
A significância estatística não é igual à validade (ou por que você obtém elevações imaginárias)
Publicados: 2020-10-06Um cenário muito comum: uma empresa executa dezenas e dezenas de testes A/B ao longo de um ano, e muitos deles “ganham”. Alguns testes proporcionam um aumento de 25% na receita, ou até mais.
No entanto, quando você implementa a mudança, a receita não aumenta 25%. E 12 meses depois de executar todos esses testes, a taxa de conversão ainda é praticamente a mesma. Por quê?
A resposta é esta: suas elevações eram imaginárias. Não houve elevação para começar.
Sim, sua ferramenta de teste disse que você tinha um nível de significância estatística de 95% (ou superior). Bem, isso não significa muito. A significância estatística e a validade não são a mesma coisa.
A significância estatística não é uma regra de parada.
Quando seu teste diz que você atingiu um nível de confiança de 95% ou até 99%, isso não significa que você tenha uma variação vencedora.
Aqui está um exemplo que eu usei antes. Dois dias após o início de um teste, estes foram os resultados:

A variação que construí estava perdendo muito — em mais de 89% (e sem sobreposição na margem de erro). Diz aqui que a Variação 1 tem 0% de chance de vencer o Controle.
Este é um resultado estatisticamente significativo? É sim. Digite os mesmos números em qualquer calculadora de teste A/B e eles dirão o mesmo. Aqui estão os resultados usando esta calculadora de significância:
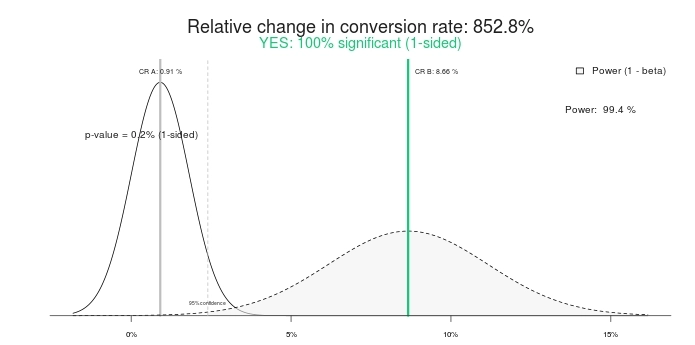
Portanto, um teste 100% significativo e 852,8% de aumento por cento (ou melhor, o controle é mais de 800% melhor que o tratamento). Vamos terminar o teste, certo? Controle vence! Ou que tal darmos mais algum tempo em vez disso?
Foi assim que ficou 10 dias depois:

Isso mesmo, a variação que tinha 0% de chance de vencer o controle agora estava vencendo com 95% de confiança. O que há com isso? Como é que “100% de significância” e “0% de chance de ganhar” se tornaram sem sentido? Porque eles são.
Se você terminar o teste mais cedo, há uma grande chance de você escolher o vencedor errado. Nesse cenário, muitos (a maioria?) das empresas ainda vão em frente e implementam a mudança (ou seja, lançam a variação vencedora para 100% do tráfego), enquanto, na verdade, o aumento de 800% se torna zero ou até negativo (perdendo).
Ainda pior do que o levantamento imaginário é a falsa confiança que você tem agora. Você acha que aprendeu alguma coisa e continua aplicando esse aprendizado em outro lugar do site. Mas o aprendizado é realmente inválido, tornando todos os seus esforços e tempo um completo desperdício.
É o mesmo com a segunda captura de tela de teste (10 dias depois) - embora diga 95% de significância, ainda não está "cozinhado". A amostra é muito pequena; a diferença absoluta nas conversões é de apenas 19 transações. Isso pode mudar em um dia.

Ton Wesseling tem isso a dizer sobre isso:
Você deve saber que parar um teste quando ele é significativo é o pecado mortal número 1 na terra dos testes A/B. Setenta e sete por cento dos testes A/A (mesma página contra a mesma página) alcançarão significância em um determinado ponto.
Aprenda o que realmente é significado.
A significância estatística por si só não deve determinar se você termina um teste ou não. Não é uma regra de parada.
A significância estatística não nos diz a probabilidade de que B seja melhor que A. Nem nos diz a probabilidade de cometermos um erro ao selecionar B em vez de A.
Ambos são equívocos extraordinariamente comuns, mas são falsos. Para saber o que realmente são os valores-p, leia este post.
Execute seus testes por mais tempo.
Se você parar seus testes depois de alguns dias, você está fazendo errado. Não importa se você recebe 10.000 transações por dia. O número absoluto de transações é importante, mas você também precisa de tempo puro.

Matt Gershoff da Conductrics explica o porquê:
Uma das dificuldades com a execução de testes online é que não estamos no controle de nossos grupos de usuários. Isso pode ser um problema se os usuários distribuírem de forma diferente por hora e dia da semana, e até mesmo por temporada. Por isso, provavelmente queremos ter certeza de que coletamos nossos dados em todos os ciclos de dados relevantes. Dessa forma, nossos tratamentos ficam expostos a uma amostra mais representativa da população média de usuários.
Observe que a segmentação realmente não nos tira disso, pois ainda precisaremos amostrar durante os dias da semana, fins de semana etc., e provavelmente queremos acertar cada dia ou parte do dia algumas vezes para calcular a média e eventos externos que podem estar afetando o fluxo/conversão de tráfego para obter boas estimativas de recursos/segmentos baseados em tempo de impacto na conversão.
Eu vejo o seguinte cenário o tempo todo:
- Primeiro par de dias: B está ganhando muito. Normalmente devido ao fator novidade.
- Após a semana #1: B vencendo forte.
- Após a semana #2: B ainda está ganhando, mas a diferença relativa é menor.
- Após a semana #4: Regressão à média – a elevação desapareceu.
Então, se você parar o teste antes de quatro semanas (talvez até depois de alguns dias), você acha que tem uma variação vencedora, mas não tem. Se você lançar ao vivo, terá o que chamo de “elevação imaginária”. Você acha que tem um aumento porque sua ferramenta de teste mostrou um crescimento >25%, mas você não vê crescimento em sua conta bancária.
Execute seus testes por mais tempo. Certifique-se de que eles incluam dois ciclos de negócios, tenham conversões/transações absolutas suficientes e tenham duração suficiente no tempo.

Exemplo de um elevador imaginário
Aqui está um teste que executamos para um cliente de comércio eletrônico. A duração do teste foi de 35 dias, direcionado apenas a visitantes de desktop e teve cerca de 3.000 transações por variação.
Spoiler: O teste terminou com “sem diferença”. Aqui está a visão geral do Optimizely para receita (clique para ampliar):

Vamos ver agora:
- Primeiros dias: Azul (variação nº 3) está ganhando muito – como US$ 16 por visitante versus US$ 12,5 para Controle (#Vencendo!). Muitas pessoas terminam o teste aqui (#Fail!).
- Após 7 dias: Azul ainda está ganhando, e a diferença relativa é grande.
- Após 14 dias: Laranja (#4) está ganhando!
- Após 21 dias: Laranja ainda está ganhando!
- Fim: Sem diferença.
Então, se você tivesse feito o teste por menos de quatro semanas, você teria chamado o vencedor errado.
As regras de parada
Então, quando um teste é preparado?
Infelizmente, não existe uma resposta celestial universal por aí, e há muitos fatores “depende”. Dito isso, você pode ter algumas regras de parada muito boas para a maioria dos casos.
Aqui estão minhas regras de parada:
- Duração do teste de pelo menos 3 semanas (melhor se 4).
- Tamanho mínimo de amostra pré-calculado alcançado (usando diferentes ferramentas). Não acredito em nenhum teste que tenha menos de 250 a 400 conversões por variação.
- Significância estatística de pelo menos 95%.
Pode ser diferente para alguns testes por causa de peculiaridades, mas na maioria dos casos, eu sigo essas regras.
Aqui está Wesseling entrando na conversa novamente:
Você quer testar o maior tempo possível—pelo menos um ciclo de compra—quanto mais dados, maior o poder estatístico do seu teste!
Mais tráfego significa que você tem uma chance maior de reconhecer seu vencedor no nível de significância em que está testando! Pequenas mudanças podem causar um grande impacto, mas grandes impactos não acontecem com muita frequência - na maioria das vezes, sua variação é um pouco melhor, então você precisa de muitos dados para perceber um vencedor significativo.
Mas se seus testes durarem e durarem, as pessoas tendem a excluir seus cookies (10% em duas semanas). Quando eles retornam em seu teste, eles podem acabar na variação errada – então, quando as semanas passam, suas amostras poluem cada vez mais e acabam com as mesmas taxas de conversão.
Teste por no máximo 4 semanas.
E se, após três ou quatro semanas, o tamanho da amostra for inferior a 400 conversões por variação?
Deixei o teste correr mais. Se, em 4 semanas, o tamanho da amostra não for alcançado, acrescento mais uma semana.
Sempre teste semanas inteiras . Se você começar o teste em uma segunda-feira, ele deve terminar em um domingo. Se você não testar uma semana inteira de cada vez, poderá distorcer seus resultados.
Gere um relatório de conversões por dia da semana em seu site. Veja quanta flutuação existe.
O que você vê abaixo? As quintas-feiras ganham 2X mais dinheiro do que sábados e domingos, e a taxa de conversão nas quintas-feiras é quase 2X melhor do que no sábado.

Se não testássemos por semanas inteiras, os resultados seriam imprecisos. Teste semanas inteiras de cada vez.
As mesmas regras de parada se aplicam a cada segmento.
A segmentação é a chave para aprender com os testes A/B. É comum que B perca para A nos resultados gerais, mas vença A em certos segmentos (por exemplo, tráfego do Facebook, usuários de dispositivos móveis etc.).
Antes de poder analisar quaisquer dados segmentados, certifique-se de ter um tamanho de amostra grande o suficiente em cada segmento. Portanto, você precisa de 250 a 400 conversões por variação em cada segmento que estiver analisando.
Eu até recomendo que você crie testes direcionados (defina público-alvo/segmento na configuração do teste) em vez de analisar os resultados nos segmentos após um teste. Isso garante que os testes não sejam chamados antecipadamente e que cada segmento tenha um tamanho de amostra adequado.
Meu amigo Andre Morys disse isso sobre suas regras de parada:

Sempre digo às pessoas que você precisa de uma amostra representativa para que seus dados sejam válidos.
O que significa “representante”? Primeiro de tudo, você precisa incluir todos os dias da semana e fins de semana. Você precisa de um clima diferente porque isso afeta o comportamento do comprador. Mas o mais importante, seu tráfego precisa ter todas as fontes de tráfego, especialmente newsletter, campanhas especiais, TV… tudo! Quanto mais tempo o teste é executado, mais insights você obtém.
Acabamos de fazer um teste para um grande varejista de moda no meio da fase de vendas de verão. Foi muito interessante ver como os resultados caíram drasticamente durante a “fase de venda difícil” com 70% ou mais, mas se recuperaram uma semana após o término da fase. Nós nunca teríamos aprendido isso se o teste não tivesse sido executado por quase quatro semanas.
Nossa “regra de ouro” é esta: 3.000–4.000 conversões por variação e duração do teste de 3–4 semanas. Isso é tráfego suficiente para que possamos até falar sobre dados válidos se detalharmos os segmentos.
Testando o “pecado” número 1: Buscando melhorias dentro de segmentos quando você não tem validade estatística (por exemplo, 85 vs. 97 conversões). Isso é treta.
Aprender com os testes é super importante – ainda mais do que obter vitórias. E segmentar seus dados de teste é uma das melhores maneiras de aprender. Apenas certifique-se de que seus segmentos tenham dados suficientes antes de tirar conclusões precipitadas.
Conclusão
Só porque seu teste atingiu um nível de significância de 95% ou mais, não interrompa o teste. Preste atenção também ao número absoluto de conversões por variação e à duração do teste.