
EAT'nin kökenleri: Sayfa içeriği, köprü analizi ve kullanım verileri
Yayınlanan: 2022-09-13Geçmişin bilgisine dayanarak geleceği tahmin etmek esastır. Teknolojik gelişmeleri her zaman yakından takip ederim ama geçmişin izini asla kaybetmem.
Bilgi alma (IR) alanındaki geçmiş başarılar ve atılımlar, arama teknolojisinde “nereye doğru” olasılıklarını çağrıştırıyor.
Bu da beni gelecekte arama motoru optimizasyonu (SEO) teknikleri ve metodolojileri üzerinde ne gibi bir etkiye sahip olacağına yönlendiriyor.
SEO “Geleceğe Dönüş” serimin bir önceki bölümünde, İndeksleme ve anahtar kelime sıralama teknikleri tekrar gözden geçirildi: 20 yıl sonra, “bolluk sorunu” olarak bilinen bir şeyi açıklayan bir grafik göstererek bitirdim. Bu, saf anahtar kelime sıralama tekniklerinin (sayfada) daha yetkili sayfaları sonuçların en üstüne yerleştirmesini sıklıkla engeller. İlgili - evet. Ama yetkili?
Google kalite değerlendiricileri için EAT yalnızca birkaç yıldır piyasada olabilir. Ancak IR alanında, her zaman arama motorlarının nasıl ve ne yaptığının merkezinde yer almıştır.
Bu makalede, uzmanlık, otoriterlik ve güvenilirliğin (EAT) ne kadar geriye gittiğini ve aslında neye dayandıklarını keşfedeceğim.
20 yıl önce 'YİYİN'
Sektörde, SEO anlamında “yetkililiğin” gerçekte ne anlama geldiği konusunda hala oldukça fazla belirsizlik var. Bir site/sayfa nasıl yetkili hale gelir?
Belki de “yetki”nin yanı sıra “uzman” ve “güven” terimlerinin IR ve SEO sözlüğüne nasıl girdiğine bakmak size daha fazla fikir verebilir.
İşte 2002'de oluşturduğum bir grafik, ancak bu sürümde tüm bunları birbirine bağlamak için ilgili bir geliştirme var.

Kökenlerinin daha iyi anlaşılmasına yardımcı olmak için şimdi üç harf EAT içeren bu klasik web veri madenciliği grafiğini kullanacağım.
EAT kendi başına bir algoritma değildir, ancak:
- Uzmanlık doğrudan sayfa içeriğine bağlanır.
- Otorite doğrudan köprü analizine bağlanır.
- Güven , sayfa içeriği ve köprü analizinin yanı sıra son kullanıcı erişim verilerinin birleşiminden gelir.
Üç veri madenciliği yönünün tümü, son kullanıcının bilgi ihtiyaçlarını karşılamak için en yetkili sayfaları sağlamak için bir meta arama (veya birleşik arama) tarzında birleştirilmelidir. Etkili bir şekilde, karşılıklı olarak birbirini güçlendiren bir dizi yakınsak algoritmik sıralama mekanizmasıdır.
Dünyanın en büyük bilgi işlem topluluğu olan Bilgisayar Makineleri Derneği'nin uzun süredir profesyonel bir üyesi olarak, bilgi alma özel ilgi grubuna (SIGIR) ait olmaktan gurur duyuyorum. Bu gruptaki ana odak alanım, köprü analizi ve arama motoru sıralama bilimidir.
Benim için bu, IR ve SEO'nun en büyüleyici alanı. Yıllar boyunca birçok konferansta söylediğim gibi: “Bütün bağlantılar eşit değildir. Bazıları diğerlerinden sonsuz derecede daha eşittir.”
Ve bu, SEO Cesur Yürek dostları için bir sonraki epik okuma için iyi bir başlangıç noktası.
Metin tabanlı sıralama tekniklerinden köprü tabanlı sıralama algoritmalarına geçiş
Bağlantıların yalnızca Google için değil, tüm arama motorları için gerekli olmasının temel nedenini hızlıca ele alalım.
İlk olarak, sosyal ağ analizinin seçkin bir geçmişi vardır. Son yirmi yılda, bilim camiasında ağlar ve ağ teorisi fikrine karşı büyük ölçüde gelişen bir ilgi ve hayranlık görüldü. Temel bir genel bakış olarak, bu basitçe bir dizi şey arasında bir ara bağlantı modeli anlamına gelir.
Sosyal ağlar, Meta gibi şirketler için yeni bir fenomen değil. Arkadaşlar arasındaki sosyal bağlar uzun yıllardır geniş çapta incelenmiştir. Ekonomik ağlar, üretim ağları, medya ağları ve daha birçok ağ mevcuttur.
Bu alanda bilim camiasının dışında çok ünlü hale gelen bir deney, farkında olabileceğiniz “Altı Derece Ayrılık” olarak bilinir.
Web bir ağlar ağıdır. Ve 1998'de, web'in hiper bağlantı yapısı, Jon Kleinberg (şimdi dünyanın önde gelen bilgisayar bilimcilerinden biri olarak kabul ediliyor) adlı genç bir bilim adamı ve Google Larry Page ve Sergey Brin de dahil olmak üzere Stanford Üniversitesi'nden birkaç öğrenci için büyük ilgi gördü. . O yıl boyunca, üçü en etkili köprü analizi sıralama algoritmalarından ikisini üretti – HITS (veya “Köprü Kaynaklı Konu Araması”) ve PageRank.
Açık olmak gerekirse, web'in bir bağlantı veya başka bir tercihi yoktur. Bir bağlantı bir bağlantıdır.
Ancak 1998'de yeni ortaya çıkan SEO endüstrisindekiler için, Avustralya'daki bir konferansta sundukları bir makalede Page ve Brin şu ifadeyi yaptıklarında bu bakış açısı tamamen değişecekti:
"Sezgisel olarak, web'deki birçok yerden iyi alıntılanmış sayfalar bakmaya değer."
Ardından, şunu izleyerek “tüm bağlantıların eşit olmadığını” vurguladığım gerçeğini onaylayan erken bir ipucu verdiler:
"Ayrıca, Yahoo ana sayfası gibi bir şeyden belki de yalnızca bir alıntıya sahip olan sayfalar da genellikle bakmaya değer."
Bu son ifade bende gerçek bir akor yarattı ve bir uygulayıcı olarak, yıllar boyunca cazibe teknikleri ve uygulamaları arasında bağlantı kurmak için daha zarif bir yaklaşım geliştirmeye odaklanmamı sağladı.
Bu bölümün sonunda, kavramsal olarak, “bağlantı kurma” olarak adlandırılan şeyi düşünme şeklinizi değiştireceğini ve bunu “ itibar inşası.”
Aramada 'otoritenin' kökenleri
SEO topluluğunda, Google hakkında konuşurken genellikle “otorite” kelimesi kullanılır. Ancak bu terimin ortaya çıktığı yer burası değil (daha sonraları).
Google kurucularının Avustralya'daki konferansta sundukları makalede, bir köprü analiz algoritmasından bahsetmelerine rağmen, "bağ" kelimesini kullanmamaları, "alıntı" kelimesini kullanmaları dikkat çekicidir. Bunun nedeni, PageRank'in alıntı analizine dayanmasıdır.
Gevşek bir şekilde açıklanmıştır, bu, belgelerdeki alıntıların sıklığının, modellerinin ve grafiklerinin analizidir (diğer bir deyişle, bir belgeden diğerine bağlantılar). Tipik bir amaç, bir koleksiyondaki en önemli belgeleri belirlemek olacaktır.
Atıf analizinin en eski örneği, en güvenilir kaynakları keşfetmek için bilimsel makale ağlarının incelenmesiydi. Kapsayıcı bilimi, daha önce değindiğim gibi sosyal ağ analizi ve ağ teorisi kategorisine uyan “bibliyometri” olarak bilinir.
Bunu 20 yıl önce Google'ın web bağlantı verilerini nasıl gördüğünü göstermek için en basit şekilde aktardım.
“Web sayfalarındaki bazı bağlantılar, bir siteye 'göz atmak' için yalnızca gezinme yardımcılarıdır. Diğer bağlantılar, onları içeren sayfanın içeriğini artıran diğer sayfalara erişim sağlayabilir. Andrei Broder [Baş Bilim Adamı Alta Vista], bir web sayfası yazarının alaka düzeyi veya önemi nedeniyle bir sayfadan diğerine bağlantı oluşturmasının muhtemel olduğuna dikkat çekti: bir sürü bilgi. Size şunu söyler: 'Bu sayfanın iyi olduğunu düşünüyorum' – çünkü çoğu insan genellikle iyi kaynakları listeler. Çok az insan 'Gördüğüm en kötü sayfalar bunlar' deyip kendi sayfalarına linkler koyardı!
İyi, açık ve özlü bilgilere sahip yüksek kaliteli sayfaların kendilerine işaret eden birçok bağlantıya sahip olma olasılığı daha yüksektir. Düşük kaliteli sayfalarda ise daha az bağlantı bulunur veya hiç yoktur. Köprü analizi, arama sonuçlarının alaka düzeyini önemli ölçüde artırabilir. Tüm büyük arama motorları artık bir tür bağlantı analizi algoritması kullanıyor.”

“Geleneksel bibliyometride kullanılan atıf/ortak atıf ilkesini kullanan köprü analizi algoritmaları, bu temel varsayımlardan birini veya her ikisini birden yapabilir:
• 'a' sayfasından 'b' sayfasına bir köprü, 'a' sayfasının yazarı tarafından 'b' sayfasının önerisidir.
• 'a' sayfası ve 'b' sayfası bir köprü ile birbirine bağlıysa, bunlar aynı konuda olabilir.
Köprü tabanlı algoritmalar ayrıca yönlendirilmemiş bir ortak alıntı grafiği kullanır. A ve B, yalnızca hem A hem de B'ye bağlanan üçüncü bir C sayfası varsa, yönlendirilmemiş bir kenarla bağlanır.
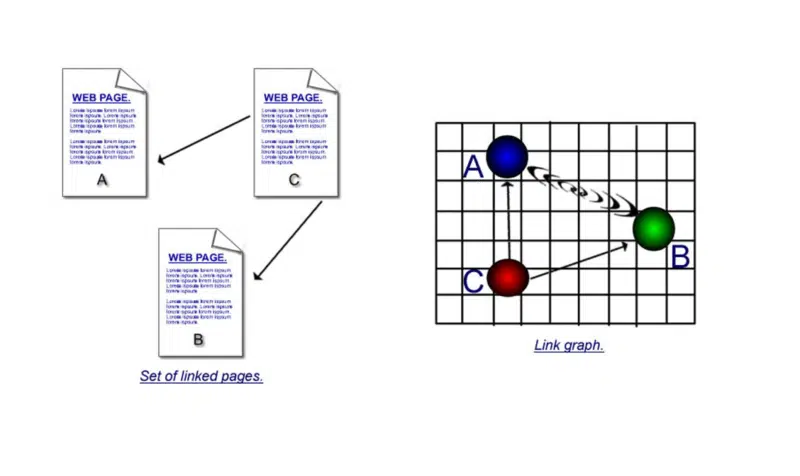
Bu ikinci bölümün kitapta çok daha uzun bir açıklaması vardı. Ama biraz kafa karıştırıcı olduğu için burada gerçekten basit bir tane vereceğim.
Hem alıntı hem de ortak alıntının güçlü yanlarını anlamak önemlidir.
İlk resimde, doğrudan bağlantılar vardır - bir sayfa diğerine bağlanmak için bir köprü kullanır. Ama eğer 'c' sayfası 'a' ve 'b'ye bağlanıyorsa ve sonra 'd' sayfası 'a' ve 'b'ye bağlanıyorsa ve sonra 'e' sayfasına ve böyle devam ediyorsa, şunu varsayabilirsiniz, 'a' sayfası ve 'b' sayfası birbirine doğrudan köprü oluşturmasa da, birçok kez birlikte alıntı yapıldıkları için aralarında bir bağlantı olmalı.
Bunun gerçek hayattan bir örneği ne olabilir?
Başlangıç için listeler. "İlk on" en çok satan dizüstü bilgisayarı, "ilk on" spor şahsiyetini veya rock yıldızlarını içeren sayfalar, bu tür sayfalarda ortak alıntının ne kadar büyük bir faktör olduğunu görebilirsiniz.
Peki hiç duymamış olabileceğiniz bu HITS algoritması nerede devreye giriyor?
Page ve Brin'in PageRank algoritmaları üzerinde çalışırken, Kleinberg'in aralarında en hızlı büyüyen Alta Vista da dahil olmak üzere günün en iyi arama motorlarındaki sonuçları analiz ettiğine dair bir hikaye var. Hepsinin oldukça zayıf olduğunu ve sorguyla ne kadar alakalı oldukları konusunda çok yetersiz sonuçlar ürettiğini düşündü.
"Japon otomotiv üreticisi" terimini aradı ve Toyota ve Nissan gibi önemli isimlerin hiçbirinin, bırakın en üstte olmaları gereken yeri, sonuçların hiçbir yerinde görünmediğini fark edince çok etkilenmedi.
Büyük üreticilerin web sitelerini ziyaret ettikten sonra, hepsinde ortak bir nokta olduğunu fark etti: Hiçbir sitenin sayfalarındaki metinde “Japon otomotiv üreticisi” kelimeleri yoktu.
Aslında, "arama motoru" terimini aradı ve Alta Vista bile aynı nedenle kendi sonuçlarında çıkmadı. Bu, belirli bir sorguyla ne kadar alakalı (ve önemli) olduklarına dair bir ipucu vermek için web sayfalarının bağlanabilirliğine başlamasına ve odaklanmasına neden oldu.
Böylece, Alta Vista'da bir anahtar kelime aramasının ardından ilk bin veya daha fazla sayfayı alan ve daha sonra bunları bağlantılarına göre sıralayan HITS algoritmasını geliştirdi.
Anahtar kelime konusu etrafında bir ağ veya "topluluk" oluşturmak için bağlantı yapısını etkili bir şekilde kullanıyordu ve bu ağ içinde "Merkezler ve Yetkililer" adını verdiği şeyi tanımlıyordu.
İşte burada “otorite” kelimesi SEO sözlüğüne girdi. Kleinberg'in tezinin başlığı “Hücre Bağlantılı Bir Ortamda Yetkili Kaynaklar” idi.
“Hub” sayfaları, belirli bir konuda “yetkililere” bağlanan birçok bağlantıya sahip sayfalardır. Belirli bir otoriteye bağlanan daha fazla hub, daha fazla yetki alır. Bu da birbirini pekiştiriyor. İyi bir merkez aynı zamanda iyi bir otorite olabilir ve bunun tersi de geçerlidir.
Her zaman olduğu gibi, yıllar önce grafik oluşturma becerilerim için hiçbir ödül yoktu, ancak 2002'de bunu böyle görselleştirdim. Merkezler (kırmızı) web toplulukları içindeki birçok "yetkiliye" (mavi) bağlananlardır.

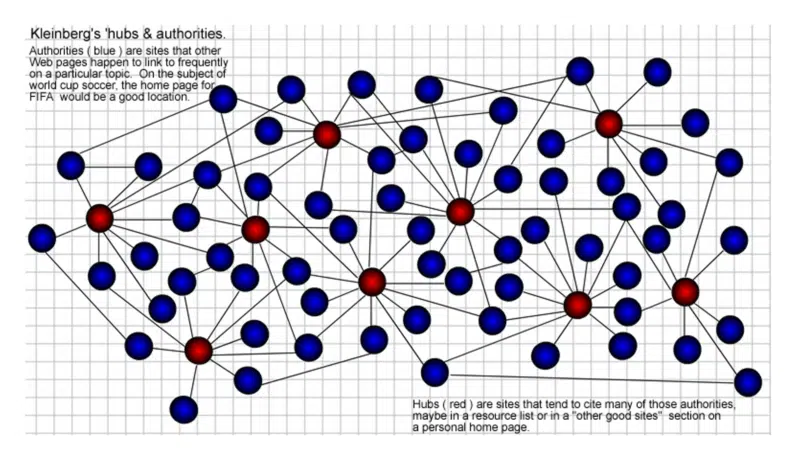
Peki, o zaman “web topluluğu” nedir?
Bir web sayfası veri topluluğu, kendi mantıksal ve anlamsal yapılarına sahip bir dizi web sayfası anlamına gelir.
Web sayfası topluluğu, web sayfasını bilgi parçalarına ayırmak yerine her web sayfasını bir bütün olarak ele alır ve ilgili web verileri arasındaki karşılıklı ilişkileri ortaya çıkarır.
Dinamikler ve heterojenlik gibi web verilerinin doğasını yansıtmada esnektir. Aşağıdaki grafikte, her renk web'de farklı bir topluluğu temsil etmektedir.
Kendi web topluluğunuzdan gelen bağlantıların, topluluğunuzun dışındakilerden daha fazla prestij taşıdığını her zaman savundum.
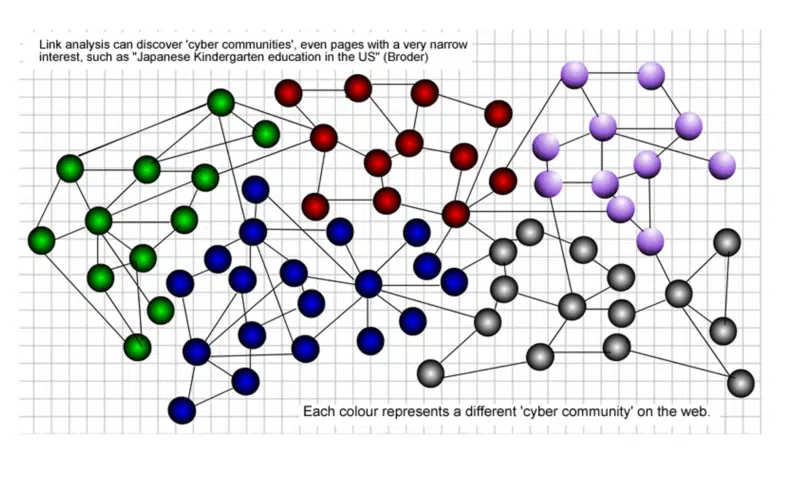
20 yıl önce toplulukları bu şekilde tanımlamanın önemi hakkında daha fazla bilgi verdim:
"Ve bağlantı verilerine gelince: diğer sayfaları işaret eden (bağlantı veren) sayfalar yapı, topluluklar ve hiyerarşi (büyük ölçüde web'in "topolojisi" olarak anılır) hakkında çok büyük miktarda bilgi sağlayabilir. Bu metodolojiyi kullanarak arama motorları, web'in entelektüel yapısını (topoloji) ve sosyal ağlarını (toplulukları) belirlemeye çalışabilir. Bununla birlikte, milyarlarca alıntı (köprü) içeren yüzlerce ve yüz milyonlarca belgeyle başa çıkmak için alıntı ve ortak alıntı analizi yöntemlerini kullanarak ölçeklendirmede birçok sorun vardır.
“Siberuzay” (web'de olduğu gibi) zaten kendi topluluklarına ve mahallelerine sahiptir. Tamam – nerede yaşadığınız ve kiminle takıldığınızla ilgili olarak daha az gerçek. Ama internette bir “sosyoloji” var. Farklı kültürlerden ve farklı geçmişlerden (ve zaman dilimlerinden) müzik severler aynı coğrafi mahallede yaşamıyorlar - ancak web üzerinde birbirlerine bağlandıklarında çok fazla topluluk oluyorlar. Tıpkı sanatseverler ve her kesimden, bilgilerini internete gönderen ve bu toplulukları oluşturan veya “siber uzayda” “mahalleleri birbirine bağlayan” insanlar gibi.”
Arama pazarlamacılarının güvendiği günlük bültenleri alın.
Şartlara bakın.
PageRank ile HITS arasındaki fark nedir?
Hem PageRank hem de HITS algoritmalarında, bir sıralama mekanizması oluşturmak için web sayfalarının birbirine bağlılığını analiz etme şekillerinde birçok benzerlik vardır.
Ama aynı zamanda önemli bir fark var.
PageRank, anahtar kelimeden bağımsız bir sıralama algoritmasıdır, HITS ise anahtar kelimeye bağlıdır.
PageRank ile, başlangıçta statik bir küresel puan olduğu için topluluktan bağımsız olarak yetki puanınızı alırsınız.
HITS anahtar kelimeye bağlıyken, otorite puanı topluluğu bir araya getiren anahtar kelime/ifade etrafında oluşturulur. Ayrıntılara girmek çok uzun sürüyor ve bu bölümün kapsamını aşıyor, bu yüzden burada fazla derine inmeyeceğim.
'Uzman' terimini tanıtan algoritma
Bu Hilltop algoritması son derece önemlidir, ancak en az dikkati çeker. Ve bunun nedeni, profesyonel çevrelerde, kötü şöhretli Florida güncellemesinin gerçekleştiği 2003 yılında Google'ın algoritmik süreçlerine dahil edildiğine dair güçlü bir inanç var.
Gerçek bir oyun değiştirici olan Hilltop algoritması, HITS'in çok daha yakın bir türevidir ve 1999'da (evet, aynı zamanda) Krishna Bharat tarafından geliştirilmiştir.
O sırada AltaVista arama motorunun sahibi olan DEC Systems Research Center için çalışıyordu. Araştırma makalesinin başlığı "Uzmanlar Kabul Ettiğinde: Popüler Konuları Sıralamak için İlişkili Olmayan Uzmanları Kullanmak". Ve Hilltop'u böyle tanımladı.
"Sorgu konusundaki en yetkili sayfaları sıralamanın en üstüne yerleştiren popüler konular için yeni bir sıralama şeması öneriyoruz. Algoritmamız özel bir "uzman belgeleri" dizini üzerinde çalışır. Bunlar, WWW'deki sayfaların bir alt kümesidir. belirli konularda bağlantılı olmayan kaynaklara bağlantı dizinleri olarak tanımlanır. Sonuçlar, belirli bir sonuç sayfasını işaret eden uzman sayfalarındaki köprüler için sorgu ile ilgili açıklayıcı metin arasındaki eşleşmeye göre sıralanır."
Evet, "uzman" teriminin SEO sözlüğüne girdiği yer burasıdır. Hem makalenin başlığında hem de sürecin açıklamasında, başkaları ona bağlantı verdiğinde sayfanızın bir uzman sayfası olarak kabul edildiğine dikkat edin. Bu nedenle, "uzman" ve "yetki" terimleri birbirinin yerine kullanılabilir.
Dikkatlice not edilmesi gereken bir diğer şey de algoritmanın açıklamasında "bağlı olmayan" teriminin kullanılmasıdır. Bu, birçok bağlı kuruluş pazarlamacısının Florida güncellemesinden neden bu kadar kötü etkilendiğine dair bir ipucu verebilir.
Unutulmaması gereken bir diğer önemli nokta ise, SEO topluluğunda insanların sıklıkla "yetkili sitelere" (veya bazen bir şey bile olmayan "etki alanı otoritesine") atıfta bulunmasıdır. Ancak gerçek şu ki, arama motorları sonuçlarında bir sorgunun ardından web sitelerini değil, web sayfalarını döndürür.
Diğer "uzman" sayfalardan ne kadar çok bağlantı çekerseniz, o kadar fazla otorite kazanırsınız ve başka bir uzman sayfasına bağlantı vererek o kadar "prestij" ekleyebilirsiniz. Bu, yalnızca bir bağlantı toplayıcı olmanın değil, topluluk içinde bir "itibar" inşa etmenin güzelliğidir.
Son yirmi yıldır yaptığım gibi, bir web topluluğu içinde bir uzman olarak tanınmanın önemini ne zaman açıklasam, insanların bazen bunun nasıl görüneceğini hayal etmekte zorlandıklarını biliyorum.
Neyse ki, yıllar önce araştırma çalışmalarımda iki Japon bilim adamı Masashi Toyoda ve Kentarou Fukuchi tarafından geliştirilen başka bir algoritmaya rastladım. Yaklaşımları da web topluluğuydu, ancak sonuçlarını görsel olarak çıkarabildiler.
Aldığım örnek, bilgisayar üreticileri etrafında bir web topluluğu kurarken kullandıkları örnekti. İşte herkesin kavram hakkında daha somut bir fikir edinmesine yardımcı olmak için konferans oturumlarında kullanmak üzere kaldırdığım çıktının küçük bir kısmı.
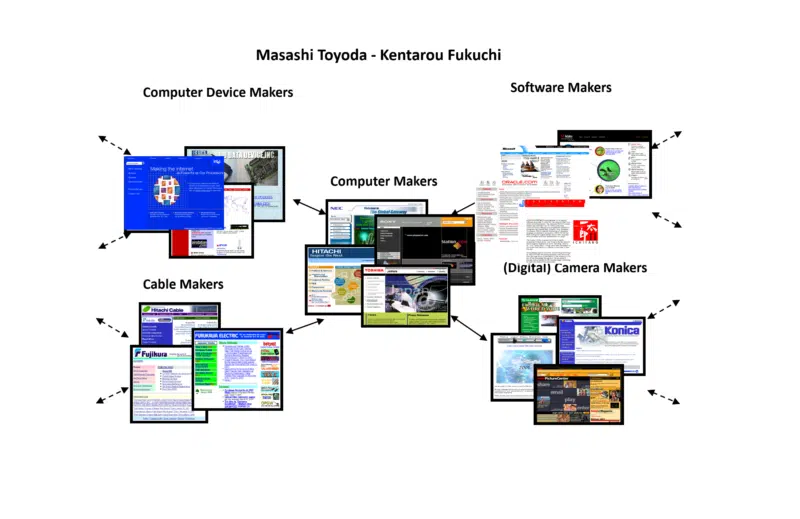
Web topluluğunun yalnızca bilgisayar üreticilerini değil, aynı zamanda cihaz üreticilerini, kablo üreticilerini, yazılım üreticilerini vb. nasıl içerdiğine dikkat edin. Bu, bir web topluluğunun ne kadar geniş ve derin (aynı zamanda dar ve sığ) olabileceğini gösterir.
'Güven' nasıl ortaya çıktı?
"Uzmanlık" ve "yetkili olma" konusuna giren çok şey var ve "güven" konusuna giren pek çok şey var.
"Güven" bile köprü analizi ve web yapısı alanına girer. İstenmeyen e-postaları keşfetmek ve ayıklamak için güvenilir olan "uzman sayfalarının" içeriğini ve bağlantısını kullanmak için çok çaba harcandı. AI ve ML teknikleri ile bu bağlantı modellerini tespit etmek ve ortadan kaldırmak çok daha kolaydır.
Eskiden "TrustRank" olarak bilinen bir algoritma geliştirildi ve buna dayanıyordu. Tabii ki, "güven" için asit testi gerçekten son kullanıcı ile gerçekleşir.
Arama motorları, istenmeyen postaları ayıklamaya ve kullanıcıların bilgi ihtiyaçlarını gerçekten karşılayan sonuçlar sunmaya çalışır. Bu nedenle, sayfalara kullanıcı erişim kalıpları, hangi sayfaların web topluluğu testini (bağlantı) ve ardından son kullanıcı testini (kullanıcı erişim verileri) geçenlere ilişkin büyük miktarda veri sağlar.
Bahsettiğim gibi, diğer web sayfalarından sayfalarınıza verilen bağlantılar, içeriğiniz için bir "oy" olarak görülebilir. Peki ya size bir bağlantı verecek web sayfaları olmayan milyonlarca son kullanıcı – nasıl oy verebilirler?
Bunu, belirli sonuçlara tıklayarak veya diğerlerine tıklamadan "güvenleri" ile yaparlar.
Her şey son kullanıcıların içeriğinizi tüketip tüketmediği ile ilgili – çünkü tüketmiyorlarsa – Google'ın bir sorgunun ardından onu sonuçlara döndürmesinin ne anlamı var?
Aramada 'uzman', 'yetki' ve 'güven' ne anlama geliyor?
Özetlemek gerekirse, kendi sayfalarınızda kendinizi uzman ilan edemezsiniz.
Belirli bir alanda uzman veya otorite olduğunuzu veya dünyanın şu veya bu konuda lider olduğunu "iddia edebilirsiniz".
Ancak felsefi olarak, Google ve diğer arama motorları şöyle diyor: "Başka kim böyle düşünüyor?"
Kendin hakkında söylediğin şey değil. Bu, başkalarının sizin hakkınızda söylediği şeydir (bağlantı metni). Topluluğunuzda bir "itibar" bu şekilde inşa edersiniz.
Ayrıca, Google'ın kalite değerlendiricileri, içeriğinizin "uzman" veya sizin bir "yetkili" olup olmadığınıza kendileri karar vermezler. Görevleri, Google'ın algoritmalarının işini yapıp yapmadığını incelemek ve belirlemektir.
Bu çok büyüleyici bir konu ve ele alınacak daha çok şey var. Ama şimdilik zamanımız ve yerimiz kalmadı.
Bir dahaki sefere, yapılandırılmış verilerin ne kadar önemli olduğunu ve web topluluğunuz içinde "anlamsal olarak" bağlantılı olmanın ne kadar önemli olduğunu açıklayacağım.
O zamana kadar, arama motorlarının iç işleyişiyle ilgili bir sonraki destansı okuma için büyük bir beklentiyle başka bir mevsime girerken sonbaharın altın renklerinin tadını çıkarın.
Bu makalede ifade edilen görüşler konuk yazara aittir ve mutlaka Search Engine Land değildir. Personel yazarları burada listelenir.