
Signifikansi Statistik Tidak Sama dengan Validitas (atau Mengapa Anda Mendapatkan Peningkatan Imajiner)
Diterbitkan: 2020-10-06Skenario yang sangat umum: Sebuah bisnis menjalankan puluhan dan puluhan pengujian A/B selama setahun, dan banyak di antaranya “menang”. Beberapa pengujian memberi Anda peningkatan pendapatan sebesar 25%, atau bahkan lebih tinggi.
Namun ketika Anda meluncurkan perubahan, pendapatan tidak meningkat 25%. Dan 12 bulan setelah menjalankan semua tes tersebut, tingkat konversi masih hampir sama. Bagaimana bisa?
Jawabannya adalah ini: Peningkatan Anda hanya imajiner. Tidak ada peningkatan untuk memulai.
Ya, alat pengujian Anda mengatakan bahwa Anda memiliki tingkat signifikansi statistik 95% (atau lebih tinggi). Yah, itu tidak berarti banyak. Signifikansi statistik dan validitas tidak sama.
Signifikansi statistik bukanlah aturan berhenti.
Ketika pengujian Anda mengatakan bahwa Anda telah mencapai tingkat kepercayaan 95% atau bahkan 99%, itu tidak berarti bahwa Anda memiliki variasi kemenangan.
Berikut adalah contoh yang pernah saya gunakan sebelumnya. Dua hari setelah memulai tes, inilah hasilnya:

Variasi yang saya buat sangat menurun—lebih dari 89% (dan tidak ada tumpang tindih dalam margin kesalahan). Dikatakan di sini bahwa Variasi 1 memiliki peluang 0% untuk mengalahkan Kontrol.
Apakah ini hasil yang signifikan secara statistik? Ya itu. Masukkan angka yang sama ke dalam kalkulator tes A/B, dan mereka akan mengatakan hal yang sama. Berikut adalah hasil menggunakan kalkulator signifikansi ini:
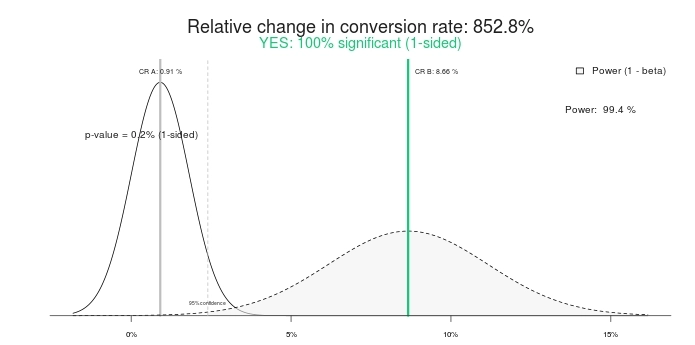
Jadi tes signifikan 100%, dan peningkatan 852,8% (atau, lebih tepatnya, Kontrol lebih dari> 800% lebih baik daripada perawatan). Mari kita akhiri tesnya, ya? Kontrol menang! Atau bagaimana kalau kita memberinya waktu lagi?
Ini penampakan 10 hari kemudian:

Itu benar, variasi yang memiliki peluang 0% untuk mengalahkan kontrol sekarang menang dengan kepercayaan 95%. Ada apa dengan itu? Mengapa “100% signifikansi” dan “0% peluang menang” menjadi tidak berarti? Karena mereka adalah.
Jika Anda mengakhiri tes lebih awal, ada kemungkinan besar Anda akan memilih pemenang yang salah. Dalam skenario ini, banyak (kebanyakan?) bisnis masih melanjutkan dan menerapkan perubahan (yaitu meluncurkan variasi yang menang ke 100% lalu lintas), sementara, pada kenyataannya, peningkatan 800% menjadi nol, atau bahkan negatif (kalah).
Bahkan lebih buruk dari lift imajiner adalah kepercayaan palsu yang Anda miliki sekarang. Anda pikir Anda telah mempelajari sesuatu dan terus menerapkan pembelajaran itu di tempat lain di situs. Tetapi pembelajaran itu sebenarnya tidak valid, sehingga membuat semua usaha dan waktu Anda menjadi sia-sia.
Ini sama dengan tangkapan layar pengujian kedua (10 hari)—meskipun dikatakan signifikansi 95%, itu masih belum "matang". Sampel terlalu kecil; perbedaan mutlak dalam konversi hanya 19 transaksi. Itu bisa berubah dalam sehari.

Ton Wesseling mengatakan ini tentangnya:
Anda harus tahu bahwa menghentikan tes setelah itu signifikan adalah dosa mematikan nomor 1 di tanah pengujian A/B. Tujuh puluh tujuh persen dari A/A-tests (halaman yang sama terhadap halaman yang sama) akan mencapai signifikansi pada titik tertentu.
Pelajari apa arti sebenarnya.
Signifikansi statistik saja seharusnya tidak menentukan apakah Anda mengakhiri tes atau tidak. Itu bukan aturan berhenti.
Signifikansi statistik tidak memberi tahu kita probabilitas bahwa B lebih baik daripada A. Signifikansi statistik juga tidak memberi tahu kita probabilitas bahwa kita akan membuat kesalahan dalam memilih B daripada A.
Ini adalah kesalahpahaman yang sangat umum, tapi itu salah. Untuk mempelajari apa sebenarnya nilai-p, baca posting ini.
Jalankan pengujian Anda lebih lama.
Jika Anda menghentikan pengujian setelah beberapa hari, Anda melakukan kesalahan. Tidak masalah jika Anda mendapatkan 10.000 transaksi per hari. Jumlah absolut transaksi penting, tetapi Anda juga membutuhkan waktu yang murni.

Matt Gershoff dari Conductrics menjelaskan alasannya:
Salah satu kesulitan dalam menjalankan tes online adalah kami tidak mengendalikan kelompok pengguna kami. Ini bisa menjadi masalah jika pengguna mendistribusikan secara berbeda menurut waktu dan hari dalam seminggu, dan bahkan menurut musim. Karena itu, kami mungkin ingin memastikan bahwa kami mengumpulkan data kami melalui siklus data yang relevan. Dengan begitu, perawatan kami diekspos ke sampel yang lebih representatif dari rata-rata populasi pengguna.
Perhatikan bahwa segmentasi tidak benar-benar membuat kita keluar dari ini, karena kita masih perlu mengambil sampel selama hari kerja, akhir pekan, dll., dan kita mungkin ingin mencapai bagian hari atau hari beberapa kali untuk rata-rata dan acara eksternal yang dapat memengaruhi arus/konversi lalu lintas untuk mendapatkan perkiraan yang baik tentang fitur/segmen berbasis waktu yang berdampak pada konversi.
Saya melihat skenario berikut setiap saat:
- Beberapa hari pertama: B menang besar. Biasanya karena faktor kebaruan.
- Setelah minggu #1: B menang kuat.
- Setelah minggu #2: B masih menang, tetapi perbedaan relatif lebih kecil.
- Setelah minggu #4: Regresi ke mean—peningkatan telah menghilang.
Jadi, jika Anda menghentikan tes sebelum empat minggu (bahkan mungkin setelah beberapa hari), Anda pikir Anda memiliki variasi kemenangan, tetapi ternyata tidak. Jika Anda meluncurkannya secara langsung, Anda memiliki apa yang saya sebut "pengangkatan imajiner". Anda merasa mengalami peningkatan karena alat pengujian Anda menunjukkan pertumbuhan >25%, tetapi Anda tidak melihat pertumbuhan di rekening bank Anda.
Jalankan pengujian Anda lebih lama. Pastikan mereka menyertakan dua siklus bisnis, memiliki konversi/transaksi absolut yang cukup, dan memiliki durasi yang cukup dari waktu ke waktu.

Contoh lift imajiner
Berikut adalah pengujian yang kami jalankan untuk klien e-niaga. Durasi pengujian adalah 35 hari, hanya menargetkan pengunjung desktop, dan memiliki hampir 3.000 transaksi per variasi.
Spoiler: Tes berakhir dengan "tidak ada perbedaan." Berikut ikhtisar Optimizely untuk pendapatan (klik untuk memperbesar):

Mari kita lihat sekarang:
- Beberapa hari pertama: Biru (variasi #3) menang besar—seperti $16 per pengunjung vs. $12,5 untuk Kontrol (#Menang!). Banyak orang mengakhiri tes di sini (#Gagal!).
- Setelah 7 hari: Biru masih menang, dan perbedaan relatifnya besar.
- Setelah 14 hari: Oranye (#4) menang!
- Setelah 21 hari: Oranye masih menang!
- Akhir: Tidak ada perbedaan.
Jadi, jika Anda menjalankan tes kurang dari empat minggu, Anda akan salah menyebut pemenangnya.
Aturan berhenti
Jadi, kapan tes dimasak?
Sayangnya, tidak ada jawaban surgawi universal di luar sana, dan ada banyak faktor "tergantung". Yang mengatakan, Anda dapat memiliki beberapa aturan berhenti yang cukup bagus untuk sebagian besar kasus.
Berikut adalah aturan berhenti saya:
- Durasi tes minimal 3 minggu (lebih baik jika 4).
- Ukuran sampel minimum yang telah dihitung sebelumnya tercapai (menggunakan alat yang berbeda). Saya tidak akan mempercayai pengujian apa pun yang memiliki kurang dari 250–400 konversi per variasi.
- Signifikansi statistik setidaknya 95%.
Mungkin berbeda untuk beberapa tes karena kekhasan, tetapi dalam banyak kasus, saya mematuhi aturan itu.
Berikut Wesseling menimpali lagi:
Anda ingin menguji selama mungkin—setidaknya satu siklus pembelian—semakin banyak data, semakin tinggi kekuatan statistik pengujian Anda!
Lebih banyak lalu lintas berarti Anda memiliki peluang lebih tinggi untuk mengenali pemenang Anda pada tingkat signifikansi yang Anda uji! Perubahan kecil dapat membuat dampak besar, tetapi dampak besar tidak terjadi terlalu sering—sebagian besar waktu, variasi Anda sedikit lebih baik, jadi Anda memerlukan banyak data untuk melihat pemenang yang signifikan.
Tetapi jika pengujian Anda bertahan lama, orang cenderung menghapus cookie mereka (10% dalam dua minggu). Ketika mereka kembali dalam pengujian Anda, mereka dapat berakhir dengan variasi yang salah—jadi, ketika minggu-minggu berlalu, sampel Anda semakin banyak mencemari dan berakhir dengan tingkat konversi yang sama.
Tes maksimal 4 minggu.
Bagaimana jika—setelah tiga atau empat minggu—ukuran sampel kurang dari 400 konversi per variasi?
Saya membiarkan tes berjalan lebih lama. Jika, dalam waktu 4 minggu, ukuran sampel tidak tercapai, saya menambahkan seminggu lagi.
Selalu uji minggu penuh . Jika Anda memulai tes pada hari Senin, itu harus berakhir pada hari Minggu. Jika Anda tidak menguji seminggu penuh pada satu waktu, Anda mungkin mendistorsi hasil Anda.
Jalankan laporan konversi per hari dalam seminggu di situs Anda. Lihat berapa banyak fluktuasi yang ada.
Apa yang kamu lihat di bawah? Hari Kamis menghasilkan uang 2X lebih banyak daripada hari Sabtu dan Minggu, dan tingkat konversi pada hari Kamis hampir 2X lebih baik daripada hari Sabtu.

Jika kami tidak menguji selama berminggu-minggu penuh, hasilnya akan tidak akurat. Uji minggu penuh pada suatu waktu.
Aturan penghentian yang sama berlaku untuk setiap segmen.
Segmentasi adalah kunci untuk belajar dari pengujian A/B. Biasanya B kalah dari A dalam hasil keseluruhan tetapi mengalahkan A di segmen tertentu (misalnya, lalu lintas Facebook, pengguna perangkat seluler, dll.).
Sebelum Anda dapat menganalisis data tersegmentasi, pastikan Anda memiliki ukuran sampel yang cukup besar dalam setiap segmen. Jadi, Anda memerlukan 250–400 konversi per variasi dalam setiap segmen yang Anda lihat.
Saya bahkan menyarankan Anda membuat pengujian bertarget (menetapkan audiens target/segmen dalam konfigurasi pengujian) daripada menganalisis hasil di seluruh segmen setelah pengujian. Ini memastikan bahwa tes tidak dipanggil lebih awal, dan setiap segmen memiliki ukuran sampel yang memadai.
Teman saya Andre Morys mengatakan ini tentang aturan berhentinya:

Saya selalu memberi tahu orang-orang bahwa Anda memerlukan sampel yang mewakili jika data Anda harus valid.
Apa yang dimaksud dengan “perwakilan”? Pertama-tama, Anda harus memasukkan semua hari kerja dan akhir pekan. Anda membutuhkan cuaca yang berbeda karena mempengaruhi perilaku pembeli. Tetapi yang terpenting, lalu lintas Anda harus memiliki semua sumber lalu lintas, terutama buletin, kampanye khusus, TV… semuanya! Semakin lama pengujian berjalan, semakin banyak wawasan yang Anda dapatkan.
Kami baru saja menjalankan tes untuk pengecer mode besar di tengah fase penjualan musim panas. Sangat menarik untuk melihat bagaimana hasilnya turun drastis selama "fase penjualan keras" dengan 70% dan lebih—tetapi pulih satu minggu setelah fase berakhir. Kami tidak akan pernah mempelajari ini jika tes tidak berjalan selama hampir empat minggu.
"Aturan praktis" kami adalah ini: 3.000–4.000 konversi per variasi dan durasi pengujian 3-4 minggu. Itu lalu lintas yang cukup sehingga kami bahkan dapat berbicara tentang data yang valid jika kami menelusuri segmen.
Menguji “dosa” nomor 1: Mencari peningkatan dalam segmen saat Anda tidak memiliki validitas statistik (mis. 85 vs. 97 konversi). Itu omong kosong.
Belajar dari ujian sangatlah penting—bahkan lebih dari sekadar mendapatkan kemenangan. Dan mengelompokkan data pengujian Anda adalah salah satu cara yang lebih baik untuk belajar. Pastikan segmen Anda memiliki data yang cukup sebelum Anda mengambil kesimpulan.
Kesimpulan
Hanya karena pengujian Anda mencapai tingkat signifikansi 95% atau lebih tinggi, jangan hentikan pengujian. Perhatikan juga jumlah mutlak konversi per variasi dan durasi pengujian.