
Le origini di EAT: contenuto della pagina, analisi dei collegamenti ipertestuali e dati di utilizzo
Pubblicato: 2022-09-13Prevedere il futuro basandosi sulla conoscenza del passato è fondamentale. Tengo sempre d'occhio i progressi tecnologici ma non perdo mai le tracce del passato.
I risultati e le scoperte passate nel campo del recupero delle informazioni (IR) evocano le possibilità di "where to next" nella tecnologia di ricerca.
Questo mi porta quindi a quale impatto avrà sulle tecniche e metodologie di ottimizzazione dei motori di ricerca (SEO) in futuro.
Nella puntata precedente della mia serie SEO "Ritorno al futuro", le tecniche di indicizzazione e ranking delle parole chiave sono state rivisitate: 20 anni dopo, ho concluso mostrando un grafico che spiega qualcosa noto come "problema dell'abbondanza". Questo spesso impedisce alle tecniche di posizionamento delle parole chiave pure (on-page) di posizionare le pagine più autorevoli in cima ai risultati. Rilevante – sì. Ma autorevole?
Per i valutatori della qualità di Google, EAT potrebbe esistere solo da pochi anni. Ma nel campo IR, è sempre stato al centro di come e cosa fanno i motori di ricerca.
In questo articolo, esplorerò fino a che punto sono le competenze, l'autorevolezza e l'affidabilità (EAT) e su cosa si basano effettivamente.
'MANGIARE' 20 anni fa
C'è ancora molta ambiguità nel settore su cosa significhi effettivamente "autorevolezza" in senso SEO. Come fa un sito/pagina a diventare autorevole?
Forse guardare come "autorità" - così come i termini "esperto" e "fiducia" - è entrata nel lessico IR e SEO può darti maggiori informazioni.
Ecco un grafico che ho creato nel 2002, ma questa versione ha un miglioramento rilevante per legare tutto questo insieme.

Userò questo classico grafico di data mining web, ora caratterizzato dalle tre lettere EAT per aiutare a comprendere meglio le sue origini.
EAT di per sé non è un algoritmo, ma:
- L'esperienza si collega direttamente al contenuto della pagina .
- L' autorità si collega direttamente all'analisi del collegamento ipertestuale .
- La fiducia deriva da una combinazione di contenuto della pagina e analisi dei collegamenti ipertestuali, oltre ai dati di accesso degli utenti finali .
Tutti e tre gli aspetti del data mining devono essere combinati in una modalità di meta-ricerca (o ricerca federata) per fornire le pagine più autorevoli per soddisfare le esigenze informative dell'utente finale. In effetti, è una serie di meccanismi di classificazione algoritmica convergenti che si rafforzano a vicenda.
In qualità di membro professionale di lunga data dell'Association for Computing Machinery, la più grande società informatica del mondo, sono orgoglioso di appartenere al gruppo di interesse speciale per il recupero delle informazioni (SIGIR). La mia principale area di interesse all'interno di quel gruppo è l'analisi dei collegamenti ipertestuali e la scienza del posizionamento nei motori di ricerca.
Per me, questa è l'area più affascinante di IR e SEO. Come ho sentito dire in molte conferenze nel corso degli anni: “Non tutti i collegamenti sono uguali. Alcuni sono infinitamente più uguali di altri”.
E questo è un buon punto di partenza per questa prossima lettura epica per gli altri SEO Bravehearts.
L'evoluzione dalle tecniche di classificazione basate su testo agli algoritmi di classificazione basati su collegamenti ipertestuali
Analizziamo rapidamente il motivo fondamentale per cui i collegamenti sono essenziali per tutti i motori di ricerca, non solo per Google.
In primo luogo, l'analisi dei social network ha una storia illustre. Gli ultimi due decenni hanno visto un enorme sviluppo di interesse e fascino nella comunità scientifica sull'idea di reti e teoria delle reti. Come panoramica di base, ciò significa semplicemente uno schema di interconnessioni tra un insieme di cose.
I social network non sono un fenomeno nuovo per aziende come Meta. I legami sociali tra amici sono stati ampiamente studiati per molti anni. Esistono reti economiche, reti di produzione, reti di media e tante altre reti.
Un esperimento nel campo che è diventato molto famoso al di fuori della comunità scientifica è noto come "Sei gradi di separazione", di cui potresti essere a conoscenza.
Il web è una rete di reti. E nel 1998, la struttura dei collegamenti ipertestuali del web divenne di grande interesse per un giovane scienziato chiamato Jon Kleinberg (ora riconosciuto come uno dei principali informatici mondiali) e per un paio di studenti della Stanford University, tra cui Google Larry Page e Sergey Brin . Durante quell'anno, i tre hanno prodotto due dei più influenti algoritmi di classificazione dell'analisi dei collegamenti ipertestuali: HITS (o "Ricerca di argomenti indotta da collegamenti ipertestuali") e PageRank.
Per essere chiari, il web non ha preferenze su un collegamento o un altro. Un collegamento è un collegamento.
Ma per quelli della nascente industria SEO nel 1998, quella prospettiva sarebbe cambiata completamente quando Page e Brin, in un documento che hanno presentato a una conferenza in Australia, hanno fatto questa dichiarazione:
"Intuitivamente, vale la pena dare un'occhiata alle pagine che sono ben citate da molti luoghi del Web."
E poi hanno dato un primo indizio avallando il fatto che ho evidenziato che "non tutti i collegamenti sono uguali" proseguendo con questo:
"Inoltre, vale la pena guardare anche le pagine che hanno forse solo una citazione da qualcosa come la home page di Yahoo."
Quest'ultima affermazione mi ha colpito molto e, come praticante, mi ha tenuto concentrato sullo sviluppo di un approccio più elegante per collegare le tecniche e le pratiche di attrazione nel corso degli anni.
In conclusione di questa puntata, spiegherò qualcosa del mio approccio (che ha avuto un enorme successo) che ritengo cambierà, concettualmente, il modo in cui pensi a ciò che viene definito "link building" e lo cambierà in " costruzione della reputazione”.
Le origini dell'"autorità" alla ricerca
Nella comunità SEO, la parola "autorità" è spesso usata quando si parla di Google. Ma non è da lì che ha avuto origine il termine (ne parleremo più avanti).
Nel documento che i fondatori di Google hanno presentato alla conferenza in Australia, è da notare che, sebbene stessero parlando di un algoritmo di analisi dei collegamenti ipertestuali, non usassero la parola "link" ma usassero la parola "citazione". Questo perché il PageRank si basa sull'analisi delle citazioni.
Spiegata liberamente, questa è l'analisi della frequenza, dei modelli e dei grafici delle citazioni nei documenti (ovvero i collegamenti da un documento all'altro). Un obiettivo tipico sarebbe quello di identificare i documenti più importanti in una collezione.
Il primo esempio di analisi delle citazioni è stato l'esame di reti di articoli scientifici per scoprire le fonti più autorevoli. La sua scienza globale è nota come "bibliometria", che rientra nella categoria dell'analisi dei social network e della teoria delle reti come ho già accennato.
Ecco come l'ho trasposto 20 anni fa nel modo più semplice in assoluto per mostrare come Google visualizzava i dati di collegamento web.
“Alcuni link nelle pagine web sono semplici aiuti alla navigazione per 'sfogliare' un sito. Altri collegamenti possono fornire l'accesso ad altre pagine che aumentano il contenuto della pagina che le contiene. Andrei Broder [Chief Scientist Alta Vista] ha sottolineato che è probabile che l'autore di una pagina Web crei un collegamento da una pagina all'altra a causa della sua rilevanza o importanza: "Sai, la cosa molto interessante del Web è l'ambiente del collegamento ipertestuale che trasporta molte informazioni. Ti dice: "Penso che questa pagina sia buona", perché la maggior parte delle persone di solito elenca buone risorse. Pochissime persone direbbero: "Quelle sono le peggiori pagine che abbia mai visto" e inserirebbero link ad esse nelle proprie pagine!
È più probabile che le pagine di alta qualità con informazioni buone, chiare e concise abbiano molti collegamenti che puntano ad esse. Considerando che le pagine di bassa qualità avranno meno collegamenti o del tutto assenti. L'analisi dei collegamenti ipertestuali può migliorare significativamente la pertinenza dei risultati di ricerca. Tutti i principali motori di ricerca ora utilizzano alcuni tipi di algoritmi di analisi dei link.

“Utilizzando il principio di citazione/co-citazione utilizzato nella bibliometria convenzionale, gli algoritmi di analisi dei collegamenti ipertestuali possono formulare uno o entrambi questi presupposti di base:
• Un collegamento ipertestuale dalla pagina 'a' alla pagina 'b' è una raccomandazione della pagina 'b' da parte dell'autore della pagina 'a.'
• Se la pagina 'a' e la pagina 'b' sono collegate da un collegamento ipertestuale, allora potrebbero essere sullo stesso argomento.
Gli algoritmi basati su collegamenti ipertestuali utilizzano anche un grafico di co-citazione non orientato. A e B sono collegati da un bordo non orientato, se e solo se esiste una terza pagina C che collega sia ad A che a B.
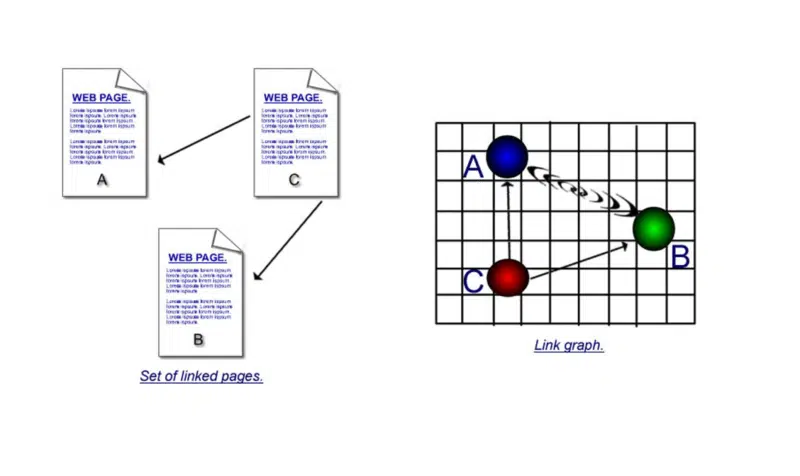
Quella seconda parte aveva una spiegazione molto più lunga nel libro. Ma poiché è un po 'confuso, ne darò uno davvero semplicistico qui.
È importante comprendere i punti di forza sia della citazione che della co-citazione.
Nella prima illustrazione, ci sono collegamenti diretti: una pagina utilizza un collegamento ipertestuale per connettersi a un'altra. Ma se la pagina 'c' si collega a 'a' e 'b' e poi la pagina 'd' si collega a 'a' e 'b' e poi la pagina 'e' e così via, quello che puoi presumere è che, sebbene la pagina "a" e la pagina "b" non si colleghino direttamente l'una all'altra, poiché sono citate così tante volte, deve esserci una connessione tra di loro.
Quale sarebbe un esempio di vita reale?
Bene, liste per cominciare. Pagine con i laptop più venduti della "top ten", i personaggi sportivi della "top ten" o le rock star, puoi vedere come la co-citazione sia un fattore importante in questi tipi di pagine.
Allora, dove entra in gioco questo algoritmo HITS di cui potresti non aver mai sentito parlare?
C'è una storia che nello stesso momento in cui Page e Brin stavano lavorando al loro algoritmo PageRank, Kleinberg stava analizzando i risultati sui principali motori di ricerca della giornata, incluso quello in più rapida crescita, Alta Vista. Pensava che fossero tutti piuttosto poveri e producessero risultati molto scarsi in termini di rilevanza per la query.
Ha cercato il termine "produttore automobilistico giapponese" ed è rimasto molto impressionato nel notare che nessuno dei nomi più importanti come Toyota e Nissan è apparso da nessuna parte nei risultati, per non parlare di dove dovrebbero essere in cima.
Dopo aver visitato i siti web delle principali case costruttrici, ha notato una cosa che avevano tutte in comune: nessuna di esse aveva la dicitura “produttore automobilistico giapponese” nel testo di nessuna pagina del sito.
In effetti, ha cercato il termine "motore di ricerca" e anche Alta Vista non è apparso nei propri risultati per lo stesso motivo. Questo lo ha portato a iniziare a concentrarsi sulla connettività delle pagine Web per dare un'idea di quanto fossero rilevanti (e importanti) per una determinata query.
Quindi, ha sviluppato l'algoritmo HITS, che ha preso le prime mille o più pagine dopo una ricerca per parole chiave su Alta Vista e poi le ha classificate in base alla loro interconnettività.
In effetti, stava usando la struttura dei collegamenti per formare una rete o una "comunità" attorno all'argomento della parola chiave e, all'interno di quella rete, identificare ciò che ha chiamato "Hub e autorità".
È qui che la parola "autorità" è entrata nel lessico SEO. Il titolo della tesi di Kleinberg era "Fonti autorevoli in un ambiente con collegamenti ipertestuali".

Le pagine "Hub" sono quelle con molti collegamenti che collegano alle "autorità" su un determinato argomento. Più hub si collegano a una determinata autorità, maggiore è l'autorità che ottiene. Anche questo si rafforza a vicenda. Un buon hub può anche essere una buona autorità e viceversa.
Come al solito, nessun premio per le mie capacità di creazione grafica tanti anni fa, ma è così che l'ho visualizzato nel 2002. Gli hub (rossi) sono quelli che si collegano a molte "autorità" (blu) all'interno delle comunità web.
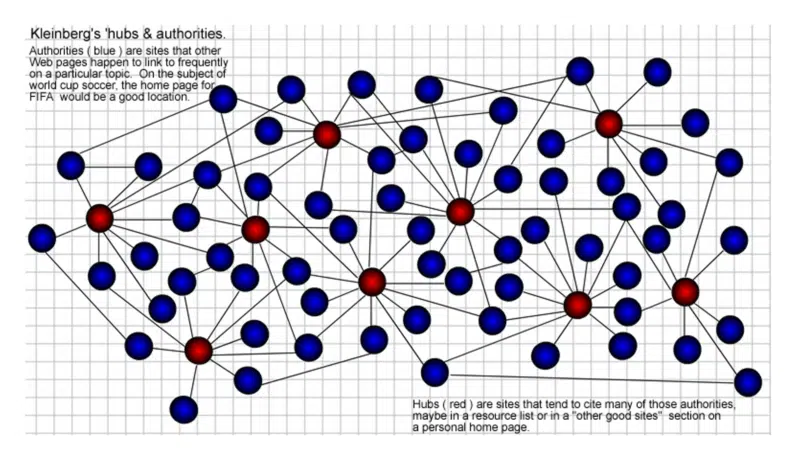
Allora, cos'è una "comunità web" allora?
Una comunità di dati di pagine Web si riferisce a un insieme di pagine Web che ha le proprie strutture logiche e semantiche.
La comunità delle pagine web considera ogni pagina web come un intero oggetto piuttosto che scomporre la pagina web in informazioni e rivela relazioni reciproche tra i dati web interessati.
È flessibile nel riflettere la natura dei dati web, come la dinamica e l'eterogeneità. Nel grafico seguente, ogni colore rappresenta una comunità diversa sul web.
Ho sempre sostenuto che i link attratti dall'interno della tua comunità web hanno più prestigio di quelli dall'esterno della tua comunità.
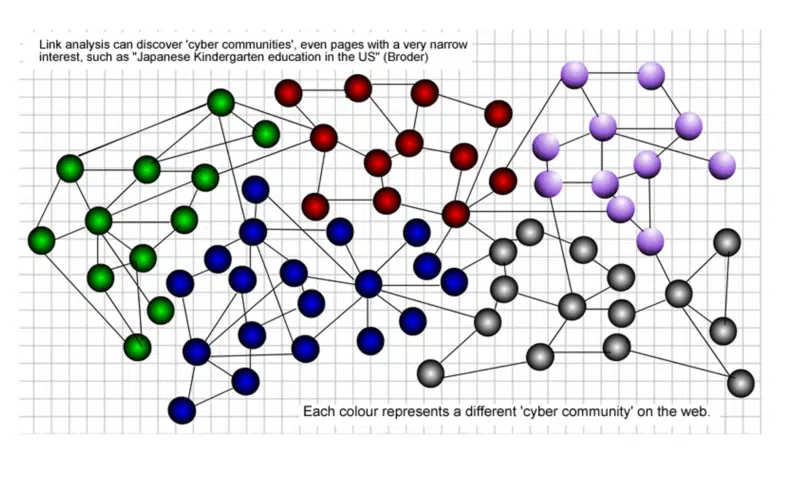
Ho spiegato di più sull'importanza di identificare le comunità in questo modo 20 anni fa:
"E per quanto riguarda i dati di collegamento: le pagine che puntano (collegano) ad altre pagine possono fornire un'enorme quantità di informazioni sulla struttura, le comunità e la gerarchia (in gran parte indicate come la "topologia" del web). Utilizzando questa metodologia i motori di ricerca possono tentare di identificare la struttura intellettuale (topologia) e le reti sociali (comunità) del web. Tuttavia, ci sono molti problemi con il ridimensionamento utilizzando metodi di citazione e analisi di co-citazione per gestire centinaia e centinaia di milioni di documenti con miliardi di citazioni (collegamenti ipertestuali).
Il “Cyberspace” (come nel web) ha già le sue comunità e quartieri. OK – meno reale nel senso di dove vivi e con chi esci. Ma c'è una “sociologia” nel web. Gli amanti della musica di diverse culture e background (e fusi orari) diversi non vivono nello stesso quartiere geografico, ma quando sono collegati tra loro sul web sono una vera comunità. Proprio come gli amanti dell'arte e le persone di ogni ceto sociale che pubblicano le loro informazioni sul Web e formano queste comunità o "collegano i quartieri" nel "cyberspazio"."
Ricevi la newsletter quotidiana su cui fanno affidamento i marketer.
Vedi termini.
PageRank vs. HITS: qual è la differenza?
Ci sono molte somiglianze negli algoritmi PageRank e HITS nel modo in cui analizzano l'interconnettività delle pagine web per creare un meccanismo di ranking.
Ma c'è anche una differenza significativa.
PageRank è un algoritmo di ranking indipendente dalle parole chiave, mentre HITS è dipendente dalle parole chiave.
Con PageRank, ottieni il tuo punteggio di autorità indipendentemente dalla comunità poiché originariamente era un punteggio globale statico.
Mentre HITS dipende dalle parole chiave, il punteggio di autorità è costruito attorno alla parola chiave/frase che unisce la comunità. Ci vuole troppo tempo e oltre lo scopo di questa puntata per entrare nei dettagli, quindi non andrò troppo in profondità qui.
L'algoritmo che ha introdotto il termine 'esperto'
Questo algoritmo Hilltop è estremamente importante ma riceve la minima attenzione. E questo perché, nei circoli professionali, c'è una forte convinzione che sia stato fuso nei processi algoritmici di Google nel 2003 quando si è verificato il famigerato aggiornamento della Florida.
Un vero punto di svolta, l'algoritmo Hilltop è un derivato molto più vicino di HITS ed è stato sviluppato nel 1999 (sì, più o meno nello stesso periodo) da Krishna Bharat.
All'epoca lavorava per il DEC Systems Research Center, proprietario del motore di ricerca AltaVista. Il suo documento di ricerca era intitolato "Quando gli esperti sono d'accordo: utilizzare esperti non affiliati per classificare argomenti popolari". Ed è così che ha descritto Hilltop.
"Proponiamo un nuovo schema di classificazione per argomenti popolari che colloca le pagine più autorevoli sull'argomento della query in cima alla classifica. Il nostro algoritmo opera su un indice speciale di "documenti esperti". Questi sono un sottoinsieme delle pagine sul WWW identificato come directory di collegamenti a fonti non affiliate su argomenti specifici. I risultati sono classificati in base alla corrispondenza tra la query e il testo descrittivo pertinente per i collegamenti ipertestuali sulle pagine degli esperti che puntano a una determinata pagina dei risultati."
Sì, è qui che il termine "esperto" è entrato nel lessico SEO. Nota sia nel titolo del documento che nella descrizione del processo che la tua pagina è considerata una pagina di esperti quando altri si collegano ad essa. Quindi, i termini "esperto" e "autorità" possono essere usati in modo intercambiabile.
Un'altra cosa che dovrebbe essere annotata con attenzione – ed è l'uso del termine "non affiliato" nella descrizione dell'algoritmo. Ciò potrebbe dare un'idea del motivo per cui molti operatori di marketing di affiliazione sono stati colpiti così duramente con l'aggiornamento della Florida.
Un'altra cosa importante da notare è che spesso nella comunità SEO, le persone fanno riferimento a "siti di autorità" (o talvolta "autorità di dominio" che non sono nemmeno una cosa). Ma il fatto è che i motori di ricerca restituiscono pagine Web nei loro risultati a seguito di una query, non siti Web.
Più link attiri da altre pagine di "esperti", maggiore è l'autorità che guadagni e più "prestigio" puoi aggiungere a un'altra pagina di esperti collegandoti ad essa. Questa è la bellezza di costruire una "reputazione" all'interno della comunità, non essere semplicemente un raccoglitore di link.
Ogni volta che spiego l'importanza di essere riconosciuto come un esperto all'interno di una comunità web, come ho fatto negli ultimi due decenni, so che a volte le persone hanno difficoltà a visualizzare come sarebbe.
Fortunatamente, nel mio lavoro di ricerca tanti anni fa, mi sono imbattuto in un altro algoritmo sviluppato da due scienziati giapponesi, Masashi Toyoda e Kentarou Fukuchi. Il loro approccio era anche la comunità web, ma sono stati in grado di produrre i loro risultati visivamente.
L'esempio che ho preso del loro è stato quello che hanno usato quando hanno costruito una comunità web attorno ai produttori di computer. Ecco una piccola parte dell'output che ho utilizzato durante le sessioni della conferenza per aiutare tutti a farsi un'idea più tangibile del concetto.
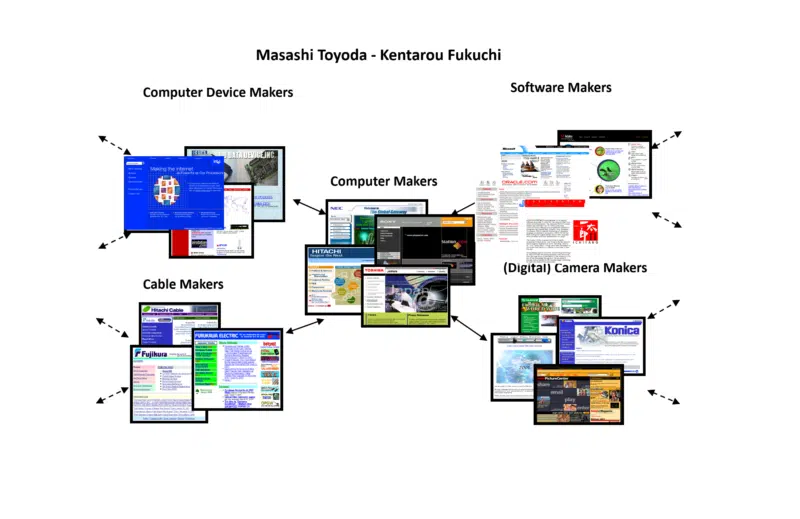
Nota come la comunità web includa non solo produttori di computer, ma anche produttori di dispositivi, produttori di cavi, produttori di software, ecc. Questo indica quanto può essere ampia e profonda una comunità web (oltre che ristretta e superficiale).
Come è nata la "fiducia".
C'è molto che va nella "competenza" e nell'"autorevolezza", e non meno nella "fiducia".
Anche la "fiducia" rientra nell'area dell'analisi dei collegamenti ipertestuali e della struttura del web. È stato dedicato molto lavoro all'utilizzo del contenuto e della connettività di "pagine di esperti" che sono affidabili per scoprire ed eliminare lo spam. Con le tecniche di IA e ML, questi modelli di connettività sono molto più facili da individuare ed eliminare.
In passato è stato sviluppato un algoritmo noto come "TrustRank" ed è su questo che si basava. Naturalmente, il test acido per la "fiducia" si verifica davvero con l'utente finale.
I motori di ricerca si sforzano di eliminare lo spam e fornire risultati che soddisfino veramente le esigenze di informazione degli utenti. Pertanto, i modelli di accesso degli utenti alle pagine forniscono un'enorme quantità di dati su quali pagine superano il test della comunità Web (connettività) e quindi quelle che superano il test dell'utente finale (dati di accesso dell'utente).
Come ho accennato, i collegamenti da altre pagine Web alle tue pagine possono essere visti come un "voto" per i tuoi contenuti. Ma che dire dei milioni e milioni di utenti finali che non hanno pagine web per darti un link: come possono votare?
Lo fanno con la loro "fiducia" facendo clic su determinati risultati o non facendo clic su altri.
Si tratta solo di sapere se gli utenti finali stanno consumando i tuoi contenuti, perché in caso contrario, qual è lo scopo di Google che li restituisce nei risultati a seguito di una query?
Cosa significano "esperto", "autorità" e "fiducia" nella ricerca
Per riassumere, non puoi dichiararti un esperto sulle tue stesse pagine.
Puoi "affermare" di essere un esperto o un'autorità in un determinato campo o il leader mondiale di questo o quello.
Ma filosoficamente, Google e altri motori di ricerca stanno dicendo: "Chi altro la pensa così?"
Non è quello che dici di te stesso. È ciò che le altre persone dicono di te (link anchor text). È così che costruisci una "reputazione" nella tua comunità.
Inoltre, i valutatori della qualità di Google non determinano da soli se i tuoi contenuti sono "esperti" o se sei un'"autorità" o meno. Il loro compito è esaminare e determinare se gli algoritmi di Google stanno facendo il loro lavoro.
Questo è un argomento così affascinante e c'è molto altro da trattare. Ma per ora siamo fuori dal tempo e dallo spazio.
La prossima volta spiegherò quanto siano importanti i dati strutturati e l'essere connessi "semanticamente" all'interno della tua comunità web.
Fino ad allora, goditi i colori dorati dell'autunno mentre scivoliamo in un'altra stagione con grande attesa per la prossima lettura epica sul funzionamento interno dei motori di ricerca.
Le opinioni espresse in questo articolo sono quelle dell'autore ospite e non necessariamente di Search Engine Land. Gli autori dello staff sono elencati qui.