub jesteś liderem na świecie w tym czy tamtym.
Ale filozoficznie Google i inne wyszukiwarki mówią: „Kto jeszcze tak myśli?”
Nie chodzi o to, co mówisz o sobie. To jest to, co mówią o Tobie inni (link anchor text). W ten sposób budujesz „reputację” w swojej społeczności.
Co więcej, wskaźniki jakości Google same nie określają, czy Twoje treści są „eksperckie”, czy też „autorytetem”, czy nie. Ich zadaniem jest zbadanie i ustalenie, czy algorytmy Google wykonują swoją pracę.
To tak fascynujący temat i jest o wiele więcej do omówienia. Ale na razie brakuje nam czasu i przestrzeni.
Następnym razem wyjaśnię, jak ważne są uporządkowane dane i jak ważne jest bycie „semantycznie” połączonym w Twojej społeczności internetowej.
Do tego czasu ciesz się złotymi kolorami jesieni, gdy wkraczamy w kolejny sezon z wielką niecierpliwością na kolejną epicką lekturę o wewnętrznym działaniu wyszukiwarek.
Opinie wyrażone w tym artykule są opiniami gościa i niekoniecznie Search Engine Land. Lista autorów personelu znajduje się tutaj.